







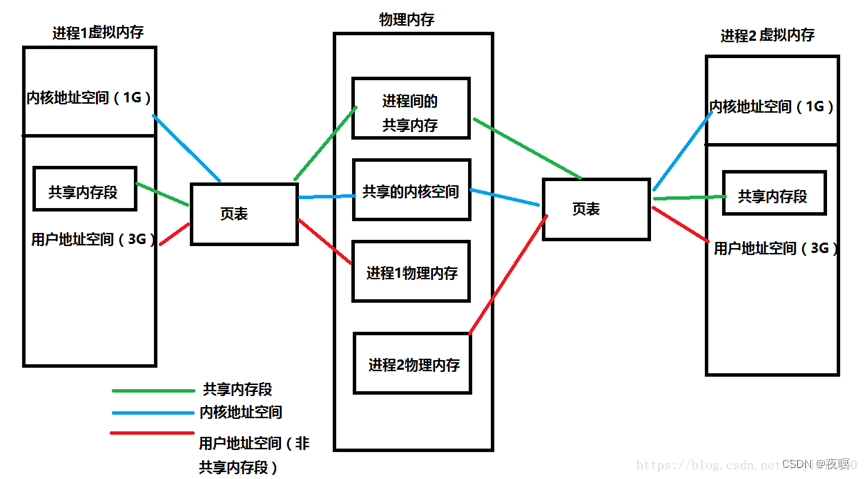
linux之内存分析(arm32)
一、内存和MMU
分析Linux内存相关内容之前先了解一下相关基础知识
0 虚拟内存和物理内存
操作系统有虚拟内存与物理内存的概念。在很久以前,还没有虚拟内存概念的时候,程序寻址用的都是物理地址。程序能寻址的范围是有限的,这取决于CPU的地址线条数。比如在32位平台下,寻址的范围是2^32也就是4G。并且这是固定的,如果没有虚拟内存,且每次开启一个进程都给4G的物理内存,就可能会出现很多问题:
- 因为我的物理内存时有限的,当有多个进程要执行的时候,都要给4G内存,很显然你内存小一点,这很快就分配完了,于是没有得到分配资源的进程就只能等待。当一个进程执行完了以后,再将等待的进程装入内存。这种频繁的装入内存的操作是很没效率的
- 由于指令都是直接访问物理内存的,那么我这个进程就可以修改其他进程的数据,甚至会修改内核地址空间的数据,这是我们不想看到的
- 因为内存时随机分配的,所以程序运行的地址也是不正确的。
于是针对上面会出现的各种问题,虚拟内存就出来了。这个虚拟内存你可以认为,每个进程都认为自己拥有4G的空间,这只是每个进程认为的,但是实际上,在虚拟内存对应的物理内存上,可能只对应的一点点的物理内存,实际用了多少内存,就会对应多少物理内存。
进程得到的这4G虚拟内存是一个连续的地址空间(这也只是进程认为),而实际上,它通常是被分隔成多个物理内存碎片,还有一部分存储在外部磁盘存储器上,在需要时进行数据交换。
进程开始要访问一个地址,它可能会经历下面的过程
- 每次我要访问地址空间上的某一个地址,都需要把地址翻译为实际物理内存地址
- 所有进程共享这整一块物理内存,每个进程只把自己目前需要的虚拟地址空间映射到物理内存上
- 进程需要知道哪些地址空间上的数据在物理内存上,哪些不在(可能这部分存储在磁盘上),还有在物理内存上的哪里,这就需要通过页表来记录
- 页表的每一个表项分两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)
- 当进程访问某个虚拟地址的时候,就会先去看页表,如果发现对应的数据不在物理内存上,就会发生缺页异常
- 缺页异常的处理过程,操作系统立即阻塞该进程,并将硬盘里对应的页换入内存,然后使该进程就绪,如果内存已经满了,没有空地方了,那就找一个页覆盖,至于具体覆盖的哪个页,就需要看操作系统的页面置换算法是怎么设计的了。
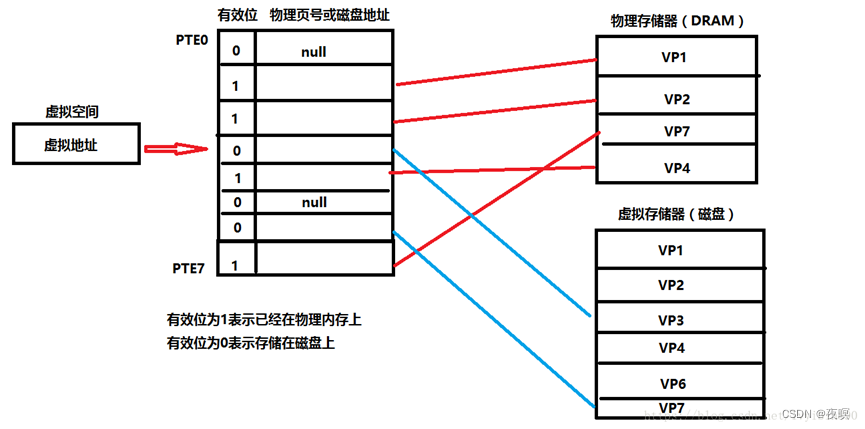
页表工作原理如下
- 我们的cpu想访问虚拟地址所在的虚拟页(VP3),根据页表,找出页表中第三条的值.判断有效位。 如果有效位为1,DRMA缓存命中,根据物理页号,找到物理页当中的内容,返回。
- 若有效位为0,参数缺页异常,调用内核缺页异常处理程序。内核通过页面置换算法选择一个页面作为被覆盖的页面,将该页的内容刷新到磁盘空间当中。然后把VP3映射的磁盘文件缓存到该物理页上面。然后页表中第三条,有效位变成1,第二部分存储上了可以对应物理内存页的地址的内容。
- 缺页异常处理完毕后,返回中断前的指令,重新执行,此时缓存命中,执行1。
- 将找到的内容映射到告诉缓存当中,CPU从告诉缓存中获取该值,结束。
利用虚拟内存机制的优点 - 既然每个进程的内存空间都是一致而且固定的(32位平台下都是4G),所以链接器在链接可执行文件时,可以设定内存地址,而不用去管这些数据最终实际内存地址,这交给内核来完成映射关系
- 当不同的进程使用同一段代码时,比如库文件的代码,在物理内存中可以只存储一份这样的代码,不同进程只要将自己的虚拟内存映射过去就好了,这样可以节省物理内存
- 在程序需要分配连续空间的时候,只需要在虚拟内存分配连续空间,而不需要物理内存时连续的,实际上,往往物理内存都是断断续续的内存碎片。这样就可以有效地利用我们的物理内存
再来总结一下虚拟内存是怎么工作的
- 当每个进程创建的时候,内核会为进程分配4G的虚拟内存,当进程还没有开始运行时,这只是一个内存布局。实际上并不立即就把虚拟内存对应位置的程序数据和代码(比如.text .data段)拷贝到物理内存中,只是建立好虚拟内存和磁盘文件之间的映射就好(叫做存储器映射)。这个时候数据和代码还是在磁盘上的。当运行到对应的程序时,进程去寻找页表,发现页表中地址没有存放在物理内存上,而是在磁盘上,于是发生缺页异常,于是将磁盘上的数据拷贝到物理内存中。
- 另外在进程运行过程中,要通过malloc来动态分配内存时,也只是分配了虚拟内存,即为这块虚拟内存对应的页表项做相应设置,当进程真正访问到此数据时,才引发缺页异常。
- 可以认为虚拟空间都被映射到了磁盘空间中(事实上也是按需要映射到磁盘空间上,通过mmap,mmap是用来建立虚拟空间和磁盘空间的映射关系的)
1 映射关系
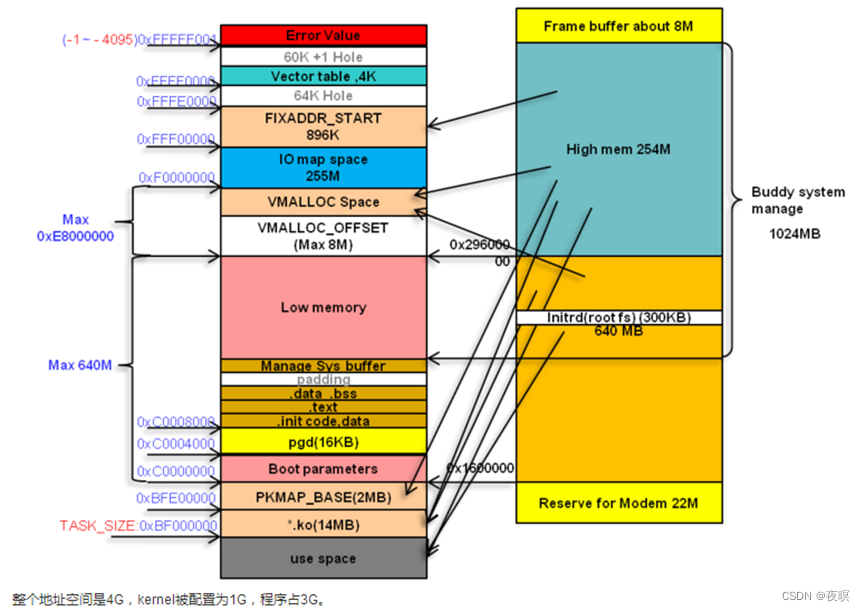
如果实际物理内存比较小,比如实际上只有512M的物理内存,那么此时已经完全被低端内存映射完了,那没有被映射的内核区怎么处理?
当然还是按照普通虚拟空间的管理方式,以页表的非线性映射方式使用物理内存。具体来说,在整个内核空间中去除固定映射区,然后在剩余部分中再去除其开头部分的一个8MB隔离区,余下的就是映射方式与用户空间相同的普通虚拟内存映射区。在这个区,虚拟地址和物理地址不仅不存在固定映射关系,而且通过调用内核函数vmalloc()获得动态内存,故这个区就被称为vmalloc分配区,如下图所示:
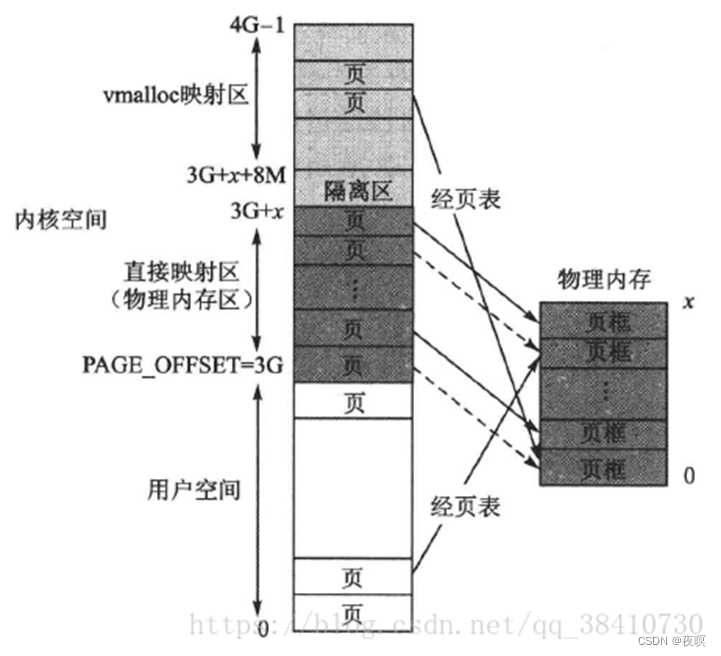
这里说明一下:这里说的内核空间与物理页框的固定映射,实质上是内核页对物理页框的一种“预定”,并不是说这些页就“霸占”了这些物理页框。即只有当虚拟页真正需要访问物理页框时,虚拟页才与物理页框绑定。而平时,当某个物理页框不被与它对应的虚拟页所使用时,该页框完全可以被用户空间以及后面所介绍的内核kmalloc分配区使用。
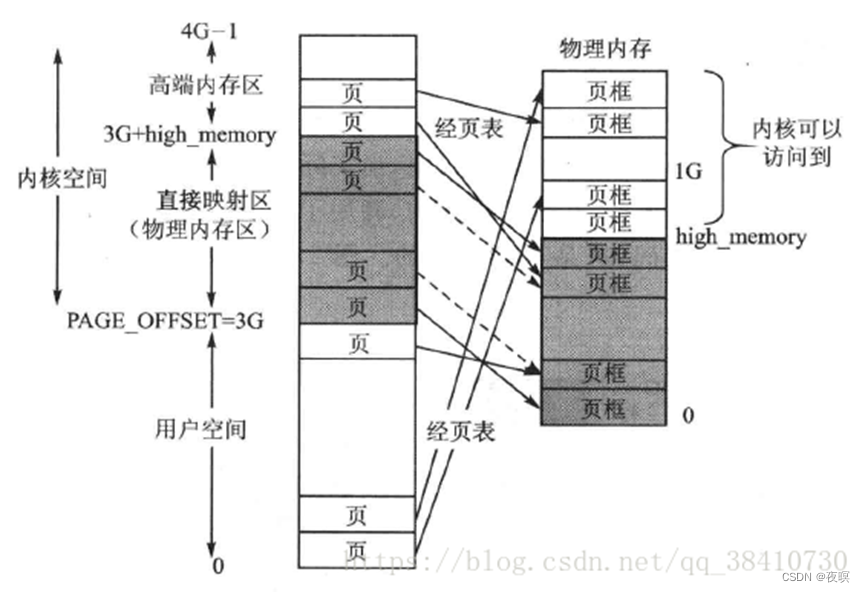
当然,如果内存较大,则有如下图所示
2.MMU
2.1什么是MMU
MMU是Memory Management Unit的缩写,中文名是内存管理单元,它是中央处理器(CPU)中用来管理虚拟存储器、物理存储器的控制线路,同时也负责虚拟地址映射为物理地址,以及提供硬件机制的内存访问授权,多用户多进程操作系统。
物理地址:(英语:physical address),也叫实地址(real address)、二进制地址(binary address),它是在地址总线上,以电子形式存在的,使得数据总线可以访问主存的某个特定存储单元的内存地址。
虚拟地址:虚拟地址是相对于物理地址来说的。虚拟地址的提出,主要是为了解决在操作系统中,多线程内存地址重复,大进程在小内存运行等问题,在32位系统中,虚拟地址空间中有4G,在操作系统中程序中使用的都是虚拟地址
2.2MMU的作用
简单的说,mm的作用有两点,地址翻译和内存保护。
2.2.1 地址翻译
在处理器上我们会运行一个操作系统,如linux,windows等,用户编写的源程序,需要经过编译,链接,生成可执行程序,然后被操作系统加载执行。在链接的时候通常我们要指定一个链接脚本,链接脚本的作用有很多,其中一个的作用是控制可执行文件的section的符号的内存布局,也就是控制可执行程序将来要在内存中哪里放置。
操作系统会按照可执行程序的要求将其加载到内存的对应地址执行。假如用户A编写的应用程序的链接地址范围是0x100-0x200,用户B编写的应用程序的链接地址范围是0x100-0x200,这是很有可能的。因为给操作系统提供应用程序的开发者很多,不可能为每个开发者限定使用那些内存。
如果直接执行在物理内存的话会出现如下情形,执行程序A的时候就不能执行程序B,执行程序B的时候就不能执行程序A,因为它们执行时会覆盖对方内存中的程序。为了解决这个问题,必须引入虚拟地址,为此操作系统和处理器都做了处理,添加了mmu,让其进行地址翻译。在程序载入内存的时候,操作系统会为其建立地址翻译表,处理器执行不同应用程序的时候,使用不同的地址翻译表。如下图所示。
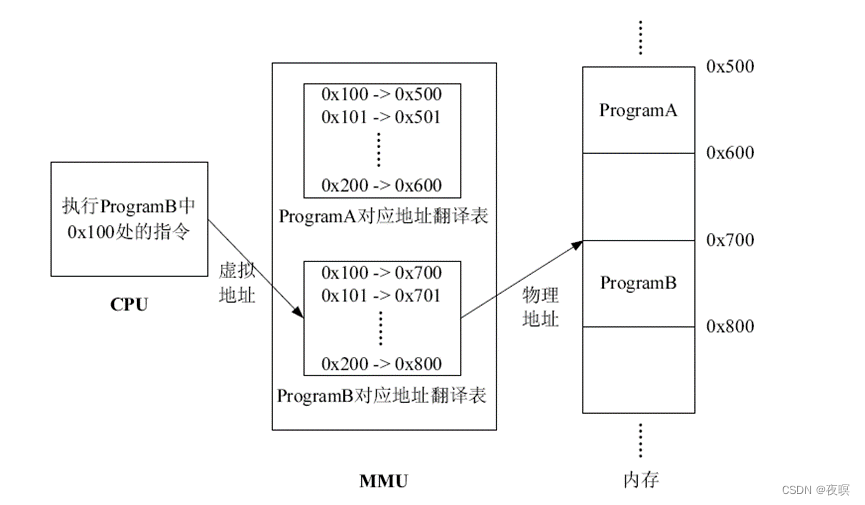
ProgramA被加载到物理地址地址0x500-0x600处,ProgramB被加载到物理地址0x700-0x800处,同时建立了各自的地址翻译表,当处理器要执行ProgramB时,会使用ProgramB对应的地址翻译表,比如读取ProgramB地址0x100处的指令,那么经过地址翻译表可知0x100对应实际内存的0x700处,所以实际读取的就是0x700处的指令。同样的,当处理器要执行ProgramA时,会使用ProgramA对应的地址翻译表,这样就避免了之前提到的内存冲突问题,有了MMU的支持,操作系统就可以轻松实现多任务了。
上图CPU给出的地址称之为虚拟地址,经过MMU翻译后的地址称之为物理地址。
MMU的地址翻译功能还可以为用户提供比实际大得多的内存空间。用户在编写程序的时候并不知道运行该程序的计算机内存大小,如果在链接的时候指定程序被加载到地址Addr处,而运行该程序的计算机内存小于Addr,那么程序就无法执行,有了MMU后,程序员就不用关心实际内存大小,可以认为内存大小就是“2^指令地址宽度”。MMU会将超过实际内存的虚拟地址翻译为物理地址进行访问。
地址翻译表存储在内存中,如果采用上中的方式:地址翻译表的表项是一个虚拟地址对应一个物理地址,那么会占用太多的内存空间,为此,需要修改翻译方式,常用的有三种:页式、段式、段页式,这也是三种不同的内存管理方式。
- 段式内存管理:将虚拟内存、物理内存空间划分为段进行管理,段的大小取决于程序的逻辑结构,可长可短,一般将一个具有共同属性的程序代码和数据定义在一个段中。每个任务和进程对应一个段表(Section Table),段表由若干个段表项(STE:Section Table Entry)组成,内含地址映像信息(段基址和段长度)等内容。在段式虚拟存储器中,地址分为段号、段内位移两部分,使用段表进行地址翻译的过程与使用页表进行地址翻译的过程是相似的。
- 段页式内存管理:在内存分段的基础上再分页,即每段分成若干个固定大小的页。每个任务或进程对应有一个段表,每段对应有自己的页表。在访问存储器时,由CPU经页表对段内存储单元进行寻址
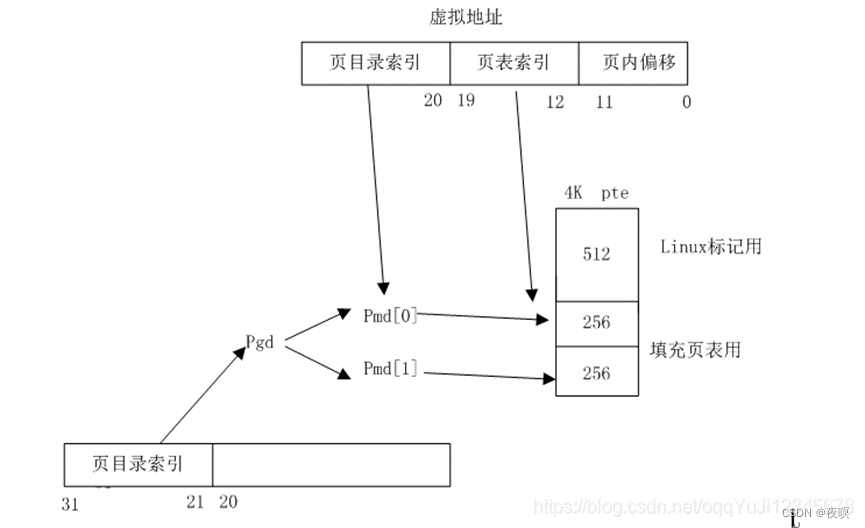
页式内存管理将虚拟内存、物理内存空间划分为大小固定的块,每一块称之为一页,以页为单位来分配、管理、保护内存。此时MMU中的地址翻译表称为页表(Page Table),每个任务或进程对应一个页表,页表由若干个页表项(PTE:Page Table Entry)组成,每个页表项对应一个虚页,内含有关地址翻译的信息和一些控制信息。在页式内存管理方式中地址由页号和页内位移两部分组成,其地址翻译方式如下图所示。
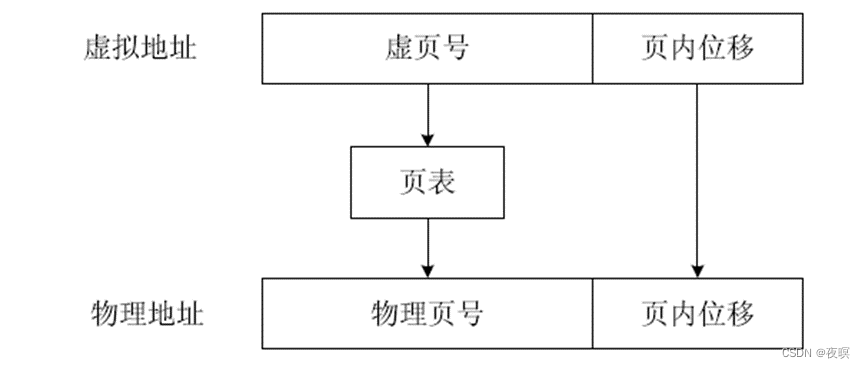
使用虚拟地址中的虚页号查询页表得到对应的物理页号,然后与虚拟地址中的页内位移组成物理地址。比如:页大小是256字节,虚拟地址是0x104,可知对应的虚页号是0x1,页内位移是0x4,假如通过页表翻译得到的对应物理页号是0x7,那么0x104对应的物理地址就是0x704。使用页表方式进行地址翻译可以有效减少地址翻译表占用的内存空间,还是以上面A,B程序为例,页大小是256(0x100)字节,此时每个程序对应的页表就只有两项,如下图所示
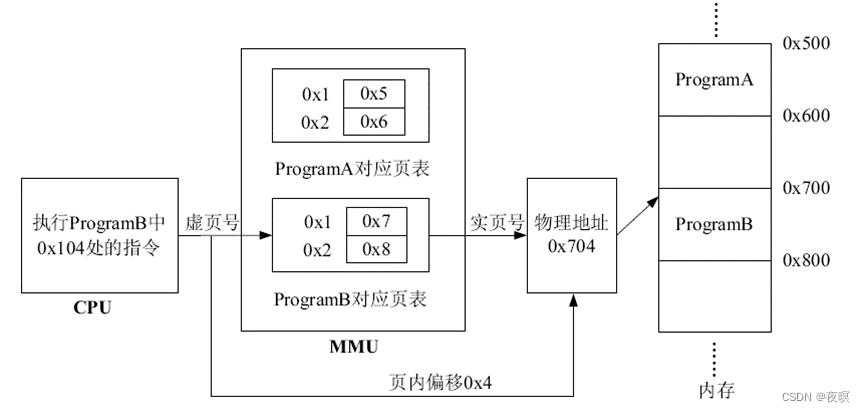
页表存放在物理内存中,打开mmu之后,如果需要修改页表,需要将页表所在的物理地址映射到虚拟地址才能访问页表(如内核初始化后会将物理内存线性映射,这样通过物理地址和虚拟地址的偏移就可以获得页表物理地址对应的虚拟地址)。
页表基地址和各级页表项中存放的都是物理地址,而不是虚拟地址
2.2.2 内存保护
内存保护也叫权限管理,除了具有地址翻译的功能外,还提供了内存保护功能。采用页式内存管理时可以提供页粒度级别的保护,允许对单一内存页设置某一类用户的读、写、执行权限,比如:一个页中存储代码,并且该代码不允许在用户模式下执行,那么可以设置该页的保护属性,这样当处理器在用户模式下要求执行该页的代码时,MMU会检测到并触发异常,从而实现对代码的保护。特别是在处理应用程序时,如果一个应用程序写的比较烂,出现了指针越界或栈溢出,程序跑飞等情况,因为不能访问别的程序的地址,所以不会影响到别的应用程序的运行。比如在操作系统下,应用程序不能访问寄存器,而操作系统可以。比如应用程序的只读数据段不能被写,否则会发生段错误。
2.2.3 大容量app在小资源系统运行
在嵌入式系统中,假如内存容量只有256M大,而应用程序却有1G大时,通常一个程序中,程序执行的比较多的是顺序指令,所以在运行1G的程序时,操作系统会先加载一小部分到内存中,当执行完这一部分或发生跳转发现内存中没有要跳转地址的指令时,操作系统再加载需要跳转部分的程序到其链接地址(虚拟地址),加载完后再继续执行。每次加载程序,都需要建立一个动态的地址映射表。当物理内存加载满后,操作系统会选择性的将最早之前加载入物理内存的程序置换到外部flash等存储器中,再加载需要用到的一块程序。因为置换需要时间,所以当使用存储容量较小内存的嵌入式系统后,让其运行大程序,使用可能会有一定的卡顿现象。
2.3 arm的MMU
2.3.1 基本介绍
下图中是arm支持的几种页表大小,以及每种页表可以管理的内存单元数量,在linux中使用的是4KB的模型

