







一些小知识:
- 关于事务:时序数据库是没有事务的,它和关系数据库的应用场景不同,通常情况下不需要多点同时操作同一条数据,而且要保证极高的吐出量,事务太消耗资源,并且时序数据库提供了覆写的功能,能让用户后期修改数据。
- 关于iotdb的写入速度:(后面引用官方的内容)时序数据库 IoTDB 可通过底层文件 Apache TsFile 支持列式数据写入,达到毫秒级数据接入,并首创乱序分离存储引擎,大幅提升弱网环境产生的乱序数据处理效率,稳定实现千万级/秒数据写入。
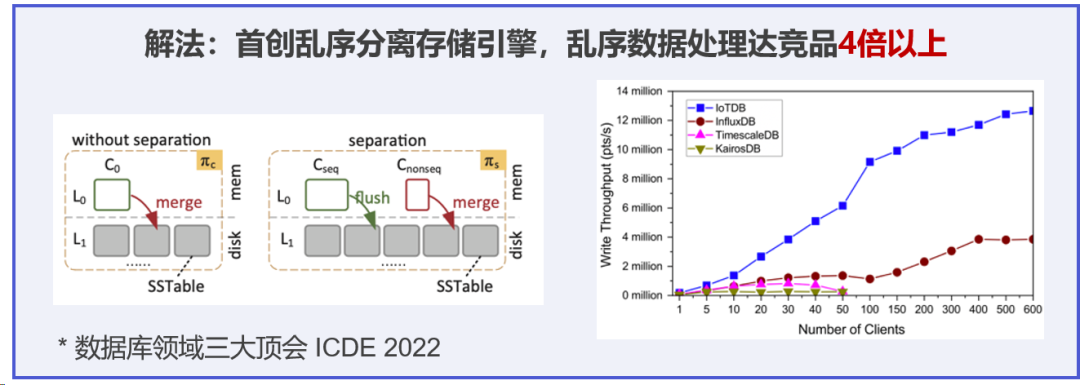
