






Redis 中的 ZSET(Sorted Set,排序集合)是一种非常重要的数据结构,它结合了集合(Set)和有序列表(List)的特点,能够存储一组 唯一 的元素,并且每个元素关联一个 分数(score)。ZSET 通过分数来对元素进行排序,因此元素在 ZSET 中是按分数升序排列的。
一、ZSET核心特性
ZSET(有序集合)是Redis中一种兼具Set和List特性的数据结构,每个元素关联一个分数(score)用于排序,主要特点包括:
-
唯一成员:成员(member)不可重复
-
分数排序:按score从小到大排序
-
高效操作:
-
插入/删除:O(logN)
-
按score查询:O(logN)
-
按rank查询:O(logN)
-
二、底层实现原理
Redis根据元素数量和大小自动选择两种编码方式:
1. ziplist(压缩列表)
使用条件:
-
元素数量 ≤
zset-max-ziplist-entries(默认128) -
每个元素大小 ≤
zset-max-ziplist-value(默认64字节)
内存布局:
[zlbytes][zltail][zllen][member1][score1][member2][score2]...[zlend]
-
连续内存:所有元素紧凑存储
-
双向遍历:通过zltail可反向遍历
-
自动转换:当不满足条件时转为skiplist
示例:
ZADD prices 10 "apple" 20 "banana" # 小集合使用ziplist
2. skiplist(跳跃表)+ dict
跳表是在一个有序链表的基础上进行扩展的,每个元素除了有一个指向下一个元素的普通指针外,还可能有指向更远节点的额外指针(称为“跳跃指针”)。通过这些跳跃指针,可以大大减少查找的步数,从而提高效率。
跳表的结构:
跳表是由多个层级的链表构成的,每一层链表的元素都和下一层链表的元素有一定的映射关系。
跳表的查找过程:
跳表的插入过程:
跳表的删除过程:
删除元素的过程类似于查找过程,找到元素后,调整跳表中所有层级中相关节点的指针,删除该元素。
跳表的时间复杂度:
跳表的优势:
- 底层链表(Level 0):底层链表包含所有元素,按照顺序排列。
- 上层链表:每个上层链表都包含下层链表的部分元素,且每层链表的元素数量大致减少。元素的选择遵循某种概率规则,通常是每隔一个元素就“跳”到上一层链表。
跳表的特点:
- 多层结构:跳表由多个链表组成,每一层都是一个有序的链表,较高层的链表元素较少。
- 元素的跳跃:通过在较高的层级中跳跃,查找的时间复杂度可以接近于对数级别,而不像传统的链表那样需要线性查找。
- 概率性:跳表的层级是随机决定的,通常通过一定的概率(比如 50% 的概率)决定某个元素是否出现在上一层链表中。
- 从跳表的最高层开始查找,沿着当前层级的指针向右移动,直到找到大于或等于目标值的元素。
- 如果当前元素大于目标值,说明目标元素应该在前面,则沿着当前层级的下一个指针跳到下一层。
- 如果当前元素小于目标值,则继续在同一层级向右移动,直到找到目标元素或者越过目标元素。
- 当到达底层链表时,如果找到目标元素,则返回该元素,否则返回未找到的标志。
- 查找位置:首先使用跳表的查找过程,找到合适的位置。
- 随机决定层数:插入时,需要为新元素随机决定它在各层中出现的层数。常见的做法是每次插入时,随机选择一个概率(如 50%)决定是否将元素添加到上一层链表中。
- 插入新节点:按照查找的结果,在合适的层中插入新元素,同时调整相关指针。
