







前言
一、爬虫思路
二、代码实现
1.引入库,设置UA
2.获得首次请求,提取源链接
3.通过真链接获取响应保存数据
总结
前言
呐,GoGoGO!!!再次走上爬虫道路了,这次的目标是一个叫“手慢无”的短视频网址,某音下载搞定之后,这几月忘了登陆密码就一直刷手手了,虽然可以直接分享微信好友但是带着自己的大名简直太烦了,找了找资料后研究出来了无水印下载视频方法,代码不多全是干货。由于事发突然,只搞了爬取短视频的代码。
手手说,你爬到了我的无水印,也爬不到我的精美图集。
提示:以下是本篇文章正文内容,下面案例可供参考
一、爬虫思路
1)首先确立目标:短视频单个视频链接(这个是我最近非常喜欢的视频了,太甜了,扛不住)
https://www.kuaishou.com/short-video/3xij3j4f5avjiua?authorId=3xv7ci7tvjdmubi&streamSource=find&area=homexxbrilliant
2)然后分析:目标网站机制问题,需要先通过抓包找到真正视频链接 ,这个很长的链接很明显就是真正链接。但是我们要在源代码界面找到可播放python可利用的链接。
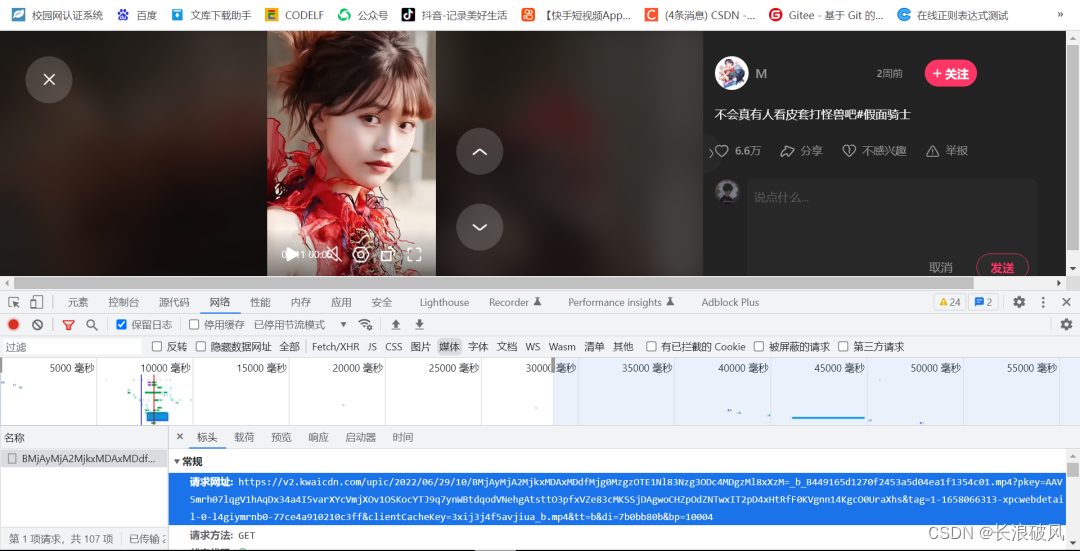
将长链接输入直接转到视频原链接观看。可知,这个长的转码链接就是视频源链接,后面爬取二进制文件保存为MP4文件就很简单了。
3)问题来了,如何在视频界面源代码中找到视频源链接?
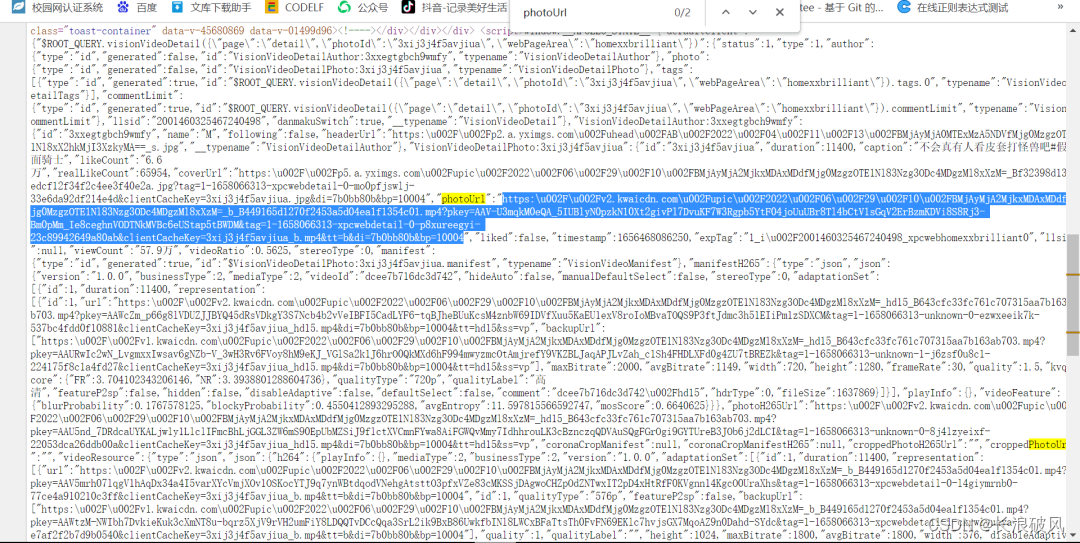
上面是源代码界面,挺复杂的,需要用心找,像是视频播放地址的多试几次,最后成功找到真正可播放链接。
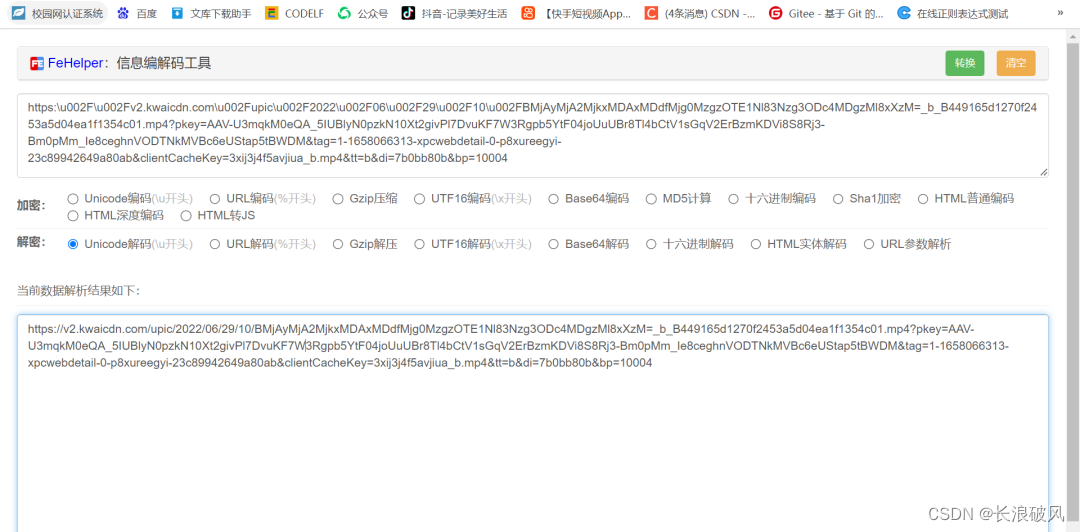
所以可知其前后转码字符,通过正则表达式匹配后进行Unicode解码可提取出真正链接。(悄悄话:抖音的是URL转解码)
二、代码实现
1.引入库,设置UA
代码如下(示例):
import re
import requests
from fake_useragent import UserAgent
headers = {
'refer': 'https://www.kuaishou.com/',
