









tips:软件翻译有差距,仍需看原文文档。
Abstract
大量关于恶意软件攻击的威胁情报信息以分散的(通常是非结构化的)格式提供。知识图谱(KG)可以使用由实体和关系表示的RDF三元组来捕获这些信息及其上下文。然而,稀疏或不准确的威胁信息会导致诸如不完整或错误的三元组等挑战。用于填充KG的命名实体识别(NER)和关系提取(RE)模型不能完全保证准确的信息检索,进一步加剧了这一问题。本文提出了一种端到端的方法来生成恶意软件知识图谱MalKG,这是第一个针对恶意软件威胁情报的开源自动化KG。MalKG数据集MT40K包含27, 354个唯一实体和34个关系生成的大约40, 000个三元组。我们展示了MalKG在预测KG中缺失的恶意软件威胁情报信息方面的应用。对于基本事实,我们手工绘制了一个名为MT3K的KG,其中3, 027个三元组来自5741个唯一实体和22个关系。对于基于最先进的实体预测模型( TuckER )的实体预测,我们的方法在hits@10度量(预测KG中缺失实体的前10个选项)上达到了80.4,在MRR (平均倒数秩)上达到了0.75。我们还提出了一个框架,从1100份恶意软件威胁情报报告和公共漏洞和暴露( CVE )数据库中,在句子级别上自动和手动地将数以千计的实体和关系抽取为RDF三元组。
1. Introduction
恶意软件威胁情报告知安全分析人员和研究人员关于趋势化的攻击和防御机制。他们利用这些情报帮助自己在日益复杂的工作中发现零日攻击、保护知识产权、防止对手入侵。这些信息是丰富的;然而,它通常以非标准和非结构化的格式存在。此外,信息并不总是准确或完整的。例如,最近针对SolarWinds软件的攻击威胁报告对将Sunburst恶意软件插入SolarWinds的Orion软件进行了详细分析。随着更多信息的披露,时间线在随后的报告中发生了变化。然而,尽管Sunburst恶意软件和与Turla高级持续性威胁( Turla Advanced Persistent Threat,APT )组链接的后门有相似之处,但没有关于威胁行为者的信息。KG可以使攻击者识别这种缺失的信息。
安全威胁研究人员的一个主要目标是在尽可能少的人工参与的情况下实现威胁检测和预防的自动化。人工智能技术,加上关于威胁的大数据,在很大程度上有潜力实现这一点。互联网上越来越多的威胁信息源,如分析报告、博客、常见漏洞和暴露数据库( CVE、NVD),提供了足够的数据来评估当前的威胁状况,并为未来的防御做好准备。将这种大多是非结构化的数据结构化并将其转换为可用的格式只解决了一个问题。它忽略了捕获威胁信息的上下文,这可以显著提高威胁情报。然而,在这一步骤之前需要解决几个挑战,例如:( a )缺乏收集数据和上下文的标准化数据聚合格式,( b )数据提取模型的限制导致收集的攻击信息不完整,( b )数据提取模型的局限性导致收集到的攻击信息不完整,( c )从威胁信息中提取的数据不准确。在本文中,我们解决了前两个挑战。解决源信息可信性的第三个挑战留待未来工作。
可以认为,CVE, NVD等数据源,以及结构化威胁信息表达( Structured Threat Information Expression,STIX )等标准,可以有效地自动聚合威胁和漏洞数据。然而,这些数据源和标准忽略了上下文的重要性,而上下文可以通过链接和语义元数据进行添加。文本数据并非单纯的词语聚合。信息是有意义的,概念与外部来源的联系对其有效利用至关重要。例如,人类安全分析家能够正确理解威胁报告中"Aurora"一词的含义。它是指2009年谷歌首次检测到的由中国实施的高级持续性威胁( Advanced Persistent Threats,APTs )系列网络攻击。然而,收集这些信息的计算机或人工智能模型可能会将其误认为北极光,除非提供安全上下文。
KG通过添加上下文以及允许对数据进行推理来弥合这一鸿沟。知识图谱的最小单元称为RDF三元组,由使用实体和关系的数据实例组成。实体捕获现实世界的对象、事件、抽象概念和事实。例如,实体代表了网络安全领域的恶意软件、组织、漏洞和恶意软件行为特征。关系通过描述实体之间关系的关键短语将实体联系起来。具体来说,在恶意软件威胁情报中使用KG添加上下文带来了许多机会:
- 实体预测:从知识图谱中预测缺失的实体。给定一个恶意软件KG,补全缺失的信息如恶意软件作者、漏洞等。对于一个不完整的三元组<multi-homed windows systems, hasVulnerability, ?>,实体预测将返回一个有序的实体集合,例如{spoofed route pointer, multiple eval injection vulnerability, heap overflow}。在这种情况下,spoofed route pointer对于不完全三元组是正确的尾部实体。
