







knitr::opts_chunk$set(echo = TRUE)条形图也许是最常用的数据可视化方法,通常用来展示不同的分类下(在x轴上)某个数值型变量的取值(在y轴上)。
绘制条形图时需要特别注意一个重要的细节:有时条形图的图形高度表示的是数据集中变量的频数,有时则表示变量取值本身。
3.1绘制简单条形图
有一个包含了两列数据的数据框,其中一列数据表示条形在x轴上的位置,另一列表示每个条形在y轴上对应的高度。
使用ggplot()函数和geom_bar(stat=”identity”)绘制上述条形图,并分别指定与x轴和y轴对应的变量
library(ggplot2)
library(gcookbook) #为了使用数据
ggplot(pg_mean,aes(x=group,y=weight))+
geom_bar(stat="identity")
当x是连续型(数值型)变量时,条形图的结果与上图会略有不同。此时,ggplot不是只在实际取值处绘制条形,而将在x轴上介于最大值和最小值之间所有可能的取值处绘制条形。
可以使用factor()函数将连续型变量转化为离散型变量。
#没有Time==6的输入
BOD## Time demand
## 1 1 8.3
## 2 2 10.3
## 3 3 19.0
## 4 4 16.0
## 5 5 15.6
## 6 7 19.8#Time是数值型(连续型)变量
str(BOD)## 'data.frame': 6 obs. of 2 variables:
## $ Time : num 1 2 3 4 5 7
## $ demand: num 8.3 10.3 19 16 15.6 19.8
## - attr(*, "reference")= chr "A1.4, p. 270"ggplot(BOD,aes(x=Time,y=demand))+
geom_bar(stat="identity")
#使用factor()函数将Time转化为离散型(分类)变量
ggplot(BOD,aes(x=factor(Time),y=demand))+
geom_bar(stat="identity")
默认设置下,条形图的填充色为黑色且条形图没有边框线,可通过调整fill参数的值来改变条形图的填充色;可通过colour参数为条形图添加边框线。
#将填充色和边框线分别指定为浅蓝色和黑色
ggplot(pg_mean,aes(x=group,y=weight))+
geom_bar(stat="identity",fill="lightblue",colour="black")
在ggplot2中,颜色参数默认使用的是英式拼写colour,而非美式拼写color。然而,ggplot2会在底层将美式拼写重映射为英式拼写,因此输入美式拼写的参数并不影响函数的运行。
3.2绘制簇状条形图
将分类变量映射到fill参数,并运行命令geom_bar(position=”dodge)
library(gcookbook) #为了使用数据
cabbage_exp## Cultivar Date Weight sd n se
## 1 c39 d16 3.18 0.9566144 10 0.30250803
## 2 c39 d20 2.80 0.2788867 10 0.08819171
## 3 c39 d21 2.74 0.9834181 10 0.31098410
## 4 c52 d16 2.26 0.4452215 10 0.14079141
## 5 c52 d20 3.11 0.7908505 10 0.25008887
## 6 c52 d21 1.47 0.2110819 10 0.06674995#分别将Date和Cultivar映射给x和fill
ggplot(cabbage_exp,aes(x=Date,y=Weight,fill=Cultivar))+
geom_bar(position="dodge",stat="identity")
最简单的条形图通常只对应一个绘制在x轴上的分类变量和一个绘制在y轴上的连续型变量。
有时候,想额外添加一个分类变量跟x轴上的分类变量一起对数据进行分组。此时,可通过将该分类变量映射给fill参数来绘制簇状条形图,这里的fill参数用来指定条形的填充色。
这一过程中必须令参数position=”dodge”以使得两组条形在水平方向上错开排列,否则,系统会输出堆积条形图。
与映射给条形图x轴的变量类似,映射给条形填充色参数的变量应该是分类变量而不是连续型变量。
