







 该实验报告详细介绍了如何在Linux环境中进行Hadoop的伪分布式安装,包括JDK的安装、SSH免密码配置以及Hadoop的配置和启动过程。在配置过程中,解决了NativeCodeLoader加载问题和SSH的严格主机检查问题,并通过jps验证了Hadoop是否成功启动。
该实验报告详细介绍了如何在Linux环境中进行Hadoop的伪分布式安装,包括JDK的安装、SSH免密码配置以及Hadoop的配置和启动过程。在配置过程中,解决了NativeCodeLoader加载问题和SSH的严格主机检查问题,并通过jps验证了Hadoop是否成功启动。
《Hadoop大数据技术》实验报告(1)
班级 学号 姓名
Hadoop的伪分布式安装和配置
一、实验目的
1、理解Hadoop伪分布式的安装过程;
2、学会JDK的安装和SSH免密码配置;
3、学会Hadoop的伪分布式安装和配置。
二、实验内容
在linux平台中安装Hadoop,包括JDK安装、SSH免密码配置和伪分布式安装。
三、实验过程
(一)、Java JDK的安装
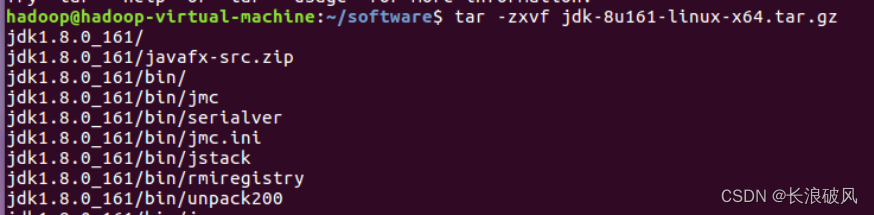
1、将JDK解压到“/software”目录下。
tar –zxvf jdk-8u161-linux-x64.tar.gz

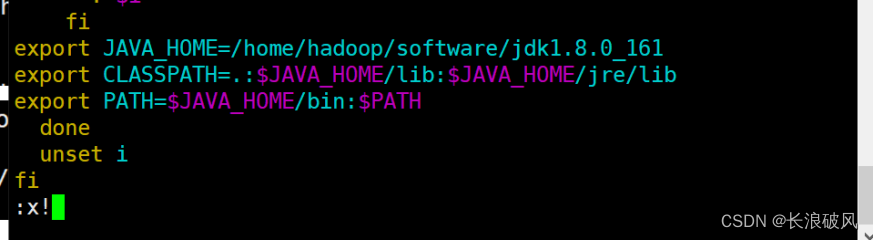
2、在/etc/profile中配置JAVA_HOME和PATH环境变量。
查看jdk所在绝对路径
进入配置Vim/etc/profile


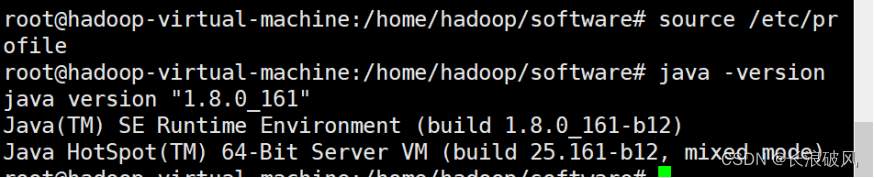
3、使环境变量生效并检查
source/etc/profile
(二)、SSH免密码配置
1.先进入到ssh目录,命令如下:
cd~/.ssh/

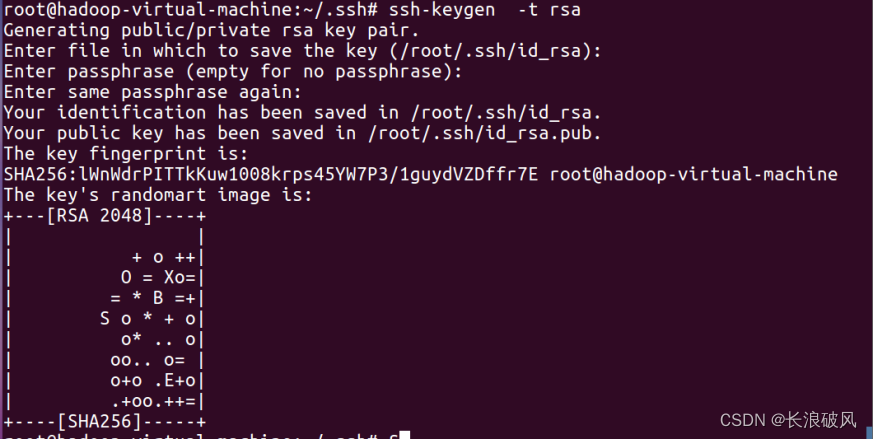
2.利用 ssh-keygent 生成(非对称加密)密钥
ssh-keygen -t rsa
3.将密钥加入到授权中
cat ./id_rsa.pub >> ./authorized_keys