- 实体分类:判断一个实体的类别标签是否准确。例如,正确判定spoofed route pointer就是class: Vulnerability的一个实例。
- 实体解析:判断两个实体是否指代同一个对象。例如,Operation AppleJeus和Operation AppleJeus Sequel可能具有类似的属性。然而,它们是不同的恶意软件活动,不应该被解析到同一个实体。
- 三元组分类:验证恶意软件威胁情报KF中的RDF三元组是否被准确分类。例如,< ZeroCleare, targets, Energy Sector In The Middle-East>应归为正确三元组,<ZeroCleare, targets, Energy Sector In Russia>应归为错误三元组。
MalKG包含丰富的信息,可以被统计学习系统利用。例如,在MalKG中,低维嵌入向量空间可以表示实体,矩阵可以表示关系。因此,实体和关系可以通过各种方法嵌入到机器可读的形式中,便于自动分析和推理。
动机:在上一节描述的实例中,KG补全会预测缺失的头部实体,即’Aurora Botnet’恶意软件的作者。MalKG的完备性主要取决于两个因素:( 1 )威胁报告中的可用信息;( 2 ) NER和RE模型的有效性。实体预测是根据存储在KG中的已有信息预测缺失实体的最佳候选对象或推断新事实的任务。使用恶意软件威胁情报本体的基于规则的推理控制哪些头尾实体类可以形成关系。本文提出了基于TuckER实体识别模型的实体预测。我们还比较和对比了在其他领域的数据集上表现良好的实体预测模型的性能。特别是基于翻译的嵌入模型,以及张量分解模型。其他模型在特定数据集上表现良好,但没有完全表达MalKG的一些性质,如实体间的一对多关系,不包括逆关系,以及极少数对称关系的实例。
网络安全情报是一个广泛的领域,在一个KG中表示这个领域是一项巨大的工作。因此,在本研究中我们专注于恶意软件威胁情报并研究恶意软件实例来说明工作。尽管如此,挑战和方法足够广泛,可以应用于安全领域的其他领域。我们的MalKG是从从互联网收集的恶意软件威胁情报报告中实例化得到的。我们从CVE漏洞描述数据库中权标化约1100条PDF格式的威胁报告中提取涵盖恶意软件威胁情报的实体。实例化过程在下文描述,包括NER和RE算法。NER和RE算法一起被部署和自动化,以生成数以千计的RDF三元组,将恶意软件威胁信息捕获到KG的单元中。我们还讨论了在这一过程中遇到的挑战。具体来说,本文的主要贡献有:
- 我们提出了一个端到端的、自动化的、本体定义的恶意软件威胁情报KG生成框架。从1100份威胁报告和以非结构化文本格式编写的CVE漏洞描述中提取了40000个三元组。这些三元组创建了第一个开源知识图谱,用于提取1999年以来近千个恶意软件的结构化和上下文相关恶意软件威胁情报。
- 使用基于张量分解的模型将三元组编码为向量嵌入,可以从图中提取潜在信息并发现隐藏信息。这对于网络安全分析人员来说是一个至关重要的目标,因为在向量嵌入上运行机器学习模型可以为自主入侵检测系统产生更准确和上下文相关的预测。
- 我们提供了一个真实数据集MT3K,该数据集包括5, 741个手工标注的实体及其类、22个关系和3, 027个三元组,从2006 - 2019年间撰写的81份非结构化威胁报告中提取。安全专家对这一数据进行了验证,对于训练用于恶意软件威胁情报的更大知识图谱的自动化过程非常有价值。
- 我们采用了一种先进的实体和关系抽取模型到网络安全领域,并将默认的语义分类映射到恶意软件本体。我们还确保了模型在不影响精度的情况下,能够扩展到威胁语料的规模。
- 针对知识图谱中存在缺失信息(或实体)的MalKG,我们通过在MalKG的其他三元组中寻找语义和句法相似度,证明了使用准确学习和预测缺失信息的嵌入模型进行实体补全的有效性。
- MalKG是开源的,与文本语料库、三元组、实体一起,为新颖的情境安全研究问题提供了新的基准框架。
2. Background
2.1 Definitions
MalKG将异构多模态数据表示为有向图,MalKG = { E,R,T },其中E、R和T分别表示实体、关系和三元组(也叫事实)的集合。每个三元组 < e h e a d , r , e t a i l > ∈ T <e_{head},r,e_{tail}>∈T <ehead,r,etail>∈T表示 e h e a d ∈ E e_{head}∈E ehead∈E和 e t a i l ∈ E e_{tail}∈E etail∈E之间存在一个关系 r ∈ R r∈R r∈R。对于实体和关系 e h e a d , e t a i l , r e_{head},e_{tail},r ehead,etail,r我们分别用粗体h,t,r表示它们的低维嵌入向量。我们用 d e d_e de和 d r d_r dr分别表示实体和关系的嵌入维数。符号 n e , n r , n t n_e, n_r, n_t ne,nr,nt分别表示KG中实体、关系和三元组的个数。我们对每个三元组<h,r,t>的得分函数使用 f ϕ f_{\phi} fϕ符号。打分函数是根据平移距离或语义相似度来衡量一个事实在T中的合理性。表1列出了记号的摘要。