可以通过将geom_bar()中的参数指定为colour=”black”为条形添加黑色边框线;可以通过scale_fill_brewer()或者scale_fill_manual()函数对图形颜色进行设置。
使用RColorBrewer包中的Pastell调色盘对图形进行调色。
ggplot(cabbage_exp,aes(x=Date,y=Weight,fill=Cultivar))+
geom_bar(position="dodge",stat="identity",colour="black")+
scale_fill_brewer(palette="Pastell")## Warning in pal_name(palette, type): Unknown palette Pastell
其他属性诸如颜色colour(指定条形图的边框线颜色)和线型(linestyle)也能用来对变量进行分组,不过,填充色(fill)也许是最合人心意的图形属性
注意,如果分类变量各水平的组合中有缺失项,那么,绘图结果中的条形则对应地略去不绘,同事,临近的条形将自动扩充到相应位置。
ce <- cabbage_exp[1:5,]
ce## Cultivar Date Weight sd n se
## 1 c39 d16 3.18 0.9566144 10 0.30250803
## 2 c39 d20 2.80 0.2788867 10 0.08819171
## 3 c39 d21 2.74 0.9834181 10 0.31098410
## 4 c52 d16 2.26 0.4452215 10 0.14079141
## 5 c52 d20 3.11 0.7908505 10 0.25008887ggplot(ce,aes(x=Date,y=Weight,fill=Cultivar))+
geom_bar(position = "dodge",stat="identity",colour="black")+
scale_fill_brewer(palette="Pastell")## Warning in pal_name(palette, type): Unknown palette Pastell
可以在分类变量组合缺失的那一项为变量y手动输入一个NA值
3.3绘制频数条形图
使用geom_bar()函数,同时不要映射任何变量到y参数
ggplot(diamonds,aes(x=cut))+geom_bar()
#等价于使用geom_bar(stat="bin")
#diamonds
head(diamonds)## carat cut color clarity depth table price x y z
## 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
## 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
## 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
## 4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
## 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
## 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48geom_bar()函数在默认情况下将参数设定为stat=”bin”,该操作会自动计算每组(根据x轴上面的变量进行分组)变量对应的观测数
本例中,x轴对应的是离散型变量,当x轴对应于连续型变量时,会得到一张直方图
ggplot(diamonds,aes(x=carat))+geom_bar()
在本例中,使用geom_bar()和geom_histgram()具有相同的效果
3.4条形图着色
将核实的变量映射到填充色(fill)上即可
选取人口增长最快的十个州:
library(gcookbook)
upc <- subset(uspopchange,rank(Change)>40)
upc## State Abb Region Change
