







本文摘抄至 : NIO - Buffer
唠叨 : 在使用OPenGL的时候,需要使用到 nio的相关内容。搜索了一下,找到了这片文章。但是,看着文字是何种的痛苦。加上最近自身心不在焉。更加雪上加霜。只有发大招,直接抄一遍。来对此进行了解
注: 摘抄此片文章是因为文章的作者只介绍了 buffer的一些内容。跟好理解的文章见参考链接的 ‘’Java NIO 系列教程 ‘’
NIO - Buffer
Buffer 类是 “java.nio“ 的构造基础。一个 Buffer 对象是固定数量的数据的容器,其作用是一个存储器。或者分段运输区。在这里,数据可被存储并在之后用于检索。缓冲区可以被写满或释放。对于么每个非布尔原始数据类型都有一个缓冲区。即 Buffer 的所有子类:ByteBuffer、CharBuffer、DoubleBuffer、FloatBuffer、IntBuffer、LongBuffer 和 ShortBuffer。 是没有 BooleanBuffer 之说的。尽管缓冲区作用于它们存储的原始数据类型。但缓存区十分倾向于处理字节。非字节缓冲区可以在后台执行字节或到非字节的转换。这取决于缓冲区是如何创建的。
◇ 缓存区的四个属性
所有的缓冲区都具有四个属性来提供关于其所包含的数据元素信息。这四个属性尽管简单,但其只管重要,需要熟记于心:
- 容量(capacity):缓冲区能够容纳的数据元素的最大数量。这一容量在缓冲区创建时被设定。并且,永远不能被改变
- 上界(limit):缓冲区的第一个不能被读或写的元素。缓冲区创建时,limit 的值等于 capacity 的值。假设, capacity = 1024,我们在程序中设置了 limit = 512,说明,Buffer的容量为 1024。但是从 512 之后既不能读也不能写。因此可以理解成,Buffer 的实际可用大小为 512
- 位置(position):下一个要被读或写的元素的索引。位置会自动由相应的 get( ) 和 put( ) 函数更新
- 标记(mark):一个备忘的位置。标记在设定前是未定义的(undefined)。使用场景是,假设缓冲区中有 10 个元素,position 目前的位置是 2,现在只想发送 6 - 10 之间的缓冲数据。此时,我们可以buffer.mark(buffer.position()),即把当前的 position 计入 mark中,然后 buffer.position(6),此时发送给 channel 的数据就是 6 - 10 的数据。发送完后,我们可以调用 buffer.reset()是的 position = mark。因此,这里的 mark 只是用于临时记录一下位置用的
◇ 相对存取个绝对存取
public abstract class ByteBuffer extends Buffer implements Comparable {
// This is a partial API listing
public abstract byte get( );
public abstract byte get (int index);
public abstract ByteBuffer put (byte b);
public abstract ByteBuffer put (int index, byte b);
}◇ 翻转
我们把 hello这个串通过 put 存入 —— ByteBuffer,如下所示:将 hello 存入 ByteBuffer中
ByteBuffer buffer = ByteBuffer.allocate(1024);
buffer.put((byte)'H').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o'); buffer.limit(buffer.poition()).position(0);◇ 释放(Drain)
这里的释放,指的是缓冲区通过 put 填充数据后,然后被读出的过程。上面讲了,要读数据。首先,的翻转。那么怎么读呢 ? hasRemaining( ) 会在释放缓冲区时告诉你是否已经达到缓冲区的上界:
for(int i = 0;i < buffer.remaining(); i++ ){
myByteArray[i] = buffer.get();
}int count = buffer.remaining();
for(int i = 0;i < count; i++ ){
myByteArray[i] = buffer.get();
}◇ buffer.clear()
clear( )函数将缓冲区重置为空状态。它并不改变缓冲区的任何数据元素,而是仅仅将 limit 设为容量的值,并把 position 设回 0。
◇Compact(不知咋翻译,压缩比?紧凑?)