(目前即使用开源版本,从我个人角度来看,系统用的1.3.x的版本运行了一年左右的时间,没有出现任何问题,可想IoTDB的稳定性,不亏为国货之光!而且还有官方的交流群,里面的问答还都非常的积极,真的是很难得!)
V2.0.2正式版
前两天IoTDB正式发布了V2.0.2正式版,作为树表双模型正式版本,主要新增表模型权限管理、用户管理以及相关操作鉴权,并新增了表模型 UDF、系统表和嵌套查询等功能。补齐了之前beta版本中权限相关的内容。
在这个版本中算是正式的带来了表模型,虽然表模型对我我个人在我的应用场景下感觉不大,对我来说就是展示层“列转行”了一下。(因为从开始从网上搜索对比时序数据库,团队就选定了国产IoTDB,不涉及一些迁移),其实内部上也是“列转行”,只是对同一种数据文件的不同展示,官方也有对应的说明,使用的是同一个底层数据文件TsFile。
所谓的表模型和树模型其实就是两种视图view。其实在之前的workbench中也有所提现。在workbench中的数据模型里面,就是树模式的展现,根就是root。
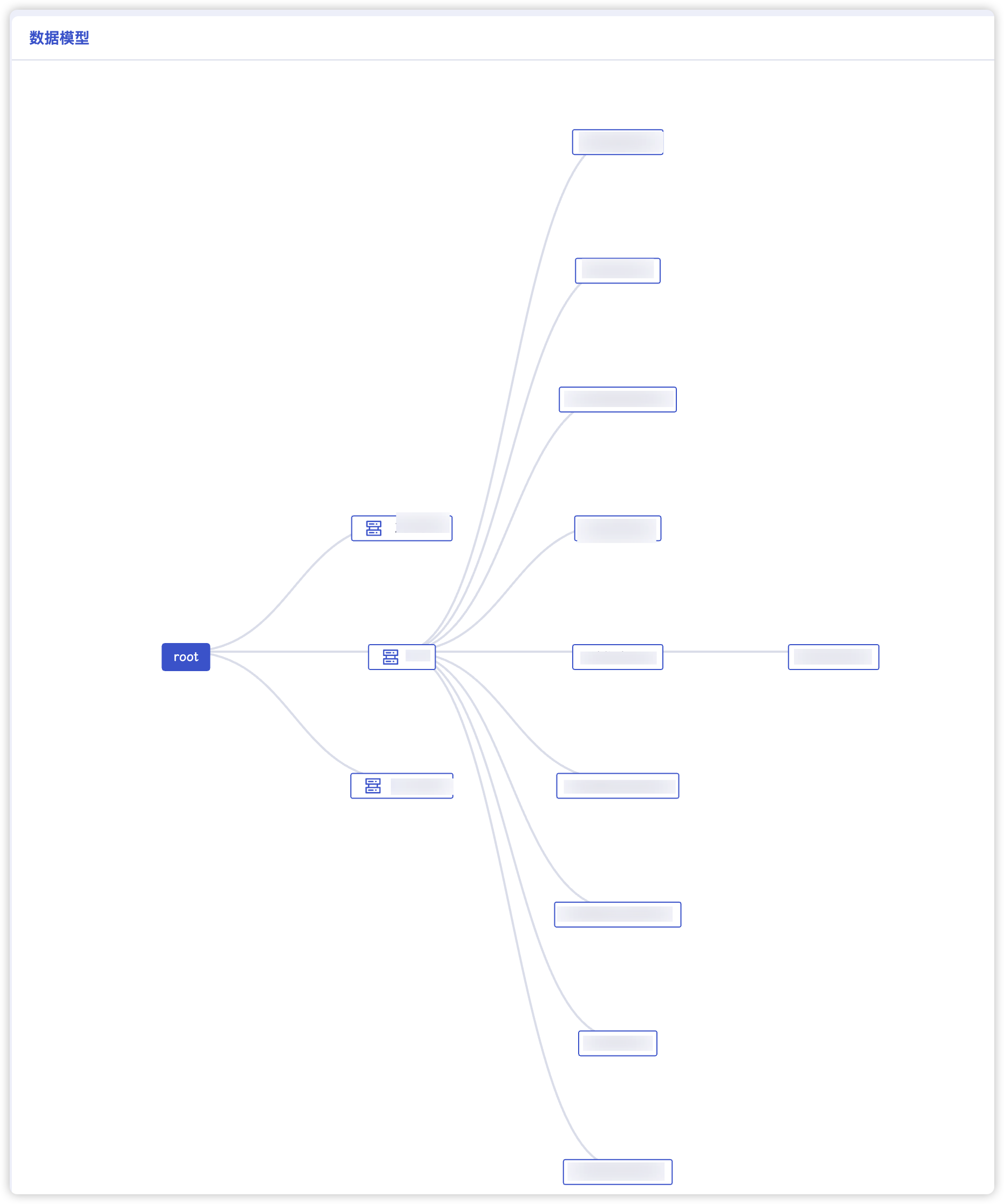
在数据查询页面,所有的点位的路径都在column上
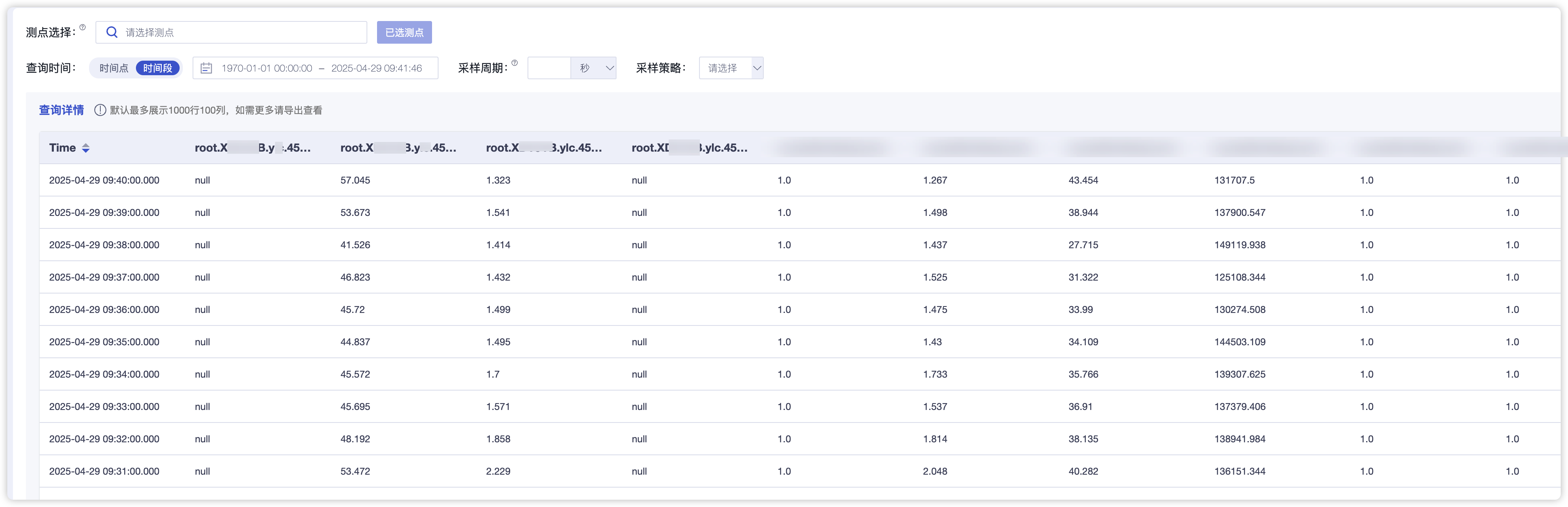
而表模式从另一种角度理解的话,就是把time后面的column名称中的相同部分进行拆分放到了前面,拆分几项就多增加几列,方便看具体的点位内容。
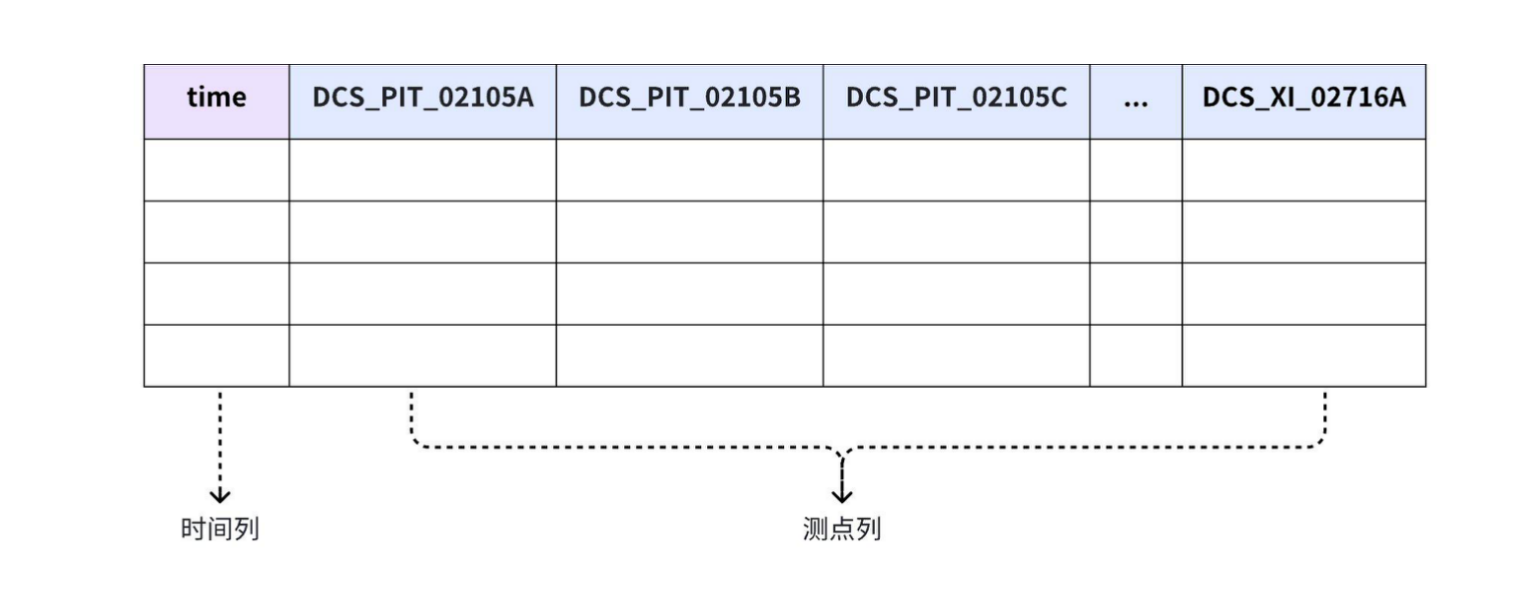
注:表模式的column不能用root开头!