## 3 Arizona AZ West 24.6
## 6 Colorado CO West 16.9
## 10 Florida FL South 17.6
## 11 Georgia GA South 18.3
## 13 Idaho ID West 21.1
## 29 Nevada NV West 35.1
## 34 North Carolina NC South 18.5
## 41 South Carolina SC South 15.3
## 44 Texas TX South 20.6
## 45 Utah UT West 23.8将Region映射到fill并绘制条形图
ggplot(upc,aes(x=Abb,y=Change,fill=Region))+geom_bar(stat="identity")
条形图的默认颜色不太吸引眼球,因此,可能需要借助函数scale_fill_brewer()或scale_fill_manual()重新设定图形颜色
通过把参数指定为color=”black”将条形的边框线设定为黑色
注意:颜色的映射设定是在aes()内部完成的,而颜色的重新设定是在aes()外部完成的:
ggplot(upc,aes(x=reorder(Abb,Change),y=Change,fill=Region))+
geom_bar(stat="identity",colour="black")+
scale_fill_manual(values=c("#669933","#FFCC66"))+
xlab("State")
本例用到了recorder()函数。在本例中,根据条形图的高度进行排序比按照字母顺序对分类变量排序更有意义
3.5对正负条形图分别着色
创建一个对取值正负情况进行标示的变量pos:
library(gcookbook)
csub <- subset(climate,Source=="Berkeley" & Year>=1900)
csub$pos <- csub$Anomaly10y>=0
#csub
head(csub)## Source Year Anomaly1y Anomaly5y Anomaly10y Unc10y pos
## 101 Berkeley 1900 NA NA -0.171 0.108 FALSE
## 102 Berkeley 1901 NA NA -0.162 0.109 FALSE
## 103 Berkeley 1902 NA NA -0.177 0.108 FALSE
## 104 Berkeley 1903 NA NA -0.199 0.104 FALSE
## 105 Berkeley 1904 NA NA -0.223 0.105 FALSE
## 106 Berkeley 1905 NA NA -0.241 0.107 FALSE上述过程准备完毕后,将pos映射给填充色参数(fill)并绘制条形图
注意:这里条形图的参数设定为position=”identity”,可以避免系统因对负值绘制堆积条形而发出的警告信息。
ggplot(csub,aes(x=Year,y=Anomaly10y,fill=pos))+
geom_bar(stat="identity",position="identity")
上面的绘图过程存在一些问题。首先,图形着色效果可能与想要的相反:蓝色是冷色,通常对应于负值;红色是暖色,通常对应于正值。其次,图例显得多余且扰乱视觉。
可以通过scale_fill_manual()参数对图形颜色进行调整,设定参数guide=FALSE可以删除图例。
同时,通过设定边框颜色(colour)和边框线宽度(size)为图形增加一个细黑色边框。
其中,边框线宽度(size)是用来控制边框线宽度的参数,单位是毫米:
ggplot(csub,aes(x=Year,y=Anomaly10y,fill=pos))+
geom_bar(stat="identity",position="identity",colour="black",size=0.25)+
scale_fill_manual(values=c("#CCEEFF","#FFDDDD"),guide=FALSE)
3.6调整条形宽度和条形间距
通过设定geom_bar()函数的参数width可以使条形变得更宽或者更窄。该参数的默认值是0.9,更大的值将是绘制的条形更宽,反之则更窄。
标准宽度的条形图如下:
library(gcookbook)
ggplot(pg_mean,aes(x=group,y=weight))+geom_bar(stat="identity")
#窄些的条形图
ggplot(pg_mean,aes(x=group,y=weight))+geom_bar(stat="identity",width=0.5)
#宽些的条形图(条形图的最大宽度为1)