2.2 Malware Knowledge Graph (MalKG)
KG利用实体及其之间的关系以三元组的形式存储大量领域特定信息。近十年来出现了Freebase、Google的Knowledge Graph、WordNet等通用目的知识图谱。它们通过计算机可解释的语义结构化信息来增强"大数据"结果,而这一特性被认为是构建更智能机器所不可或缺的。没有开源的恶意软件知识图谱存在,因此,在本研究中,我们提出了第一个自动生成的恶意软件威胁智能知识图谱。
MalKG的生成过程采用精选和自动化非结构化数据相结合的方式来填充KG。这帮助我们实现了精确方法的高精度和自动化方法的高效性。MalKG是利用现有本体构建的,因为它们为MalKG的生成提供了一个结构,并考虑到了可实现的最终目标。本体是使用能力问题构建的,为系统地识别语义类别(称为类)和属性(也叫关系)铺平了道路。本体还避免了冗余三元组的生成,加速了三元组的生成过程。
MalKG由分层实体组成。例如,恶意软件类可以有TrojanHorse和Virus等子类。层次结构根据恶意软件如何传播和感染计算机来捕获恶意软件的类别。另一方面,MalKG中的关系并不具有等级性。例如,一个名为WickedRose的病毒(恶意软件的子类)利用Microsoft PowerPoint漏洞并安装恶意代码。这里的"漏洞利用"是实体Virus (子类)和Software之间的关系,因此不需要子关系来描述不同类别的漏洞利用。MalKG以三元组的形式存储类似的事实。
2.3 Information Prediction
考虑一个来自MalKG的不完全三元组<Adobe Flash Player,hasVulnerability,?>。KG补全将预测其缺失的尾部t,即" Adobe Flash Player "软件的漏洞。MalKG可以从一个不完整的三元组中预测缺失实体,形成最小的恶意软件威胁情报单元。在KG的构建过程中,三元组可能存在头或尾的缺失。知识图谱补全,有时也称为实体预测,是为缺失实体预测最佳候选实体的任务。它还根据KG表示的现有信息,通过推断新的事实来预测实体。形式上,实体预测的任务是预测给定<?,r,t>的h或给定<h,r,?>的t的值,其中’ ? '表示缺失的实体。
2.4 MalKG Vector Embedding
MalKG的三元组由一个相对较低的(例如, 50)维向量空间嵌入[ 2、36、39、42、43]表示,不会丢失结构信息和保留关键特征。我们为MalKG中的所有三元组构造嵌入,其中每个三元组有三个向量 e 1 , r , e 2 ∈ R d e1,r,e2∈R^d e1,r,e2∈Rd且实体是分层的。因此,为了缩小嵌入模型的选择范围,我们保证嵌入模型满足以下要求:
-
一个嵌入模型必须具有足够的表达能力来处理不同类型的关系(相对于所有边都是等价的一般图而言)。它应该为共享相同关系的三元组创建单独的嵌入。具体来说,一个三元组<e1,hasVulnerability,e3>的嵌入,其中 e 1 ∈ c l a s s : D e v e l o p T a r g e t e1∈class:Develop Target e1∈class:DevelopTarget应该不同于一个三元组<e2,hasVulnerability,e3>的嵌入,其中 e 2 ∈ c l a s s : S o f t w a r e e2∈class:Software e2∈class:Software。
-
嵌入模型还应该能够为一个实体在涉及不同类型关系时创建不同的嵌入。这一要求确保了创建具有1对n,n对1和n对n关系的三元组的嵌入。例如,一个直白而富有表现力的模型TransE在处理1对n、n对1、n对n关系时存在缺陷。DUSTMAN和ZeroCleare恶意软件的嵌入非常相似,因为它们都涉及TDL文件,虽然它们是两个独立的实体,应该有单独的嵌入。
-
属于同一类的实体应该在嵌入空间中投影在同一个邻域内。该要求允许在预测未标记实体(这个任务被称为实体分类)的类标签时使用嵌入的邻域信息。
2.5 Challenges in MalKG Construction
从海量的威胁报告中生成三元组并不是一项简单的任务,而且与小规模的基准数据集不同,人工标注过程对于大量数据来说是不可复制和可扩展的。需要解决的一些挑战是:
(a)恶意软件威胁报告以非结构化文本的形式涵盖了恶意软件攻击的技术和社会层面。这些用于描述恶意软件威胁情报的报告没有标准化的格式。因此,从原始文本中提取的信息包含噪声和其他复杂信息,如代码段、图像、表格等。