如果 SuperSection 或者 Section 的话,只需要一级页表即可,如果支持 4KB 或者 64KB 的页面,需要用到二级页表。以 4KB 的页映射为例:
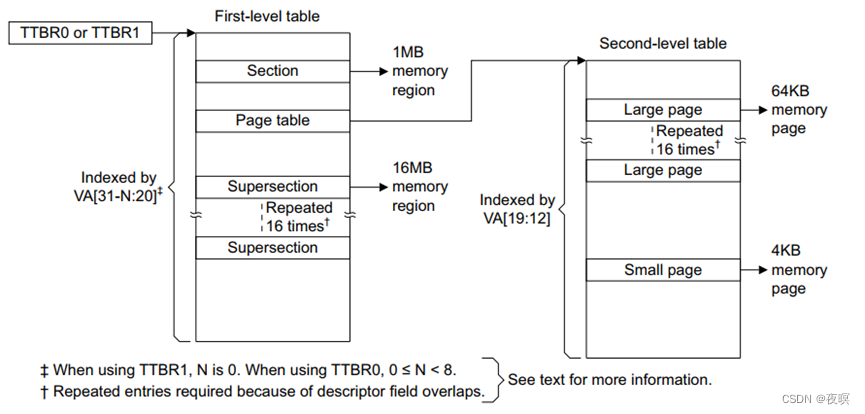
上面图截取自ARMV7手册,翻译一下就是如下图,实际上在linux中使用的就是page teble的方式,通过ttb寄存器和虚拟地址经过MMU转换最终成为实际物理地址
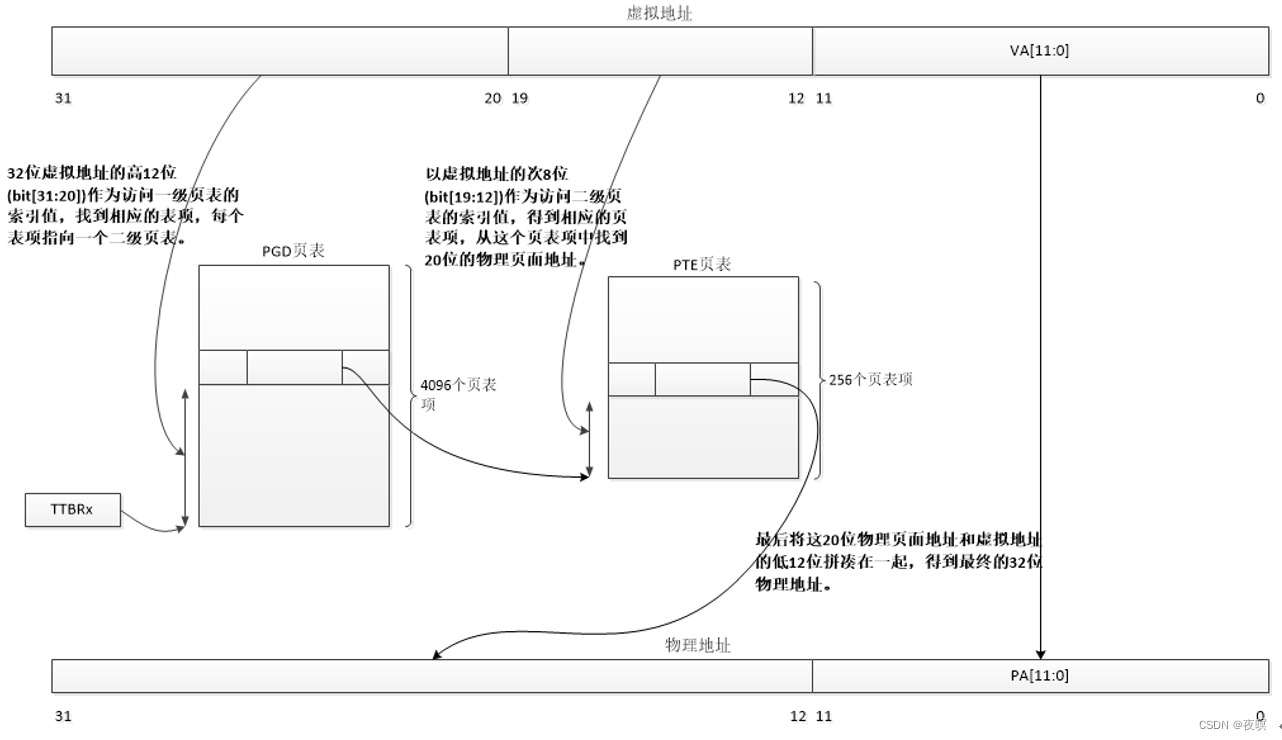
当 TLB Miss 的时候(也就是当前页表没有被缓存时),处理器进行 table walk(注:TLB,俗称快表,因为它确实快。TLB是MMU的一部分,实质是cache,它所缓存的是最近使用的数据的页表项(虚拟地址到物理地址的映射)。他的出现是为了加快访问数据(内存)的速度,减少重复的页表查找。当然它不是必须要有的,但有它,速度就更快):
- 根据 TTBCR 寄存器和虚拟地址来判断使用哪个页表基地址寄存器(TTBR0 或者 TTBR1)。其中放置了一级页表的基地址
- 处理器根据虚拟地址的 bit[31:20]作为索引,在一级页表中查找页表项,一级页表一共有 4096 个 页表项(4K 个 entry)
- 一级页表的表象中存放了二级页表的基地址,处理器根据虚拟地址的 bit[19:12]作为索引值,在二级页表中找到对应的表,二级页表一个 256 个表项
- 二级页表的页表项里面存放了 4KB 页的物理基地址,加上最后的 bit[11:0] 的offset,寻找到最终的物理内存。这4KB实际上就是对应的页偏移
接下来具体解析一下虚拟地址是如何通过MMU转化成实际地址的
2.3.2 MMU的相关寄存器
MMU相关寄存器操作皆由ARM处理器中CP15协处理器进行操作,访问CP15寄存器指令的编码格式及语法说明如下。

说明:
- <opcode_1>:协处理器行为操作码,对于CP15来说,<opcode_1>永远为0b000,否则结果未知。
- :不能是r15/pc,否则,结果未知。
- :作为目标寄存器的协处理器寄存器,编号为C0~C15。
- :附加的目标寄存器或源操作数寄存器,如果不需要设置附加信息,将crm设置为c0,否则结果未知。
- <opcode_2>:提供附加信息比如寄存器的版本号或者访问类型,用于区分同一个编号的不同物理寄存器,可以省略<opcode_2>或者将其设置为0,否则结果未知。
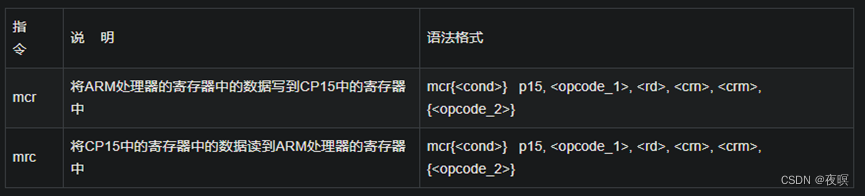
CP15的寄存器列表大致如下图,具体还是需要看手册给的,因为实际上非常复杂,这里只是给出大概作用,实际上由op0,crn,op2,crm组合成多种情况能访问不同寄存器并读取其值,这里不在额外进行讨论
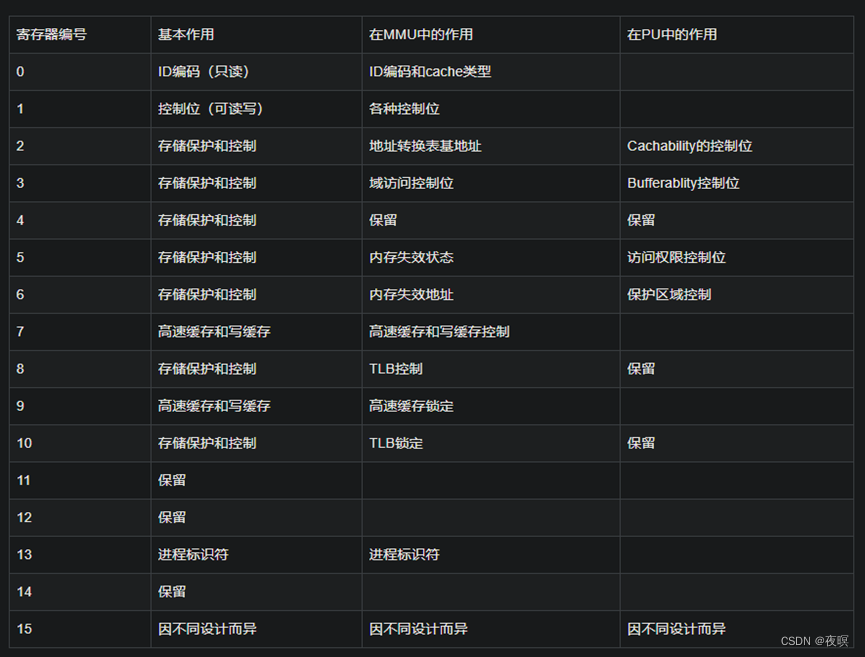
2.3.2.1 C0
主标识符寄存器,访问主标识符寄存器的指令格式如下所示:
- mrc p15, 0, r0, c0, c0,0 ;将主标识符寄存器C0,0的值读到r0中
cache类型标识符寄存器, 访问cache类型标识符寄存器的指令格式如下所示: - mrc p15, 0, r0, c0, c0,1 ;将cache类型标识符寄存器C0,1的值读到r0中
具体值为如何和如何规定这里不进行研究,详情查看该链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/78743305
具体的读取内容完全参考DDI0406C_d_armv7ar_arm.pdf第1476页中Table B3-42 Summary of VMSA CP15 register descriptions, in coprocessor register number order
2.3.2.2 C1
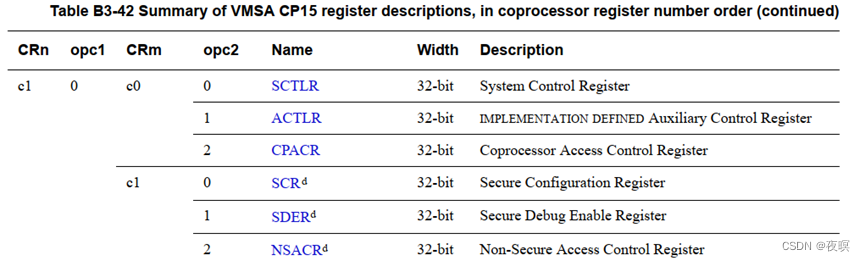
同样的,这里只列出部分可访问的,并只单独列出SCTLR,因为这个寄存器比较重要
访问主标识符寄存器的指令格式如下所示:
- mrc p15, 0, r0, c1, c0, 0 ;将CP15的寄存器C1的值读到r0中
- mcr p15, 0, r0, c1, c0, 0 ;将r0的值写到CP15的寄存器C1中
CP15中的寄存器C1的编码格式及含义说明如下:

例如:CP15的寄存器C1[0]设置为0时,禁止MMU,设置成1的时候enable MMU,如: - MRC P15, 0 ,R0 ,C1 ,C0 ,0 ;从协处理器CP15的C1传送到ARM处理器R0
- ORR R0, #01
- MCR P15 ,0 ,R0 ,C1 ,C0 ,0 ;给CP15的寄存器C1[0]写1
2.3.2.3 C2
C2是专门用于存储TTB的值的寄存器,前面讲过,当TLB miss时就会从TTBR0或者TTBR1中取值作为一级表项
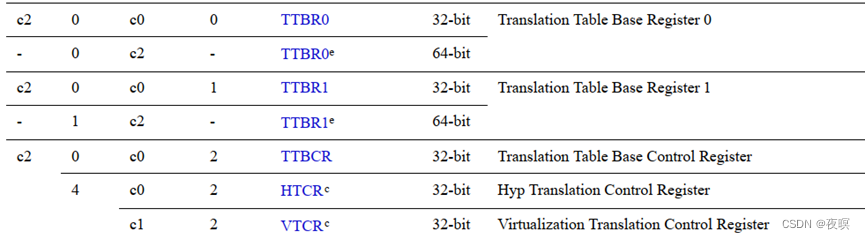
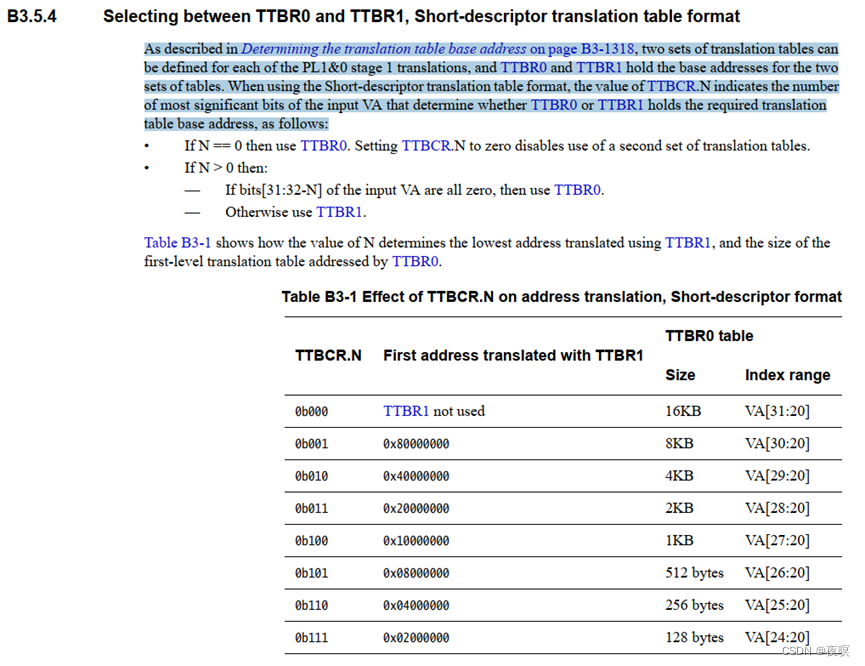
如下图所示,使用TTBR0还是TTBR1是根据TTBCR寄存器设置的值进行判断的,当TTBCR值设为0,则只使用TTBR0,否则在对应地址之内使用TTBR0,比如TTBCR,N=1,当输入VM<0x8000_0000时,使用TTBR0,高于时使用TTBR1。
操作系统为用户空间的每个进程分配各自的页表,即每个进程的一级页表基址是不一样的,故当发生进程上下文切换时,TTBR0需要被存放当前进程的一级页表基址;TTBR1中存放的是内核空间的一级页表基址,内核空间的一级页表基址是固定的,故TTBR1中的基址值不需要改变
N的大小由TTBCR寄存器决定。0x0 -> 1<<(32-N)为用户空间,由TTBR0控制,1<<(32-N) -> 4GB为内核空间,由TTBR1控制。
N的大小与一级页表大小的关系图如下:
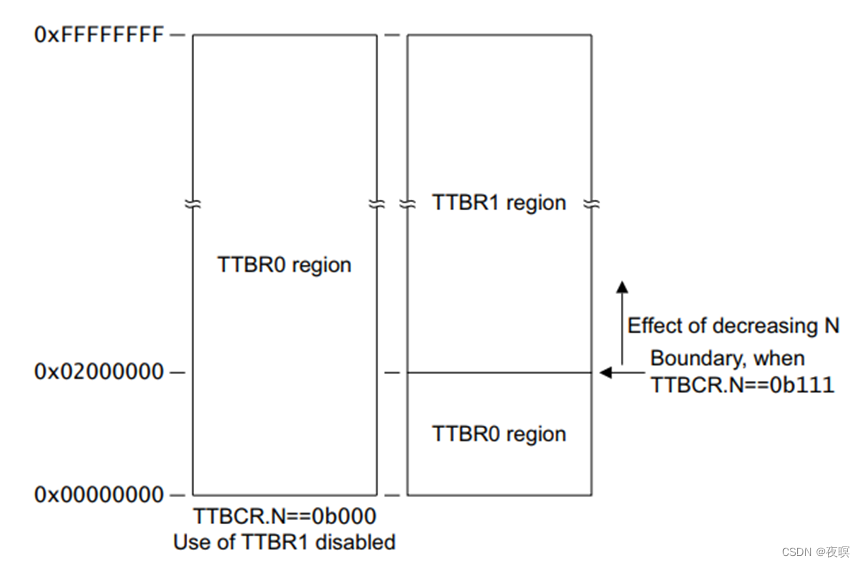
如下图所示,可以发现在启动MMU的过程中,将页表指针加载到了C2中
2.3.2.4 C3
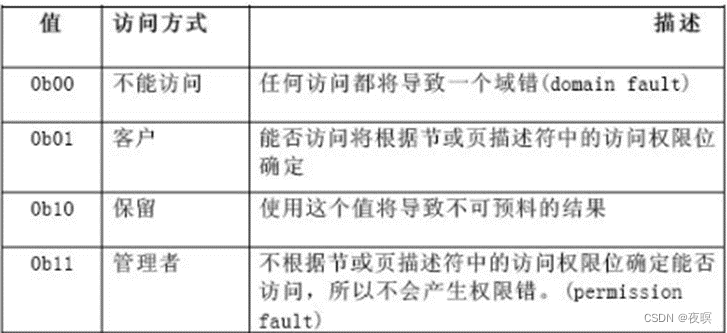
CP15中的寄存器C3定义了ARM处理器的16个域的访问权限


每个域分成两个bit,其权限定义如下,比如域15值为0b11的话,无论内存被如何读写都不会报错。
2.3.3 VA到PA的流程
2.3.3.1 表项格式
段式映射格式如下,在arm32位linux中,低端内存区使用的是段式映射

在分析具体流程之前,先看下手册是如何描述其表项格式的,对于linux中使用的为Short-descriptor translation table format descriptors
在上面的基本介绍里提到过,arm32位linux使用的是4KB的映射方式。4KB 映射的一级页表表项和二级页表的表项其实也是 32bits 的,只不过其他的一些 bit 被硬件用作其他作用:
- 一级表项:

- 二级表项:
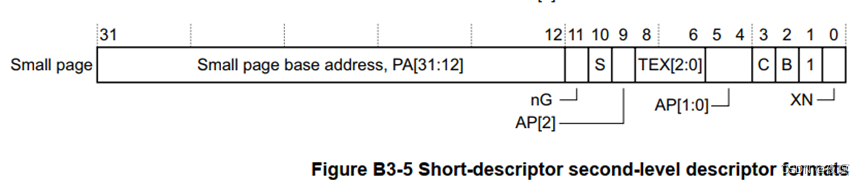
- Domain:就是前面C3寄存器指定的域,这里[8:5]四个bit正好16个域
- AP[2],AP[1:0]:权限访问位
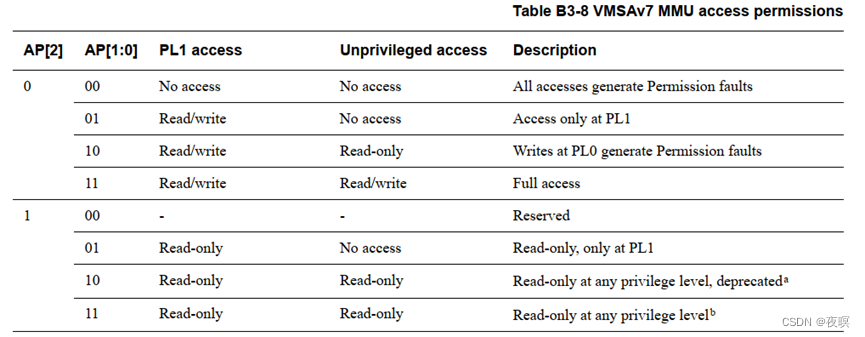
注:PL的全称是Power Limit,意思是功率极限,后边的数字代表级别,其实这个数字从小到大一共是四个级别,分别是PL1、PL2、PL3、PL4,数字越小功率限制级别就越低 - TEX[2:0], C, B:内存区域属性位,这些位不在页表条目中

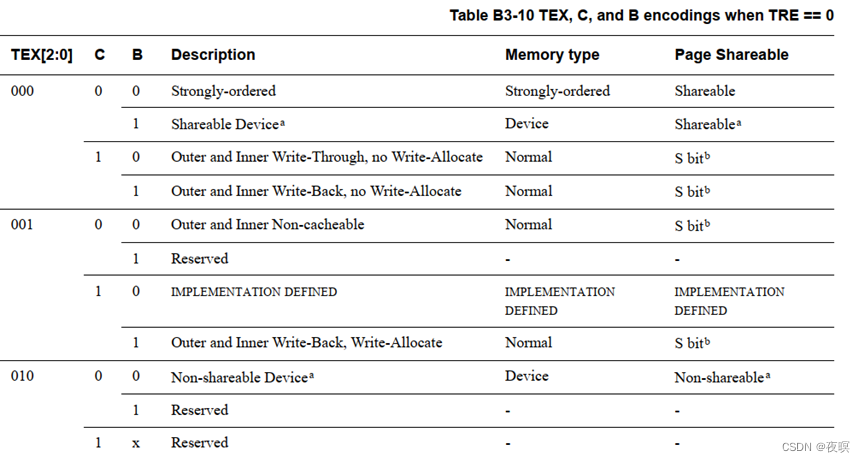

6. XN,该位被置1,不允许执行该页表处程序,该位不在页表条目中

2.3.3.2 具体流程
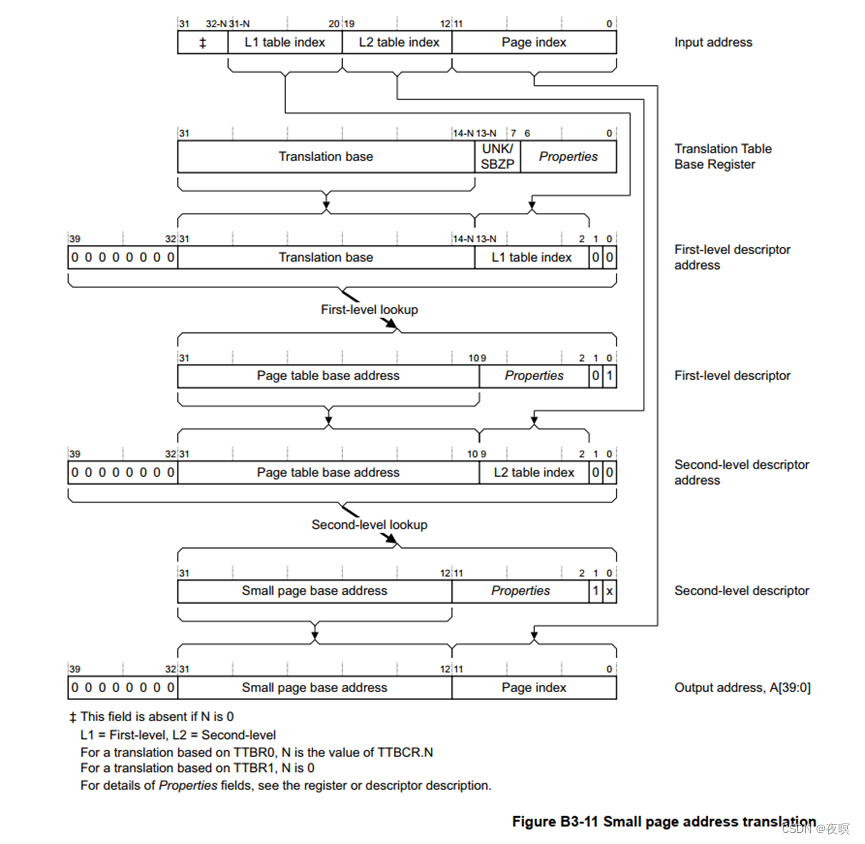
具体流程如下,虚拟地址VA[31:20]作为L1索引,VA[19:12]作为L2索引,剩余部分为实际页内偏移。
L1索引负责从TTBRx中索引表项,找到对应一级页表中对应的二级页表的实际地址,根据一级页表中实际地址在加上L2索引,找到2级页表项中对应的PA[31:12]
最终,PA[31:12]+VA[11:0]=PA[31:0]
.地址转换的总体流程:
(1)从虚拟地址取出前面的31-20位,作为索引。
(2)根据索引在translation table(一级页表)中找到相应的表项。
(3)根据表项最低两位的值决定第二阶段的转换方式。
00:转换无效
01:粗页转换
10:段转换
11:细页转换
(4)linux系统一般用细页转换,也有一定的处理器和操作系统用段转换,很少用粗页转换。
.关于TTB(translation table base)
(1)translation table存放在内存中。
(2)由程序员制造,故程序员知道其基地址(TTB)。
(3)程序员将TTB写入cp15的c2寄存器(TTB寄存器)。
(4)MMU工作的时候从c2寄存器去到TTB,从而找到translation table,进而利用虚拟地址的31-20位可以在该表中找到相应的表项,开始虚拟地址到物理地址的转换。
#define GPKCON (volatile unsigned long*)0xA0008820
#define GPKDAT (volatile unsigned long*)0xA0008824
/*
* 用于段描述符的一些宏定义
*/
#define MMU_FULL_ACCESS (3 << 10) /* 段的访问权限 AP*/
#define MMU_DOMAIN (0 << 5) /* 属于哪个域 */
#define MMU_SPECIAL (1 << 4) /* 必须是1 */
#define MMU_CACHEABLE (1 << 3) /* cacheable 快速访问*/
#define MMU_BUFFERABLE (1 << 2) /* bufferable 缓冲区 */
#define MMU_SECTION (2) /* 表示这是段描述符 */
#define MMU_SECDESC (MMU_FULL_ACCESS | MMU_DOMAIN | MMU_SPECIAL | MMU_SECTION)
#define MMU_SECDESC_WB (MMU_FULL_ACCESS | MMU_DOMAIN | MMU_SPECIAL | MMU_CACHEABLE | MMU_BUFFERABLE | MMU_SECTION)
/*
1. 建立页表
2. 写入TTB (cp15 c2)
3. 使能MMU
*/
void create_page_table(void)
{
unsigned long *ttb = (unsigned long *)0x40000000;
unsigned long vaddr, paddr;
vaddr = 0xA0000000;
paddr = 0x7f000000;
*(ttb + (vaddr >> 20)) = (paddr & 0xFFF00000) | MMU_SECDESC;
vaddr = 0x50000000; /* 映射内存 */
paddr = 0x50000000;
while (vaddr < 0x54000000)
{
*(ttb + (vaddr >> 20)) = (paddr & 0xFFF00000) | MMU_SECDESC_WB;
vaddr += 0x100000; /* 每一个表项只能映射1M */
paddr += 0x100000;
}
}
void mmu_init()
{
__asm__(
/*设置TTB 写入cp15的c2中*/
"ldr r0, =0x50000000\n"
"mcr p15, 0, r0, c2, c0, 0\n"
/*不进行权限检查 域的访问权限取决于cp15的c3寄存器*/
"mvn r0, #0\n"
"mcr p15, 0, r0, c3, c0, 0\n"
/*使能MMU*/
"mrc p15, 0, r0, c1, c0, 0\n"
"orr r0, r0, #0x0001\n"
"mcr p15, 0, r0, c1, c0, 0\n"
:
:
);
}
int gboot_main()
{
create_page_table();
mmu_init();
*(GPKCON) = 0x1111;
*(GPKDAT) = 0xe;
return 0;
}
二、页,页表和页框
1.三者关系
页:进程中的块(进程被分成许多大小相同的块)
页框:内存中的块(内存被分成许多大小相同的块)
页表:进程中的每一页所对应的页框的位置(进程中的每一块对应在内存中的位置)
页表项:
逻辑地址(页号,偏移量) (逻辑地址就是虚拟地址)
物理地址(页框号,偏移量)
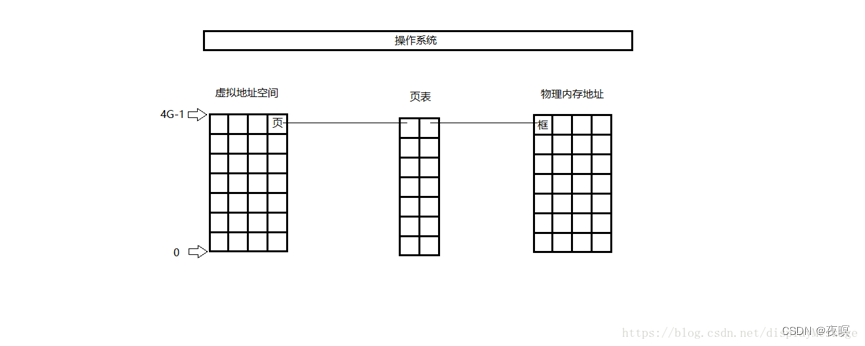


逻辑地址32位、页面大小4KB、页表项大小4B,按字节编址,根据页的定义和页面大小的定义将进程进行分页

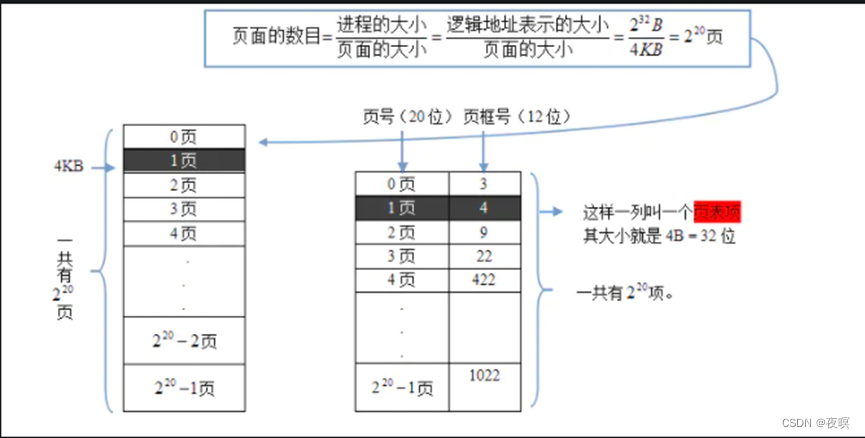
页面的数目为:2^20页, 所以页表就需要4B*2^20 = 4MB的空间存储(注:这种是纯页式,实际上使用的段页)
2.Linux内存模型
Linux提供了三种内存模型(include/asm-generic/memory_model.h):
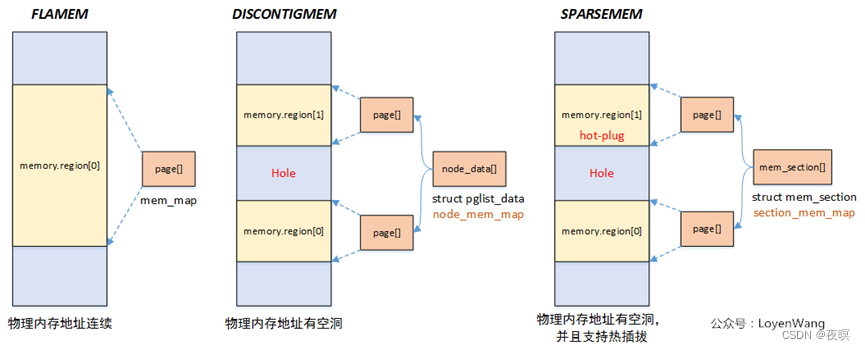
一般处理器架构支持一种或者多种内存模型,这个在编译阶段就已经确定,比如H8中使用的是最简单的Flat Memory。
Flat Memory:物理内存地址连续,这个也是Linux最初使用的内存模型。当内存有空洞的时候也是可以使用这个模型,只是struct page *mem_map数组的大小跟物理地址正相关,内存有空洞会造成浪费。
Discontiguous Memory:物理内存存在空洞,随着Sparse Memory的提出,这种内存模型也逐渐被弃用了。
Sparse Memory:物理内存存在空洞,并且支持内存热插拔,以section为单位进行管理。
Linux三种内存模型下,struct page到物理page frame的映射方式也不一样,具体可以查看include/asm-generic/memory_model.h文件中的__pfn_to_page/__page_to_pfn定义
关于Nodes、Zones、Pages三者之间的关系,《ULVMM》 Figure 2.1介绍,虽然zone_mem_map一层已经被替代,但是仍然反映了他们之间的层级树形关系。pg_data_t对应一个Node,node_zones包含了不同Zone;Zone下又定义了per_cpu_pageset,将page和cpu绑定
Linux把物理内存划分为三个层次来管理

