







Tensorflow使用
张量属性
- name:名字
- shape:维度,可能会被改变,但最好别改
- dtype:类型,初始化后就不可变了
计算图
Tensorflow只会保存一个计算的流程,而不是直接出结果。相当于写公式。
In [3]: a = tf.constant([1.0,2.0])
In [4]: b = tf.constant([2.0,3.0])
In [5]: result = a + b
In [6]: result
Out[6]: <tf.Tensor 'add:0' shape=(2,) dtype=float32>会话
会话用于执行公式,得出计算的结果。会话拥有并管理tf运行时的所有资源。所以用完需要关闭,否则会资源泄露。
with tf.Session() as sess:
sess.run(公式)
#退出作用域会自动关闭
#在交互模式下可以使用InteractiveSession
sess = tf.InteractiveSession()
result = a + b
result.eval()#自动使用sess其他类
- 配置类tf.ConfigProto
机器学习算法流程
- 从物体中提取出特征向量
- 定义一个合适的神经网络的结构
- 调整神经网络中的参数值
//定义参数
EPOCHS = 500
......
//初始化变量
......
epoch = 0
while (!reachTarget() && epoch < EPOCHS){
batchData = getBatchData() //获取batch大小的数据集
result= trainForNerNet(batch) //前馈NN得到预期值
invUpdateForNN(value) //反向传播更新矩阵值
epoch++
}从这里看,每次迭代都会产生一个result,显然这样会撑爆计算图,因此TF有placeholder来作为单个填充位置。placeholder不用指定值和维度,只要给定数据类型。
- 验证效果
神经网络的层之间的连接
如第一层(为输入层)是2个节点,而第二层是3个节点,那么从第一层到第二层的映射,是一个2*3的矩阵。
W1 = [[w11, w12, w13],
[w21, w22, w23]]
X1 = [x1, x2]生成的第二层的结果是一个1*3的矩阵,正好对于第二层的3个节点
X2 = X1 * W1如果第三层就是输出层,只有一个节点,那么第二层到第三层的映射为3*1的矩阵
W2 = [[w11],
[w21],
[w31]]
X3 = X2 * W2最后只有一个值,即为输出值。
实现这个神经网络
- 矩阵乘法为
tf.matmul(X, W)
- 生成一个正态分布的映射矩阵
weights = tf.Variable(tf.random_normal([2, 3], stddev=2))
- 其他生成映射矩阵的函数
tf.random_normal #标准正态分布
tf.truncated_normal #无离群值(99%以外)的正态分布
tf.random_uniform #平均分布
tf.random_gamma #Gamma分布(没听过)
tf.zeros #全0的矩阵
tf.ones #全1的矩阵
tf.fill #全某数的矩阵
tf.constant #自定义常量矩阵- 在计算出结果前,变量需要初始化
w1 = tf.Variable(tf.random_normal([2,3], stddev=1, seed=1)
...
y = tf.matmul(a, w1)
sess = tf.Session()
sess.run(tf.initialize_all_variables()) #先初始化所有变量
sess.run(y) #才能开始计算
sess.close()- placeholder的使用
w1 = tf.Variable(tf.random_normal([2,3], stddev=1, seed=1)
x = tf.placeholder(tf.float32, #类型必需
shape = (1,2)) #维度最好有,可避免出错
y = tf.matmul(x, w1)
sess = tf.Session()
sess.run(tf.initialize_all_variables()) #先初始化所有变量
sess.run(y, feed_dict={x: [0.7,0.9]}) #才能开始计算, 并要往placeholder中填充数据
sess.close()- 实现反向传播算法
cross_entropy = -tf.reduce_mean(
y * tf.log(tf.clip_by_value(y,1e-10,1.0)))
learning_rate = 0.001
train_step = tf.train.AdamOptimizer(learning_rate)
.minimize(cross_entropy)模型持久化
saver = tf.train.Saver()
# 保存模型
saver.save(sess, "/path/model.ckpt")
# 加载模型
saver.restore(sess, "/path/model.ckpt")
#直接加载
saver = tf.train.import_meta_graph(..)深度学习
基本概念
一类通过多层非线性变换对高复杂性数据建模算法的合集
线性模型的局限
一个线性模型如下
Y = x * W1 * W2 * W3
= x * W他再怎么变换(即无论怎么多层),还是一个线性模型
因此只能解决线性可分问题,无法解决XOR问题
要解决复杂问题,需要非线性模型,如relu
去线性化
一个二层模型如下
Y = f(f(x*W1+b1)*W2+b2)常用的变换函数如下
- ReLU
- sigmid
- tanh
经典损失函数
交叉熵:两个概率分布之间的距离,多用于分类问题
- 如一个三分类问题
- 如输出的结果为[0.12, 0.79, 0.09], 而预期的结果y为[0, 1, 0], 那么使用交叉熵能够计算这两个结果之间的距离
softmax回归:将原始输出层映射到最终输出层,映射成为一个概率值
- 一般是通过softmax回归将输出值进行一次映射,成为最终概率