(b)威胁报告既包含通用信息,也包含领域特定信息。使用在通用数据集或特定领域(如健康)上训练的NER模型不能用于网络安全威胁报告。此外,领域特定的概念有时会有标题误导NER模型将其归类为泛型概念。例如,当一个CVE描述提到"Yosemite backup 8.7 "时,它指的是Yosemite服务器备份软件,而不是加州的国家公园。
(c)实体抽取有时会导致同一概念的多次分类。例如,SetExpan可能对与输入种子语义类相似的已标注实体进行分类。例如,实体" Linux "既被归类为软件,也被归类为漏洞。
(d)DocRED等关系抽取方法在医学数据集上进行训练且文档稀疏。源代码中专门为样本数据工作的硬编码变量使其重用具有挑战性。然而,我们将其推广到针对恶意软件威胁情报实体。文献[ 44 ]中另一个至关重要的方面是内存需求随着给定文档中实体数量的指数增长。
(e)实体提取模型 [1,5,29] 定义的语义分类器与恶意软件威胁情报域所需的语义分类器不同,因此不能直接应用。
3 MalKG: System Architecture
如图 1 所示,我们提出的恶意软件 KG 构建框架的输入包括一个训练语料库和一个现有的本体(例如 [28]),该本体具有为 MalKG 提供结构的类和关系。训练语料库包含从 Internet 收集的恶意软件威胁情报报告、使用本体对这些报告中的实体和关系的手动注释以及 CVE 漏洞数据库。训练语料库和本体类被馈送到实体提取器(如 SetExpan)中,以提供来自非结构化恶意软件报告的实体实例。关系提取模型使用这些实体实例和本体关系作为输入,并预测实体对之间的关系。实体对和相应的关系称为三元组,它们形成初始KG。我们使用基于张量分解的方法TuckER来创建向量嵌入来预测缺失的实体,并获得带有完整RDF三元组的MalKG的最终版本。
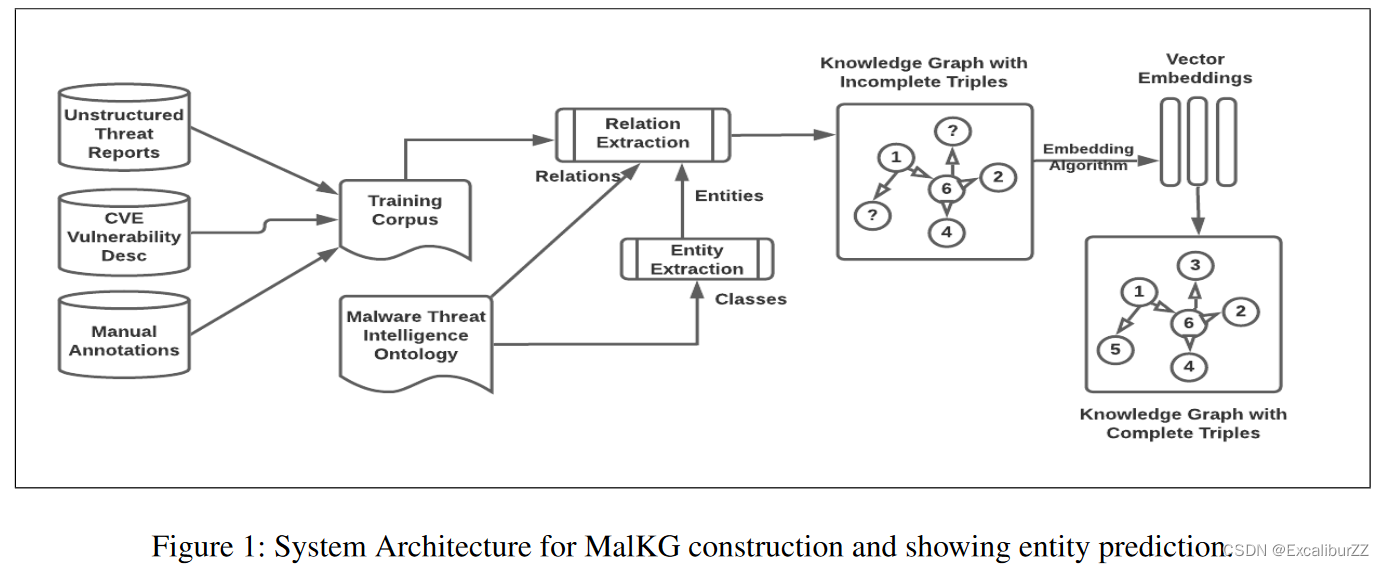
3.1 Generating Contextual and Structured Information
本节介绍从非结构化数据生成上下文和结构化恶意软件威胁信息的过程。
语料库——可以调查威胁报告、博客、威胁公告、推文和反向工程代码,以收集有关恶意软件特征的详细信息。我们的工作依靠威胁报告来捕获有关恶意软件攻击的详细帐户和 CVE 漏洞描述的信息。安全组织发布有关网络犯罪分子如何滥用各种软件和硬件平台以及安全工具的深入信息。有关 Backdoor.Winnti 恶意软件系列的威胁报告摘录,请参见图 2。从威胁报告语料库中收集的信息包括漏洞、受影响的平台、作案手法、攻击者、首次发现攻击以及入侵指标等事实。这些报告可作为其他安全分析师的研究材料,这些分析师获取基本信息来研究和分析恶意软件样本、对手技术、了解利用的零日漏洞等等。但是,并非所有报告都是一致、准确或全面的。聚合来自这些威胁报告的价值数据,以整合有关给定恶意软件的所有知识,并在威胁事件研究(例如,调查误报事件)期间获取此信息是一个重要的研究目标。

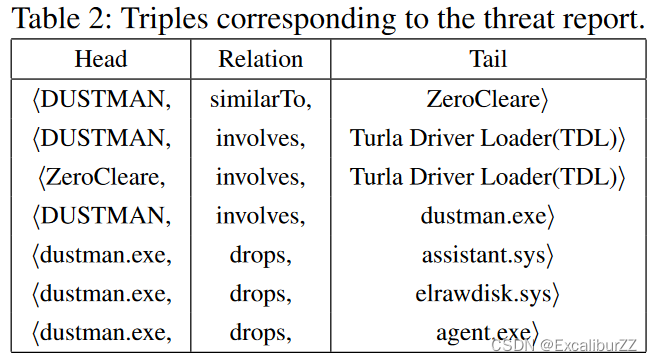
情境化——MalKG以三元组方式捕获威胁信息,这是KG中最小的信息单位。例如,考虑威胁报告中的以下片段:
“… DUSTMAN can be considered as a new variant of ZeroCleare malware … both DUSTMAN and ZeroCleare utilized a skeleton of the modified “Turla Driver Loader (TDL)” … The malware executable file “dustman.exe” is not the actual wiper , however , it contains all the needed resources and drops three other files [assistant.sys, elrawdisk.sys, agent.exe] upon execution…”
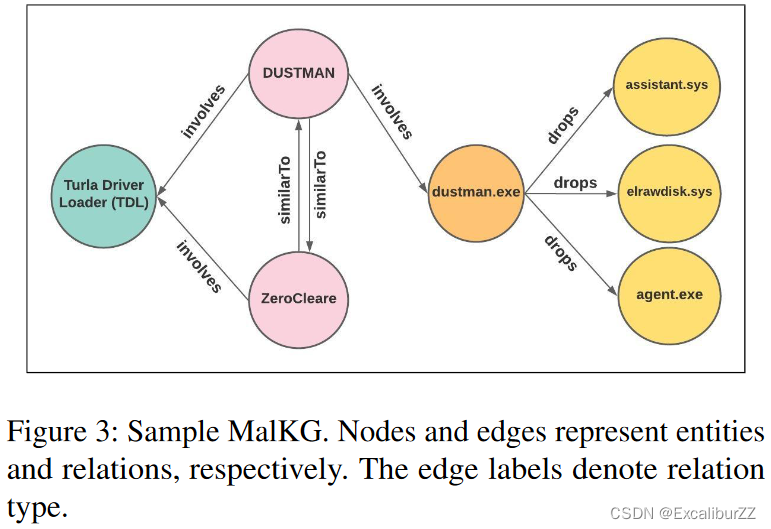
表 2 显示了从此文本生成的一组三元组。许多这样的三元组共同构成了恶意软件KG,其中实体和关系分别对节点和有向边缘进行建模。图 3 显示了文本中的示例KG。
实例化本体——MalKG中的每个实体都有一个唯一的标识符,该标识符捕获来源信息,包括对三元组威胁源的引用。对于MalKG,此来源信息包含从中提取威胁报告的唯一标识符或唯一的 CVE ID。
信息抽取——遵循恶意软件威胁情报的本体,我们通过手动注释威胁报告创建了基本事实三元组。我们生成了 MT3K,这是一个使用手动注释的三元组用于恶意软件威胁情报的KG。虽然这是创建基本事实的重要步骤,但手动注释方法有几个局限性,但对于测试大规模模型非常宝贵。