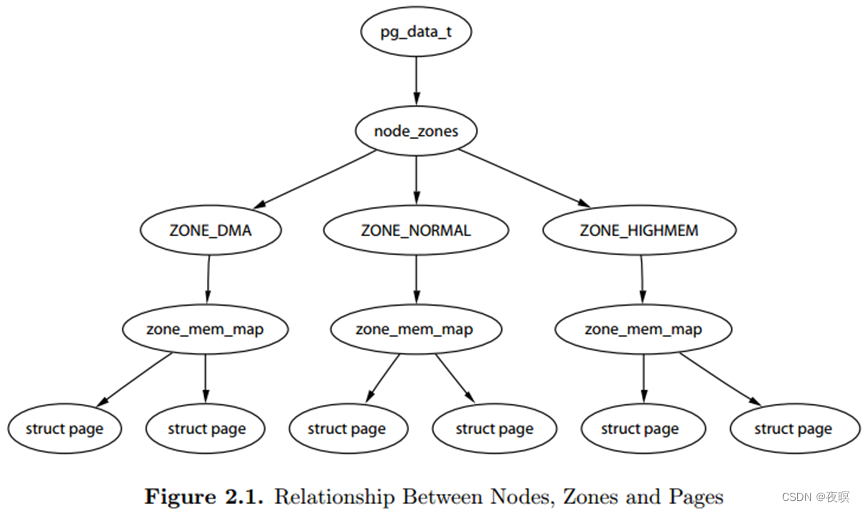
内存被划分为结点. 内存中的每个节点都是由pg_data_t描述,而pg_data_t由struct pglist_data定义而来, 该数据结构定义在include/linux/mmzone.h, 每个结点关联到系统中的一个处理器, 内核中表示为pg_data_t的实例. 系统中每个节点被链接到一个以NULL结尾的pgdat_list链表中,而其中的每个节点利用pg_data_tnode_next字段链接到下一节,而对于PC这种UMA结构的机器来说, 只使用了一个成为contig_page_data的静态pg_data_t结构.
各个节点又被划分为内存管理区域, 一个管理区域通过struct zone_struct描述, 其被定义为zone_t, 用以表示内存的某个范围, 低端范围的16MB被描述为ZONE_DMA, 某些工业标准体系结构中的(ISA)设备需要用到它, 然后是可直接映射到内核的普通内存域ZONE_NORMAL,最后是超出了内核段的物理地址域ZONE_HIGHMEM, 被称为高端内存.是系统中预留的可用内存空间, 不能被内核直接映射
页帧(page frame)代表了系统内存的最小单位, 堆内存中的每个页都会创建一个struct page的一个实例. 传统上,把内存视为连续的字节,即内存为字节数组,内存单元的编号(地址)可作为字节数组的索引. 分页管理时,将若干字节视为一页,比如4K byte. 此时,内存变成了连续的页,即内存为页数组,每一页物理内存叫页帧,以页为单位对内存进行编号,该编号可作为页数组的索引,又称为页帧号
3.physical frame number(PFN)
前面我们讲述过了虚拟地址到物理地址的映射过程,而系统中对内存的管理是以页为单位的:
page:线性地址被分成以固定长度为单位的组,称为页,比如典型的4K大小,页内部连续的线性地址被映射到连续的物理地址中;
page frame:内存被分成固定长度的存储区域,称为页框,也叫物理页。每一个页框会包含一个页,页框的长度和一个页的长度是一致的,在内核中使用struct page来关联物理页。
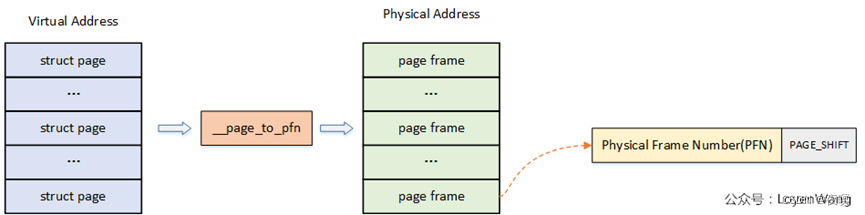
至于__page_to_pfn这个实现取决于具体的物理内存模型,下文将进行介绍
4.(N)UMA
均匀存储器存取(Uniform-Memory-Access,简称UMA)模型UMA,所有处理器对内存的访问都是一致的
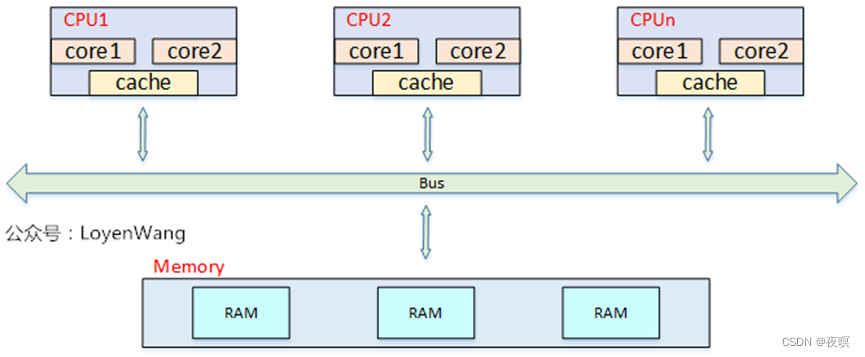
从上图中可以看出,当处理器和Core变多的时候,内存带宽将成为瓶颈问题
非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型:
处理器被划分成多个”节点”(node), 每个节点被分配有的本地存储器空间. 所有节点中的处理器都可以访问全部的系统物理存储器,但是访问本节点内的存储器所需要的时间,比访问某些远程节点内的存储器所花的时间要少得多
内存被分割成多个区域(BANK,也叫”簇”),依据簇与处理器的”距离”不同, 访问不同簇的代码也会不同
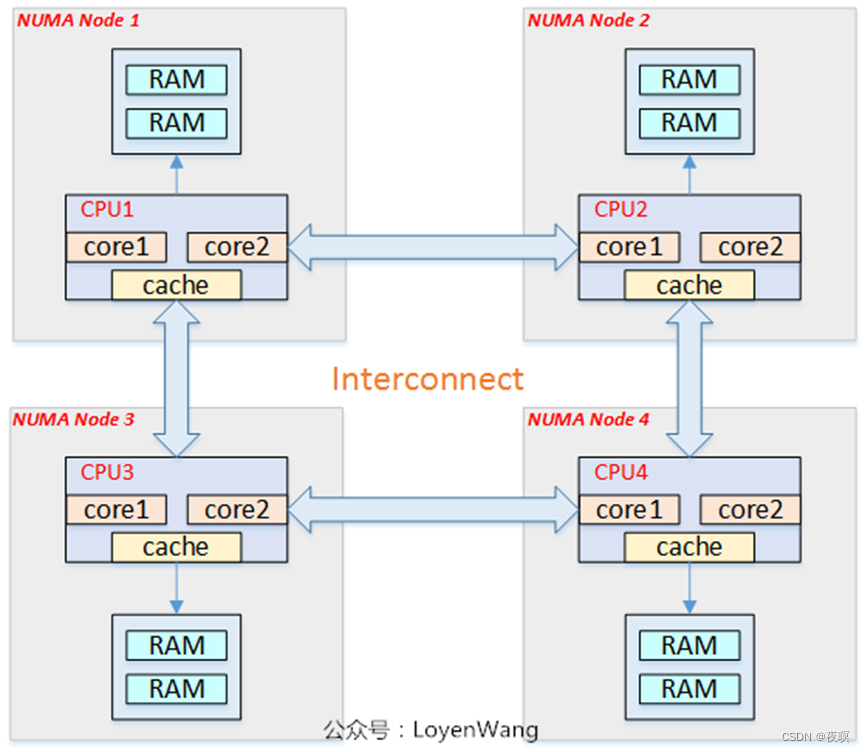
5.关键结构
5.1 page
内核把物理页作为内存管理的基本单位. 尽管处理器的最小可寻址单位通常是字, 但是, 内存管理单元MMU通常以页为单位进行处理. 因此,从虚拟内存的上来看,页就是最小单位。页帧代表了系统内存的最小单位, 对内存中的每个页都会创建struct page的一个实例. 内核必须要保证page结构体足够的小,否则仅struct page就要占用大量的内存.
因为即使在中等程序的内存配置下, 系统的内存同样会分解为大量的页. 例如, IA-32系统中标准页长度为4KB, 在内存大小为384MB时, 大约有100000页. 就当今的标准而言, 这个容量算不上很大, 但页的数目已经非常可观了。因而出于节省内存的考虑,内核要尽力保持struct page尽可能的小. 在典型的系统中, 由于页的数目巨大, 因此对page结构的小改动, 也可能导致保存所有page实例所需的物理内存暴涨.
struct page {
/* First double word block */
unsigned long flags; /* 描述page的状态和其他信息*/
union {
struct address_space *mapping; /* 如果低位清除,则指向inode address_space,或NULL。若页面映射为匿名内存,则设置低位,并指向一个anon_vma对象:请参阅下面的页面映射。*/
void *s_mem; /* slab first object */
atomic_t compound_mapcount; /* first tail page */
/* page_deferred_list().next -- second tail page */
};
/* Second double word */
union {
pgoff_t index; /* 在映射的虚拟空间(vma_area)内的偏移,一个文件可能只映射一部分,假设映射了1M的空间,index指的是在1M空间内的偏移,而不是在整个文件内的偏移. */
void *freelist; /* sl[aou]b first free object */
/* page_deferred_list().prev -- second tail page */
};
union {
unsigned counters;
struct {
union {
mms中映射的PTE计数,以显示页面何时映射并限制反向映射搜索。对于从未映射的页面,此处可能会存储有关页面类型的额外信息,在这种情况下,值必须<=-2。请参阅page-flags.h了解更多细节。
atomic_t _mapcount; /* 页映射计数器 */
unsigned int active; /* SLAB */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
int units; /* SLOB */
};
atomic_t _refcount; /* 页引用计数器 */
};
};
/*
* Third double word block
*/
union {
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone_lru_lock !
* Can be used as a generic list
* by the page owner.
*/
struct dev_pagemap *pgmap; /* ZONE_DEVICE pages are never on an
* lru or handled by a slab
* allocator, this points to the
* hosting device page map.
*/
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
short int pages;
short int pobjects;
};
struct rcu_head rcu_head;
/* Tail pages of compound page */
struct {
unsigned long compound_head; /* If bit zero is set */
/* First tail page only */
unsigned short int compound_dtor;
unsigned short int compound_order;
};
};
/* Remainder is not double word aligned */
union {
unsigned long private;
struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
};
}