'User-Agent': str(UserAgent().random)
}
2.获得首次请求,获得源代码提取源链接
进行源代码解析,利用正则表达式提取标题及视频链接
解码方法步骤在代码
代码如下(示例):
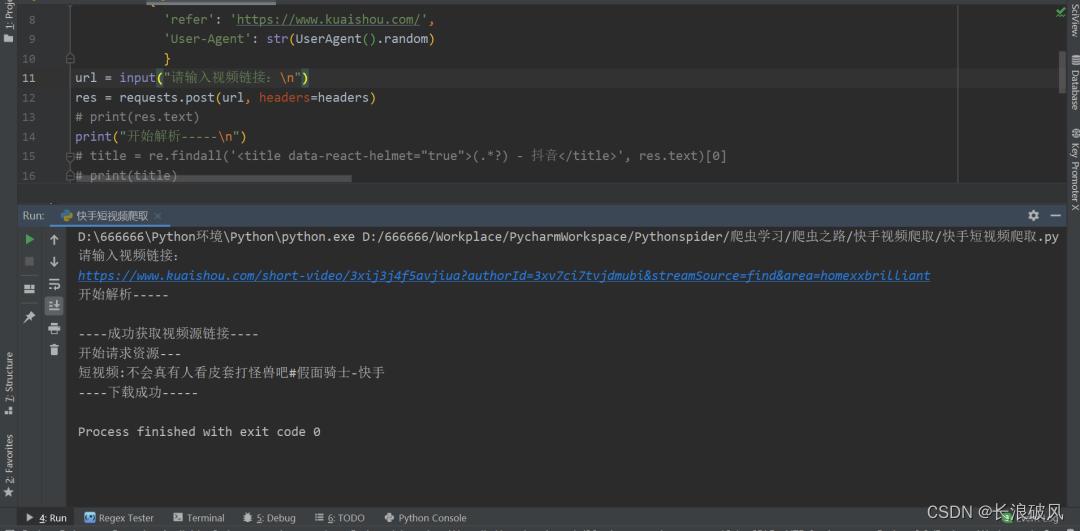
url = input("请输入视频链接:\n")
res = requests.post(url, headers=headers)
# print(res.text)
print("开始解析-----\n")
# title = re.findall('<title data-react-helmet="true">(.*?) - 抖音</title>', res.text)[0]
# print(title)
src = re.findall('"photoUrl":"(.*?)",', res.text)[0]
# print(src)
video_url = src.encode(encoding='utf-8').decode('unicode_escape') # Unicode解码
# print(video_url)
print("----成功获取视频源链接----")
title = re.findall('<title>(.*?)</title>', res.text)[0]
3.通过真链接获取响应保存数据
get请求获取二进制文件保存为MP4格式视频文件
resp = requests.get(url=video_url, headers=headers).content
# print(resp)
print("开始请求资源---")
with open(title + '.mp4', 'wb') as f:
f.write(resp)
print("短视频:"+title+"\n----下载成功-----")
总结;
图片
以上就是今天要讲的内容,点个关注再走吧。
邓紫棋闭关半年带着新专辑来了,启示录,嗯~ o( ̄▽ ̄)o















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