推理引擎——我们使用 MALOnt [28] 和恶意软件本体 [34] 中定义的类和关系从非结构化文本中提取三元组。虽然使用本体不是实例化 MalKG 的唯一方法,但它可以将来自多个来源的不同数据映射到共享结构中,并使用规则在该结构中维护逻辑。本体使用通用词汇,可以促进该数据的收集、聚合和分析[24]。例如,MALOnt 中有名为“Malware”和“Location”的类。根据 MALOnt 中指定的关系,恶意软件类的实体可以与另一个恶意软件类实体具有“类似”的关系。但由于规则引擎,Malware类永远不能与Location类的实体相关。
KG包含实体之间的 1 对 1、1 对 n、n 对 1 和 n 对 n 关系。实体级别的 1 到 n 关系意味着KG中对于特定的头部和关系对有多个正确的尾部。在图 3 中,实体“dustman.exe”是恶意软件文件的一个实例。它会删除三个不同的文件。实体DUSTMAN和ZeroCleare都涉及Turla Driver Loader (TDL)文件,并详细说明KG中 n 对 1 的关系如何存在; n 对 n 的工作方式类似。
3.2 Predicting Missing Information
KG补全可以在有关恶意软件威胁的信息(实体和关系)稀少时,根据 MalKG 中的现有三元组推断缺失的事实。对于MalKG,我们通过TuckER和TransH演示了实体预测。使用如FB15K, FB15k237, WN18,WN18RR等标准数据集与其他模型进行比较,为其他更精细的模型建立基线。然而,用于比较的数据集与我们的MT3KG和MT40K三组数据集截然不同。下面的协议描述了恶意软件KG中缺失实体的预测:
-
对于测试集中的每个三元组,头实体 h 将替换为KG中的所有其他实体。这将生成一组候选三元组,以与每个真正的测试三元组进行比较。此步骤称为损坏测试三元组的头部,生成的三元组称为损坏的三元组。
-
计算每个真实测试三元组及其相应的损坏三元组的相异性分数 f ϕ ( h , r , t ) f_{\phi}(h, r,t) fϕ(h,r,t)。分数按升序排序,以确定有序集合中真实测试三元组的排名。该排名评估模型在预测给定的头部<?, relation, tail>方面的性能。较高的排名表示模型在学习实体和关系的嵌入方面的效率。
-
对尾实体 t 重复前两个步骤,并存储真正的测试三元组排名。该排名评估模型在预测给定 <h、r、t> 的缺失 t 方面的性能。
-
Mean Rank、Mean Reciprocal Rank(MRR)和Hits@n是文献中使用的常规指标,根据所有真实测试三元组的秩计算得出。平均排名表示所有真实测试三元组的平均排名。当单个测试三元组的排名较差时,平均排名会受到显著影响。最近的文献报告了更稳健的估计的平均倒数排名(MRR)。它是所有真实测试三元组的秩倒数的平均值。Hits@n表示排名前 n 位的真实测试三元组的比率。比较嵌入模型时,Mean Rank越小,MRR 和 Hits@n 值较大表示模型越好。我们报告了各种张量分解和基于翻译的模型的MRR和Hits@n的结果。
4 Experimental Evaluation
本节介绍KG完成的实验设置、结果和实现细节。
4.1 Datasets
恶意软件威胁情报语料库由威胁报告和CVE漏洞描述组成。威胁报告是在2006-2021年间编写的,所有CVE漏洞描述都是在1990-2021年间创建的。我们对初始语料库数据执行了几个预处理步骤。我们为每个单独的文档和 CVE 描述提供唯一的标识符。从每个文档中提取单个句子并分配一个句子ID。 文档和句子的识别还为可信度,上下文实体分类和关系提取的未来工作提供了来源。我们使用spaCy默认tokenizer库将纯文本句子标记化并解析为具有开始和结束位置的单词,并按顺序为每个文档保存它们。
4.2 Manually Curated Triples: MT3K
MT3K 数据集是由我们的研究团队手动注释并由安全专家验证的 5741 个三元组的集合。使用Brat注释工具对81份威胁报告进行了注释(见图4)。在图 4 中,“PowerPoint file”和“installs malicious code”分别标记为“Software”和“Vulnerability”类。从“Software”到“Vulnerability”的箭头表示它们之间具有 hasVulnerability的语义关系。注释遵循恶意软件威胁本体中定义的规则[28,34]。恶意软件威胁情报本体中定义了 22 种其他关系类型 (NR)。