- 再将最终概率与目标值之间,进行交叉熵计算距离
- 反向传播以更新值
- tf.clip_by_value: 设定上下限,比下限小的设为下限,比上限大的设为上限
- tf.nn.softmax_cross_entropy_with_logits(y, y_)
均方误差:用于回归问题
- mse = tf.reduce_mean(tf.square(y_ - y))
自定义损失函数
#如下述函数
def f(x,y):
if x > y:
return A * (x - y)
else:
return B * (y - x)
def loss(y, y_):
sum = 0
for i in range(len(y)):
sum += f(y, y_)
return sum
# 在tensorflow中
tf.reduce_sum(
tf.select(
tf.greater(v1, v2),
(v1 - v2) * a,
(v2 - v1) * b
)
)优化算法
批量梯度下降:选择一小批数据,进行优化
设置学习率, 衰减学习率
decayed_learning_rate
= learning_rate * decayed_rate ^ (step / decay_steps)
# TF自带的
step = tf.Variable(0)
learning_rate =
tf.train.exponential_decay(0.1, global_step, 100, 0.96, staircase=true)
learning_step =
tf.train.GradientDescentOptimizer(learning_rate)
.minimize(loss_func, global_step = step)
过拟合问题
- L1正则化:sum(X)
tf.contrib.layers.l1_regularizer
- L2正则化:sum(X ** 2)
tf.contrib.layers.l2_regularizer
- 这两个正则化可以一起使用
滑动平均模型
- tf.train.ExponentialMovingAverage
卷积神经网络
简介
一张图片的像素太多了,而全连接层的每一个节点都要接受所有像素作为参数。如一张图片为30*30,而第二层(第一层隐藏层)假设有500个节点,那么所有参数为30*30*500+500个。
而卷积就是用于减少参数数量的,还能避免过拟合。
CNN的组成
- 输入层:接受所有像素
- 卷积层:通常为3*3或5*5个节点映射为一个节点,矩阵会变深,抽象层次更高
- 池化层:不会改变三维矩阵的深度,会减小长和宽,简而言之就是将高像素的图片变成低像素的
- 全连接层:在多轮卷积和池化后,连接入全连接层分类。将卷积层和池化层视为信息特征的提取,而全连接层就是训练了
- SoftMax层:给出概率结果
卷积层
卷积层每个节点又叫过滤器:将当前神经网络中的一个子矩阵映射为下一层矩阵的一个值。
X2 = f(X1 * W + b)
#在tf中
# 填充的值,由正态分布生成
initer = tf.truncated_normal_initializer(stddev=0.1)
# 生成一个5*5卷积核,当前层深度为3(RGB),输出层为16
filter_weight = tf.get_variable("weight", [5,5,3,16], initializer=initer)
# 生成偏差项
biases = tf.get_variable('biases', [16], initializer=tf.constant_initializer(0.1))
# 定义卷积层
conv = tf.nn.conv2d(input, #上面的X1
filter_weight, #上面的W
strides=[1,1,1,1],#步长
padding='SAME')
# 加上偏差项
bias_cnn = tf.nn.bias_add(conv, biases)
# 上面的f()
actived_cnn = tf.nn.relu(bias_cnn)
△卷积核为3、步幅为1和带有边界扩充的二维卷积结构
- input: 一个四维矩阵,第一维为一个batch,后三维表示一张图片。如[0,:,:,:]表示第一张图片
- filter_weight:卷积层的权重
- stride: 不同维度上的步长大小。第一个1表示图片,必然是1,总不能跳过图片吧。最后一个1表示色彩通道,也必然为1,总不能跳过一种颜色吧。中间两个可以改变,表示在长宽上的移动步长。
- padding:表示填充,SAME为全0填充,VALID为不填充
池化层
这是一种特殊的卷积,其深度不变,只减少长宽。公式如下X2 = X1 * W
- 最大池化层:tf.nn.max_pool
- 平均池化层:tf.nn.avg_pool
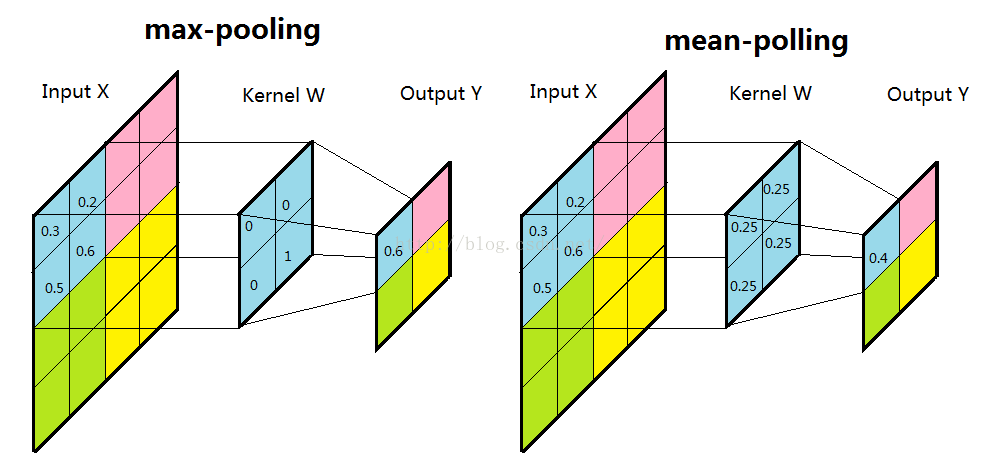
pool = tf.nn.max_pool(actived_conv,
ksize=[1,3,3,1],
strides=[1,2,2,1],
padding='SAME')- actived_conv: 卷积层输出值
- ksize: 过滤器尺寸, 常用的为[1,3,3,1]或[1,2,2,1]
- strides: 步长
- padding:填充
经典CNN模型
LeNet-5
- AlexNet
- ZF Net
- VGGNet
# 一个正则表达式,哈哈哈
输入层 -> (卷积层 -> 池化层?)+ -> 全连接层+
Inception
Google的这个模型和上面显然是两个思路,AlexNet发明的时代,计算机资源不算强大,想的是减少参数还能达到模型效果。
Inception是反复从图像中抽取特征信息,宁可抓错也不放过,得益于Google的强大计算能力,显然这样可以得到更多的信息。效果自然很好。


TensorFlow-Slim
这是一个封装包
# 定义一个卷积层, 32表示下一层的深度, [3,3]为核大小
net = slim.conv2d(input, 32, [3,3])














 6231
6231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









