







昨天晚上刚提交了Cache Simulator的大作业。趁热赶紧总结一下。
基本的Cache知识可以在网上学习,这里着重总结一些知识覆盖不到的细节部分。
1. cache流程
1.1 获取上层request
实际硬件中,这是来自上层(CPU、L1或L2 cache)的request,simulator中是来自文件。格式如下:
w 400341a0
r dfcfa8
w 7b034dd4
r df7c48
r 7b034dd4
r 423aebbc
r 423aebb8
读取这些request也很简单,几行指令即可搞定:
std::ifstream traceFile;//create an instance to read file char command[11]; //create a space to save the request, I call it command. traceFile.open(filePath,std::ios::in);//filePath has been settled before while(!traceFile.eof())//when it doesn/t reach the end of line { traceFile.getline(command,11);//get this line's request(or command) }
2. 解析request
2.1 获取读/写属性
对command的第一个字符用switch...case。同时将后边的地址也解析出来用参数形式返回。这里在类中定义了枚举变量,方便阅读
Cache::addressOne Cache::getAddOne(const char* command, unsigned long int &address)
{
Cache::addressOne ret = error;
switch(command[0])
{
case 'w':ret = write;break;
case 'r':ret = read;break;
case '\0':ret = error;break;
default:
std::cout << "The content from trace file is:" <<command[0] << std::endl;
std::cout << "error in resolving command!" << std::endl;
ret = error;
}
address = std::strtoul(command+2, NULL, 16);
//get the rest of the command as the address.
//The 3rd parameter is 16 because the address is in hex.
//In this way, we can tranfer it to the number from character.
//I tried '10' in 3rd parameter, it can only recognize the 1-9 instead of 1-f.
return ret;
} typedef enum _addressOne{
error = 0,
read = 1,
write = 2,
}addressOne;2.2 解析地址
根据cache的基本知识,地址的低位是block offset,即数据在数据块内的偏移量;中间是set编号,也叫index;剩余的是tag。所以先看block offset和index占几位。根据作业说明,blocksize是个参数。假定block size等于32,为了能全部获取到这些block内容,offset宽度需为log2(32)=5。即5位offset即可确定。同理,确定了set数量即可确定index宽度。set数量计算如下图表示
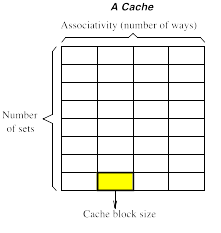
#(number of) blocks = #sets * #ways(associativity)
cache size = #blocks * block size
因此, ,index所需宽度 = log2(sets)
代码如下:
bool Cache::resolveAdd(const unsigned long int &address)
{
int offsetSize = log2(_blockSize);//_blockSize is the input parameter
int indexSize = log2(_sets);//_sets calculated in initial step
unsigned long int temp_address = address;
//use the way like 0xff&0x400341a0 = 0xa0 to extract the offset in address
_cacheadd.offset = temp_address & (int)(pow(2,offsetSize)-1);
//after extraction, you may move the address to meet the next step.