MT3K数据集作为基准数据集,用于使用我们的三元组自动生成自动化方法评估恶意软件威胁情报。其他三元组数据集如FB15K、FB15K-237、WN18和WN18RR已被用于评估通用KG及其应用的性能,例如链接预测和KG补全。但是,没有用于恶意软件威胁情报的开源KG,因此不存在用于恶意软件 KG 评估的三元组。我们希望MT3K和MT40K能够作为未来安全研究的基准数据集。
4.3 Automated Dataset: MT40K
MT40K 数据集是由 27, 354 个唯一实体和 34 个关系生成的 40, 000 个三元组的集合。该语料库包含大约 1, 100 份在 2006-2021 年间编写的去识别化纯文本威胁报告,以及 1990 年至 2021 年间创建的所有 CVE 漏洞描述。带注释的关键短语被分类为派生自恶意软件威胁本体中定义的语义类别的实体。在实体之间形成关系时应用推理规则引擎以生成用于构建 MalKG 的三元组。
我们的信息提取框架包括实体抽取和关系提取,并以网络安全领域要求为基础。该框架将威胁报告的纯文本和原始 CVE 漏洞描述作为输入。它查找和分类文本中的原子元素(提及),这些元素属于预定义的类别,例如攻击者、漏洞等。我们拆分了实体提取和识别的任务。实体提取 (EE) 步骤结合了最先进的实体提取技术。实体分类 (EC) 步骤解决了分类为多个语义类别的实体的消除歧义,并且根据经验学习的算法仅分配一个类别。将EE和EC获得的结果结合起来,得出最终的提取结果。下一节将提供详细信息。
4.3.1 Entity Extraction (EE)
我们将标记化单词的提取分为两类:领域特定的关键短语提取和通用关键短语提取(class:Location)。特定于网络安全领域的EE任务进一步细分为事实关键短语提取(class:Malware)和上下文关键字提取(class:Vulnerability)。我们使用精确率和召回率测量作为评估标准,以缩小不同类别的EE模型。具体来说,Flair框架给出了高精度分数(0.88-0.98),用于对通用和事实领域特定的关键短语进行分类,例如:Person, Date, Geo-Political Entity , Product (Software,Hardware)。威胁报告写作风格的多样性以及报告转换为文本期间引入的噪音导致类的精度得分不同,但在 0.9-0.99 的范围内。对于上下文实体提取,我们扩展了 SetExpan 模型以生成文本语料库中的所有实体。基于置信度值输入实体种子值的反馈循环允许更好的训练数据集。在此方法中使用的一些语义类是Malware,Malware Campaign,Attacker Orgnization,Vulnerability。
4.3.2 Entity Classification (EC)
使用多个 EE 模型的一个缺点是某些实体可以多次分类,在某些情况下甚至可能不准确。我们凭经验观察到,这种现象并不局限于任何特定类别。对这种现象的一种解释是不同威胁报告及其写作风格的变化和语法不一致。例如,对于文档中相同位置实体“linux”被归类Software和Organization。由于实体提取模型彼此独立运行,因此紧密类类型可能会有重叠。我们遵循三步法来解决实体分类中的歧义:
- 我们比较了在同一文档中和类之间出现在相同位置的实体的置信度分数。
- 对于相同的置信度分数,我们将这些类标记为不明确。我们保留了这些实例,直到关系提取阶段。当时,我们依靠本体的规则引擎来确定给定关系的头和尾实体的正确类别(在下一节中描述)。
- 对于通过前两个步骤的实体,我们使用更广泛的语义类对它们进行分类。
4.3.3 Relation Extraction
我们基于DocRED对MalKG进行关系提取;一个远程监督的人工神经网络模型,在维基数据和维基百科上预训练,具有三个特征。DocRED需要分析文档中的多个句子,以提取实体并通过合并文档的所有知识来推断它们的关系,这是句子级关系提取的转变。MT3K 三元组和文本语料库构成训练数据集和前面步骤中生成的实体,处理后的文本语料库构成测试数据集。如第 2.5 节所述,虽然训练和测试不是一个简单的实现,但我们使用 27, 354 个实体之间的 34 个关系生成了 40, 000 个三元组。实例化的实体、它们的分类以及在威胁报告或 CVE 描述中的位置构成了 RE 模型的输入。测试批次大小为 16 个文档。由于 DocRED 中的可伸缩性问题,每个文档的实体数量限制为少于 80 个。实体数量较多的文本文档进一步拆分为较小的尺寸。训练运行 4-6 小时,epoch大小为 984,阈值设置为 0.5。
4.4 Predicting Missing Information
KG完成(或实体预测)预测 MalKG 中缺失的信息。它还评估给定三元组的实体预测准确性,并建议预测实体的排名。对于 MalKG 三元组中的缺失实体,基于张量分解的方法 TuckER 满足 MalKG 结构的要求(参见第 2.4 节),并且可以预测缺失的实体。但是,在缩小实体预测模型的范围之前,我们评估了其与其他最新模型的性能。