ggplot(pg_mean,aes(x=group,y=weight))+geom_bar(stat="identity",width=1)
簇状条形图默认组内的条形间距为0.如果希望增加组内条形的间距,则可以通过将width设定得小一些,并令position_dodge的取值大于width
#更窄的簇状条形图可运行:
ggplot(cabbage_exp,aes(x=Date,y=Weight,fill=Cultivar))+
geom_bar(stat="identity",width=0.5,position="dodge")
#添加条形组距可运行:
ggplot(cabbage_exp,aes(x=Date,y=Weight,fill=Cultivar))+
geom_bar(stat="identity",width=0.5,position=position_dodge(0.7))
position=”dodge”是参数默认为0.9的position_dodge()的简写,当需要单独指定该参数的时候,必须输入完整的命令。
width参数的默认值是0.9,position_dodge函数中width参数的默认值也是0.9。更确切的说,position_dodge函数和geom_bar()函数中的width参数的取值是一样的。
下面的四个命令是等价的:
geom_bar(position="dodge")## geom_bar: width = NULL, na.rm = FALSE
## stat_count: width = NULL, na.rm = FALSE
## position_dodgegeom_bar(width=0.9,position=position_dodge())## geom_bar: width = 0.9, na.rm = FALSE
## stat_count: width = 0.9, na.rm = FALSE
## position_dodgegeom_bar(position=position_dodge(0.9))## geom_bar: width = NULL, na.rm = FALSE
## stat_count: width = NULL, na.rm = FALSE
## position_dodgegeom_bar(width=0.9,position=position_dodge(0.9))## geom_bar: width = 0.9, na.rm = FALSE
## stat_count: width = 0.9, na.rm = FALSE
## position_dodge3.7绘制堆积条形图
使用geom_bar()函数,并映射一个变量给填充色参数(fill)即可。该命令会降Date对应到x轴上,并以Cultivar作为填充色
library(gcookbook)
ggplot(cabbage_exp,aes(x=Date,y=Weight,fill=Cultivar))+
geom_bar(stat="identity")
弄清楚图形对应的数据结构有助于理解图形的绘制过程
cabbage_exp## Cultivar Date Weight sd n se
## 1 c39 d16 3.18 0.9566144 10 0.30250803
## 2 c39 d20 2.80 0.2788867 10 0.08819171
## 3 c39 d21 2.74 0.9834181 10 0.31098410
## 4 c52 d16 2.26 0.4452215 10 0.14079141
## 5 c52 d20 3.11 0.7908505 10 0.25008887
## 6 c52 d21 1.47 0.2110819 10 0.06674995默认绘制的条形图有一个问题,即条形的堆积顺序与图例顺序是相反的。可以通过guides()函数对图例顺序进行调整,并指定图例所对应的需要调整的图形属性,本例中对应的是填充色(fill)
ggplot(cabbage_exp,aes(x=Date,y=Weight,fill=Cultivar))+
geom_bar(stat="identity")+
guides(fill=guide_legend(reverse=TRUE))
如果想调整条形的堆叠顺序,可以通过指定图形映射中的参数order=desc()来实现:
library(plyr) #为了使用desc()函数
ggplot(cabbage_exp,aes(x=Date,y=Weight,fill=Cultivar,order=desc(Cultivar)))+