应用场景
至于两种模式的应用场景,我个人觉得团队的经验还是很重要的,整体还是需要根据实际情况来,下面贴出官方的建议(但也只是建议,大多数对的并不一定适合你自身的场景)
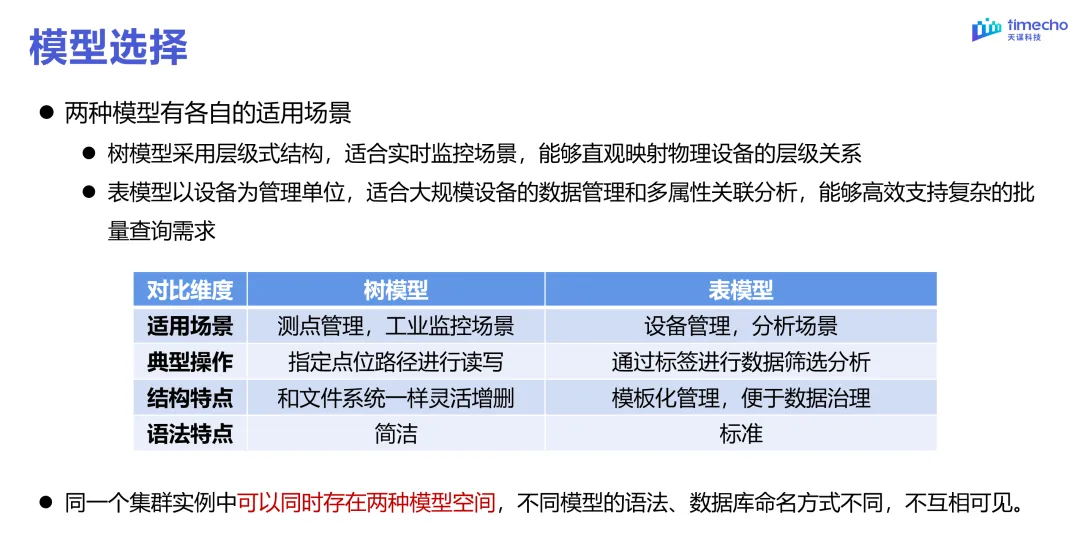
虽然IoTDB支持两种模式的切换,我个人更建议如果有资源的话,而且你的业务场景也需要两种场景的话,不如弄两份“单机”数据库,这样可以一个专门负责实时采集,一个负责分析。
表模型的链接方式
先附上官方的图(这个在说明文档里面可能没有,在教学视频里面。)

我个人用的是java,也就是把之前用的SessionPool前面都加上Table。至于其它方式注意图片上面的红字内容!
IoTDB与其他时序数据库的综合对比
下面的内容来自deepseek(现在有Ai了,要用好Ai,从deepseek给我的反馈,我更庆幸我们的团队从最开始就选择了IoTDB,尤其是他们的群聊里面回复疑问真的很及时!)