4.4.1 Benchmark Dataset
由于网络安全领域缺乏基准数据集,我们依靠其他数据集来观察和比较现有嵌入模型的性能。最常用的基准数据集是FB15K,WN18,FB15K237,WN18RR。从freebase知识图谱中收集的FB15K和FB15K-237是包含一般事实(如名人,地点,事件)的协作知识库。WN18和WN18RR是来自英语词汇数据库Wordnet的数据集。更简单的模型在这些数据集上表现更好,其中训练集中存在测试三元组的相应反比关系。从FB15K和WN18中消除此类实例以生成FB15K237和WNRR。表4总结了OpenKE(https://github.com/thunlp/OpenKE)对实体预测(或知识图谱完成)的实验结果。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EwNOqIHG-1675684551700)(C:\Users\ExcaliburZ\AppData\Roaming\Typora\typora-user-images\image-20230206184658735.png)]](https://img-blog.csdnimg.cn/b254f476e6264fa4919194141ea18572.png)
表3描述了我们生成的图形结构——MalKG和手工注释,它们的属性和语料库详细信息之间的比较。例如,它比较了我们的数据集(MT3K、MT40K)和基准数据集的实体、关系和三元组(事实)的数量、实体的平均程度和图形密度。请注意,所有关系和图密度的平均度数分别定义为 n t / n e n_t /n_e nt/ne和 n t / n e 2 n_t /{n_e}^2 nt/ne2。这两个指标的得分越低,表示图形越稀疏。
4.4.2 Implementation
MT3K 验证集用于调整 MT40K 的超参数。对于MT3K上的TuckER实验,我们 d e = 200 , d r = 30 d_e= 200, d_r= 30 de=200,dr=30,learning rate= 0.0005, batch size of 128 and 500 iterations时实现了最佳性能。对于TransH实验, d e = d r = 200 d_e = d_r = 200 de=dr=200,learning rate = 0.001给了我们最好的结果。对于 MT3K 和 MT40K,我们将每个数据集分为 70% 的训练数据、15% 的验证数据和 15% 的测试数据。但是,对于较大的 MT40K 数据集,我们依靠 MT3K 数据集进行测试。MalKG的知识图谱完成情况可以在两种情况下进行描述:
- 预测 head 给定 <?, relation, tail>
- 预测 tail 给定 <head, relation, ?>
5 Results and Discussion
表 4 显示了基准数据集上现有嵌入模型的实体预测结果。评估指标旁边的向上箭头 (↑) 表示该指标首选较大的值,反之亦然。为了便于解释,我们将Hits@n度量值显示为百分比值,而不是 0 到 1 之间的比率。TransE在FB15K-237数据集上的Hits@10和MRR得分最高,而TransR在其余三个数据集上表现更好。然而,尽管具有TransE的简单性(时间复杂度 O ( d e ) O(d_e) O(de)),但是TransH比TransE更具表现力(能够模拟更多的关系)。TransR ( O ( n e d e + n r d e d r ) O(n_ed_e + n_rd_ed_r) O(nede+nrdedr)) 的空间复杂度比 TransH( O ( n e d e + n r d e O(n_ed_e + n_rd_e O(nede+nrde) 更大。此外,平均而言,训练TransR所需的时间是TransH的六倍。考虑到这些模型功能和复杂性权衡,我们选择TransH作为基于表征翻译的模型。DistMult仅在一种情况下(WN18上Hits@10)的表现优于TuckER,仅0.37%。TuckER和ComplEx在多个案例上都取得了非常接近的结果。
因此,我们密切关注最近优化的数据集(FB15K-237和WN18RR)的结果,因为我们的MT3K数据集与这两个数据集具有相似的属性(MT3K具有与WN18RR中的层次结构关系,并且没有像FB15K-237那样的冗余三元组)。由于空间复杂度非常接近( C o m p l E x : O ( n e d e + n r d e ) ComplEx: O(n_ed_e+n_rd_e) ComplEx:O(nede+nrde)和 T u c k E R : O ( n e d e + n r d r ) TuckER: O(n_ed_e+n_rd_r) TuckER:O(nede+nrdr)),我们选择TuckER在MT3K上进行评估,因为它包含了ComplEx。