geom_bar(stat="identity")
当然,也可通过调整数据框中对应列的因子顺序来实现上述操作,但需谨慎进行该操作,因为对数据进行修改可能导致其他分析结果也发生改变。
为了获得效果更好的条形图,保持逆序的图例顺序不变,同时,使用scale_fill_brewer()函数得到一个新的调色板,最后设定colour=”black”为条形增加一个Hisense边框线
ggplot(cabbage_exp,aes(x=Date,y=Weight,fill=Cultivar))+
geom_bar(stat="identity",colour="black")+
guides(fill=guide_legend(reverse=TRUE))+
scale_fill_brewer(palette="Pastell")## Warning in pal_name(palette, type): Unknown palette Pastell
3.8绘制百分比堆积条形图
首先,通过plyr包中的ddply()函数和transform()函数将每组条形对应的数据标准化为100%格式,之后,针对计算得到的结果绘制堆积条形图即可
library(gcookbook)
library(plyr)以Date为切割变量()对每组数据进行transform()
ce <- ddply(cabbage_exp,"Date",transform, percent_weight=Weight/sum(Weight)*100)
ggplot(ce,aes(x=Date,y=percent_weight,fill=Cultivar))+
geom_bar(stat="identity")
用ddply()函数计算每组Date变量对应的百分比。本例中,ddply()函数根据指定的变量Date对数据框cabbage_exp进行分组,并对各组数据执行transform()函数(ddply()函数中设定的其他参数也会传递给该函数)
下面是cabbage_exp数据,从中可以看出ddply()命令对其进行操作的过程
cabbage_exp## Cultivar Date Weight sd n se
## 1 c39 d16 3.18 0.9566144 10 0.30250803
## 2 c39 d20 2.80 0.2788867 10 0.08819171
## 3 c39 d21 2.74 0.9834181 10 0.31098410
## 4 c52 d16 2.26 0.4452215 10 0.14079141
## 5 c52 d20 3.11 0.7908505 10 0.25008887
## 6 c52 d21 1.47 0.2110819 10 0.06674995ce <- ddply(cabbage_exp,"Date",transform,percent_weight=Weight/sum(Weight)*100)计算出百分比之后,就可以按照绘制常规堆积条形图的方法来绘制百分比堆积条形图了。
跟常规堆积条形图一样,可以调整百分比堆积条形图的图例顺序、更换调色板及添加边框线。
ggplot(ce,aes(x=Date,y=percent_weight,fill=Cultivar))+
geom_bar(stat="identity",colour="black")+
guides(fill=guide_legend(reverse=TRUE))+
scale_fill_brewer(palette="Pastell")## Warning in pal_name(palette, type): Unknown palette Pastell
3.9 添加数据标签
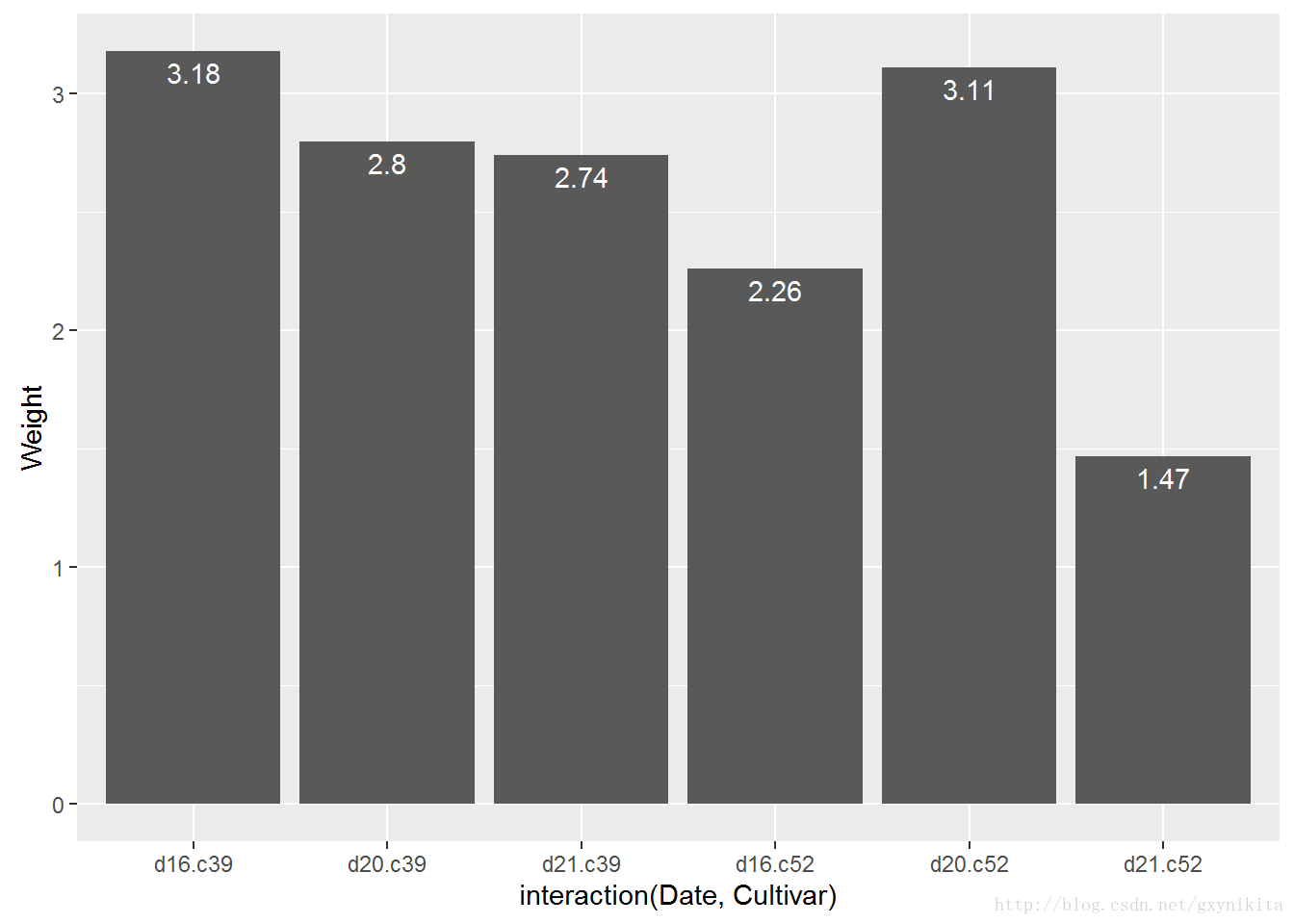
在绘图命令中加上geom_text()即可为条形图添加数据标签。运行命令时,需要分别指定一个变量映射给x、y和标签本身。
通过设定vjust(竖直调整数据标签位置)可以将标签位置移动至条形图顶端的上方或者下方。
library(gcookbook) #为了使用数据
#在条形图顶端下方
ggplot(cabbage_exp,aes(x=interaction(Date, Cultivar),y=Weight))+
geom_bar(stat="identity")+
geom_text(aes(label=Weight),vjust=1.5,colour="white")
```
```{r}