有时候我们指向释放一部分数据,即只读取部分数据。当然,你可以把position 指向你要读取的第一个数据的位置,将 limit 设置成最后一个元素的位置 +1。但是,一旦缓存区对象完成填充并释放,它就可以被重新使用了。所以,缓冲区一旦被读取出来,已经没有使用价值了。 以 Mellow 为例,填充后后为 Mellow,但如果我仅仅想读取 llow。读取完后,缓冲区就可以重新使用了。Me 这两个位置对于我们而言是没有用的。我们可以将 llow 复制至 0 - 3 上,Me 则被冲掉。但是, 4 和 5 仍然为 o 和 w。这个事我们当然可以自行通过 get 和 put 来完成,但 api 给我们提供了一个 compact( )的函数,此函数比我们自己使用 get 和 put 要高效的对多。
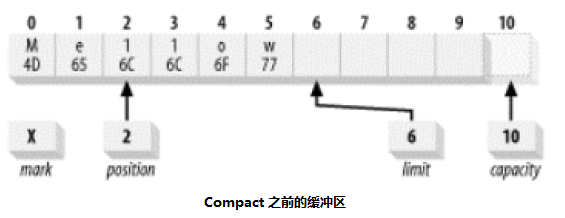
buffer.compact( )会使缓冲区的状态图如下图所示:

这里发生了几件事:
- 数据元素 2 - 5 倍复制到 0 - 3 位置,位置 4 和 5 不受影响,但现在正在或者已经超出了当前位置。因此是“死的“。 它们可以被之后的 put( ) 调用填写
- position 已经被设为被复制的数据元素的数目,也就是说,缓冲区现在被定位在缓冲区中的最后一个“存活“ 元素的后一个位置
- 上界属性被设置为容量的值,因此缓冲区可以被再次填满
- 调用 compact( )的作用是丢弃已经释放的数据,保留未释放的数据。并使缓冲区对重新填充容量准备就绪。该例子中,你当然可以将 Me 之前已经读过,即已经被释放过
◇ 缓冲区的比较
有时候比较两个缓冲区所包含的数据是很有必要的。所有 的缓冲区都提供了一个常规的 equals() 用以测试两个缓冲区是否相等,以及一个 compareTo( )函数用以比较缓冲区
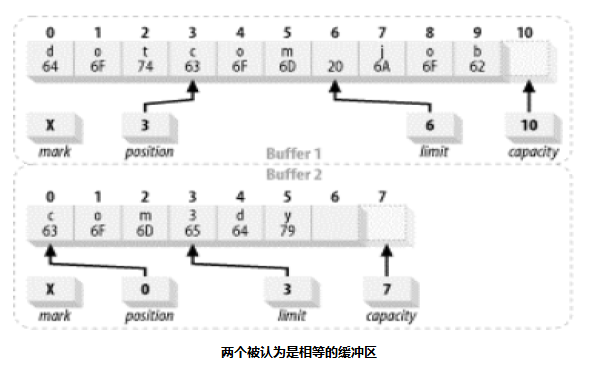
两个缓冲区被认为相等的充要条件是:
- 两个对象类型相同,包含不同数据类型的 buffer 永远不会相等,而且buffer 绝不会等于非 buffer 对象
- 两个对象都剩余相同数量(limit - position)的元素。Buffer 的容器不需要相同,而且缓冲区中剩余数据的索引页不必相同
- 在每一个缓冲区中应被 get( ) 函授返回的剩余数据元素序列([position,linit - 1] 位置对应元素的序列) 必须一致

缓冲区也支持 compareTo( )函数以词典顺序进行比较。当然,这是所有的缓冲区实现了java.lang.Comparable 语义化的接口。这也意味着缓冲区数组可以通过调用 java.util.Arrays.sort() 函数按照它们的内容进行排序。
与 equals( )相似,compareTo( )不允许不同对象间进行比较。但 compareTo( )更为严格;如果你传递一个类型错误的对象,它会抛出 ClassCastException 异常,但 equals( )只是返回 false。
比较是针对每个缓冲区你剩余数据(从 position 到 limit) 进行的,与它们在 equals( )中的方式相同,直到不相等的元素被发现或者到达缓冲区的上界。如果一个缓冲区在不相等元素发现前,已经耗尽。较短的缓冲区被认为是小于较长的缓冲区。这里有个顺序问题:下面小于零的结果(表达式的值为 true) 的含义是 buffer2 < buffer1。切记,这里代表的并不是 buffer1 < buffer2
if (buffer1.compareTo(buffer2) < 0) {
// do sth, it means buffer2 < buffer1,not buffer1 < buffer2
doSth();
} ◇ 批量移动
缓冲区的设计目的就是为了能够高效传输数据,一次移动一个数据元素并不高效。如果在下面的程序清单中所看到的那样,buffer API提供了 向缓冲区内外批量移动数据元素的函数
public abstract class ByteBuffer extends Buffer implements Comparable {
public ByteBuffer get(byte[] dst);
public ByteBuffer get(byte[] dst, int offset, int length);
......
public final ByteBuffer put(byte[] src);
public ByteBuffer put(byte[] src, int offset, int length);
......