三、页表创建
1.内核启动前
我们直接来分析一下内核启动阶段的页表创建过程,先看一下.map,如下图,显然的,在内核启动初期时没有开启MMU的,在这之前必须先把页表映射做好(这里创建的页表是个临时页表,在后面会被真正的页表替换),开启MMU后,内核才能在运行虚拟地址的时候不会崩溃,这里有一个关键变量:swapper_pg_dir
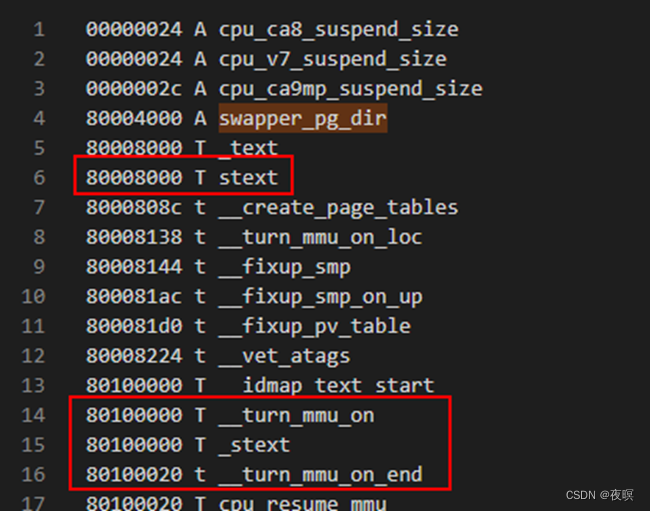
所以swapper_pg_dir的值为0x8000_4000,也就是页表存放的地址。至于为什么预留0x4000?在一级页表项中,需要4096项,每项都是32bit即4字节,所以一共就是0x4000。即每个1级页表项对应了实际物理大小的1M的内存,随后2级页表有256项,这256项对应1M,所以2级页表项每一项对应实际物理内存的4K。
注:在该阶段使用的是段式页表
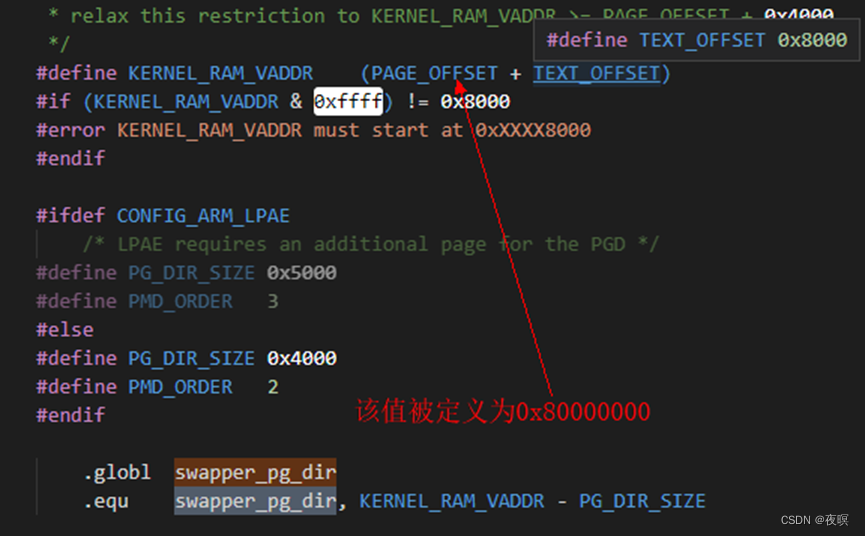
1.1 __create_page_tables
下面我们来逐步分析开启MMU之前的页表映射。由于板子内的内存和Kernel地址处于同一地址都是0x8000_0000所以,这里人为的定义:
- PAGE_OFFSET =0x8000_0000 ;kernel偏移地址
- PHYS = 0x3000_0000 ;实际物理内存地址(为了进行区分,这里把地址改一下)
- PG_DIR_SIZE = 0x4000
- PMD_ORDER = 2
.globl swapper_pg_dir
.equ swapper_pg_dir, KERNEL_RAM_VADDR - PG_DIR_SIZE
//按照上述定义,swapper_pg_dir = 0X8000_4000
/* 这里定义了一个宏 pgtbl 实际上就是传入实际物理地址,
然后计算偏移给到一个指定寄存器,算法为 rd = phys+ TEXT_OFFSET - PG_DIR_SIZE
即 rd = 0x3000_0000 +0x8000 -0x4000 = 0x3000_4000 */
.macro pgtbl, rd, phys
add \rd, \phys, #TEXT_OFFSET
sub \rd, \rd, #PG_DIR_SIZE
.endm
/*
* r8 = phys_offset, r9 = cpuid, r10 = procinfo
*/
__create_page_tables:
pgtbl r4, r8 ;
这里根据上面的宏和上面注释,
已知在前面调用该函数的过程中已经获取到了物理地址到r8中,
这里计算出 r4就是页表在实际物理地址的保存位置,即r4=0x3000_4000
/*
* 实际上这里就是将页表的16K大小全部清0
*/
mov r0, r4 ;r0=0x3000_4000
mov r3, #0 ;r3=0
add r6, r0, #PG_DIR_SIZE ;r6=0x3000_8000
1: str r3, [r0], #4 ;将r3中的值存到r0所指定的地址中, 同时r0地址+4
str r3, [r0], #4 ;即 将0存入 0x3000_4000/0x3000_4004/0x3000_4008…
str r3, [r0], #4 ;即 将16K页表清0
str r3, [r0], #4
teq r0, r6
bne 1b ;r0不等于r6就继续这个循环
ldr r7, [r10, #PROCINFO_MM_MMUFLAGS] @ mm_mmuflags ;
根据上面注释可知r10中存着CPU相关信息(CPU的processor_type_list(处理器信息结构体)),
这里是获取mmuflag的信息到r7 r7 = *(r10 + 8) 取proc_info_list结构体offset 8
是__cpu_mm_mmu_flags
/*
* Create identity mapping to cater for __enable_mmu.
* This identity mapping will be removed by paging_init().
*/
首先建立包含turn_mmu_on函数1M空间的平映射(virt addr = phy addr)
adr r0, __turn_mmu_on_loc ;
得到的是__turn_mmu_on_loc的当前执行位置,由 pc+offset 决定得到有效地址,
根据实际map 见图1,2 可知 __turn_mmu_on_loc,
所以此时r0地址应该为0X3000_8138(因为内核会被boot搬运到物理内存偏移0x8000之后的位置,
那么根据map表得出偏移,就是这个值)
ldmia r0, {r3, r5, r6} ;
将R0存储地址里面的内容手动加载到寄存器r3,r5,r6里,由下图(图1图2)可知,
实际加载的就是__turn_mmu_on_loc,__turn_mmu_on和__turn_mmu_on_end在map中的值,
就是0X8000_8138,0x8010_0000,0x8010_0020
sub r0, r0, r3 @ virt->phys offset ;
这里计算虚拟地址和实际物理地址之间的偏移量
add r5, r5, r0 @ phys __turn_mmu_on ;
那么实际物理地址的__turn_mmu_on就是0x8010_0000 + 偏移 = 0x3010_0000
add r6, r6, r0 @ phys __turn_mmu_on_end;同理
mov r5, r5, lsr #SECTION_SHIFT ;
因1页映射1M空间,所以SECTION_SHIFT为20 这里是将r5右移20为0x301
mov r6, r6, lsr #SECTION_SHIFT ;
r6实际值等于r5=0x301右移20位后,r5,r6代表该段地址空间的物理地址页号,
因为是平映射,也代表了页表中的下标,即虚拟地址页号
//r5左移20位,获取该页基地址,或上CPU的mmuflags,存在r3中
1: orr r3, r7, r5, lsl #SECTION_SHIFT @ flags + kernel base;
这里r3的值就是 0x3010_0000+flag,也就是页表内容
//将r3值存储在页表空间(r4起始)的(r5<<4)的页表中
//因一页用4bytes表示,所以PMD_ORDER=2,上面也有定义
str r3, [r4, r5, lsl #PMD_ORDER] @ identity mapping;
这里是把r3值存放到r4实际物理内存的对应的301号页表项的实际位置,
也就是地址 0x3000_4000 + 0x301 * 4 = 0x3000_4C04
cmp r5, r6 ;这里直接就是r5=r6了因为这一段程序比较小,映射1M的空间已经够用了
addlo r5, r5, #1 @ next section
blo 1b
/*
* Map our RAM from the start to the end of the kernel .bss section
*/
//接下来以多个1M的线性映射页表,建立kernel整个镜像的线性映射
add r0, r4, #PAGE_OFFSET >> (SECTION_SHIFT - PMD_ORDER);
0x8000_0000右移18位为0x2000,故r0=0x3000_6000
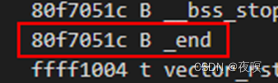
ldr r6, =(_end - 1) ;故r6=0x80f7_051b这里获取的是绝对地址(见图3)
这里内核大小将近16M,所以实际上也就是映射了16M大小的页表从实际物理地址
orr r3, r8, r7 ;r8和r7或完放入r3,即r3存入了0x3000_0000+flag
add r6, r4, r6, lsr #(SECTION_SHIFT - PMD_ORDER) ;
r6右移18位得0x203d,故r6=0x3000_603d
1: str r3, [r0], #1 << PMD_ORDER ;将r3的值放入,r0地址+4
add r3, r3, #1 << SECTION_SHIFT ;r3每次+0x0010_0000(1M)
cmp r0, r6 ;直到r0=r6,即将kernel在对应的页表地址处进行了映射
bls 1b
/*
* Then map boot params address in r2 if specified.
* We map 2 sections in case the ATAGs/DTB crosses a section boundary.
*/
/* 这里单独再对boot传来的atag做线性映射,
其中r2为boot传入的atag的实际物理地址 假设这里r2的值为0x3000_0100 */
mov r0, r2, lsr #SECTION_SHIFT ;对r2右移20位,在放入r0=0x300
movs r0, r0, lsl #SECTION_SHIFT ;r0左移20位,r0=0x3000_0000
subne r3, r0, r8 ;这里算出与实际物理地址的偏移
addne r3, r3, #PAGE_OFFSET ;加上虚拟地址偏移,r3目前的值就是atag在虚拟地址的位置
addne r3, r4, r3, lsr #(SECTION_SHIFT - PMD_ORDER) ;
算出1M大小的虚拟地址结束位置,也就是页表的下标
orrne r6, r7, r0 ;计算实际物理地址与flag或值放入r6,r6就是要存入页表的值
strne r6, [r3], #1 << PMD_ORDER ;同上面操作,r3地址处放实际地址
addne r6, r6, #1 << SECTION_SHIFT ;偏移1M大小
strne r6, [r3] ;在存一次,完成atag附近的1M映射
图1
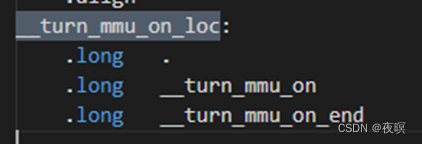
图2
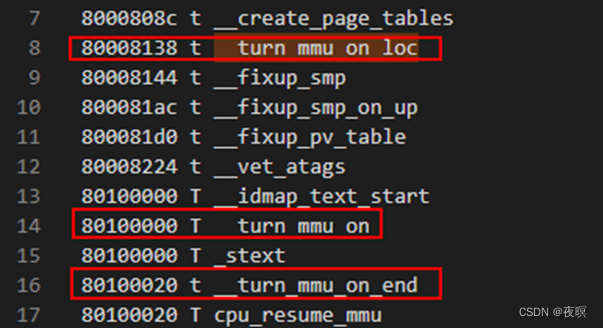
图3
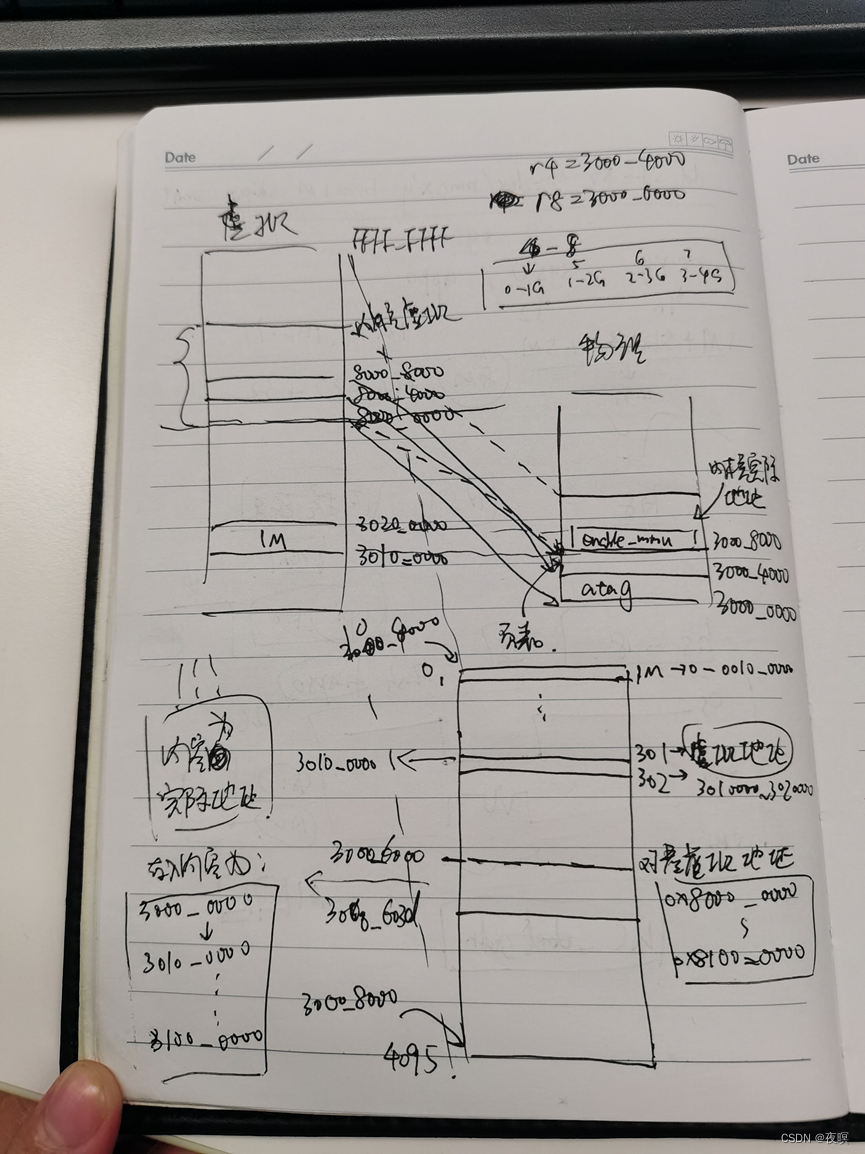
如下图所示为colg上实际物理地址为0x8000_0000,内核运行地址为0xC000_0000,0x00011c0e为读出的flag值。依据上诉推测0x4000开始对应虚拟的0-1G,0x5000开始对应虚拟1-2G,0x6000对应虚拟的2-3G,0x7000对应虚拟3-4G。正好下图证明了推测
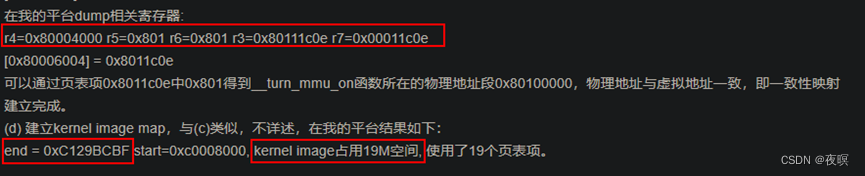
至此__create_page_tables完成。
总结:create_page_table完成了3种地址映射的页表空间填写:
- turn_mmu_on所在1M空间的平映射
- kernel image的线性映射
- atags所在1M空间的线性映射
(1)为什么turn_mmu_on要做平映射?
主要是完成开启MMU的操作。那为什么将turn_mmu_on处做一个平映射?
可以想象,执行开启MMU指令之前,CPU取指是在0x80008000附近turn_mmu_on中。
如果只是做kernel image的线性映射,执行开启MMU指令后,CPU所看到的地址就全变啦。
turn_mmu_on对于CPU来说在0xc0008000附近,0x80008000附近对于CPU来说已经不可预知了。
但是CPU不知道这些,它只管按照地址一条条取指令,执行指令。所以不做turn_mmu_on的平映射(virt addr = phy addr),turn_mmu_on在开启MMU后的运行是完全不可知。完成turn_mmu_on的平映射,我们可以在turn_mmu_on末尾MMU已经开启稳定后,修改PC到0xc0008000附近,就可以解决从0x8xxxxxxx到0xcxxxxxxx的跳转。
(2)kernel image加载地址为什么会在0x8000?
分析了kernel image线性映射部分,这个就好理解了,kernel编译链接时的入口地址在0xc0008000(PAGE_OFFSET + TEXT_OFFSET),但其物理地址不等于其链接的虚拟地址,image的线性映射实现其运行地址等于链接地址。kernel的每一页表映射1M,所以入口处在(0x80000000–>0xc0000000)映射页表中完成映射。物理地址和虚拟地址的1M内偏移必须一致呀。kernel定义的TEXT_OFFSET = 0x8000.所以加载的物理地址必须为0x8000。这样,开启MMU后,访问0xc0008000附近指令,MMU根据TLB才能正确映射找到0x****8000附近的指令。
(3)atags跟kernel入口是在同一1M空间内,bootparams的线性映射操作是否多余?
根据第二个问题的分析,kernel image可以加载到任何sdram地址空间的0x****8000即可。atags地址是有bootloader中指定,然后告诉kernel。那就有这样一种情况,加入sdram起始地址为0x80000000,atags起始地址为0x80000100。但kernel image我加载到0x81008000,可以看出,这时atags跟kernel image就在不同一1M空间啦。所以atags单独的线性映射操作还是很有必要的。
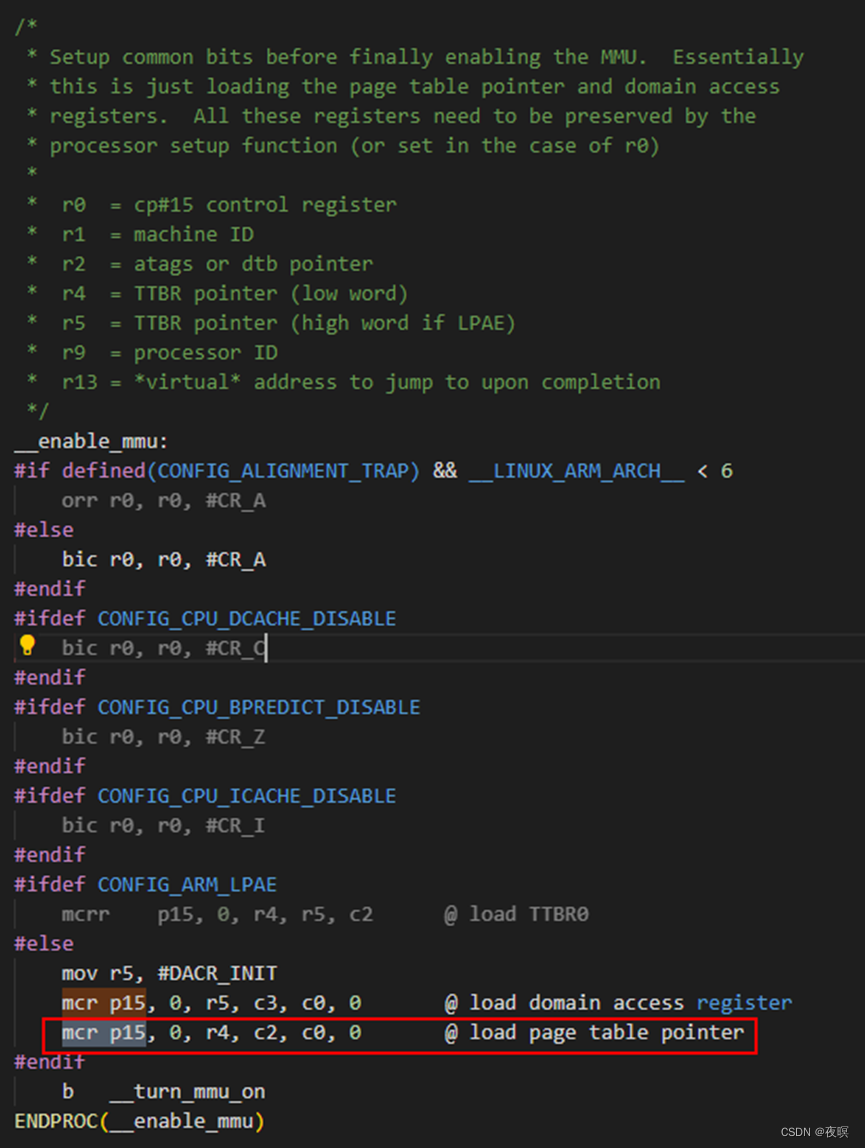
1.2. __enable_mmu
创建完内核启动阶段的页表后就是开启mmu的过程了,具体不在分析,就是根据手册来进行控制,详情看手册的具体寄存器操作

bic r0, r0, #CR_A
mov r5, #DACR_INIT
mcr p15, 0, r5, c3, c0, 0 @ load domain access register
mcr p15, 0, r4, c2, c0, 0 @ load page table pointer 在创建页表时,r4的值已经获得到,依旧按上述假设,则r4=0x3000_4000,就是实际上页表在物理内存中所在的位置
b __turn_mmu_on
.macro instr_sync
#if __LINUX_ARM_ARCH__ >= 7
isb
#elif __LINUX_ARM_ARCH__ == 6
mcr p15, 0, r0, c7, c5, 4
#endif
.endm
/*
* Enable the MMU. This completely changes the structure of the visible
* memory space. You will not be able to trace execution through this.
* If you have an enquiry about this, *please* check the linux-arm-kernel
* mailing list archives BEFORE sending another post to the list.
*
* r0 = cp#15 control register
* r1 = machine ID
* r2 = atags or dtb pointer
* r9 = processor ID
* r13 = *virtual* address to jump to upon completion
*
* other registers depend on the function called upon completion
*/
ENTRY(__turn_mmu_on)
mov r0, r0
instr_sync ; 指令同步屏障操作,可以理解为MMU的操作锁
mcr p15, 0, r0, c1, c0, 0 @ write control reg
mrc p15, 0, r3, c0, c0, 0 @ read id reg
instr_sync
mov r3, r3
mov r3, r13
ret r3
__turn_mmu_on_end:
ENDPROC(__turn_mmu_on)
2.内核启动后
paging_init主要完成初始化内核的分页机制,通过对启动阶段页表的覆盖,并填充新的一级页表,这样我们的虚拟内存空间就初步建立,并可以完成物理地址到虚拟地址的映射工作
/*
* paging_init() sets up the page tables, initialises the zone memory
* maps, and sets up the zero page, bad page and bad page tables.
*/
void __init paging_init(const struct machine_desc *mdesc)
{
void *zero_page;
build_mem_type_table(); //该函数主要根据arm的架构,来设置mem_types表,该表对不同的内存类型,进行不同的映射,并附加不同的标志位
prepare_page_table(); //清零一些页目录
map_lowmem(); //对ram的地址再进行一次段映射
memblock_set_current_limit(arm_lowmem_limit);
dma_contiguous_remap(); /dma 相关的一些映射
early_fixmap_shutdown();
devicemaps_init(mdesc); //包括中断向量的映射,io空间的映射
kmap_init();
tcm_init();
top_pmd = pmd_off_k(0xffff0000);
/* allocate the zero page. */
zero_page = early_alloc(PAGE_SIZE);
bootmem_init();
empty_zero_page = virt_to_page(zero_page);
__flush_dcache_page(NULL, empty_zero_page);
}
2.1 build_mem_type_table
该函数根据CPU架构类型初始化PMD和PTE的属性信息。给静态全局变量mem_types赋值,这个变量就在本文件(arch/arm/mm/mmu.c)定义,它的用处就是在create_mapping函数创建映射时配置MMU硬件时需要。mem_types数组是kernel记录当前系统映射不同地址空间类型(普通内存 设备内存 IO空间等)的页表属性,其中页表属性还包括section-mapping的属性prot_sect,以及page-mapping的一级页目录属性prot_l1,二级页表属性prot_pte。这个都是与处理器相关的内容
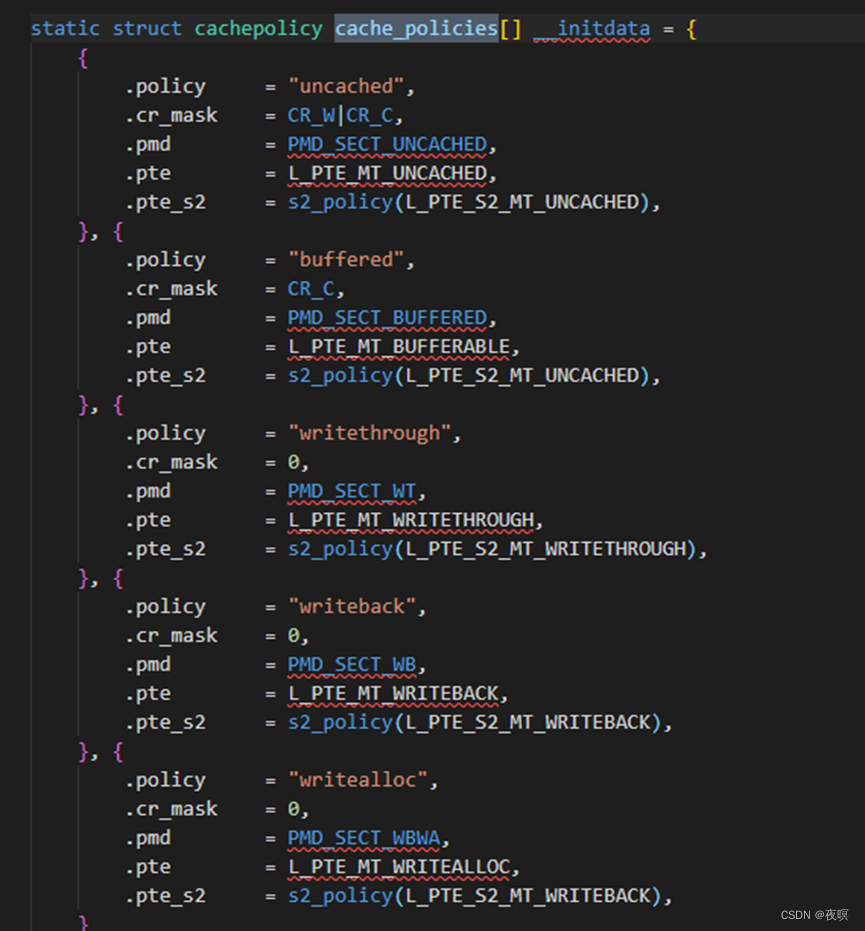
后期创建PMD和PTE时会使用到该阶段的mem_types数据结构,该函数整体比较复杂,这里不进行深究,但是有一点可以讲一下,见如下打印:


这里关系到一个内存策略的问题,writealloc对应的是如下。其含义也为字面意思,好像是写的时候才去分配,也就是说当我们申请内存时,实际上并没有真的申请出来,只有真的去写数据,才会申请真正的物理内存。
writealloc结合了write back的功能,而write back是在CACHE hit时所采取的策略,alloc是在CACHE miss所采取的策略,当发生CACHE miss时,会从主存中读取数据并更新CACHE line到CACHE缓存中
2.2 prepare_page_table
在内核使用内存之前,需要初始化内核的页表,初始化页表主要在map_lowmem()函数中。在映射页表之前,需要把页表的页表项清零,也就是把汇编阶段分配的mmu启动阶段的恒等映射的页表清空。
#define MODULES_VADDR PAGE_OFFSET //即0x8000_0000
#define PMD_SHIFT 21
#define PGDIR_SHIFT 21
#define PMD_SIZE (1UL << PMD_SHIFT) //大小为2M
#define PMD_MASK (~(PMD_SIZE-1))
#define PGDIR_SIZE (1UL << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE-1))
static inline void prepare_page_table(void)
{
unsigned long addr;
phys_addr_t end;
/*
* Clear out all the mappings below the kernel image.
*/
for (addr = 0; addr < MODULES_VADDR; addr += PMD_SIZE)
pmd_clear(pmd_off_k(addr));
for ( ; addr < PAGE_OFFSET; addr += PMD_SIZE)
pmd_clear(pmd_off_k(addr));
/*
* Find the end of the first block of lowmem.
*/
end = memblock.memory.regions[0].base + memblock.memory.regions[0].size;
if (end >= arm_lowmem_limit)
end = arm_lowmem_limit;
/*
* Clear out all the kernel space mappings, except for the first
* memory bank, up to the vmalloc region.
*/
for (addr = __phys_to_virt(end);
addr < VMALLOC_START; addr += PMD_SIZE)
pmd_clear(pmd_off_k(addr));
}
源码如上,我们具体来分析一下对pmd_clear的全过程。注意,这里面PGDIR_SHIFT已经变为了21,和实际再创建页表时的1M分法已经不同了,再这里PGD按照2M为单位,也就是说,原先的页表需要4096项对应4G,现在需要2048项对应4G
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
//这里存着初始的页表,其定义如下所示,是个longlong型,typedef unsigned long pgd_t[2];
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};
#define pgd_index(addr) ((addr) >> PGDIR_SHIFT)
假设这里传入的adr=0x7FE0_0000那么此时的索引为1023
#define pgd_offset(mm, addr) ((mm)->pgd + pgd_index(addr))
对于一个longlong型偏移1023也就等同于1M情况下的2046,即地址为0x3000_5FF8
#define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
那么这里得到的就是0x3000_5FF8
static inline pud_t * pud_offset(pgd_t * pgd, unsigned long address)
{
return (pud_t *)pgd; 对于2级页表是没有pud的,只有pgd,pmd和pte
}
static inline pmd_t *pmd_offset(pud_t *pud, unsigned long addr)
{
return (pmd_t *)pud; 即pmd=pud=pgd
}
static inline pmd_t *pmd_off_k(unsigned long virt)
{
return pmd_offset(pud_offset(pgd_offset_k(virt), virt), virt);
}
#define pmd_clear(pmdp) \
do { \
pmdp[0] = __pmd(0); \
pmdp[1] = __pmd(0); \
clean_pmd_entry(pmdp); \ 这个cp15操作,略过
} while (0)
清零的过程就是将地址里的数据赋值为0,
这里相当于0x3000_5FF8和0x3000_5FFC地址里的数据赋值0
因此这个过程就很清晰了,就是把内核地址以下的全部页表清0,然后剩下的也比较简单了,就是找到lowmem的结束位置,然后计算vmalloc(高端内存)的起始地址,将其对应的页表项全部清0。即这里的准备工作就是将内核和低端内存在内的全部其他页表清0
我们在这里再简单分析一下vmalloc的起始地址,如下源码,可以看出vmalloc的起始地址就是高端内存地址加上一个8M的偏移
#define VMALLOC_OFFSET (8*1024*1024)
#define VMALLOC_START (((unsigned long)high_memory + VMALLOC_OFFSET) & ~(VMALLOC_OFFSET-1))
#define VMALLOC_END 0xff800000UL

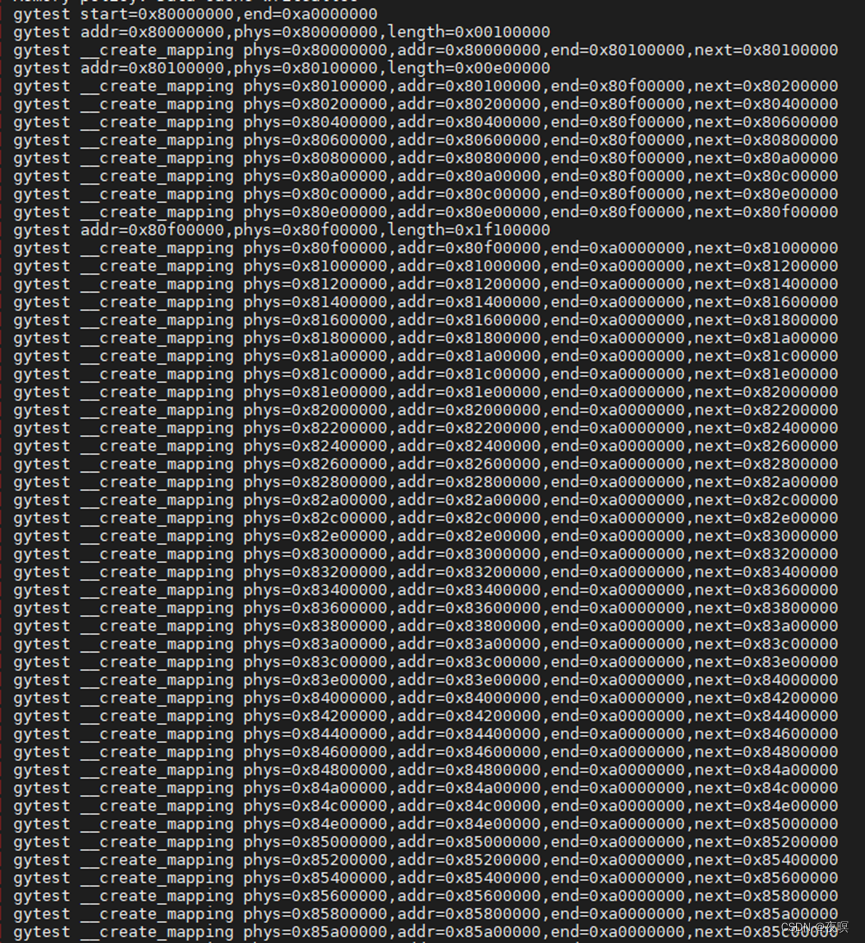
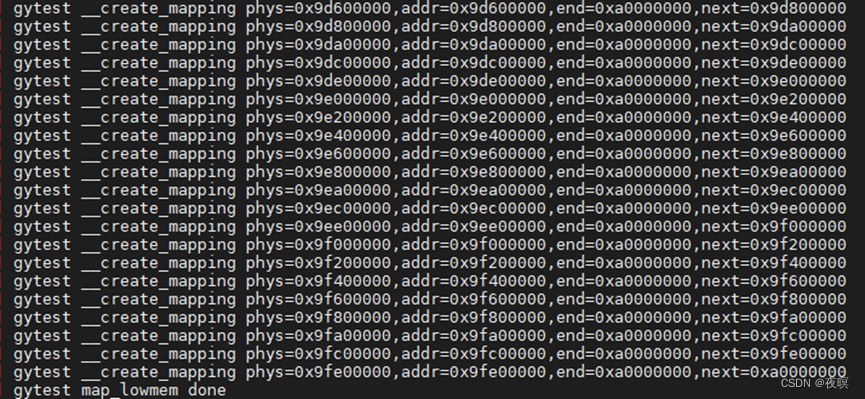
2.3 map_lowmem
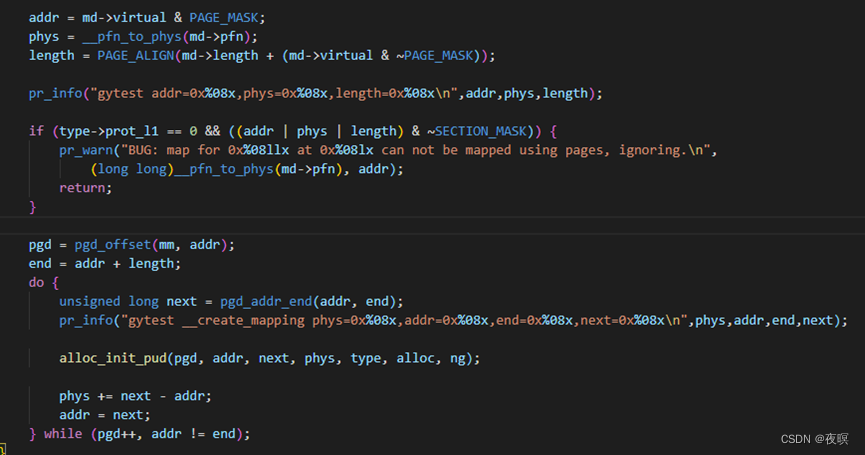
通过如下打印可以发现地段内存页表映射皆为1M(段大小)或2M的对齐
2.3.1 map_desc
在深入解析函数之前,先来了解一下一个重要的结构体
struct map_desc {
unsigned long virtual; 表示这个区间的虚拟地址的起始地址
unsigned long pfn; 物理地址开始地址的页帧号
unsigned long length; 内存区间长度
unsigned int type; 内存区间的属性
};
而对于内存区间的属性type指向类型位struct mem_type的mem_types数组
struct mem_type {
pteval_t prot_pte; PTE的属性
pteval_t prot_pte_s2; 定义CONFIG_ARM_LPAE才有效,32位机用不到的
pmdval_t prot_l1; PMD属性
pmdval_t prot_sect; section类型映射
unsigned int domain; 定义ARM不同的域
};
域定义如下,DOMAIN_KERNEL属于系统空间,DOMAIN_IO用于I/O地址域,实际也属于系统空间,DOMAIN_USER则属于用户空间。这里的域就是表项格式中的domain项
#ifndef CONFIG_IO_36
#define DOMAIN_KERNEL 0
#define DOMAIN_USER 1
#define DOMAIN_IO 2
#else
#define DOMAIN_KERNEL 2
#define DOMAIN_USER 1
#define DOMAIN_IO 0
#endif
#define DOMAIN_VECTORS 3
这里我们在把表项格式联系程序的定义重新认识一下
- 一级表项

