







ES集群与zookeeper集群及kafka集群的安装部署
6.1、ELK应用案例


6.2、环境与角色说明
1.操作系统统一采用CentOS7.5版本
|
IP地址
|
主机名
|
角色
|
所属集群
|
|
192.168.126.130
|
filebeatserver
|
业务服务器+filebeat
|
业务服务器集群
|
|
192.168.126.129
|
kafka1
|
kafka+ZooKpeeper
|
kafka Broker集群
|
|
192.168.126.139
|
kafka2
|
kafka+ZooKpeeper
|
kafka Broker集群
|
|
192.168.126.149
|
kafka3
|
kafka+ZooKpeeper
|
kafka Broker集群
|
|
192.168.126.131
|
Logstashserver
|
Logstash
|
数据转发
|
|
192.168.126.128
|
server1
|
ES Master、ES NataNode
|
Elasticsearch集群
|
|
192.168.126.138
|
server2
|
ES Master、Kibanae
|
Elasticsearch集群
|
|
192.168.126.148
|
server3
|
ES Master、ES NataNode
|
Elasticsearch集群
|
2.软件环境与版本

一、安装部署-(除了filebeat其他都要安装JDK)
1.安装JAVA环境
1.1、解压jdk并指定解压目录
tar zxvf jdk-8u152-linux-x64.tar.gz -C /usr/local/

1.2.修改环境变量
vim /etc/profile
#尾部添加一下内容
export JAVA_HOME=/usr/local/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$CLASSPATH
#保存退出后执行
source /etc/profile
1.3.显示java版本
[root@localhost local]# java -version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
显示上述内容说明环境变量配置成功了
6.4、安装并配置elasticsearch集群
1.el
asticsearch集群的架构与角色


2.安装elasticsearch与授权
解压elasticsearch压缩包到指定目录
tar zxvf elasticsearch-6.3.2.tar.gz -C /usr/local

修改解压后的文件名
cd /usr/local/
mv elasticsearch-6.3.2 elasticsearch

创建用户并授权
[root@localhost elasticsearch]# useradd elasticsearch
[root@localhost elasticsearch]# passwd elasticsearch
更改用户 elasticsearch 的密码 。
新的 密码:
无效的密码: 密码少于 8 个字符
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
[root@localhost elasticsearch]# chown -R elasticsearch:elasticsearch /usr/local/elasticsearch
3、操作系统调优
操作系统以及
JVM
调优主要是针对安装
elasticsearch
的机
器。
#修改vim /etc/sysctl.conf文件,添加以下内容
fs.file-max=655360
vm.max_map_count = 262144
#fs.file-max主要是配置系统最大打开文件描述符数,建议修改为655360或者更高
#vm.max_map_count影响Java线程数量,用于限制一个进程可以拥有的VMA(虚拟内存区域)的大小,系统默认是65530,建议修改成262144或者更高
#添加如下内容到/etc/security/limits.conf文件中
* soft nproc 20480
* hard nproc 20480
* soft nofile 655360
* hard nofile 655360
* soft memlock unlimited
* hard memlock unlimited调整进程最大打开文件描述符(nofile)、最大用户进程数(nproc)和最大锁定内存地址空间(memlock)
修改/etc/security/limits.d/20-nproc.conf文件(centos7.x系统),将:
* soft nproc 4096
修改为:
* soft nproc 40960
或者直接删除/etc/security/limits.d/20-nproc.conf文件也行。
#使用sysctl -p 使/etc/sysctl.conf文件生效

使用exit退出登录使文件生效
查看配置文件是否生效
[root@localhost ~]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 3795
max locked memory (kbytes, -l) unlimited
max memory size (kbytes, -m) unlimited
open files (-n) 655360
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 20480
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
4、JVM调优
JVM调优主要是针对elasticsearch的JVM内存资源进行优化,elasticsearch的内存资源配置文件为jvm.options,
此文件位于
/
usr
/local/
elasticsearch
/
config
目录下,打开此文件
,修改如下内容:
JVM内存默认
为2g,
一般设置为服务器物理内存的一半最佳。
-Xms2g
-Xmx2g
5、配置elasticsearch

