







k-means算法作为经典的数据挖掘聚类算法,应用也相当广泛,由用户自己设置一个聚类个数,任取原始的k个数据,将其值作为聚类中心,再将原始数据的其他值按照相应的距离(如 欧氏距离)的大小进行归类,因为选取的k个中心点一般情况下并非为最终的中心点,算法需要多次的递归确定最终的中心点,结束递归的条件就是,本次递归每个簇所产生的新的每个中心点值和该簇上一次产生的中心点值相等,结果稳定,聚类完成。
大致步骤如下:
输入:聚类簇的个数和n个原始数据集
输出:k个聚类簇
(1). 任选k个数据对象作为初始簇的中心
(2). 重复:
for i =1 to n
do 将第 i 条数据依次和划分的k个簇集合的中心进行距离计算得到距离 distance,并将该记录添加到distance最小的一簇中;
重新计算每个簇的中心得到新的中心点;
将该簇新的中心点 newCenterid 和上一次划分得到的中心点preCenterid 进行比较,
if(每一个簇的中心点未发生变化) return;
else 递归执行该方法
| 数据id | 属性1 | 属性2 |
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 1 |
| 4 | 2 | 2 |
| 5 | 4 | 3 |
| 6 | 5 | 3 |
| 7 | 4 | 4 |
| 8 | 5 | 4 |
该例中n = 8,假如 k = 2
选取 id为 1和2 的作为原始聚类簇的中心 则 1(1, 1) , 2(1, 2)
第一次迭代:根据欧氏距离 distance = 比较,比如计算第三条记录(2,1)和第一个簇中心(1,1)的欧氏距离为 = 1 ;同样计算第三条(2,1)和第二个中心也就是(1, 2)的距离为 ,可见第三条记录和第一个簇距离近,故将第三条记录归到第一个簇,依次可将这八条数据划分为两个簇即 (1, 3)和(2, 4 , 5, 6, 7, 8)其中数字是数据的id号则第一次所产生的新的中心点为(1.5, 1) 和(3.5, 3)
第二次迭代:将每一条原始数据和新的中心点进行距离比较划分,本次划分产生的新的中心点在(1.5, 1.5) 和 (4.5, 3.5) 该次产生的中心点和上一次的对应簇的中心点不一样 继续迭代
第三次迭代 结果产生新的中心点位(1.5, 1.5) 和 (4.5, 3.5) 和第二次的结果一致,迭代过程结束。
原代码如下:
类一:Point.java 类:
package newKmeans;
/*
* 坐标点类
*/
public class Point {
private double x;
private double y;
public Point(double x, double y){
this.x = x;
this.y = y;
}
public Point(){
}
public double getX() {
return x;
}
public void setX(double x) {
this.x = x;
}
public double getY() {
return y;
}
public void setY(double y) {
this.y = y;
}
}
类二:Cluster.java 类
package newKmeans;
import java.util.List;
import java.util.LinkedList;
/*
* 聚类产生的类别类
* @ clusterid 簇的编号
* @ preCenterid 当前的质心
* @ newCenterid 经过新一轮的聚类重新产生的质心 通过比较 preCenterid and newCenterid如果相同则作为结束条件
* @ listPoint 是该聚类所包括的所有点
*/
public class Cluster {
private int clusterid;
private Point preCenterid;
private Point newCenterid;
private List<Point> listPoint;
public Cluster(Point p){
this.preCenterid = p;
}
public void setClusterid(int clusterid){
this.clusterid = clusterid;
}
public int getClusterid(){
return this.clusterid;
}
public void serPreCenterid( Point p){
this.preCenterid = p;
}
public Point getPreCenterid(){
return this.preCenterid;
}
public void serNewCenterid( Point p){
this.newCenterid = p;
}
public Point getNewCenterid(){
return this.newCenterid;
}
public void addPoint(Point p){
if(this.listPoint == null){
List<Point> listPoint = new LinkedList<Point>();
listPoint.add(p);
this.listPoint = listPoint;
}
else{
this.listPoint.add(p);
}
}
public List<Point> getListPoint(){
return this.listPoint;
}
public void calCenterid(){
double sumx = 0.0;
double sumy = 0.0;