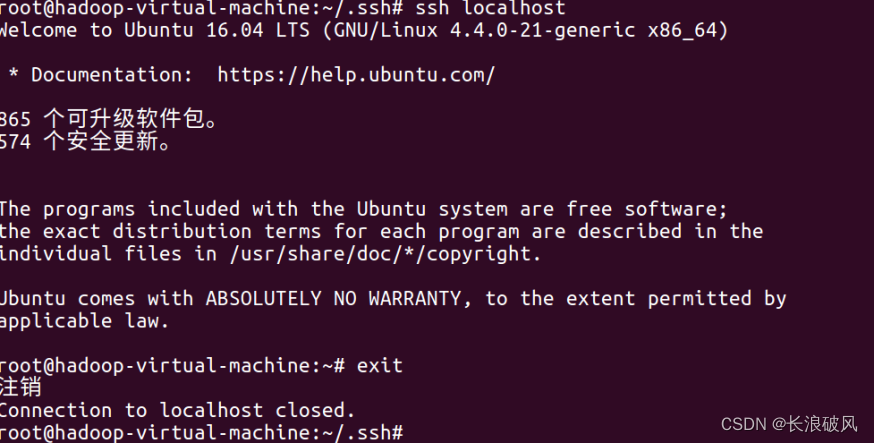
4.执行 「ssh localhost」命令,即可免密登录
(三)、hadoop的伪分布式安装和配置
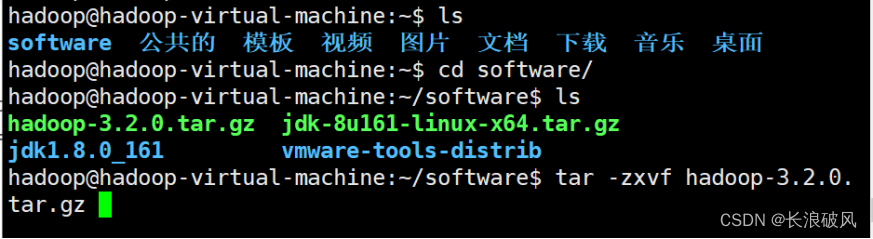
1.下载好了的hadoop包解压
进入目标目录:cd software
解压tar -zxvf hadoop -3.2.0.tar.gz
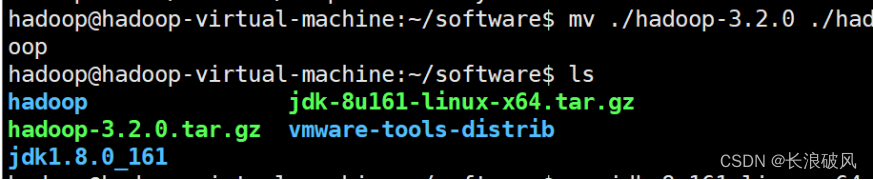
2.将Hadoop文件名改变便于后期环境配置
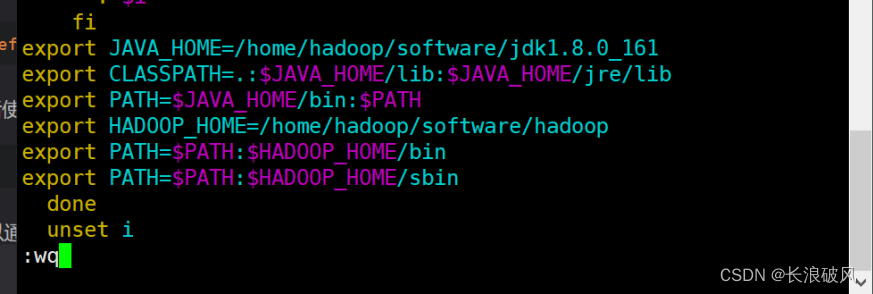
3.配置Hadoop环境变量
Vim /etc/profile
刷新变量source /etc/profile