#在条形图顶端上方
ggplot(cabbage_exp,aes(x=interaction(Date, Cultivar),y=Weight))+
geom_bar(stat="identity")+
geom_text(aes(label=Weight),vjust=-0.2)
在上图中,数据标签的y轴坐标位于每个条形的顶端中心位置;通过设定竖直调整(vjust)可以将数据标签置于条形图顶端的上方或者下方。
这种做法的不足之处在于当数据标签被置于条形图顶端上方时有可能使数据标签溢出绘图区域。
为了修正这个问题,可以手动设定y轴的范围,也可以保持竖直调整不变,而令数据标签的y轴坐标高于条形图顶端。
后一种办法的不足之处在于,当想将数据标签完全置于条形图顶端上方或者下方的时候,竖直方向调整的幅度依赖于y轴的数据范围;而更改vjust时,数据标签离条形顶端的距离会根据条形图的高度自动进行调整。
将y轴上限变大
ggplot(cabbage_exp,aes(x=interaction(Date, Cultivar),y=Weight))+
geom_bar(stat="identity")+
geom_text(aes(label="Weight"),vjust=-0.2)+
ylim(0, max(cabbage_exp$Weight)*1.05)
设定标签的y轴位置使其略高于条形图顶端–y轴范围会自动调整
ggplot(cabbage_exp, aes(x=interaction(Date, Cultivar),y=Weight))+
geom_bar(stat="identity")+
geom_text(aes(y=Weight+0.1,label=Weight))
对于簇状条形图,需要设定position=position_dodge()并给其一个参数来设定分类间距。
分类间距的默认值是0.9,因为簇状条形图的条形更窄,所以,需要使用字号(size)来缩小数据标签的字体大小以匹配条形宽度。
数据标签的默认字号是5,这里将字号设定为3使其看起来更小。
ggplot(cabbage_exp,aes(x=Date,y=Weight,fill=Cultivar))+
geom_bar(stat="identity",position="dodge")+
geom_text(aes(label=Weight),vjust=1.5,colour="white",position=position_dodge(.9),size=3)
向堆积条形图添加数据标签之前,要先对每组条形对应的数据进行累积求和。
在进行本操作之前,需保证数据的合理排序,否则,可能计算出错误的累积和。
可以利用plyr包中的arrange()函数完成上述操作,plyr包是一个随ggplot2包加载的软件包。
library(plyr)
#根据日期和性别对数据进行排序
ce <- arrange(cabbage_exp, Date, Cultivar)确认数据合理排序之后,可以借助ddply()函数以Date为分组变量对数据进行分组,并计算每组数据对应的变量Weight的累积和。
#计算累积和
ce <- ddply(ce,"Date",transform,label_y=cumsum(Weight))
ce## Cultivar Date Weight sd n se label_y
## 1 c39 d16 3.18 0.9566144 10 0.30250803 3.18
## 2 c52 d16 2.26 0.4452215 10 0.14079141 5.44
## 3 c39 d20 2.80 0.2788867 10 0.08819171 2.80
## 4 c52 d20 3.11 0.7908505 10 0.25008887 5.91
## 5 c39 d21 2.74 0.9834181 10 0.31098410 2.74
## 6 c52 d21 1.47 0.2110819 10 0.06674995 4.21ggplot(ce,aes(x=Date,y=Weight,fill=Cultivar))+
geom_bar(stat="identity")+
geom_text(aes(y=label_y,label=Weight),vjust=1.5,colour="white")
使用数据标签时,对堆叠顺序的调整最好是通过在计算累积和之前修改因子的水平顺序来完成。
另一种修改堆叠顺序的方法是在标度中指定breaks参数,但在这里此方法并不合适,因为累计求和的顺序与堆叠的顺序并不一致。