} - 如果你所需求的数量的数据不能被传递,那么不会有数据被传递,缓冲区的状态保持不变,同时抛出 BufferUnderflowException 异常
- 如果缓冲区中的数据不够完全填满数组,你会得到一个异常。这意味着如果你想将一个小型缓冲区传入大型数组,你需要明确的指定缓冲区中剩余的数据长度
byte[] smallArray = new Byte[10];
while (buffer.hasRemaining()) {
int length = Math.min(buffer.remaining(), smallArray.length);
buffer.get(smallArray, 0, length);
// 每取出一部分数据后,即调用 processData 方法,length 表示实际上取到了多少字节的数据
processData(smallArray, length);
} ◇ 创建缓冲区
Buffer 的七种子类,没有一种能够直接实例化,它们都是抽象类。但是都包含静态工厂方法来创建相应类新实例。这部分讨论中,将以 CharBuffer 类为例,对于其它六种主要的缓冲区类也是适用的 下面创建一个缓冲区的关键 函数,对所有的缓冲区类通用(要按照需要替换类名)
public abstract class CharBuffer extends Buffer implements CharSequence, Comparable {
// This is a partial API listing
public static CharBuffer allocate (int capacity);
public static CharBuffer wrap (char [] array);
public static CharBuffer wrap (char [] array, int offset, int length);
......
public final boolean hasArray();
public final char [] array();
public final int arrayOffset();
......
} // 这段代码隐含地从堆空间中分配了一个 char 型数组作为备份存储器来储存 100 个 char 变量。
CharBuffer charBuffer = CharBuffer.allocate (100);
/**
* 这段代码构造了一个新的缓冲区对象,但数据元素会存在于数组中。这意味着通过调用 put() 函数造成的对缓
* 冲区的改动会直接影响这个数组,而且对这个数组的任何改动也会对这个缓冲区对象可见。
*/
char [] myArray = new char [100];
CharBuffer charbuffer = CharBuffer.wrap (myArray);
/**
* 带有 offset 和 length 作为参数的 wrap() 函数版本则会构造一个按照你提供的 offset 和 length 参
* 数值初始化 position 和 limit 的缓冲区。
*
* 这个函数并不像你可能认为的那样,创建了一个只占用了一个数组子集的缓冲区。这个缓冲区可以存取这个数组
* 的全部范围;offset 和 length 参数只是设置了初始的状态。调用 clear() 函数,然后对其进行填充,
* 直到超过 limit,这将会重写数组中的所有元素。
*
* slice() 函数可以提供一个只占用备份数组一部分的缓冲区。
*
* 下面的代码创建了一个 position 值为 12,limit 值为 54,容量为 myArray.length 的缓冲区。
*/
CharBuffer charbuffer = CharBuffer.wrap (myArray, 12, 42);◇ 复制缓冲区
缓冲区不限于管理数组中的外部数据,它们也能管理其他缓冲区中的外部数据。当一个管理其他缓冲区所包含的数据元素的缓冲器被创建时,这个缓冲器被称为 视图缓冲器 视图存储器总是通过调用已经存在的存储器实例中的函数来创建。使用已存在的存储器实例中的工厂方法意味着视图对象为原始存储区域的,你不实现细节私有。数据元素可以直接存取,无论它们是存储在数组中还是以一些其他的方式。而不需经过原始缓冲区对象的 get( )/put( ) API。如果原始缓冲区是直接缓冲区,该缓冲区(视图缓冲区)的视图会具有同样的效率优势。 继续以 CharBuffer 为例,但同样的操作被用于任何基本的缓冲区类型。 用于复制缓冲区的 api