//it shoule like 0x400341a0 >> 8 = 0x400341
temp_address = temp_address >> offsetSize;
//the same as above
_cacheadd.index = temp_address & (int)(pow(2,indexSize)-1);
temp_address = temp_address >> indexSize;
_cacheadd.tag = temp_address;
return true;
}总结来说,可以概括为下图:

这里_cacheadd是私有成员变量,是个类内的struct, 定义如下:
typedef struct cacheAdd
{
unsigned long int tag;
int index;
int offset;
}cacheAdd;
3. 查看cache中是否存在这个内容
int Cache::isHit(const unsigned long int &address)
{
resolveAdd(address);
for(int i = 0; i < _Assoc; i++)
{
if(true == _cacheCell[_cacheadd.index][i].valid && _cacheadd.tag == _cacheCell[_cacheadd.index][i].tag)
{
return i;
}
}
return -1;
}对一个set的所有way遍历一遍(for(int i = 0; i < _Assoc; i++)),比较是否有需要的数据,如果有,返回数据的位置(#way),否则返回-1
4. 对第三步的查看情况结果分别处理
4.1 读hit
更新替换策略的状态
if(-1 != hit && read == direc)//如果hit返回#way,且为读状态
{
//更新替换策略的状态 update the status of replacement policy
replaceHitSet(_cacheadd.index, hit);
//计数,后期要统计miss rate. count it for miss rate calculation
_sR++;
return 0;//nothing to do for the following(lower) cache
}4.2 读miss
//没有返回#way,且为读状态 do not return #way and in read status
else if(-1 == hit && read == direc)
{
//miss rate计数器+1
_sRm++;
//执行读数据进cache操作
int result = getData(bfadjWB);
if(result)
{
wbAdd = combineAdd(bfadjWB);
return 2;//write to lower cache, then read from it
}
else
{
return 1;//read from lower cache
}
}分为三种,这三种会在后面解析:
a. 有空位,直接从下层request数据填上
b. 没有空位,根据替换策略找位置,从下层request数据填上;
c. 没有空位,根据替换策略找到的位置,此位置dirty。需要先写到下层cache或main memory,再request数据上来
4.3 写hit
更新替换策略的状态;
标记该block是dirty的。
else if(-1 != hit && write == direc)
{
replaceHitSet(_cacheadd.index, hit);
_cacheCell[_cacheadd.index][hit].dirty = true;
_sW++;
return 0;//nothing to do for the following cache
}4.4 写miss
else if(-1 == hit && write == direc)
{
int result = setData(bfadjWB);
if(result)
{
wbAdd = combineAdd(bfadjWB);
return 2;//write to lower cache
}
else
{
return 1;//allocate from lower cache
}
}写实际上是直接写到main memory,然后再write allocate 到下层cache。
分为三种:
a. 有空位,直接写入,标记dirty
b. 没有空位,根据替换策略找位置,写入,标记dirty;
c. 没有空位,根据替换策略找到的位置,此位置dirty。需要先写到下层cache或main memory,写入新数据,同时该位置仍然dirty。
5. 读miss后从下层读取数据
5.1 有空位,直接从下层request数据填上
//对当前set的每个block都检查,是否有空位
for(int i = 0; i < _Assoc; i++)
{
//如果valid状态是false,那么说明该block没有被占过,或者被inclusive policy从下层evict
//如果tag为0,那么不可能是被inclusive policy从下层evict。后期evict中不会将tag置0
if(_cacheCell[_cacheadd.index][i].valid == false && _cacheCell[_cacheadd.index][i].tag == 0)//find the empty position to fill in
{
//检查到空位后,对其赋值。实际过程是从main memory中取值上来。这里就直接把要获取的值赋给他。
_cacheCell[_cacheadd.index][i].tag = _cacheadd.tag;
//同时valid置成true,因为是读操作,从下层读上来,所以dirty仍然是false
_cacheCell[_cacheadd.index][i].valid = true;
//记得更新替换策略状态
replaceSet(_cacheadd.index, i);
return 0;
}
}5.2 没有空位,根据替换策略找位置,从下层request数据填上;
//如果上面代码没有返回退出这个函数,那么说明没有空位可用,需要替换某个block
//用替换策略找到这个可被替换的block
int replace = replaceGet(_cacheadd.index, tag);
//替换
_cacheCell[_cacheadd.index][replace].tag = _cacheadd.tag;
//更新替换策略状态
replaceSet(_cacheadd.index, replace);
//ret会在后面讲到write back时候用到
return ret;5.3 没有空位,根据替换策略找到的位置,此位置dirty。需要先写到下层cache或main memory,再request数据上来
//根据替换策略找可被替换的block
int replace = replaceGet(_cacheadd.index, tag);
//检查这个block之前有没有被写过,写过的话会被置dirty
if(_cacheCell[_cacheadd.index][replace].dirty == true)