如果想把数据标签置于条形中部,须对累计求和的结果加以调整,并同时略去geom_bar()函数中对y偏移量(offset)的设置:
ce <- arrange(cabbage_exp,Date,Cultivar)
#计算y轴的位置,将数据标签置于条形中部
ce <- ddply(ce,"Date",transform,label_y=cumsum(Weight)-0.5*Weight)
ggplot(ce,aes(x=Date,y=Weight,fill=Cultivar))+
geom_bar(stat="identity")+
geom_text(aes(y=label_y,label=Weight),colour="White")
为了得到效果更好的条形图,修改一下图例顺序和颜色,将数据标签置于条形中间,同时通过字号参数(size)缩小标签字号,并调用paste函数在标签后面添加“kg”,为了使得标签保留两位小数还需调用format函数:
ggplot(ce,aes(x=Date,y=Weight,fill=Cultivar))+
geom_bar(stat="identity",colour="black")+
geom_text(aes(y=label_y,label=paste(format(Weight,nsmall=2),"kg")),size=4)+
guides(fill=guide_legend(reverse=TRUE))+
scale_fill_brewer(palette="Pastell")## Warning in pal_name(palette, type): Unknown palette Pastell
3.10绘制Cleveland点图
有时人们会用Cleverland点图来替代条形图以减少图形造成的视觉混乱并使图形更具可读性。
最简单的绘制Cleverland点图的方法是直接运行geom_point()命令。
library(gcookbook) #为了使用数据
tophit <- tophitters2001[1:25,] #取出tophitters数据集中的前25个数据
ggplot(tophit,aes(x=avg,y=name))+geom_point()
#tophitters2011数据集包含很多列,这里只看其中三列:
tophit[,c("name","lg","avg")]## name lg avg
## 1 Larry Walker NL 0.3501
## 2 Ichiro Suzuki AL 0.3497
## 3 Jason Giambi AL 0.3423
## 4 Roberto Alomar AL 0.3357
## 5 Todd Helton NL 0.3356
## 6 Moises Alou NL 0.3314
## 7 Lance Berkman NL 0.3310
## 8 Bret Boone AL 0.3307
## 9 Frank Catalanotto AL 0.3305
## 10 Chipper Jones NL 0.3304
## 11 Albert Pujols NL 0.3288
## 12 Barry Bonds NL 0.3277
## 13 Sammy Sosa NL 0.3276
## 14 Juan Pierre NL 0.3274
## 15 Juan Gonzalez AL 0.3252
## 16 Luis Gonzalez NL 0.3251
## 17 Rich Aurilia NL 0.3239
## 18 Paul Lo Duca NL 0.3196
## 19 Jose Vidro NL 0.3189
## 20 Alex Rodriguez AL 0.3180
## 21 Cliff Floyd NL 0.3171
## 22 Shannon Stewart AL 0.3156
## 23 Jeff Cirillo NL 0.3125
## 24 Jeff Conine AL 0.3111
## 25 Derek Jeter AL 0.3111上图中的名字是按照字母先后顺序排列的,这种排列方式用处不大。通常,点图中会根据x轴对应的连续变量的大小取值对数据进行排序。
尽管tophit的行顺序恰好与avg的大小顺序一致,但这并不意味着在图中也是这样排序的。在点图的默认设置下,坐标轴上的变量通常会根据变量类型自动选取合适的排序方式。
本例中变量name属于字符串类型,因此,点图根据字母先后顺序对其进行了排序。
当变量是因子型变量时,点图会根据定义好的因子水平顺序对其进行排序。