public abstract class CharBuffer extends Buffer implements CharSequence, Comparable {
// This is a partial API listing
public abstract CharBuffer duplicate();
public abstract CharBuffer asReadOnlyBuffer();
public abstract CharBuffer slice();
} CharBuffer buffer = CharBuffer.allocate(8);
buffer.position(3).limit(6).mark().position (5);
CharBuffer dupeBuffer = buffer.duplicate();
buffer.clear();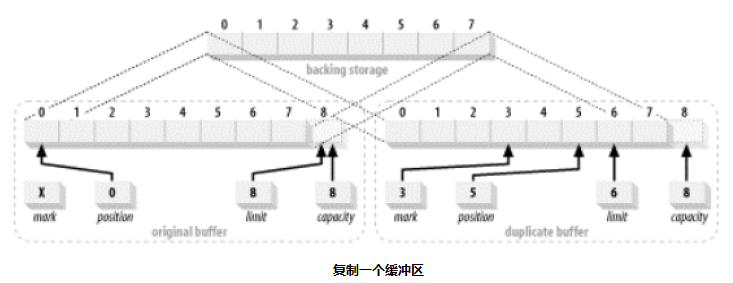
● asReadOnlyBuffer( )
asReadOnlyBuffer( )函数来生成一个只读的缓冲区视图。这与 duplicate( )相同,除了这个新的缓冲区不予许使用 put( ),并且其 isReadOnly( )函数将会返回 true。
如果一个只读的缓冲区与一个可写的缓冲区共享数据,或者有包装好的备份数组,那么对这个可写的缓冲区或直接对这个数组的改变将反应在所有关联的缓冲区上,包括只读缓冲区。
● slice( )
分割缓冲区与复制相似,但 slice( )创建一个从原始缓冲区的当前 position 开始的新的缓冲区,并且其容量是原始缓冲区的剩余元素数量(limit - position)。这个新的缓冲区与原始缓冲区共享一段元素子序列。分割出来的缓冲区也会继续只读和直接属性slice( )分割缓冲区:
CharBuffer buffer = CharBuffer.allocate(8);
buffer.position(3).limit(5);
CharBuffer sliceBuffer = buffer.slice(); 
◇ 字节缓冲区(ByteBuffer)
ByteBuffer只是Buffer 的一个子类,但字节缓冲区有字节的独特之处。字节缓冲区跟其它缓冲区类型最明明显的不同在于,它可以成为通道锁执行的 I/O 的源头或目标,后面你会发现 通道只接受 ByteBuffer 作为参数。
字节是操作系统及其 I/O设备使用的基本数据类型。当在 JVM 和操作系统间传递数据时,将其它数据类型拆分成它们的字节是十分必要的,系统层次的 I/O 面向字节的性质可以在整个缓冲区的设计及它们互相配合的服务中感受到。同时,操作系统是在内存区域中进行 I/O 操作。这些内存区域,就操作系统方面而言,是相连的字节序列。于是,毫无疑问,只有字节缓冲区有资格参数与
I/O 操作
非字节类型的基本类型,除了布尔型都是由组合在一起的几个字节组成的。那么必然要引出另一个问题:字节的顺序。
多字节数值被存储在内存中的方式一般被称为 endian-ness(字节顺序)。如果数字数值的最高字节 - big end(大端),位于低位地址(即 big end 先写入内存,先写入的内存的地址是低位的,后写入内存的地址是高位的),那么系统就是大端字节顺序。如果最低字节最先保存在内存中,那么系统就是小端字节顺序。什么是计算机的大小端规则? 在 java.nio 中,字节顺序由 ByteOrder 类封装:
package java.nio;
public final class ByteOrder {
public static final ByteOrder BIG_ENDIAN;
public static final ByteOrder LITTLE_ENDIAN;
public static ByteOrder nativeOrder();
public String toString();
}public abstract class CharBuffer extends Buffer implements Comparable, CharSequence {
// This is a partial API listing
public final ByteOrder order();
} public abstract class ByteBuffer extends Buffer implements Comparable {
// This is a partial API listing
public final ByteOrder order();
public final ByteBuffer order(ByteOrder bo);