{
//如果dirty,根据write back策略,需要将这个块同步(写)到下层cache或main memory
//所以把这个块的数据放到了output中,output是getdata函数的输出参数
output.tag = _cacheCell[_cacheadd.index][replace].tag;
output.index = _cacheadd.index;
output.offset = 0;
//write back计数器+1
_sWb++;
//因为新数据不是写的,所以这里把dirty置false
_cacheCell[_cacheadd.index][replace].dirty = false;
//返回值告诉外层需要write back
ret = 1;
}
_cacheCell[_cacheadd.index][replace].tag = _cacheadd.tag;
replaceSet(_cacheadd.index, replace);6.写miss后从下层读取数据
6.1 有空位,直接写入,标记dirty
for(int i = 0; i < _Assoc; i++)
{
if(_cacheCell[_cacheadd.index][i].valid == false /*&& _cacheCell[_cacheadd.index][i].tag == 0*/)
{
_cacheCell[_cacheadd.index][i].tag = _cacheadd.tag;
_cacheCell[_cacheadd.index][i].valid = true;
_cacheCell[_cacheadd.index][i].dirty = true;
replaceSet(_cacheadd.index, i);
_sWm++;
return 0;
}
}6.2 没有空位,根据替换策略找位置,写入,标记dirty;
int replace = replaceGet(_cacheadd.index, tag);
_cacheCell[_cacheadd.index][replace].tag = _cacheadd.tag;
_cacheCell[_cacheadd.index][replace].dirty = true;
replaceSet(_cacheadd.index, replace);
_sWm++;
return ret;6.3 没有空位,根据替换策略找到的位置,此位置dirty。需要先写到下层cache或main memory,写入新数据,同时该位置仍然dirty。
unsigned long int tag[MAX_ASSOC] = {0};
for(int i = 0; i < _Assoc; i++)
{
tag[i]=_cacheCell[_cacheadd.index][i].tag;
}
int replace = replaceGet(_cacheadd.index, tag);
if(_cacheCell[_cacheadd.index][replace].dirty == true)
{
_sWb++;
output.tag = _cacheCell[_cacheadd.index][replace].tag;
output.index = _cacheadd.index;
output.offset = 0;
ret = 1;
}
_cacheCell[_cacheadd.index][replace].tag = _cacheadd.tag;
_cacheCell[_cacheadd.index][replace].dirty = true;
replaceSet(_cacheadd.index, replace);
_sWm++;
return ret;
7. 替换策略
7.1 LRU(least recently used)
每次读写一个block,都算是一个use,基本理论如下:

首先建立一个方阵,边长为asscociaty(#way),每次读写一个block,就先将对应位置的行都置1(set),列置0(reset)。当一个set所有的block都访问过后,找方阵中,行之和为0的行,即为LRU。
void Cache::LRUset(int set, int assoc)
{
for(int k = 0; k < _Assoc; k++)
{
_LRUMatrix[set][assoc][k] = 1;
_LRUMatrix[set][k][assoc] = 0;
}
}
int Cache::LRUget(int set)
{
int sum[MAX_ASSOC] = {0};
for(int k = 0; k < _Assoc; k++)
{
for(int j = 0; j < _Assoc; j++)
{
sum[k] += _LRUMatrix[set][k][j];
}
if(!sum[k])
{
return k;
}
}
return -1;
}7.2 FIFO(First In First Out)
对于这个替换策略,容易犯的错是,hit后更新FIFO队列的状态,这样会使得队列中有两个相同元素。正确做法是,只有miss后才更新队列状态:
void Cache::replaceHitSet(int set, int assoc)
{
if(LRU == _replacementPolicy)
{
LRUset(set, assoc);
}
else if(FIFO == _replacementPolicy)
{
//do nothing
}
else if(optimal == _replacementPolicy)
{
OPTset(set, assoc);
}
}队列采用std::queue的数据结构:
void Cache::FIFOset(int set, int assoc)
{
if(_FIFOqueue[set].size() < _Assoc)
{
_FIFOqueue[set].push(assoc);
}
else
{
_FIFOqueue[set].pop();
_FIFOqueue[set].push(assoc);
}
}
需要找替换block时:
int Cache::FIFOget(int set)
{
return _FIFOqueue[set].front();
}7.3 OPT
optimal策略虽然在实际中无法实现,但是实现一下,也是对自己代码和逻辑能力的一个锻炼。
首先对给定的文件统计,这里建立了一个map数组,数组索引是set编号,map的key值是tag,value是一个队列,记录该tag访问该set时的行数:
效果大致是这样
void Cache::OPTinit(const char* filepath)
{
std::ifstream traceFile;
unsigned long int address = 0;
char command[11];
unsigned long int line = 0;
traceFile.open(filepath,std::ios::in);
while(!traceFile.eof())
{
traceFile.getline(command,11);
getAddOne(command, address);
resolveAdd(address);