我们在数据集上评估了TransH和TuckER的性能。表 5 和表 6 显示了 TransH 和 Tucker 在 MT3K 和 MT40K 上的性能。与基准测试相比,TransH在MT3K上的MRR得分有所提高。与其他基准结果相比,Tucker在所有指标上的表现都有所改善。显然,TuckER在MT3K数据集上的表现远远优于TransH。这一结果背后的四个原因:
-
与5, 741个唯一实体相比,MT3K只有22个关系。这使得KG密集,具有更高的实体与关系比率,这意味着实体之间的相关性很强。基于张量分解的方法使用张量和非线性变换,比线性模型更准确地将这种相关性捕获到嵌入中。对于较大的KG(如 MalKG),此属性特别重要,因为由于实体提取模型的缺点或用于预测稀疏填充图的信息,它可能缺少 KG 中的实体。准确的预测在这两种情况下都有帮助,尤其是在网络安全领域。
-
我们表明TuckER不会将所有潜在知识存储到单独的实体和关系嵌入中。相反,它使用其核心张量强制参数共享,以便所有实体和关系学习存储在核心张量中的常识。这被称为多任务学习,除了复杂的模型之外,没有其他模型采用。因此,TuckER创建的嵌入反映了MalKG中实体之间的复杂关系(1-n,n-1,n-n)。
-
此外,我们几乎可以肯定地确保验证和测试数据集中没有反比关系和冗余信息。与TuckER等双线性模型相比,像TransH这样简单但富有表现力的模型很难在这样的数据集中表现良好。
-
TransH的参数数量随唯一实体( n e n_e ne)的数量线性增长,而对于TuckER,它对于嵌入维度( d e d_e de和 d r d_r dr)呈线性增长。TuckER低维嵌入可以在各种机器学习模型中学习和重用,并执行分类和异常检测等任务。我们将异常检测作为MalKG的未来工作来探索,以识别可信赖的三元组。
由于TuckER在ground truth数据集上的表现明显优于TransH,因此我们在MT40K数据集上仅使用TuckER。值得注意的是,与MT3K相比,MT40K上除平均排名(MR)外的所有指标都有所改善。它证实了一般的直觉,即当我们提供更多数据时,模型会更有效地学习嵌入。MR 不是一个稳定的衡量标准,即使单个实体排名不佳,也会波动。我们看到,即使MR恶化,MRR分数也有所提高,这证实了只有少数糟糕的预测极大地影响了MT40K上的MR的假设。Hits@10为 80.4 表示当实体预测模型预测一组有序的实体时,真实实体在其前 10 名中出现 80.4% 的次数。Hits@1度量表示 73.9% 的次数,模型将真实实体排名在第 1 位,即对于 80.4% 的情况,模型的最佳预测是相应的不完整三元组缺失实体。我们可以类似地解释Hits@3。我们将MT40K上的整体实体预测结果转换为足够的,以便可以改进训练的模型并进一步用于预测看不见的实体。
7 Conclusion
在本研究中,我们提出一个框架来生成第一个恶意软件威胁情报知识图谱MalKG,它可以从非结构化威胁报告中生成结构化和上下文相关的威胁情报。我们提出了一种以非结构化文本语料库、恶意软件威胁本体、实体抽取模型和关系抽取模型作为输入的体系结构。它创建了三元组的向量嵌入,可以从图中提取潜在信息并发现隐藏信息。该框架输出一个MalKG,它包括27, 354个独特实体、34个关系和大约40, 000个以 e n t i t y h e a d − r e l a t i o n − e n t i t y t a i l entity_{head}-relation-entity_{tail} entityhead−relation−entitytail形式存在的三元组。由于这是一个相对较新的研究领域,我们演示了知识图如何通过实体预测应用程序准确地预测文本语料库中的缺失信息。我们激励并实证地研究了编码三元组的不同模型,并得出结论:基于张量因子分解的方法在我们的数据集中获得了最高的整体性能。
使用MT40K作为基准数据集,我们将为未来的工作探索实体和关系提取的稳健模型,这些模型可以推广到网络安全领域的不同的数据集,包括博客、推文和多媒体。另一个应用是使用向量嵌入从MalKG编码的背景知识中识别可能的网络安全攻击。当前的预测模型可以生成一个为缺失信息的顶级选项列表。将这种能力扩展预测新出现的攻击向量的威胁情报,并利用这些信息来防御尚未广泛传播的攻击,这将很有意思。通过这项研究,我们想要解决的一个基本问题是KG中不准确的三元组。这是由于实体和关系提取模型的局限性和威胁报告中不准确的描述。















 949
949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