}◇ 直接缓冲区
内核空间(与之相对的是用户空间,如 JVM)是操作系统所在的区域,它能与设备控制器(硬件)通讯,控制着用户区域进程(如 JVM) 的运行状态。最重要的是,所有的 I/O 都是直接(物理内存)或间接(虚拟内存) 通过内核空间。 当进程(如 JVM)请求 I/O 操作的时候,它执行一个系统调用将控制权移交给内核。当内核以这种方式被调用,它随即采取任何必要步骤,找到进程所需数据,并把数据传递到用户空间你的指定缓冲区。内核视图对数据进行高速缓存或预读取。因此进程所需可能已经在内核空间里了。如果是这样,该数据只需要简单的拷贝出来即可。如果数据不在内核空间,则进程被挂起,内核着手把数据读进内存
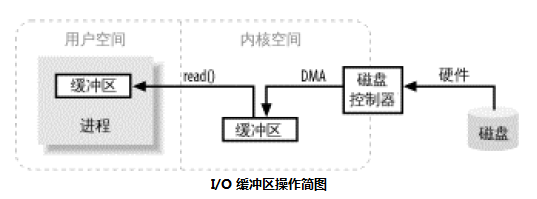
从图中你可能觉得,把数据从内核空间拷贝到用户空间似乎有些多余。为什么不直接让磁盘控制器把数据送到用户空间的缓冲区呢? 首先,硬件通常不能直接访问用户空间。其次,像磁盘这样基于块存储的硬件设备操作的,是固定大小的数据块,而用户进程请求的可能是任意大小的或非对齐的数据块。在数据往来于用户空间与存储设备的过程中,内核负责数据的分解、再组合工作,因此充当着中间人的角色
因此,操作系统是在内存区域中进行 I/O 操作。这些内存区域,就操作系统方面而言,是相连的字节序列,这也意味着 I/O 操作的目标内存区域必须是连续的字节序列。在 JVM 中,字节数组可能不会在内存中连续存储(因为 Java 有 GC 机制),或者无用的存储单元(会被垃圾回收)收集可能随时对其进行的移动
出于这个原因,引入了直接缓冲区的概念。直接缓冲区通常是 I/O操作最好的选择。非直接字节缓冲区(即通过 allocate( )或wrap( )创建的缓冲区)可以被传递给通道,但是这样可能到导致性能损耗。通常非直接缓冲区不可能成为一个 I/O 操作的目标
如果你向一个通道中传递一个非直接 ByteBuffer 对象用于写入。通道可能会在每次调用中隐含的进行下面的操作:
- 创建一个临时的直接 ByteBuffer 对象
- 将非直接缓冲区的内容复制到临时直接缓冲区中
- 使用临时直接缓冲区执行底层 I/O 操作
- 临时直接缓冲区对象离开作用域,并最终成为被回收的无用数据
这个可能导致缓冲区在每一个 I/O 上复制并产生大量对象,而这种事都是我们极力避免的。如果你仅仅为一次使用而创建一个缓冲区,区别并不是很明显。另一方面,如果你将在一段高性能脚本中重复使用缓冲区,分配直接缓冲区并重新使用它们会使你游刃有余
直接缓冲区可能比创建非直接缓冲区要花费更高的成本,它使用的内存是通过调用本地操作系统方面的代码分配的。绕过标准的 JVM 堆栈,不受垃圾回收支配,因为它们位于标准 JVM 堆栈之外
直接 ByteBuffer 是通过调用具有所需容量的 ByteBuffer.allocateDirect( )函数产生的。注意:wrap( )函数所创建的被包装的缓冲区总是非直接的与直接缓冲区相关的 api
public abstract class ByteBuffer extends Buffer implements Comparable {
// This is a partial API listing
public static ByteBuffer allocateDirect (int capacity);
public abstract boolean isDirect();
}◇ 视图缓冲区
I/O 基本上可以归结成字节数据的四处传递,在进行大数据量的 I/O 操作时,很有可能你会使用各种 ByteBuffer 类去读取文件内容,接受来之网络的数据,等等… 。ByteBuffer 类提供了 丰富的 api 来创建视图缓冲区 视图缓冲区通过已存在的缓冲区对象实例的工厂方法来创建。这种视对象维护它自己的属性,容量,位置,上界 和 标记,但是和原来的缓冲区共享数据元素 每一个工厂方法都在原有的 ButeBuffer 对象上创建一个视图缓冲区。调用其中的任何一个方法都会创建对应的缓冲区类型,这个缓冲区是基础缓冲区的一个切分,由基础缓冲区的位置和上界决定,新的缓冲区的容量是字节缓冲区中存在的元素数量除以视图类型中组成一个数据类型的字节数,在切分中任一个超过上界的元素对于这个视图缓冲区都是不可见的。视图缓冲区的第一个元素从创建它的 ByteBuffer 对象的位置开始(position( )函数的返回值) 。来自 ByteBuffer 创建视图缓冲区的工厂方法:
public abstract class ByteBuffer extends Buffer implements Comparable {