4.配置hadoop的配置文件
1)cd $HADOOP_HOME/etc/Hadoop
vim hadoop-env.sh

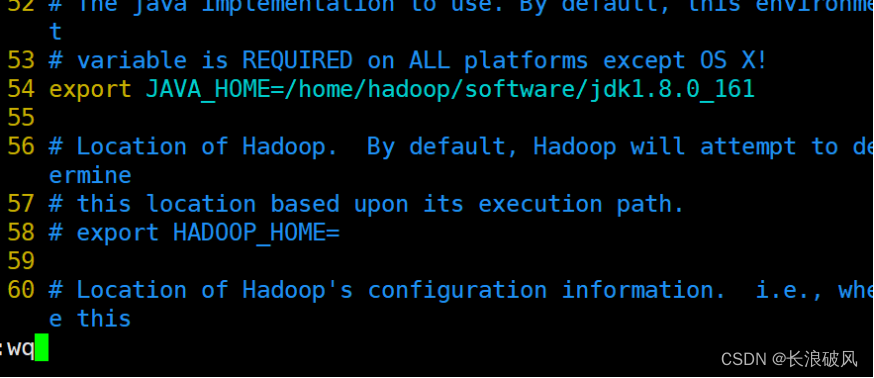
vim core-site.xml

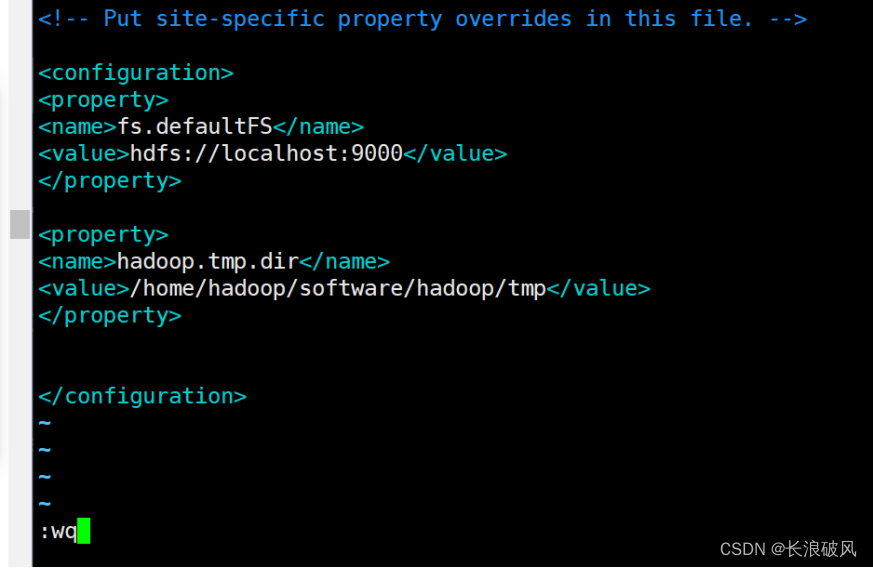
3)vim hdfs-site.xml

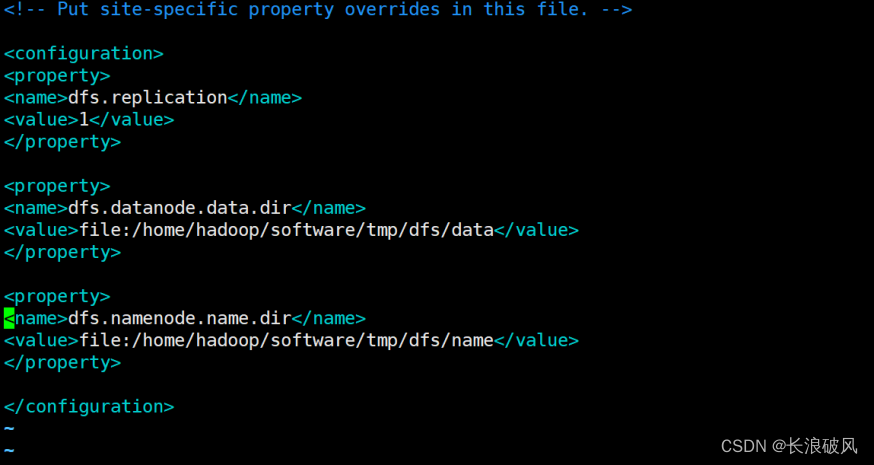
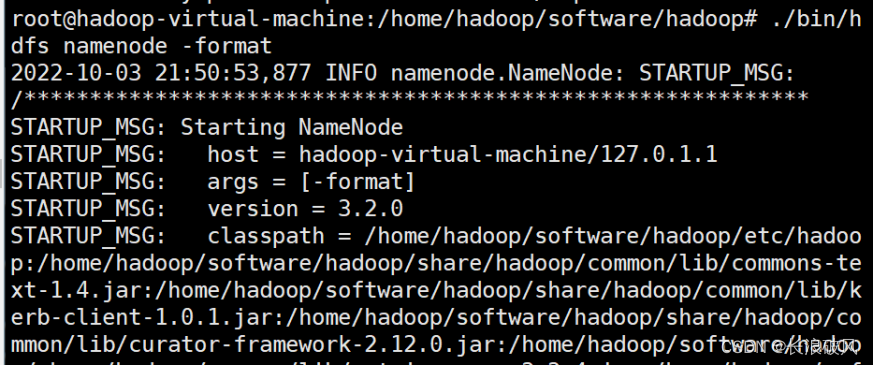
5.完成配置执行 NameNode 的格式化:
cd /home/hadoop/software/hadoop
./bin/hdfs namenode -format
6.试运行Hadoop
1)开启 NameNode 和 DataNode 守护进程。
cd /home/hadoop/software/hadoop
./sbin/start-dfs.sh
#start-dfs.sh是个完整的可执行文件,中间没有空格

