







 本文介绍了IK分词器的下载、使用和测试过程,适用于Win10x86和Ubuntu环境。通过创建索引、写入数据并执行搜索,展示IK分词器相较于Elasticsearch自带分词器的优势,如ik_max_word和ik_smart两种模式在中文分词上的不同效果。
本文介绍了IK分词器的下载、使用和测试过程,适用于Win10x86和Ubuntu环境。通过创建索引、写入数据并执行搜索,展示IK分词器相较于Elasticsearch自带分词器的优势,如ik_max_word和ik_smart两种模式在中文分词上的不同效果。
对于Win10x86、Ubuntu环境均适用~
1.下载
为什么要使用IK分词器呢?最后面有测评~
访问:https://github.com/medcl/elasticsearch-analysis-ik/releases,找到与自己的ES相同的版本,
可以下载源码,然后自己编译,也可以直接下载编译好的压缩包,比如我这里是5.4.0版本:
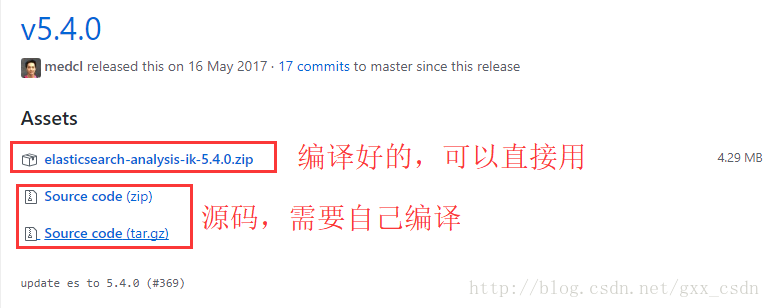
如果选择下载源码然后自己编译的话,使用maven进行编译:
在该目录下,首先执行:mvn compile;,会生成一个target目录,然后执行mvn package;,会在target目录下生成一个releases目录,在该目录下有一个压缩包,这就是编译好的,与直接下载编译好是一样的~
或者把该项目在IDEA打开,在客户端执行maven的clear、compile和package命令,效果都是一样的,但是用命令行编译好像稍微快一点~
2.使用
在es目录下的plugins目录下创建一个新文件夹,命名为ik,然后把上面的压缩包中的内容解压到该目录中。
比如在Ubuntu中,把解压出来的内容放到es/plugins/ik中:

之后,需要重新启动es。
3.测试
1). 创建索引,指定分词器为“ik_max_word”
PUT index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word"
}
}
}
},
"mappings": {
"test1":{
"properties": {
"content": {
"type": "text",
"analyzer": "ik",
"search_analyzer": "ik_max_word"
}
}
}
}
}2). 写入数据到索引中
POST index/test1/1
{
"content": "里皮是一位牌足够大、支持率足够高的教练"
}
POST index/test1/2
{
"content": "他不仅在意大利国家队取得过成功"
}
POST index/test1/3
{
"content": "教练还带领广州恒大称霸中超并首次夺得亚冠联赛"
}3). 执行搜索,比如匹配有“教练”字样的文档
GET index/_search
{
"query": {
"match": {
"content": "教练"
}
},
"highlight": {
"pre_tags": ["<span style = 'color:red'>"],
"post_tags": ["</span>"],
"fields": {
"content": {}}
}
}4). 搜索效果
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"failed": 0
},
"hits": {
"total": 2,
"max_score":  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









