









给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"] 输出: true 解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"] 输出: true 解释: 返回 true 因为"applepenapple"可以由"apple" "pen" "apple" 拼接成。 注意,你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] 输出: false
提示:
1 <= s.length <= 3001 <= wordDict.length <= 10001 <= wordDict[i].length <= 20s和wordDict[i]仅由小写英文字母组成wordDict中的所有字符串 互不相同
思路
#背包问题
单词就是物品,字符串s就是背包,单词能否组成字符串s,就是问物品能不能把背包装满。
拆分时可以重复使用字典中的单词,说明就是一个完全背包!
动规五部曲分析如下:
1. 确定dp数组以及下标的含义
dp[i] : 字符串长度为i的话,dp[i]为true,表示可以拆分为一个或多个在字典中出现的单词。
2. 确定递推公式
如果确定dp[j] 是true,且 [j, i] 这个区间的子串出现在字典里,那么dp[i]一定是true。(j < i )。
所以递推公式是 if([j, i] 这个区间的子串出现在字典里 && dp[j]是true) 那么 dp[i] = true。
3. dp数组如何初始化
从递推公式中可以看出,dp[i] 的状态依靠 dp[j]是否为true,那么dp[0]就是递推的根基,dp[0]一定要为true,否则递推下去后面都都是false了。
那么dp[0]有没有意义呢?
dp[0]表示如果字符串为空的话,说明出现在字典里。
但题目中说了“给定一个非空字符串 s” 所以测试数据中不会出现i为0的情况,那么dp[0]初始为true完全就是为了推导公式。
下标非0的dp[i]初始化为false,只要没有被覆盖说明都是不可拆分为一个或多个在字典中出现的单词。
4. 确定遍历顺序
题目中说是拆分为一个或多个在字典中出现的单词,所以这是完全背包。
还要讨论两层for循环的前后顺序。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
本题其实我们求的是排列数,为什么呢。 拿 s = "applepenapple", wordDict = ["apple", "pen"] 举例。
"apple", "pen" 是物品,那么我们要求 物品的组合一定是 "apple" + "pen" + "apple" 才能组成 "applepenapple"。
"apple" + "apple" + "pen" 或者 "pen" + "apple" + "apple" 是不可以的,那么我们就是强调物品之间顺序。
所以说,本题一定是 先遍历 背包,再遍历物品。
5. 举例推导dp[i]
以输入: s = "leetcode", wordDict = ["leet", "code"]为例,dp状态如图:
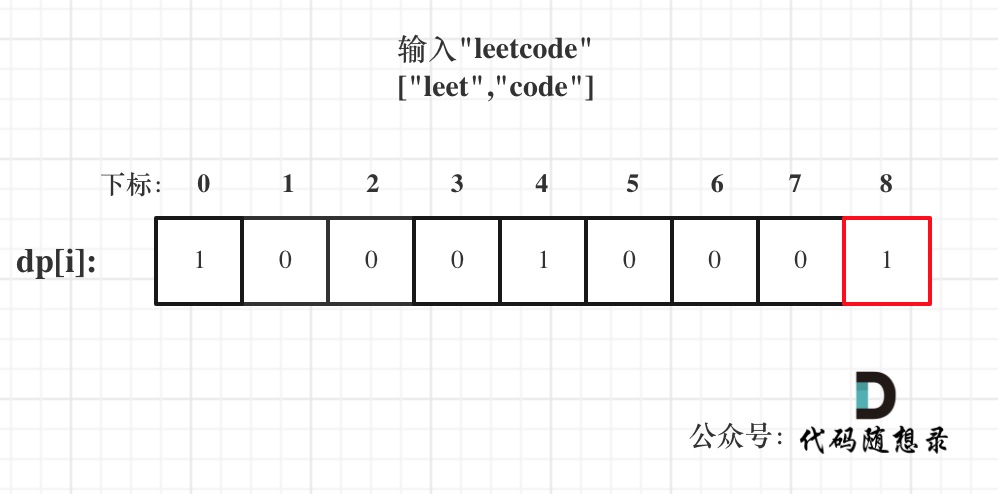
dp[s.size()]就是最终结果。
动规五部曲分析完毕,C++代码如下:
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
vector<bool> dp(s.size() + 1, false);
dp[0] = true;
for (int i = 1; i <= s.size(); i++) { // 遍历背包
for (int j = 0; j < i; j++) { // 遍历物品
string word = s.substr(j, i - j); //substr(起始位置,截取的个数)
if (wordSet.find(word) != wordSet.end() && dp[j]) {
dp[i] = true;
}
}
}
return dp[s.size()];
}
};
- 时间复杂度:O(n^3),因为substr返回子串的副本是O(n)的复杂度(这里的n是substring的长度)
- 空间复杂度:O(n)
注意: 不要把wordDict里的元素当成物品,这个数组里面的东西不是物品,它只是用来检测的工具!!!物品都从s字符串中拿,背包的容量也是根据s字符串长度而来,也就是都在同一数组里,只不过遍历物品的时候,这个物品长度要小于当前背包容量,说白了都是长度















 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