for(Point p: listPoint){
sumx += p.getX();
sumy += p.getY();
}
sumx /= listPoint.size();
sumy /= listPoint.size();
Point p = new Point(sumx, sumy); //新的质心是该簇所包含的point点的x坐标平均 和 y坐标 平均 ; 并设置新的质心
this.serNewCenterid(p);
}
}
类三: Kmeans 类:
package newKmeans;
import java.util.List;
import java.util.LinkedList;
import java.io.*;
public class Kmeans {
/*
* 实现k-means聚类方法
*/
public List<Cluster> kmeansFunc(List<Point> data, Integer k){
List<Cluster> kCluster = new LinkedList<Cluster>();
for(int i = 0; i < k; i++){ //随机根据前k条数据的(x, y)坐标作为簇的质心
Cluster cl = new Cluster(data.get(i));
cl.setClusterid(i);
kCluster.add(cl);
}
operateFunc(data, kCluster, k);
for(Cluster c: kCluster){
for(Point p : c.getListPoint()){
System.out.println("点 (" + p.getX() + "," + p.getY() +") 属于 第:" + c.getClusterid() + "类 ");
}
}
return kCluster;
}
/*
* 具体的聚类操作方法
* @ data 原始数据
* @ kCluster 生成的k个簇
* @ k 聚类个数
*/
public void operateFunc(List<Point> data, List<Cluster> kCluster, int k){
for(Cluster c: kCluster){
if(c.getListPoint() != null){
c.getListPoint().clear();
}
}
for(Point p: data){
double distance = 100000.0;
double tempDistance = 0.0;
int centerid = kCluster.get(0).getClusterid();
for(Cluster c: kCluster){
if(distance > (tempDistance = calDistance(p, c))){
centerid = c.getClusterid();
distance = tempDistance;
}
}
kCluster.get(centerid).addPoint(p); //将该点添加到离kCluster集合 最近质心的簇的listPoint中去 在后面的显示和计算新的质心用到listPoint
}
for(Cluster c: kCluster){ //计算新的质心
c.calCenterid();
}
boolean flag = true; //用来作为判断新旧质心是否相同的标志
for(Cluster c: kCluster){ //判断新旧质心是否相同作为聚类结束的标准
if(c.getNewCenterid().getX() != c.getPreCenterid().getX() || c.getNewCenterid().getY() != c.getPreCenterid().getY()){
c.serPreCenterid(c.getNewCenterid());
flag = false;
}
}
if(!flag){
operateFunc(data, kCluster, k);
}
return;
}
/*
* 计算测试记录和已划分记录的距离
*/
public Double calDistance(Point p, Cluster c){
Double resDistance = 0.0;
double x = p.getX() - c.getPreCenterid().getX();
double y = p.getY() - c.getPreCenterid().getY();
resDistance = Math.sqrt(x * x + y * y); //欧氏距离比较
return resDistance;
}
/*
* 获取文本数据
*/
public List<Point> getData(){
List<Point> data = new LinkedList<Point>();
try{
String path = System.getProperty("user.dir") +"/data.txt";
FileReader fr = new FileReader(path);
BufferedReader br = new BufferedReader(fr);
String line = br.readLine();
while(line != null){
String [] da = line.split(" ");
Double x = Double.parseDouble(da[0]);
Double y = Double.parseDouble(da[1]);
Point point = new Point(x, y);
data.add(point);
line = br.readLine();
}