- 查找操作:跳表的查找时间复杂度为 O(log N),其中 N 是跳表中元素的个数。由于每一层都缩小了查找的范围,查找的效率非常高。
- 插入操作:插入操作的时间复杂度也是 O(log N),需要查找插入位置并随机决定新元素的层数。
- 删除操作:删除操作同样是 O(log N),只需找到要删除的元素并修改相关指针。
- 动态性强:跳表可以动态地进行增删改查操作,适应性较强。
- 空间效率高:由于跳表的多层链表是按需生成的,并且只有在查找、插入时才会创建新的层,因此空间开销较小。
- 易于实现:跳表相比于平衡二叉搜索树(如 AVL 树、红黑树)实现起来更加简单。
L3: head -------------------------------------------> nil L2: head ------------> 4 ------------> 7 -----------> nil L1: head ---> 2 ---> 4 ---> 5 ---> 7 ---> 9 ---> nil L0: head->1->2->3->4->5->6->7->8->9->nil
三、ziplist实现细节
1. 内存优化技术
-
变长编码:
-
字符串长度用1/2/5字节表示
-
整数用特殊编码(如6位存储0-63)
-
-
相邻score压缩:差值存储减少内存占用
2. 操作复杂度
| 操作 | 复杂度 | 说明 |
|---|---|---|
| 插入 | O(N) | 需要内存重分配 |
| 查找 | O(N) | 顺序遍历 |
| 删除 | O(N) | 需要内存移动 |
优势:内存利用率高(无指针开销)
劣势:大数据量时性能下降明显
四、skiplist实现细节
1. 跳跃表节点结构
typedef struct zskiplistNode {
sds member; // 成员字符串
double score; // 分数
struct zskiplistNode *backward; // 后退指针
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned long span; // 跨度
} level[]; // 柔性数组,层级随机生成
} zskiplistNode;
2. 关键算法
层级生成算法:
int zslRandomLevel(void) {
int level = 1;
// 每增加一层的概率为25%
while ((random()&0xFFFF) < (0.25 * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
查找过程:
查找score=6.5的路径: 1. 从L3(head) -> nil (6.5 < ∞) 2. 降级到L2(head) -> 4 -> nil (6.5 > 4) 3. 从节点4的L1 -> 7 -> nil (6.5 < 7) 4. 降级到节点4的L0 -> 5 -> 6 -> 7 (找到6.5的插入位置)
3. 性能分析
| 操作 | 平均复杂度 | 最坏复杂度 |
|---|---|---|
| 插入 | O(logN) | O(N) |
| 删除 | O(logN) | O(N) |
| 查询 | O(logN) | O(N) |
| 范围 | O(logN+M) | O(N) |
五、ZSET典型命令实现
1. ZADD命令流程
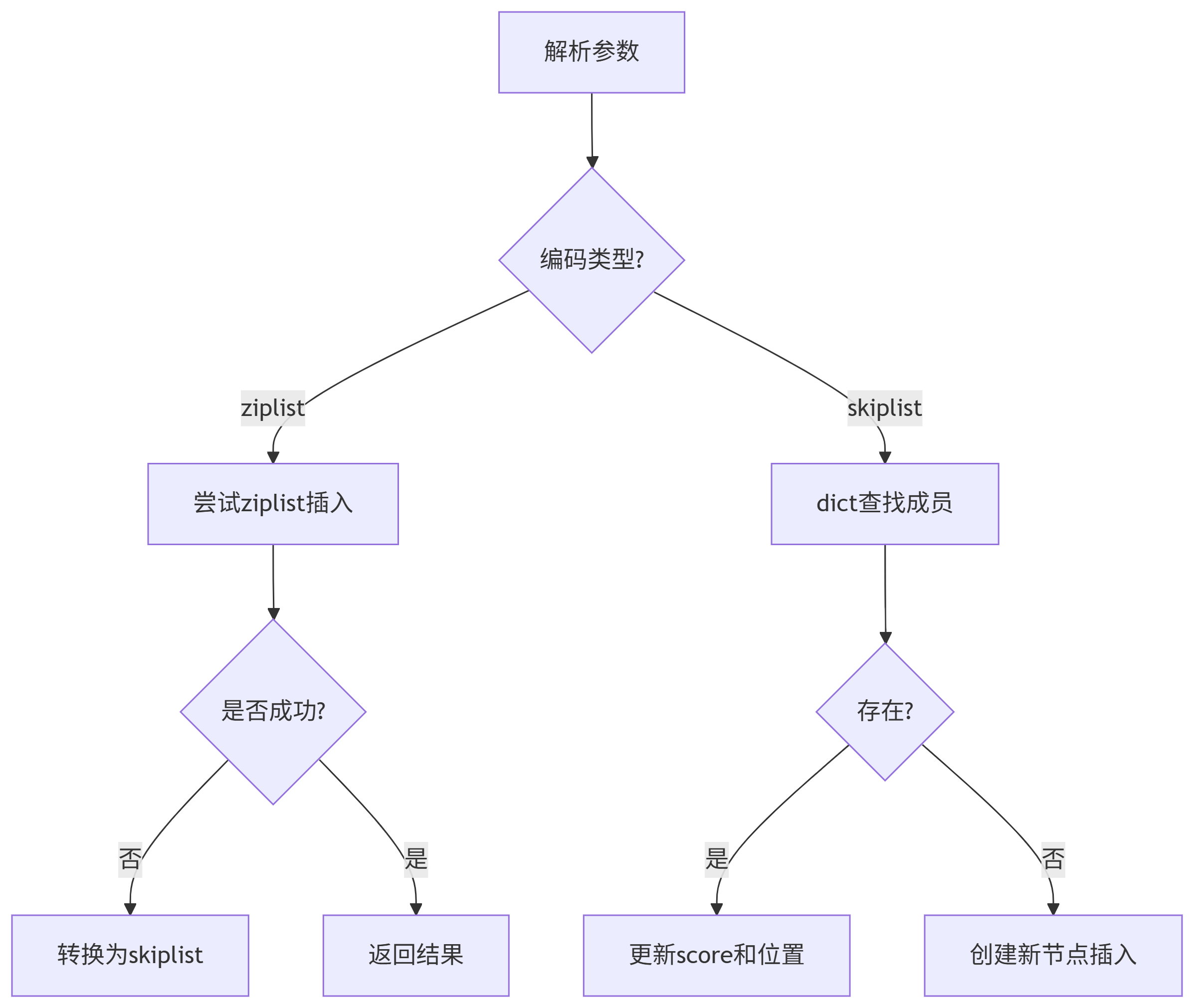
2. ZRANGEBYSCORE实现