// This is a partial API listing
public abstract CharBuffer asCharBuffer();
public abstract ShortBuffer asShortBuffer( );
public abstract IntBuffer asIntBuffer( );
public abstract LongBuffer asLongBuffer( );
public abstract FloatBuffer asFloatBuffer( );
public abstract DoubleBuffer asDoubleBuffer( );
}/**
* 1 char = 2 byte,因此 7 个字节的 ByteBuffer 最终只会产生 capacity 为 3 的 CharBuffer。
*
* 无论何时一个视图缓冲区存取一个 ByteBuffer 的基础字节,这些字节都会根据这个视图缓冲区的字节顺序设
* 定被包装成一个数据元素。当一个视图缓冲区被创建时,视图创建的同时它也继承了基础 ByteBuffer 对象的
* 字节顺序设定,这个视图的字节排序不能再被修改。字节顺序设定决定了这些字节对是怎么样被组合成字符
* 型变量的,这样可以理解为什么 ByteBuffer 有字节顺序的概念了吧。
*/
ByteBuffer byteBuffer = ByteBuffer.allocate (7).order (ByteOrder.BIG_ENDIAN);
CharBuffer charBuffer = byteBuffer.asCharBuffer();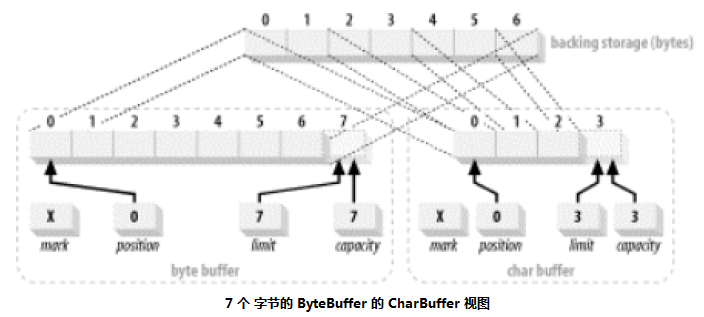
◇ 数据元素视图
ByteBuffer 类为每一种原始数据类型提供了存取和转化的方法:
public abstract class ByteBuffer extends Buffer implements Comparable {
public abstract short getShort( );
public abstract short getShort(int index);
public abstract short getInt( );
public abstract short getInt(int index);
......
public abstract ByteBuffer putShort(short value);
public abstract ByteBuffer putShort(int index, short value);
public abstract ByteBuffer putInt(int value);
public abstract ByteBuffer putInt(int index, int value);
.......
}这些函数从当前位置开始存取 ByteBuffer 的字节数据,就好像一个数据元素被存储在那里一样,根据这个缓冲区的当前的有效的字节顺序,这些字节数据会被排列或打乱成需要的原始数据类型
如果 getInt( )函数被调用,从当前的位置开始的四个字节会被包装成一个 int 类型的变量。然后作为函数的返回值返回。实际上返回值取决于缓冲区的当前的比特排序(byte - order)设置。不同字节顺序取得的是不同的:
// 大端顺序
int value = buffer.order(ByteOrder.BIG_ENDIAN).getInt();
// 小端顺序
int value = buffer.order(ByteOrder.LITTLE_ENDIAN).getInt();
// 上述两种方法取得的 int 是不一样的,因此在调用此类方法前,请确保字节顺序是你所期望的 如果你视图获取的原始类型需要比缓冲区存在的字节数更多的字节,会抛出 BufferUnderflowException 。
参考链接
- Java NIO 系列教程
- http://www.iteye.com/magazines/132-Java-NIO
- Java NIO系列教程(三) Buffer
- http://ifeve.com/buffers/#cap-pos-limit
- java中的float缓冲区FloatBuffer
- http://www.2cto.com/kf/201412/363658.html
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