2)出现错误,解决方案
cd /home/hadoop/software/Hadoop
vim hadoop-env.sh
添加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
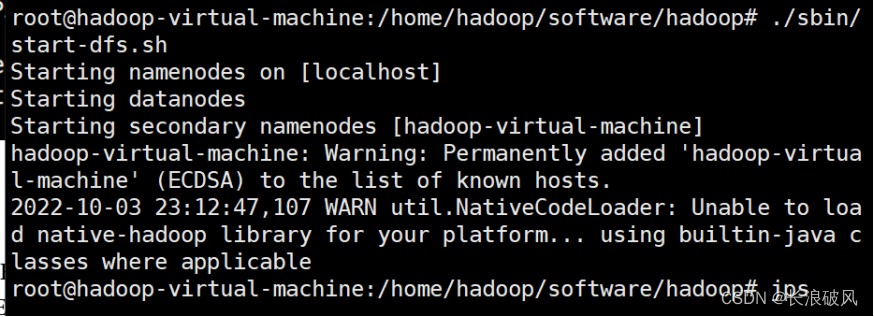
4) 错误WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
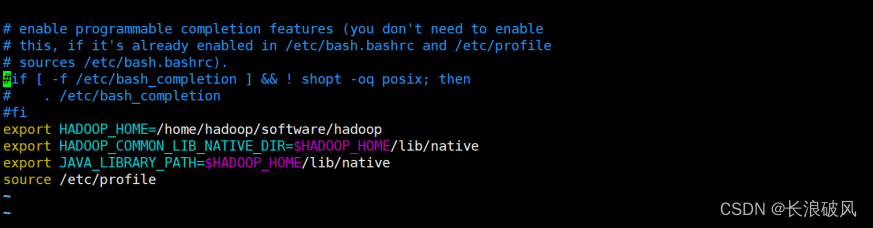
vim ~/.bashrc
export JAVA_LIBRARY_PATH=/usr/local/hadoop/lib/native
source ~/.bashrc
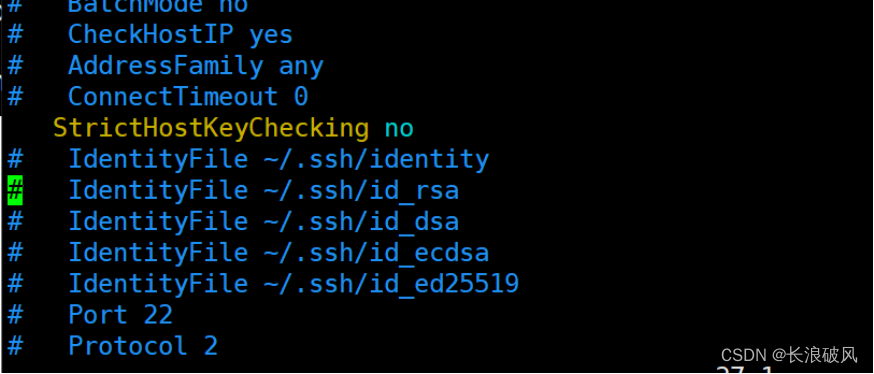
3)错误Permanently added (ECDSA) to the list of known hosts
vim etc/ssh/ssh_config
#StrictHostKeyChecking ask去掉注释,并改为no

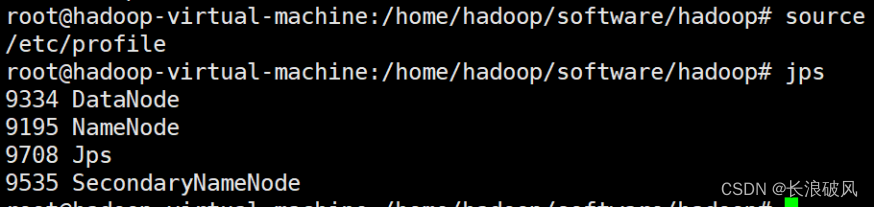
7.验证 Hadoop 启动完成后,可以通过命令 jps 来判断是否成功启动
8.关闭 Hadoop
./sbin/stop-dfs.sh



















 9585
9585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