// 伪代码实现
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range) {
// 1. 找到第一个≥min的节点
// 2. 检查是否≤max
// 3. 返回满足条件的首节点
}
void zslRangeByScore(zskiplist *zsl, zrangespec *range) {
node = zslFirstInRange(zsl, range);
while(node && node->score <= range->max) {
addToReply(node);
node = node->level[0].forward;
}
}
六、应用场景与优化
1. 典型使用场景
-
排行榜:
ZADD leaderboard 100 "user1" 200 "user2" ZREVRANGE leaderboard 0 9 WITHSCORES
-
延迟队列:
ZADD delays 1651234567 "task1" ZRANGEBYSCORE delays 0 $(date +%s) LIMIT 0 1
-
时间序列:
ZADD temperatures:2023 25.3 "2023-06-01T12:00" 26.1 "2023-06-01T13:00"
-
推荐系统: 可以用 ZSET 来存储用户对商品、内容的评分,通过分数来排序,进而实现个性化推荐。
2. 性能优化建议
-
合理设置阈值:
config set zset-max-ziplist-entries 256 config set zset-max-ziplist-value 128
-
避免大ZSET:超过10万成员考虑分片
-
分数设计:使用整数分数可提升比较效率
Redis的ZSET通过智能切换ziplist和skiplist两种实现,在内存效率和查询性能之间取得了完美平衡。理解其底层原理有助于开发者根据实际场景做出最优设计决策。
七:跳表和B+树的对比
跳表(Skip List)和 B+ 树是两种常见的有序数据结构,它们在许多方面具有相似性,但也有显著的差异。以下是它们的对比:
1. 基本结构
-
跳表:跳表是一种基于链表的数据结构,通过在基础链表上增加多层指针来提高查询效率。每一层链表包含部分元素,上一层的元素大多是下一层元素的副本,形成一种“跳跃”机制,使得查找可以通过多层次的跳跃快速定位目标。
-
B+ 树:B+ 树是一种自平衡的树形数据结构,通常用于数据库和文件系统的索引。B+ 树是一种多路平衡查找树,每个节点可以包含多个子节点,它保证了数据的有序性,并且所有的值都存储在叶子节点中,内部节点仅用于导航。
2. 时间复杂度
-
跳表:
- 查找:平均 O(log N),最坏情况下也是 O(log N)。
- 插入:平均 O(log N),最坏情况下也是 O(log N)。
- 删除:平均 O(log N),最坏情况下也是 O(log N)。
-
B+ 树:
- 查找: O(log N)。
- 插入: O(log N)(需要进行分裂操作,保持树的平衡)。
- 删除: O(log N)(删除后可能需要进行合并操作)。
在理论上,跳表和 B+ 树的查找、插入、删除操作的时间复杂度都是 O(log N)。
3. 数据存储
-
跳表:跳表是基于链表实现的,它将元素分布在不同的层级中,每一层的链表指向下一个层级的元素,直到底层。跳表的所有元素都分布在各层链表中,并且每个节点都可能有多个指针指向不同的后续元素。
-