elasticsearch
的配置文件均在
elasticsearch
根目录下的
config
文件夹,这里是
/
usr
/local/
elasticsearch
/
config
目录,主要有
jvm.options
、
elasticsearch.yml
和
log4j2.properties
三个主要配置文件
。这
里重点介绍
elasticsearch.yml
一些重要的配置项及其含义
。
创建索引数据的存储路径
mkdir -p /data1/elasticsearch
mkdir -p /data2/elasticsearch
chown -R elasticsearch:elasticsearch /data1/elasticsearch
chown -R elasticsearch:elasticsearch /data2/elasticsearch
这里配置的elasticsearch.yml文件内容如下:
cluster.name: elkbigdata
node.name: server1
node.master: true
node.data: true
path.data: /data1/elasticsearch,/data2/elasticsearch
path.logs: /usr/local/elasticsearch/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.minimum_master_nodes: 1
discovery.zen.ping.unicast.hosts: ["192.168.126.128:9300","192.168.126.129:9300"]
elasticsearch.yml文件注释
(1)cluster.name: elkbigdata
配置elasticsearch集群名称,默认是elasticsearch。这里修改为elkbigdata,elasticsearch会自动发现在同一网段下的集群名为elkbigdata的主机。
(2)node.name: server1
节点名,任意指定一个即可,这里是server1,我们这个集群环境中有三个节点,分别是server1、server2和server3,记得根据主机的不同,要修改相应的节点名称。
(3)node.master: true
指定该节点是否有资格被选举成为master,默认是true,elasticsearch集群中默认第一台启动的机器为master角色,如果这台服务器宕机就会重新选举新的master。
(4)node.data: true
指定该节点是否存储索引数据,默认为true,表示数据存储节点,如果节点配置node.master:false并且node.data: false,则该节点就是client node。这个client node类似于一个“路由器”,负责将集群层面的请求转发到主节点,将数据相关的请求转发到数据节点。
(5)path.data:/data1/elasticsearch,/data2/elasticsearch
设置索引数据的存储路径,默认是elasticsearch根目录下的data文件夹,这里自定义了两个路径,可以设置多个存储路径,用逗号隔开。
(6)path.logs: /usr/local/elasticsearch/logs
设置日志文件的存储路径,默认是elasticsearch根目录下的logs文件夹
(7)bootstrap.memory_lock: true
此配置项一般设置为true用来锁住物理内存。 linux下可以通过“ulimit -l” 命令查看最大锁定内存地址空间(memlock)是不是unlimited
(8)network.host: 0.0.0.0
此配置项用来设置elasticsearch提供服务的IP地址,默认值为0.0.0.0,此参数是在elasticsearch新版本中增加的,此值设置为服务器的内网IP地址即可。
(9)http.port: 9200
设置elasticsearch对外提供服务的http端口,默认为9200。其实,还有一个端口配置选项transport.tcp.port,此配置项用来设置节点间交互通信的TCP端口,默认是9300。
(10)discovery.zen.minimum_master_nodes: 1
配置当前集群中最少的master节点数,默认为1,也就是说,elasticsearch集群中master节点数不能低于此值,如果低于此值,elasticsearch集群将停止运行。在三个以上节点的集群环境中,建议配置大一点的值,推荐2至4个为好。
(11)discovery.zen.ping.unicast.hosts: ["172.16.213.37:9300","172.16.213.78:9300"]
设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。这里需要注意,master节点初始列表中对应的端口是9300。即为集群交互通信端口。
9200与9300端口的区别:
9200 是ES节点与外部通讯使用的端口。它是http协议的RESTful接口
9300是ES节点之间通讯使用的端口。它是tcp通讯端口,集群间和TCPclient都走的它。
启动es,并将它作为后台守护进程运行
#启动路径如下
[root@localhost elasticsearch]# pwd
/usr/local/elasticsearch
[root@localhost elasticsearch]# bin/elasticsearch -d
注意:虽然启动没有报错,但使用ps ef |grep java,并没有发现启动进程
查看日志