/*
* Hardware page table definitions.
*
* + Level 1 descriptor (PMD)
* - common
*/
#define PMD_TYPE_MASK (_AT(pmdval_t, 3) << 0)
#define PMD_TYPE_FAULT (_AT(pmdval_t, 0) << 0)
#define PMD_TYPE_TABLE (_AT(pmdval_t, 1) << 0)
#define PMD_TYPE_SECT (_AT(pmdval_t, 2) << 0)
#define PMD_PXNTABLE (_AT(pmdval_t, 1) << 2) /* v7 */
#define PMD_BIT4 (_AT(pmdval_t, 1) << 4)
#define PMD_DOMAIN(x) (_AT(pmdval_t, (x)) << 5)
#define PMD_DOMAIN_MASK PMD_DOMAIN(0x0f)
#define PMD_PROTECTION (_AT(pmdval_t, 1) << 9) /* v5 */
- 二级表项
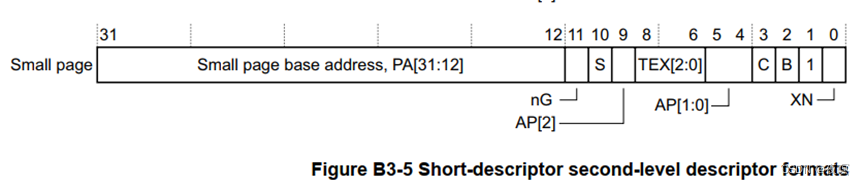
/*
* + Level 2 descriptor (PTE)
* - common
*/
#define PTE_TYPE_MASK (_AT(pteval_t, 3) << 0)
#define PTE_TYPE_FAULT (_AT(pteval_t, 0) << 0)
#define PTE_TYPE_LARGE (_AT(pteval_t, 1) << 0)
#define PTE_TYPE_SMALL (_AT(pteval_t, 2) << 0)
#define PTE_TYPE_EXT (_AT(pteval_t, 3) << 0) /* v5 */
#define PTE_BUFFERABLE (_AT(pteval_t, 1) << 2)
#define PTE_CACHEABLE (_AT(pteval_t, 1) << 3)
而实际上这些定义已经在2.1章节里面初始化完成了,只不过我们没有对其深入分析
2.3.2 map_lowmem源码解析
在分析建立页表前,我们先来看一下map_lowmem的源码,看看低端内存是根据什么进行映射的,怎么划分低端内存
该函数把memory的物理地址都做了段映射。之前在汇编里面kernel的地址已经做过段映射了,这边次把页表里面的内容再填一下
这里涉及到memblock进行物理内存的管理,每次都通过他来申请物理内存,这个之后进行分析
static void __init map_lowmem(void)
{
struct memblock_region *reg;
phys_addr_t kernel_x_start = round_down(__pa(_stext), SECTION_SIZE); 内核开始区域内存向下以1M对齐
phys_addr_t kernel_x_end = round_up(__pa(__init_end), SECTION_SIZE); 内核结束区域内存向上以1M对齐,这时得到的kernel_x_start 、kernel_x_end地址以段内存对齐。
依旧以0x3000_8000为例(内核实际的物理加载地址),那么 kernel_x_start = 0x3000_0000,kernel_x_end = 0x3100_0000 (内核大小16M的空间)
/* Map all the lowmem memory banks. */
这里依旧以物理内存地址为0x3000_0000为例,且只有一块内存,内存大小2GB
for_each_memblock(memory, reg) {
phys_addr_t start = reg->base;
phys_addr_t end = start + reg->size;
struct map_desc map;
if (memblock_is_nomap(reg))
continue;
这里arm_lowmem_limit是由函数 adjust_lowmem_bounds 进行计算的,具体计算源码不在列出,只举例这里限制值为512M大小
if (end > arm_lowmem_limit)
end = arm_lowmem_limit;
if (start >= end)
break;
---------------ex_start---------------
[MT_MEMORY_RWX] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_RW] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_XN,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE,
.domain = DOMAIN_KERNEL,
},
---------------ex_end-----------------
根据上面可知,这俩就差一个XN,也就是RWX可读可写可执行 RW可读可写不可执行
下面分了3种情况(因为可能一个设备挂了好多个物理内存)
情况1:该内存实际结束地址小于内核加载地址,可读可写可执行
情况2:起始地址在内核结束地址之后,可读可写不可执行
情况3:有3种情况,覆盖到kernel的部分可执行,其余部分都不能执行
#define PAGE_SHIFT 12
#define PHYS_PFN(x) ((unsigned long)((x) >> PAGE_SHIFT))
#define __phys_to_pfn(paddr) PHYS_PFN(paddr)
也即是说 pfn(页帧号)=phy>>12
--------------ex_start---------------
#define __PV_BITS_31_24 0x81000000
#define __pv_stub(from,to,instr,type) \
__asm__("@ __pv_stub\n" \
"1: " instr " %0, %1, %2\n" \
" .pushsection .pv_table,\"a\"\n" \
" .long 1b\n" \
" .popsection\n" \
: "=r" (to) \
: "r" (from), "I" (type))
static inline unsigned long __phys_to_virt(phys_addr_t x)
{
unsigned long t;
__pv_stub((unsigned long) x, t, "sub", __PV_BITS_31_24);
return t;
}
物理地址转为虚拟地址的源码如上,但是目前不能完全理解,涉及到一个.pv_table段操作和堆栈操作 pushsection 是个堆栈操作的伪指令。
总之推测就是 to = form + 一个偏移
Form是实际物理地址
其中pv_table在链接文件vmlinux.lds中能够找到
.init.pv_table : {
__pv_table_begin = .;
*(.pv_table)
__pv_table_end = .;
}
---------------ex_start---------------
if (end < kernel_x_start) {
map.pfn = __phys_to_pfn(start); 获取页帧号
map.virtual = __phys_to_virt(start); 获取虚拟地址
map.length = end - start; 计算长度
map.type = MT_MEMORY_RWX; 设置内存属性
create_mapping(&map);
} else if (start >= kernel_x_end) {
map.pfn = __phys_to_pfn(start);
map.virtual = __phys_to_virt(start);
map.length = end - start;
map.type = MT_MEMORY_RW;
create_mapping(&map);
} else {
/* This better cover the entire kernel */
if (start < kernel_x_start) {
map.pfn = __phys_to_pfn(start);
map.virtual = __phys_to_virt(start);
map.length = kernel_x_start - start;
map.type = MT_MEMORY_RW;
create_mapping(&map);
}
map.pfn = __phys_to_pfn(kernel_x_start);
map.virtual = __phys_to_virt(kernel_x_start);
map.length = kernel_x_end - kernel_x_start;
map.type = MT_MEMORY_RWX;
create_mapping(&map);
if (kernel_x_end < end) {
map.pfn = __phys_to_pfn(kernel_x_end);
map.virtual = __phys_to_virt(kernel_x_end);
map.length = end - kernel_x_end;
map.type = MT_MEMORY_RW;
create_mapping(&map);
}
}
}
}
2.3.3 create_mapping(段映射)
creat_mapping前面部分进行地址的校验,实现映射主体是__create_mapping
static void __init create_mapping(struct map_desc *md)
{
if (md->virtual != vectors_base() && md->virtual < TASK_SIZE) {
pr_warn("BUG: not creating mapping for 0x%08llx at 0x%08lx in user region\n",
(long long)__pfn_to_phys((u64)md->pfn), md->virtual);
return;
} /* 不能映射到用户空间 */
if ((md->type == MT_DEVICE || md->type == MT_ROM) &&
md->virtual >= PAGE_OFFSET && md->virtual < FIXADDR_START &&
(md->virtual < VMALLOC_START || md->virtual >= VMALLOC_END)) {
pr_warn("BUG: mapping for 0x%08llx at 0x%08lx out of vmalloc space\n",
(long long)__pfn_to_phys((u64)md->pfn), md->virtual);
} /* 类型不同,进不来 */
__create_mapping(&init_mm, md, early_alloc, false);
}
重点解析如下
static void __init __create_mapping(struct mm_struct *mm, struct map_desc *md, void *(*alloc)(unsigned long sz), bool ng)
{
unsigned long addr, length, end;
phys_addr_t phys;
const struct mem_type *type;
pgd_t *pgd;
type = &mem_types[md->type]; 获取对应的mem_types
假设这里传入的地址为: 0x3000_0000,虚拟地址为:0x8000_0000,长度为0x2000_0000(512M)(注:正常应该分段了,这里简化一下)
addr = md->virtual & PAGE_MASK; 获取虚拟地址,屏蔽掉后12位 还是0x8000_0000
phys = __pfn_to_phys(md->pfn); 页号转物理地址,也就是相当于物理地址屏蔽了后12位 还是0x3000_0000
length = PAGE_ALIGN(md->length + (md->virtual & ~PAGE_MASK)); 长度和虚拟地址的后12位的和,然后按照页面长度(1<<12=4096=0x1000)进行对齐。对齐后值为:0X2000_0000
if (type->prot_l1 == 0 && ((addr | phys | length) & ~SECTION_MASK)) {
pr_warn("BUG: map for 0x%08llx at 0x%08lx can not be mapped using pages, ignoring.\n",
(long long)__pfn_to_phys(md->pfn), addr);
return;
} 这里进不来,type类型不同
pgd = pgd_offset(mm, addr); 根据虚拟地址获取pgd位置,前面有过解析,这里能获得 0x8000_6000(0x3000_6000)
end = addr + length; 计算完地址0xa000_0000
#define pgd_addr_end(addr, end) \
({ unsigned long __boundary = ((addr) + PGDIR_SIZE) & PGDIR_MASK; \
(__boundary - 1 < (end) - 1)? __boundary: (end); \
})
do {
unsigned long next = pgd_addr_end(addr, end); 根据上面的宏,每次next = addr +2M
alloc_init_pud(pgd, addr, next, phys, type, alloc, ng);
pgd=0x8000_6000(0x3000_6000),addr=0x8000_0000,next=0x8020_0000
phy=0x3000_0000,ng=0,二级没有pud实际就是调用pmd
alloc_init_pmd(pud, addr, next, phys, type, alloc, ng);
phys += next - addr; 每次映射2M,物理地址也跟着走2M
addr = next;
} while (pgd++, addr != end); 直到映射完成
}
static void __init alloc_init_pmd(pud_t *pud, unsigned long addr,
unsigned long end, phys_addr_t phys,
const struct mem_type *type,
void *(*alloc)(unsigned long sz), bool ng)
{
typedef u32 pmdval_t;
typedef pmdval_t pmd_t;
typedef pmdval_t pgd_t[2];
pmd_t *pmd = pmd_offset(pud, addr); pmd=pud=pgd,注意虽然地址一样,但是pgd是8字节的单位,pmd是4字节的,也就是说pgd颗粒度是2M,那么pmd就是1M
unsigned long next;
do {
/* we don't need complex calculations here as the pmd is folded into the pgd */
这里我们不需要复杂的计算,因为pmd被折叠到pgd中,二级页表中pmd实际也不存在,因为pmd=pgd
#define pmd_addr_end(addr,end) (end)
这里end=上面传参的next=0x8020_0000,故next=0x8020_0000
next = pmd_addr_end(addr, end);
/*
* Try a section mapping - addr, next and phys must all be
* aligned to a section boundary.
*/
段的映射,都会调用__map_init_section,而alloc_init_pte的实现是进行二级页表映射。
if (type->prot_sect &&
((addr | next | phys) & ~SECTION_MASK) == 0) {
能按1M对齐的映射空间就按段式映射,不足1M的空间才需要二级映射,很明显,目前为止都是能够按照1M地址来的
__map_init_section(pmd, addr, next, phys, type, ng);
pmd=0x8000_6000(0x3000_6000).addr=0x8000_0000,next=0x8020_0000,
phy=0x3000_0000
} else {
alloc_init_pte(pmd, addr, next,
__phys_to_pfn(phys), type, alloc, ng);
}
phys += next - addr; 这里每次do,地址都是按1M算的
} while (pmd++, addr = next, addr != end);
}
static void __init __map_init_section(pmd_t *pmd, unsigned long addr,
unsigned long end, phys_addr_t phys,
const struct mem_type *type, bool ng)
{
pmd_t *p = pmd;
#ifndef CONFIG_ARM_LPAE
/*
* In classic MMU format, puds and pmds are folded in to
* the pgds. pmd_offset gives the PGD entry. PGDs refer to a
* group of L1 entries making up one logical pointer to
* an L2 table (2MB), where as PMDs refer to the individual
* L1 entries (1MB). Hence increment to get the correct
* offset for odd 1MB sections.
* (See arch/arm/include/asm/pgtable-2level.h)
*/
上诉机翻:在经典MMU格式中,PUD和PMD被折叠到PGD中。pmd_偏移量提供PGD条目。PGD指的是一组一级条目,它们构成一个指向二级表(2MB)的逻辑指针,其中PMD指的是单个一级条目(1MB)。因此,为奇数1MB段获得正确偏移量的增量。
(见arch/arm/include/asm/pgtable-2 h级)
if (addr & SECTION_SIZE)
pmd++; 这里由于颗粒度问题,本身pgd是2M的,所以传入的是1M大小的地址需要pmd地址+4也就是pmd++
#endif
#define __pmd(x) (x)
do {
*pmd = __pmd(phys | type->prot_sect | (ng ? PMD_SECT_nG : 0));
也就是说pmd地址里指向的数据就是物理地址或上段标志
即 页表地址0x8000_6000(0x3000_6000) 里的内容为 3000_0000|flag 对应的虚拟地址为0x8000_0000
页表地址 0x8000_6004(0x3000_6004) 里的内容为 3001_0000|flag 对应的虚拟地址为0x8001_0000
phys += SECTION_SIZE;
} while (pmd++, addr += SECTION_SIZE, addr != end);
flush_pmd_entry(p); flush_pmd_entry 应该是用来刷新页表缓存的,不深究,总之还是cp15对寄存器操作
}
2.4 devicemaps_init
/*
设置设备映射。由于我们清除了VMALLOC_START之上所有映射的页面表(早期fixmap除外),因此我们可能会删除调试设备映射。这意味着earlycon可以用来调试这个函数,任何其他可能接触任何设备的函数或调试方法都会使内核崩溃
*/
static void __init devicemaps_init(const struct machine_desc *mdesc)
{
struct map_desc map;
unsigned long addr;
void *vectors;
vectors = early_alloc(PAGE_SIZE * 2);
这边的early_alloc函数都是从memblock中进行分配,然后添加到该reserve域中,标记为使用,memblock进行物理内存的管理,这边返回的是虚拟地址,因为整个memory都被段映射了,所以这边的虚拟地址在物理地址上加个偏移就能得到
early_trap_init(vectors); //异常向量页表的初始化,不深究
#define FIXADDR_START 0xffc00000UL
#define FIXADDR_END 0xfff00000UL
#define FIXADDR_TOP (FIXADDR_END - PAGE_SIZE)
for (addr = VMALLOC_START; addr < (FIXADDR_TOP & PMD_MASK); addr += PMD_SIZE)
pmd_clear(pmd_off_k(addr)); 这里相当于把从VM开始到FIXADDR_TOP之间的虚拟地址的页表又全清空了
/*
* Create a mapping for the machine vectors at the high-vectors
* location (0xffff0000). If we aren't using high-vectors, also
* create a mapping at the low-vectors virtual address.
*/
map.pfn = __phys_to_pfn(virt_to_phys(vectors)); 获取到向量表的实际物理地址并获取页号
map.virtual = 0xffff0000; 虚拟地址固定到0xffff_0000
map.length = PAGE_SIZE; 大小为1页,4K大小
map.type = MT_LOW_VECTORS;
create_mapping(&map); 注意,这里映射大小为4K,小于1M,将使用二级映射!
这里涉及到中断向量表映射的一些比较复杂的东西,这里不深入,可以看https://blog.csdn.net/haolianglh/article/details/51986987
if (!vectors_high()) {
map.virtual = 0;
map.length = PAGE_SIZE * 2;
map.type = MT_LOW_VECTORS;
create_mapping(&map);
}
/* Now create a kernel read-only mapping */
map.pfn += 1;
map.virtual = 0xffff0000 + PAGE_SIZE;
map.length = PAGE_SIZE;
map.type = MT_LOW_VECTORS;
create_mapping(&map);
/*
* Ask the machine support to map in the statically mapped devices.
*/
if (mdesc->map_io)
mdesc->map_io();
else
debug_ll_io_init();
fill_pmd_gaps();
/* Reserve fixed i/o space in VMALLOC region */
pci_reserve_io();
/*
* Finally flush the caches and tlb to ensure that we're in a
* consistent state wrt the writebuffer. This also ensures that
* any write-allocated cache lines in the vector page are written
* back. After this point, we can start to touch devices again.
*/
local_flush_tlb_all();
flush_cache_all();
/* Enable asynchronous aborts */
early_abt_enable();
}
2.4.1 create_mapping(二级页表映射)
这里我们直接分析alloc_init_pte这个函数,这里我们假设中断向量表获取到的实际物理地址为0x3456_7890,虚拟地址为0xffff_0000(本身是4K对齐的),pfn=0x3_4567,len=4096
可以推出 pgd[1]=pud=pmd=0x3000_7FFC(因为虚拟地址已经在最后1M的范围内了,就是页表的最后一项),end=0xffff_1000
static void __init alloc_init_pte(pmd_t *pmd, unsigned long addr,
unsigned long end, unsigned long pfn,
const struct mem_type *type,
void *(*alloc)(unsigned long sz),
bool ng)
{
pte_t *pte = arm_pte_alloc(pmd, addr, type->prot_l1, alloc); 分配页目录项,并且把目录里面对应的页表地址返回
do {
set_pte_ext(pte, pfn_pte(pfn, __pgprot(type->prot_pte)),
ng ? PTE_EXT_NG : 0);
pfn++;
} while (pte++, addr += PAGE_SIZE, addr != end);
}
以下是alloc的指向函数,实际也是用memblock进行管理的,后面再分析
static void __init *early_alloc_aligned(unsigned long sz, unsigned long align)
{
void *ptr = __va(memblock_alloc(sz, align));
memset(ptr, 0, sz);
return ptr;
}
static void __init *early_alloc(unsigned long sz)
{
return early_alloc_aligned(sz, sz);
}
#define PTRS_PER_PTE 512
#define PTRS_PER_PMD 1
#define PTRS_PER_PGD 2048
#define PTE_HWTABLE_PTRS (PTRS_PER_PTE) //512
#define PTE_HWTABLE_OFF (PTE_HWTABLE_PTRS * sizeof(pte_t)) 512*4
#define PTE_HWTABLE_SIZE (PTRS_PER_PTE * sizeof(u32)) 512*4
static pte_t * __init arm_pte_alloc(pmd_t *pmd, unsigned long addr,
unsigned long prot,
void *(*alloc)(unsigned long sz))
{
if (pmd_none(*pmd)) {
如果pmd地址里的值为0,才进来
pte_t *pte = alloc(PTE_HWTABLE_OFF + PTE_HWTABLE_SIZE); 申请大小4096->对应1024个4字节表项,2组512个二级页表。
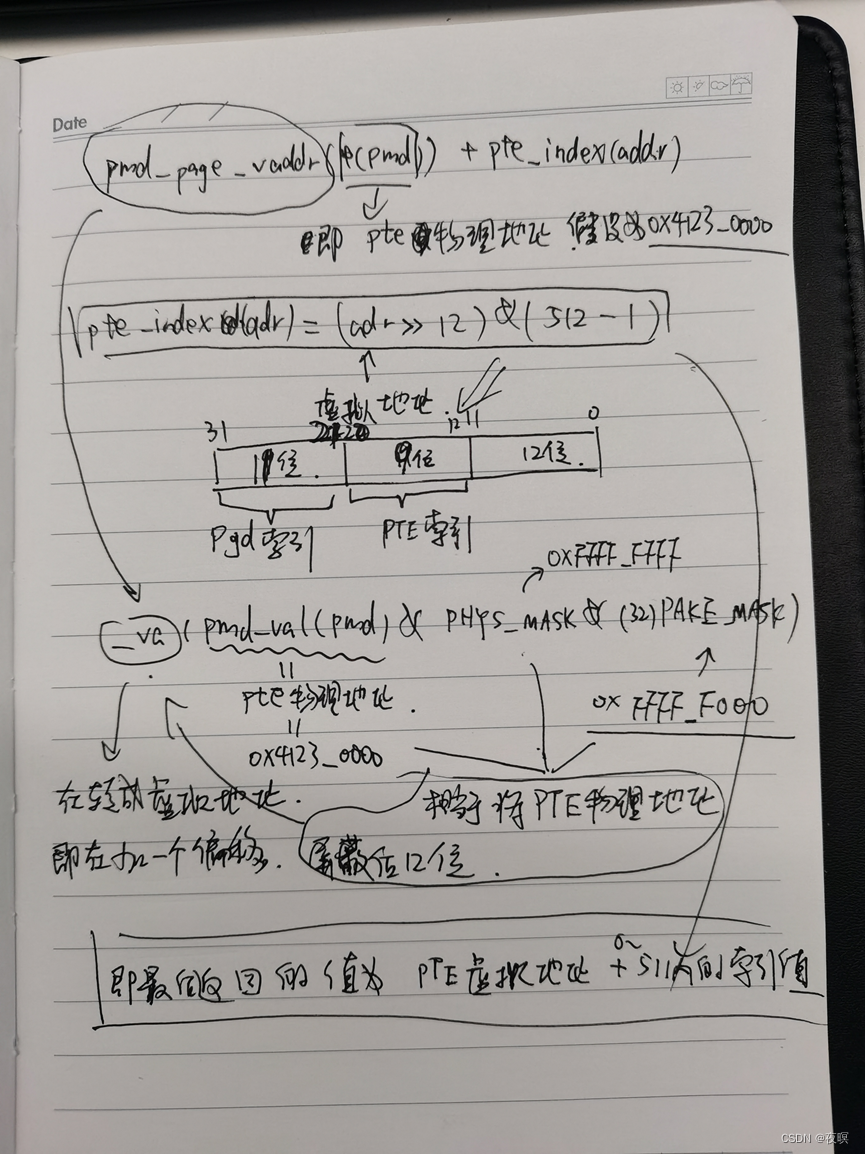
下面__pa将申请的虚拟地址转成实际地址,就是pte,即表项地址,假设该值为0x4123_0000,pmd=0x8000_7FF8(0x3000_7FF8),adr=0xffff_0000,prot=PMD_TYPE_TABLE
__pmd_populate(pmd, __pa(pte), prot);
}
BUG_ON(pmd_bad(*pmd));
return pte_offset_kernel(pmd, addr); 返回pte虚拟地址加索引值,该函数的解析看下图
}
static inline void __pmd_populate(pmd_t *pmdp, phys_addr_t pte,
pmdval_t prot)
{
pmdval_t pmdval = (pte + PTE_HWTABLE_OFF) | prot;
pmdp[0] = __pmd(pmdval); 存入表项PTE地址到pmd(前256项),相当于是在地址0x3000_7FF8中存入地址0x4123_0800 + 标志
#ifndef CONFIG_ARM_LPAE
pmdp[1] = __pmd(pmdval + 256 * sizeof(pte_t)); 存入后256项,相当于是在地址0x3000_7FFC中存入地址0x4123_0C00 + 标志
#endif
flush_pmd_entry(pmdp);
}
#define __pte(x) (x)
#define pgprot_val(x) (x)
#define pfn_pte(pfn,prot) __pte(__pfn_to_phys(pfn) | pgprot_val(prot)) 相当于 获取pfn的物理地址 + port 即要填入到页表项的内容
最后的最后,执行 set_pte_ext,这个宏相当于执行 CPU_NAME##_set_pte_ext这个函数,这个函数是个汇编,入参分别为pte的虚拟地址+索引,要填入的实际物理地址+flag,最后一参数为0
这里有一个疑惑点,为什么传参pte的地址要是虚拟地址?
我的想法是:在这个阶段已经开启了MMU,如果寻址的话,直接给实际物理地址,程序反而是不识别的,所以给出虚拟地址+偏移,经MMU转换,就是把数据存到虚拟地址对应的实际物理地址的位置了。即在MMU开启时,一切寻址操作都必须是虚拟地址的操作
/*
* cpu_v7_set_pte_ext(ptep, pte)
*
* Set a level 2 translation table entry.
*
* - ptep - pointer to level 2 translation table entry --- 放入R0
* (hardware version is stored at +2048 bytes)
* - pte - PTE value to store --------------------------- 放入R1
* - ext - value for extended PTE bits ------------------ 放入R2
*/
ENTRY(cpu_v7_set_pte_ext)
#ifdef CONFIG_MMU
str r1, [r0] 将r1的值存入r0地址的内存中
bic r3, r1, #0x000003f0 清除r1的bit[9:4],存入r3
bic r3, r3, #PTE_TYPE_MASK PTE_TYPE_MASK为0x03,记清除低2位
orr r3, r3, r2 r3与r2或,存入r3,这里r2=0,故r3不变
orr r3, r3, #PTE_EXT_AP0 | 2 这里将bit1和AP0置位(见下图1),所以是Small page
tst r1, #1 << 4 判断r1的bit4是否为0
orrne r3, r3, #PTE_EXT_TEX(1) 设置TEX为1—0x001
eor r1, r1, #L_PTE_DIRTY
tst r1, #L_PTE_RDONLY | L_PTE_DIRTY
orrne r3, r3, #PTE_EXT_APX 设置AP[2]
tst r1, #L_PTE_USER
orrne r3, r3, #PTE_EXT_AP1 设置AP[1]
tst r1, #L_PTE_XN
orrne r3, r3, #PTE_EXT_XN 设置XN位
tst r1, #L_PTE_YOUNG
tstne r1, #L_PTE_VALID
eorne r1, r1, #L_PTE_NONE
tstne r1, #L_PTE_NONE
moveq r3, #0 如果eq成立,执行mov r3,#0,不成立则该条不执行
ARM( str r3, [r0, #2048]! ) 写入r0+2048Bytes的偏移
THUMB( add r0, r0, #2048 )
THUMB( str r3, [r0] )
ALT_SMP(W(nop))
ALT_UP (mcr p15, 0, r0, c7, c10, 1) @ flush_pte
#endif
bx lr
ENDPROC(cpu_v7_set_pte_ext)
图1

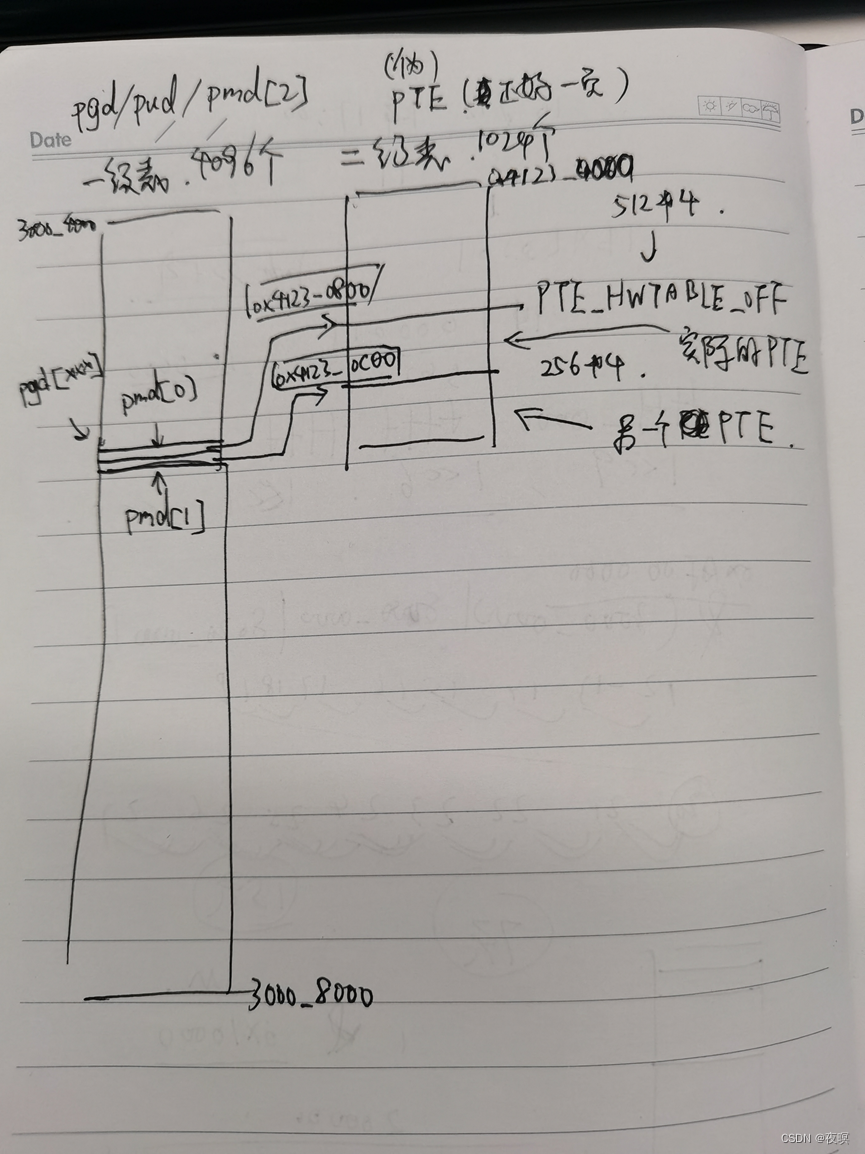
系统每次对某个虚拟地址进行映射时,先申请pgd,这个pgd是8个字节,索引11位,对于mmu来说,11位的页目录显然不对,所以填写时又分为pmd[0],pmd[1],pmd 所以12位,以1M 为单位,这个时候和mmu能对应上了,然后申请页表,一次申请4K,上面2K 用来为下面2K的做标记,下面的每页偏移512*4个字节就能找到上面的标记页,然后把下面的512又分成两份填充pmd[0],和pmd[1]。所以从实现上来看,每次分配空间,都会在页目录中填两个页目录项,范围是2M。
2.5 kmap_init
该函数为可持久内核映射区,和固定映射区分配页表,只分配没进行填充,这里只分析一下虚拟地址的规划情况
可以分析出PKMAP在用户层的最后2MB,即0x8000_0000 -2M,
该区域名为可持久内核映射区(permanent kernel mapping),可通过调用函数kmap()在物理页框与内核虚拟页之间建立长期映射。只能映射512个页框(512*4KB),数量较为稀少,所以为了加强页框的周转,应及时调用函数kunmap()将不再使用的物理页框释放。
#define PKMAP_BASE (PAGE_OFFSET - PMD_SIZE)