1. 架构设计与分布式能力
-
IoTDB
-
原生分布式优化:IoTDB专为物联网场景设计,支持灵活的分布式架构,提供共识协议统一框架(如IoTConsensus、RatisConsensus),用户可根据需求选择不同算法,兼顾性能与一致性110。其数据分区和负载均衡策略适应亿级设备与跨十年时间范围的数据管理,最大支持PB级存储14。
-
轻量级部署:支持单机部署,无需依赖Hadoop或Zookeeper等组件,资源占用低,适合边缘设备110。
-
-
对比其他数据库
-
HBase/OpenTSDB:依赖HDFS和Zookeeper,架构复杂,扩展性受限;HBase采用链式复制(Chain Replication),写入延迟较高,故障恢复复杂1410。
-
TimescaleDB:基于PostgreSQL扩展,支持SQL兼容,但时序优化不如IoTDB深入,分布式能力依赖外部分片策略7。
-
2. 边云同步与边缘计算支持
-
IoTDB
-
内置流处理引擎:支持端边云实时同步,自适应选择流式或文件(TsFile)传输,断点续传和低带宽优化,适合边缘环境1310。
-
近存储计算:通过TsFile高压缩传输,减少网络流量,支持边缘侧数据预处理19。
-
-
其他数据库
-
HBase:需借助Kafka或Flink实现同步,开发运维成本高10。
-
InfluxDB:单机版开源,缺乏分布式支持,长期数据查询性能下降3。
-
3. 性能表现与存储优化
-
IoTDB
-
写入与查询性能:在TPCx-IoT基准测试中,IoTDB的吞吐量是HBase的6.6倍,性价比提升11.8倍58。支持千万点/秒写入,10年跨度的历史数据查询秒级响应9。
-
高压缩比:采用复合压缩算法(如Gorilla、SDT),存储成本降低10倍,适用于振动波形等高频数据69。
-
-
对比其他数据库
-
OpenTSDB:依赖HBase存储,查询受限于读放大,压缩效率较低4。
-
TimescaleDB:支持自动分片和压缩,但时序压缩率不及IoTDB,且写入性能在工业级场景中表现较弱7。
-
4. 部署易用性与运维成本
-
IoTDB
-
一键部署:支持单机与集群模式,无需复杂依赖,运维工具丰富(如监控指标上千种)110。
-
动态扩展:节点增减无需停机,适应业务弹性需求410。
-
-
其他数据库
-
HBase/OpenTSDB:需部署HDFS、Zookeeper等组件,运维复杂度高,扩展需人工干预分区策略14。
-
TimescaleDB:依赖PostgreSQL生态,轻量级场景资源占用较高7。
-
5. 功能特性与扩展性
-
IoTDB
-
分析与计算:内置30+函数(如标准差、频域分析),支持时序聚合、异常检测及机器学习框架(AINode)47。
-
动态模式:支持树形数据模型,灵活适应设备层级结构,动态更新元数据27。
-
-
对比其他数据库
-
OpenTSDB:仅支持基础聚合(如sum/avg),复杂计算需依赖Spark等外部系统4。
-
TimescaleDB:完整SQL支持,适合传统数据分析,但缺乏原生时序语义优化7。
-
6. 应用场景与行业实践
-
IoTDB
-
工业物联网:支持端-边-云协同,应用于能源电力(如宝武钢铁)、车联网(千万级数据点/秒)等场景,实现长周期数据存储与实时分析39。
-
案例:宝武集团通过IoTDB替换OpenTSDB,写入性能提升10倍,存储成本降低90%,支持振动波形数据纳秒级处理9。
-
-
其他数据库
-
InfluxDB:适合短期监控数据,长期存储性能不足3。
-
HBase:适用于数据中心大规模存储,但边缘场景适配性差10。
-
7. 产品迭代与生态建设
-
IoTDB:代码提交活跃(周均100-300次),持续优化压缩算法与边缘计算支持,社区生态与Hadoop/Spark深度集成47。
-
OpenTSDB:发展停滞,依赖老旧HBase生态,功能迭代缓慢4。
总结
IoTDB在工业物联网场景中展现出显著优势,尤其在分布式架构灵活性、边云协同、高压缩存储及长期数据管理方面领先。相比HBase、OpenTSDB等依赖传统大数据组件的数据库,IoTDB更适合资源受限的边缘环境与海量时序数据处理;而对比TimescaleDB等关系型时序库,其原生时序优化更贴合工业需求。未来,随着端边云协同需求的增长,IoTDB有望进一步巩固其作为时序数据库领航者的地位。

















 8537
8537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