现在,根据变量avg对变量name进行排序。
可以借助recorder(name,avg)函数实现这一过程。
该命令会先将name转化为因子,然后,根据avg对其进行排序。
为使图形效果更好,借助图形主题系统(Theming System)删除垂直网格线,并将水平网格线的线型修改为虚线。
ggplot(tophit,aes(x=avg,y=reorder(name,avg)))+
geom_point(size=3)+ #使用更大的点
theme_bw()+
theme(panel.grid.major.x=element_blank(), panel.grid.minor.x=element_blank(), panel.grid.major.y=element_line(colour="grey60",linetype="dashed"))
可以将点图的x轴和y轴互换,互换后,x轴对应于姓名,y轴将对应于数值,如下图所示。也可以将数据标签旋转60°。
ggplot(tophit,aes(x=reorder(name,avg),y=avg))+
geom_point(size=3)+ #使用更大的点
theme_bw()+
theme(axis.text.x=element_text(angle=60,hjust=1), panel.grid.major.y=element_blank(), panel.grid.minor.y=element_blank(), panel.grid.major.x=element_line(colour="grey60",linetype="dashed"))
有时候,根据其他变量对样本进行分组很有用。
这里根据因子lg对样本进行分组,因子lg对应有NL和AL两个水平,分别表示国家队(National League)和美国队(American League)。
依次根据lg和avg对变量进行排序。遗憾的是reorder()函数只能根据一个变量对因子水平进行排序,所以只能手动实现上述过程。
#提取出name变量,依次根据变量lg和avg对其进行排序
nameorder <- tophit$name[order(tophit$lg,tophit$avg)]
#将name转化为因子,因子水平与nameorder一致
tophit$name <- factor(tophit$name,levels=nameorder)绘制点图时,把lg变量映射到点的颜色属性上。
借助geom_segment()函数用“以数据点为端点的线段”代替贯穿全图的网格线。
注意geom_segment()函数需要设定x、y、xend和yend四个参数:
ggplot(tophit,aes(x=avg,y=name))+
geom_segment(aes(yend=name),xend=0,colour="grey50")+
geom_point(size=3,aes(colour=lg))+
scale_colour_brewer(palette="Set1",limits=c("NL","AL"))+
theme_bw()+
theme(panel.grid.major.y=element_blank(), #删除水平网格线
legend.position=c(1,0.55), #将图例放置在绘图区域中 legend.justification=c(1,0.5))
另外一种分组展示数据的方式是分面,如下图所示。
分面条形图中的条形的堆叠顺序与上图的堆叠顺序有所不同;要修改分面显示的堆叠顺序只有通过调整lg变量的因子水平来实现。
ggplot(tophit,aes(x=avg,y=name))+
geom_segment(aes(yend=name),xend=0,colour="grey50")+
geom_point(size=3,aes(colour=lg))+
scale_colour_brewer(palette="Set1",limits=c("NL","AL"),guide=FALSE)+
theme_bw()+
theme(panel.grid.major.y=element_blank())+
facet_grid(lg~.,scales="free_y",space="free_y")
本系列笔记所涉及的知识、数据等信息的版权归原书作者所有,请购买正版图书。O(∩_∩)O谢谢~
参考资料:R数据可视化手册


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