内核在 FIXADDR_START 到 FIXADDR_TOP 之间保留了一些线性空间用于特殊需求。这个空间称为”固定映射空间”在这个空间中,有一部分用于高端内存的临时映射。该区主要应用在多处理器系统中,因为在这个区域所获得的内存空间没有所保护,故所获得的内存必须及时使用;否则一旦有新的请求,该页框上的内容就会被覆盖,所以这个区域叫做临时映射区
#define FIXADDR_START 0xffc00000UL
#define FIXADDR_END 0xfff00000UL
#define FIXADDR_TOP (FIXADDR_END - PAGE_SIZE)

2.6 bootmem_init
在paging_init中最为重要的函数要数bootmem_init(),接下来我们来详细介绍一下bootmem_init

void __init bootmem_init(void)
{
unsigned long min, max_low, max_high;
memblock_allow_resize();
max_low = max_high = 0;
find_limits(&min, &max_low, &max_high);
early_memtest((phys_addr_t)min << PAGE_SHIFT,
(phys_addr_t)max_low << PAGE_SHIFT);
zone_sizes_init(min, max_low, max_high); /* 从min_low_pfn到max_low_pfn是ZONE_NORMAL,max_low_pfn到max_pfn是ZONE_HIGHMEM */
min_low_pfn = min;
max_low_pfn = max_low;
max_pfn = max_high;
}
zone_sizes_init中计算出每个zone大小以及zone之间的hole,然后调用free_area_init_node创建内存节点的zone
static void __init zone_sizes_init(unsigned long min, unsigned long max_low, unsigned long max_high)
{
unsigned long zone_size[MAX_NR_ZONES], zhole_size[MAX_NR_ZONES];
struct memblock_region *reg;
/*
* initialise the zones.
*/
memset(zone_size, 0, sizeof(zone_size));
/*
* The memory size has already been determined. If we need
* to do anything fancy with the allocation of this memory
* to the zones, now is the time to do it.
*/
zone_size[0] = max_low - min; /* 低端内存空间= 131072个页 */
#ifdef CONFIG_HIGHMEM
zone_size[ZONE_HIGHMEM] = max_high - max_low; /* 高端内存空间=0 */
#endif
/*
* Calculate the size of the holes.
* holes = node_size - sum(bank_sizes)
*/
memcpy(zhole_size, zone_size, sizeof(zhole_size));
for_each_memblock(memory, reg) {
unsigned long start = memblock_region_memory_base_pfn(reg);
unsigned long end = memblock_region_memory_end_pfn(reg);
if (start < max_low) {
unsigned long low_end = min(end, max_low);
zhole_size[0] -= low_end - start;
}
#ifdef CONFIG_HIGHMEM
if (end > max_low) {
unsigned long high_start = max(start, max_low);
zhole_size[ZONE_HIGHMEM] -= end - high_start;
}
#endif
}
上面的步骤扫描全部的可能存在的内存,然后根据内存模型计算实际内存空间状态,
实际上我们使用的是最简单的Flat Memory 内存个数是一个,最终计算的结果如下图1
free_area_init_node(0, zone_size, min, zhole_size);
}
void __paginginit free_area_init_node(int nid, unsigned long *zones_size,unsigned long node_start_pfn, unsigned long *zholes_size)
{
pg_data_t *pgdat = NODE_DATA(nid); /* 获取nid对应的Node数据结构 */
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
/* pg_data_t should be reset to zero when it's allocated */
WARN_ON(pgdat->nr_zones || pgdat->kswapd_classzone_idx);
pgdat->node_id = nid;
pgdat->node_start_pfn = node_start_pfn;
pgdat->per_cpu_nodestats = NULL;
start_pfn = node_start_pfn;
/* 在实际机器中获取到的pfn=0x80000,
如上我们使用实际物理地址0x3000_0000的话,
那么pfn就是0x30000 如下图2 */
/* 计算Node的page数目,512M/4KB=131072 */
calculate_node_totalpages(pgdat, start_pfn, end_pfn,
zones_size, zholes_size);
alloc_node_mem_map(pgdat); /* 为全部zone分配空间 */
#ifdef CONFIG_FLAT_NODE_MEM_MAP
printk(KERN_DEBUG "free_area_init_node: node %d, pgdat %08lx, node_mem_map %08lx\n",
nid, (unsigned long)pgdat,
(unsigned long)pgdat->node_mem_map);
#endif
reset_deferred_meminit(pgdat);
free_area_init_core(pgdat); /* 逐个初始化Node中的Zone */
}
图1

图2

图3

四、memblock
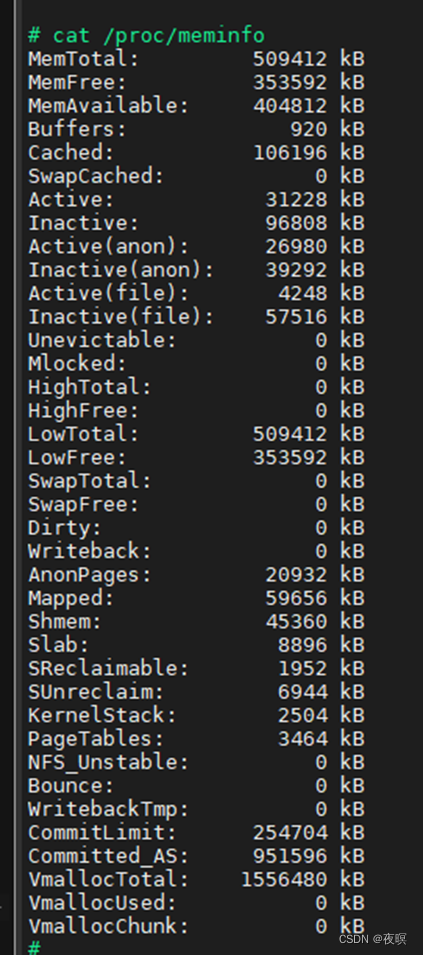
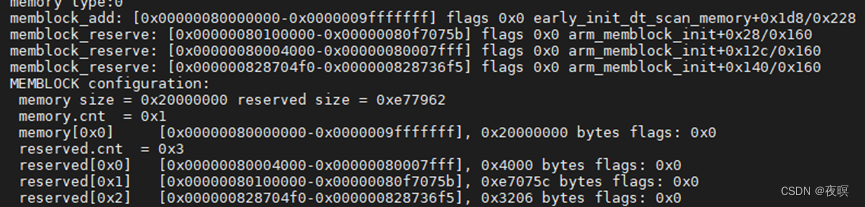
其中MemTotal:可用的总内存–总物理内存减去kernel 代码/数据段占用再减去保留的内存区,而在该设备中总共分配的可用物理内存为512M,但是这里显示的总内存为497M也就是说有一部分内存不见了,我们接下载就从最初的内存管理memblock去分析内存都哪去了
1.memblock初始化
抛开early_fixmap_init这个固定映射所使用的内存,memblock算是内核启动阶段最早的内存控制手段了,前期的页表分配都需要使用该方法。
memblock的初始化始于early_init_dt_scan_memory,即对设备树中内存部分的扫描,然后调用early_init_dt_add_memory_arch后将物理地址的起始地址及其长度通过memblock_add(base, size);进行添加,至此,memblock的内存起始和大小就获得到了,随后就是真正的初始化。
void __init arm_memblock_init(const struct machine_desc *mdesc)
{
memblock_reserve(__pa(_stext), _end - _stext);
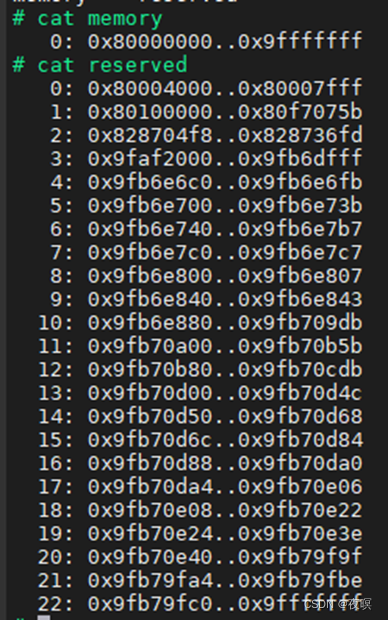
/* 预留内核代码段的内存 0x80100000..0x80f7075b 见下图1*/
arm_mm_memblock_reserve(); /* 页表区域0x80004000..0x80007fff预留 */
/* reserve any platform specific memblock areas */
if (mdesc->reserve)
mdesc->reserve();
early_init_fdt_reserve_self();
/* 设备树的预留 0x828704f8..0x828736fd 内核加载地址为0x8200_0000
内核的Zimage自身大小0x8704f8=8848632*/
early_init_fdt_scan_reserved_mem();
/* 设备树中定义了memreserve/字段的内存部分会被预留出来 */
/* reserve memory for DMA contiguous allocations */
dma_contiguous_reserve(arm_dma_limit);
arm_memblock_steal_permitted = false;
memblock_dump_all();
}
图1
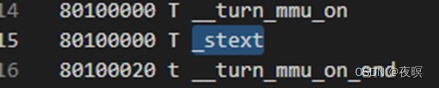
在低端内存页表映射阶段皆为1M或2M颗粒度的映射,不会进行pte分配,也就是实际上还不需要memblock预留空间,但是到了devicemaps_init中,就会实际的使用memblock进行内存预留分配了
在之后会为zone和中断预留空间,memblock申请空间是由下至上的(以高地址为下),如下部分就是给中断和zone的预留
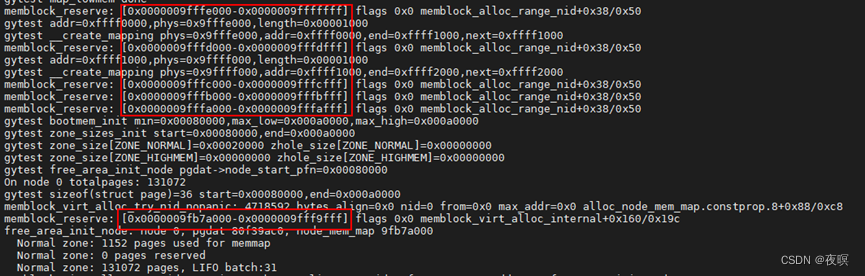
2.memblock_alloc
假如需要申请64字节的空间,那么实际流程如下:
sz=64, align=sz=64, max_addr =0, nid=-1,flag=0, start=0, end=0,
early_alloc(sz) -> early_alloc_aligned(sz, sz) -> __va(memblock_alloc(sz, align)) -> memblock_alloc_base(size, align, max_addr) -> __memblock_alloc_base(size, align, max_addr) -> memblock_alloc_base_nid(size, align, max_addr,nid,flag) -> memblock_alloc_range_nid(size, align, 0, max_addr, nid, flags) -> memblock_find_in_range_node(size, align, start, end, nid,flags) -> __memblock_find_range_top_down(0, 0, 64, 64, -1,0)
phys_addr_t __init memblock_alloc(phys_addr_t size, phys_addr_t align)
{
return memblock_alloc_base_nid(size, align, 0, NUMA_NO_NODE,
MEMBLOCK_NONE);
}
static phys_addr_t __init memblock_alloc_range_nid(phys_addr_t size,
phys_addr_t align, phys_addr_t start,
phys_addr_t end, int nid, ulong flags)
{
phys_addr_t found;
if (!align)
align = SMP_CACHE_BYTES;
found = memblock_find_in_range_node(size, align, start, end, nid,
flags); /* 最终会调用下面的函数 */
if (found && !memblock_reserve(found, size)) {
/*
* The min_count is set to 0 so that memblock allocations are
* never reported as leaks.
*/
kmemleak_alloc_phys(found, size, 0, 0);
return found;
}
return 0;
}
static phys_addr_t __init_memblock
__memblock_find_range_top_down(phys_addr_t start, phys_addr_t end,
phys_addr_t size, phys_addr_t align, int nid,
ulong flags)
{
phys_addr_t this_start, this_end, cand;
u64 i;
/* for (i = (u64)ULLONG_MAX, __next_mem_range_rev(&i, nid, flags, type_a, type_b,p_start, p_end, p_nid);
i != (u64)ULLONG_MAX;
__next_mem_range_rev(&i, nid, flags, type_a, type_b,p_start, p_end, p_nid)) */
for_each_mem_range_rev(i, &memblock.memory, &memblock.reserved, -1, 0, p_start, p_end, NULL)
for_each_free_mem_range_reverse(i, nid, flags, &this_start, &this_end,NULL) {
this_start = clamp(this_start, start, end);
this_end = clamp(this_end, start, end);
clamp(val, lo, hi) min((typeof(val))max(val, lo), hi)
if (this_end < size)
continue;
cand = round_down(this_end - size, align);
if (cand >= this_start)
return cand;
}
return 0;
}

由上图可以看出,该实际物理设备的memblock.memory就是实际物理内存的数量,memblock可以管理的memblock_region最大为128,该设备设计物理内存总大小512M基址0x8000_0000,到截图中的时候,预留了23块(与上面的debugfs下查询的memblock的出的结果一样),其中第一块预留的区域基址是0x8000_4000,大小0x4000
void __init_memblock __next_mem_range_rev(u64 *idx, int nid, ulong flags,struct memblock_type *type_a,struct memblock_type *type_b, phys_addr_t *out_start,phys_addr_t *out_end, int *out_nid)
{
入参如下
idx = &i,nid=-1,flag=0,type_a = &memblock.memory,
type_b = &memblock.reserved,out_start=&this_start
out_end=&this_end,out_nid=NULL
int idx_a = *idx & 0xffffffff; 索引的低32位
int idx_b = *idx >> 32; 索引的高32位
if (*idx == (u64)ULLONG_MAX) {
idx_a = type_a->cnt - 1;
if (type_b != NULL)
idx_b = type_b->cnt; idx_b= memblock.reserved.cnt
else
idx_b = 0;
}
for (; idx_a >= 0; idx_a--) {
struct memblock_region *m = &type_a->regions[idx_a];
m = memblock.memory.regions[idx_a],对于只有一个内存的设备,idx_a应该一直为0
phys_addr_t m_start = m->base; /* 定值,就是内存的基址,这里为0x8000_0000 */
phys_addr_t m_end = m->base + m->size; /* 定值,就是内存的结束地址,这里为0xa000_0000 */
if (!type_b) {
/* 预留为空的时候,基本不能走这里 */
if (out_start)
*out_start = m_start;
if (out_end)
*out_end = m_end;
if (out_nid)
*out_nid = m_nid;
idx_a--;
*idx = (u32)idx_a | (u64)idx_b << 32;
return;
}
/* scan areas before each reservation */
for (; idx_b >= 0; idx_b--) {
struct memblock_region *r;
phys_addr_t r_start;
phys_addr_t r_end;
r = &type_b->regions[idx_b];
/* r = memblock.reserved.regions[idx_b] */
r_start = idx_b ? r[-1].base + r[-1].size : 0;
/* 这里r_start就是对应的最大的预留块的结束地址的位置,作为其起始地址 */
r_end = idx_b < type_b->cnt ?
r->base : ULLONG_MAX;
/* 当idx_b=cnt 时,结束地址永远是最大值ffff_ffff_ffff_ffff */
/*
* if idx_b advanced past idx_a,
* break out to advance idx_a
*/
if (r_end <= m_start)
break;
/* if the two regions intersect, we're done */
if (m_end > r_start) {
if (out_start)
*out_start = max(m_start, r_start);
if (out_end)
*out_end = min(m_end, r_end);
if (out_nid)
*out_nid = m_nid;
if (m_start >= r_start)
idx_a--;
else
idx_b--;
*idx = (u32)idx_a | (u64)idx_b << 32;
return;
}
}
}
/* signal end of iteration */
*idx = ULLONG_MAX;
}
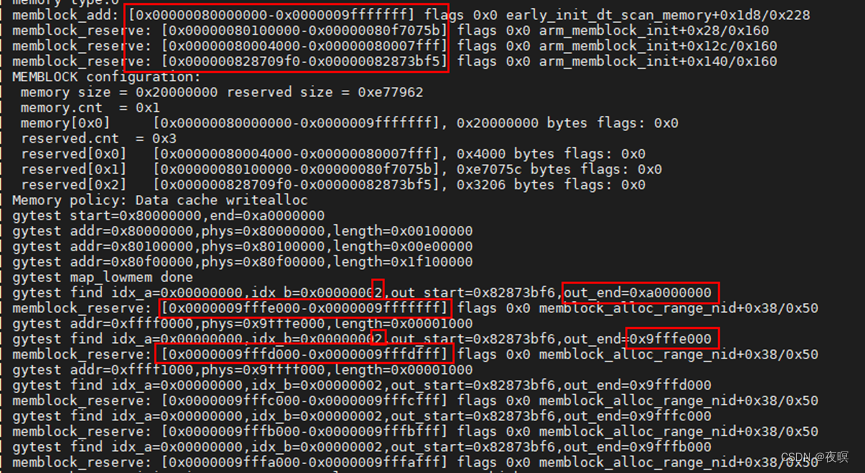
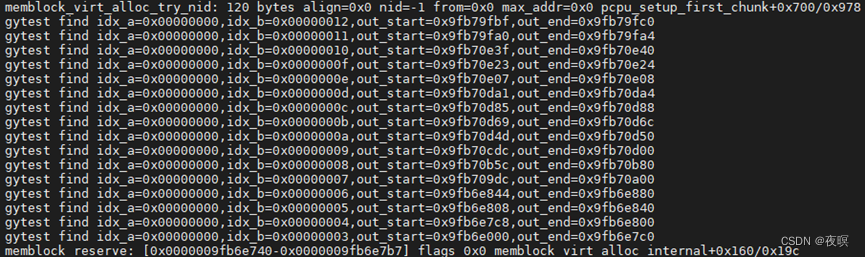
如上图为memblock申请一个空间的整个过程。然后就能得出下图
















 3383
3383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