_OPTarr[_cacheadd.index][_cacheadd.tag].push(line);
line++;
}
traceFile.close();
}效果大致是这样:

接下来,就是再次访问到这个set下时候,需要替换哪个block:
int Cache::OPTget(int set, unsigned long int* tag)
{
int bigone = 0, index = 0, i = 0;
for(i = 0; i < _Assoc; i++)
{
if(_OPTarr[set][tag[i]].front() > bigone)
{
bigone = _OPTarr[set][tag[i]].front();
index = i;
}
}
return index;
}这里,需要把cache中现有的数据拿来做对比。拿上图举例子,在set1中现有的tag是A 和 B,Associate为2。需要比较A和B,在下一次访问中,谁更靠后,谁离得更远。注意,这里是说下一次访问,那就是拿出queue中的front()来比较;比较谁更远,就是比较front()谁的值更大。所以这里for循环中,就是找set中,谁的下一次访问最远。bigone存储这个最远值,index就是associate的编号,跟着bigone实时更新,循环结束,那么就找到了这个需要被替换的block。
Appendix:
Cache类的头文件:
#ifndef CACHE_H_
#define CACHE_H_
#include <string>
#include <bitset>
#include <queue> /* FIFO*/
#include <map>
enum replacementPolicy
{
LRU=0,
FIFO=1,
optimal
};
enum inclusionProperty
{
noninclusive=0,
inclusive,
};
#define MAX_SET 4096
#define MAX_ASSOC 8
class Cache
{
private:
typedef struct cacheAdd
{
unsigned long int tag;
int index;
int offset;
}cacheAdd;
public:
Cache();
Cache(uint32_t size, int Assoc, int blcSize, int replace);
~Cache();
typedef struct cacheData
{
unsigned long int tag;
bool valid;
bool dirty;
}cacheData;
typedef enum _addressOne{
error = 0,
read = 1,
write = 2,
}addressOne;
private:
addressOne getAddOne(const char* command, unsigned long int &address);
bool resolveAdd(const unsigned long int &address);
unsigned long int combineAdd(const Cache::cacheAdd &address);
int isHit(const unsigned long int &address);
int getData(cacheAdd &output);
int setData(cacheAdd &output);
void createCache(void);
void initVariables(void);
void setSETs();
//Replacement Policy
void replaceSet(int set, int assoc);
void replaceHitSet(int set, int assoc);
int replaceGet(int set, unsigned long int* tag = NULL);
//LRU
void LRUset(int set, int assoc);
int LRUget(int set);
//FIFO
void FIFOset(int set, int assoc);
int FIFOget(int set);
int OPTget(int set, unsigned long int* tag);
void OPTset(int set, int assoc);
public:
int deal(const char* command, unsigned long int &address, unsigned long int &wbAdd);
int deal(addressOne direc, unsigned long int &address, unsigned long int &wbAdd);
void evict(unsigned long int &address);
void OPTinit(const char* filepath);
// int getSIZE(void);
int getSETs(void);
int getASSOCs();
cacheData getContent(int set, int assoc);
int getSRm(void);
int getSWm(void);
int getSR(void);
int getSW(void);
double getSTr(void);
double getSTr2(void);
int getSWb(void);
int getSTt(void);
private:
cacheData _cacheCell[MAX_SET][MAX_ASSOC];//0-31:tag; 32:valid; 33:dirty; 34:hit
//LRU
int _LRUMatrix[MAX_SET][MAX_ASSOC][MAX_ASSOC];
//FIFO
std::queue<int> _FIFOqueue[MAX_SET];
//OPT
std::map<unsigned long int, std::queue<unsigned long int>> _OPTarr[MAX_SET];
cacheAdd _cacheadd;
uint32_t _totalSize;
int _blockSize;
int _Assoc;
int _sets;
// int _L1Size;
// int _L1Assoc;
// int _L2Size;
// int _L2Assoc;
int _replacementPolicy;
int _inclusionProperty;
std::string _traceFile;
char address[11];
//for statistics
int _sR; //Read and hit
int _sRm; //Read and miss
int _sW; //Write and hit
int _sWm; //Write and miss
int _sWb; //Write back
int _swmmmm;//debug
};
#endif // CACHE_H_















 6103
6103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