}
catch(Exception e){
System.out.println(e);
}
return data;
}
}
类四 :MainFrame.java类:
package newKmeans;
import java.awt.Color;
import java.awt.Graphics;
import java.util.List;
import javax.swing.*;
public class MainFrame extends JFrame {
public static void main (String args[]) {
new MainFrame();
}
public MainFrame(){
setBounds(100,100,400,400);
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
setVisible(true);
}
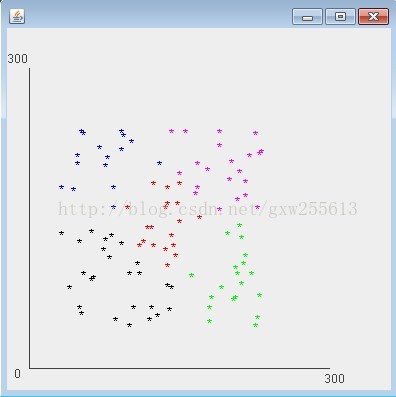
public void paint(Graphics g) {
super.paint(g);
g.setColor(Color.DARK_GRAY);
g.drawLine(30, 70, 30, 370);
g.drawLine(30, 370, 330, 370);
g.drawString("0", 15, 380);
g.drawString("300", 325, 385);
g.drawString("300", 8, 65);
Color [] col = {Color.MAGENTA, Color.BLUE, Color.GREEN, Color.RED, Color.BLACK, Color.YELLOW, Color.GRAY, Color.PINK, Color.CYAN, Color.ORANGE,};
Kmeans ks = new Kmeans();
int k = 5; //k 建议在10类以内,只设置了10中颜色
List<Point> data = ks.getData();
List<Cluster> cluData = ks.kmeansFunc(data, k);
double xValue = 0;
double yValue = 0;
int i = 0;
for(Cluster c: cluData){
for(Point p: c.getListPoint()){
xValue = p.getX() + 30;
yValue = p.getY() + 70;
g.setColor(col[i]);
g.drawString( "*" , (int)xValue * 2, (int)yValue * 2);
}
i++;
i %= 10;
}
}
}
所需数据如下:data.txt
100 10
15 50
74 88
91 66
36 88
23 13
22 17
56 57
52 59
80 78
73 19
53 28
65 72
67 31
48 92
0 28
74 95
16 73
44 94
87 68
6 29
55 0
39 71
31 2
85 15
62 0
58 36
19 8
59 45
25 52
45 48
46 57
22 54
88 34
53 77
11 71
30 56
0 51
24 63
92 32
87 83
46 26
98 93
34 71
94 12
33 38
26 28
90 53
79 39
59 26
55 52
10 91
21 59
57 62
68 16
84 24
4 78
10 0
8 12
34 97
86 84
39 57
45 88
52 38
69 43
30 0
8 16
49 16
35 5
41 55
83 51
38 66
98 38
99 11
97 97
92 62
59 21
55 78
9 55
53 67
90 76
43 48
79 0
11 1
95 71
30 9
9 88
27 94
99 82
26 38
15 74
92 25
89 20
54 89
79 7
89 47
68 28
88 71
97 1
53 36
75 83
100 10
15 50
74 88
91 66
36 88
23 13
22 17
56 57
52 59
80 78
73 19
53 28
65 72
67 31
48 92
0 28
74 95
16 73
44 94
87 68
6 29
55 0
39 71
31 2
85 15
62 0
58 36
19 8
59 45
25 52
45 48
46 57
22 54
88 34
53 77
11 71
30 56
0 51
24 63
92 32
87 83
46 26
98 93
34 71
94 12
33 38
26 28
90 53
79 39
59 26
55 52
10 91
21 59
57 62
68 16
84 24
4 78
10 0
8 12
34 97
86 84
39 57
45 88
52 38
69 43
30 0
8 16
49 16
35 5
41 55
83 51
38 66
98 38
99 11
97 97
92 62
59 21
55 78
9 55
53 67
90 76
43 48
79 0
11 1
95 71
30 9
9 88
27 94
99 82
26 38
15 74
92 25
89 20
54 89
79 7
89 47
68 28
88 71
97 1
53 36
75 83














 4804
4804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