B+ 树:B+ 树的元素只存储在叶子节点中,内部节点只包含索引和导航信息,所有的叶子节点通过链表连接起来,便于范围查询。B+ 树的叶子节点是一个双向链表,允许顺序遍历。
4. 空间开销
-
跳表:跳表需要额外的空间来存储每一层的指针。每个元素可能出现在多层,因此跳表的空间复杂度比链表稍高,但与 B+ 树相比,跳表的空间效率通常较低。
-
B+ 树:B+ 树的空间开销相对较低,因为它只需要存储叶子节点中的数据和内部节点中的索引信息。B+ 树的内部节点只有索引,没有数据,因此占用的空间相对较小。
5. 查询效率
-
跳表:跳表适用于动态数据量频繁变化的场景,如数据量较小或者频繁进行插入和删除操作时。跳表由于是随机层级构建,查询效率较为稳定,但其查询速度相较于 B+ 树略有不确定性,尤其是在元素较多时。
-
B+ 树:B+ 树特别适合于磁盘存储或大规模数据查询的场景,因为它的高度通常较小,且通过顺序访问叶子节点来提高数据的扫描速度。B+ 树特别适用于需要范围查询(如区间查找)和按顺序访问的场景。
6. 插入和删除
-
跳表:跳表的插入和删除操作相对简单。每次插入时,元素会在随机层级上插入,可能需要调整多个指针。删除时也只需简单地修改指针。因为跳表是基于链表的,节点可以灵活地调整,不需要进行树的旋转或平衡操作。
-
B+ 树:B+ 树的插入和删除需要保持树的平衡。在插入时,如果某个节点满了,需要进行分裂操作;在删除时,可能需要进行合并操作,保持树的平衡。B+ 树的这种操作相对复杂,但在大规模数据存储中,平衡机制可以保证查询性能。
7. 应用场景
-
跳表:跳表的优势在于实现简单、动态性能好,适用于内存中存储的数据结构。它通常用于需要高频更新的应用场景,如内存数据库、缓存系统等。
-
B+ 树:B+ 树广泛应用于数据库索引和文件系统中。由于 B+ 树的结构非常适合磁盘存储,并且能够高效地支持范围查询和顺序遍历,它是很多数据库系统(如 MySQL、SQLite)和文件系统(如 NTFS、HFS+)中常用的索引结构。
8. 适用性
-
跳表:跳表适用于内存中的数据结构,对于动态变化、频繁插入删除的场景非常适合。它的实现比 B+ 树更简单,但在大规模磁盘存储中的表现不如 B+ 树稳定。
-
B+ 树:B+ 树适用于大规模数据存储,尤其是磁盘存储系统中。它在磁盘存储优化和范围查询方面的优势非常明显,尤其是在数据库系统中,B+ 树可以高效地管理大量数据并进行快速查询。
总结对比:
| 特性 | 跳表 | B+ 树 |
|---|---|---|
| 结构 | 多层链表 | 多路自平衡树 |
| 查询复杂度 | O(log N) | O(log N) |
| 插入/删除复杂度 | O(log N) | O(log N) |
| 空间开销 | 较高(需要存储多个指针) | 较低(只在叶子节点存储数据) |
| 数据存储方式 | 数据存储在各层链表中 | 数据存储在叶子节点,内部节点仅存索引 |
| 应用场景 | 内存数据库、缓存系统 | 数据库索引、文件系统、范围查询 |
| 实现复杂度 | 较简单 | 较复杂(需要保证平衡) |
结论:
- 如果应用需要动态数据操作(如频繁插入、删除),且数据量不大,跳表是一个不错的选择,因为它实现简单且灵活。
- 如果应用需要高效的磁盘存储、范围查询和顺序遍历,并且数据量较大,B+ 树是更合适的选择,尤其是在数据库和文件系统中。

















 3135
3135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