不能以root用户运行es
以之前创建的普通用户启动。
[root@localhost local]# su - elasticsearch
[elasticsearch@localhost ~]$ cd /usr/local/elasticsearch/
[elasticsearch@localhost elasticsearch]$ ls
bin lib logs NOTICE.txt README.textile
config LICENSE.txt modules plugins
[elasticsearch@localhost elasticsearch]$ bin/elasticsearch -d
将整个logs目录授权给普通用户
[root@localhost ~]# cd /usr/local/
[root@localhost local]#
[root@localhost local]# cd elasticsearch/
[root@localhost elasticsearch]# ls
bin config lib LICENSE.txt logs modules NOTICE.txt plugins README.textile
[root@localhost elasticsearch]# chown -R elasticsearch:elasticsearch logs
[root@localhost elasticsearch]# ll
总用量 448
drwxr-xr-x. 3 elasticsearch elasticsearch 4096 4月 16 21:44 bin
drwxr-xr-x. 2 elasticsearch elasticsearch 178 4月 17 11:08 config
drwxr-xr-x. 2 elasticsearch elasticsearch 4096 7月 20 2018 lib
-rw-r--r--. 1 elasticsearch elasticsearch 13675 7月 20 2018 LICENSE.txt
drwxr-xr-x. 2 elasticsearch elasticsearch 244 4月 17 11:08 logs
drwxr-xr-x. 17 elasticsearch elasticsearch 4096 7月 20 2018 modules
-rw-r--r--. 1 elasticsearch elasticsearch 416018 7月 20 2018 NOTICE.txt
drwxr-xr-x. 2 elasticsearch elasticsearch 6 7月 20 2018 plugins
-rw-r--r--. 1 elasticsearch elasticsearch 8511 7月 20 2018 README.textile
[root@localhost elasticsearch]#
最后可以重启一下
检验elasticsearch是否安装成功

6.5
、安装并配置
ZooKeeper
集群
注意:先要按之前要求装好JAVA环境,这里就不展示了

1、解压和重命名zookeeper
[root@localhost ~]# tar -zxvf zookeeper-3.4.11.tar.gz -C /usr/local
[root@localhost ~]# mv /usr/local/zookeeper-3.4.11 /usr/local/zookeeper
2、配置zookeeper
zookeeper
的配置模板文件为
/
usr
/local/zookeeper/
conf
/
zoo_sample.cfg
,拷贝
zoo_sample.cfg
并重命名为
zoo.cfg
,重点配置如下内容:
#源文件有对应的信息,可以直接注释掉复制下列信息
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
server.1=172.16.213.51:2888:3888
server.2=172.16.213.109:2888:3888
server.3=172.16.213.75:2888:3888
每个配置项含义如下:
每个配置项含义如下:
tickTime:zookeeper使用的基本时间度量单位,以毫秒为单位,它用来控制心跳和超时。2000表示2 tickTime。更低的tickTime值可以更快地发现超时问题。
initLimit:这个配置项是用来配置Zookeeper集群中Follower服务器初始化连接到Leader时,最长能忍受多少个心跳时间间隔数(也就是tickTime)
syncLimit:这个配置项标识Leader与Follower之间发送消息,请求和应答时间长度最长不能超过多少个tickTime的时间长度
dataDir:必须配置项,用于配置存储快照文件的目录。需要事先创建好这个目录,如果没有配置dataLogDir,那么事务日志也会存储在此目录。
clientPort:zookeeper服务进程监听的TCP端口,默认情况下,服务端会监听2181端口。
server.A=B:C:D:其中A是一个数字,表示这是第几个服务器;B是这个服务器的IP地址;C表示的是这个服务器与集群中的Leader服务器通信的端口;D 表示如果集群中的Leader服务器宕机了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
3、创建 目录和pmyid文件
mkdir /data/zookeeper -p
vim /data/zookeeper/myid
在dataDir配置项指定的目录下创建myid文件, 这个文件里面只有一个数字,如果要写入1,表示第一个服务器,与zoo.cfg文本中的server.1中的1对应,以此类推,在集群的第二个服务器zoo.cfg配置文件中dataDir配置项指定的目录下创建myid文件,写入2,这个2与zoo.cfg文本中的server.2中的2对应。Zookeeper在启动时会读取这个文件,得到里面的数据与zoo.cfg里面的配置信息比较,从而判断每个zookeeper server的对应关系

4、启动zookpeer服务器
/usr/local/zookeeper/bin
./zkServer.sh start

以同样方法安装部署另外几台zookpeer服务器。
Zookeeper
启动后,通过
jps
命令(
jdk
内置命令)可以看到有一个
QuorumPeerMain
标识,这个就是
Zookeeper
启动的进程,前面的数字是
Zookeeper
进程的
PID
。

将启动路径添加到系统环境变量
/
etc
/profile中,在任意路径都可以执行“zkServer.sh start”命令了
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#使刚修改的文件生效
source /etc/profile
接着在zookpeer服务器上安装kafka
1、解压并重命名
[root@localhost ~]# tar -zxvf kafka_2.10-0.10.0.1.tgz -C /usr/local
[root@localhost ~]# mv /usr/local/kafka_2.10-0.10.0.1 /usr/local/kafka
2、配置kafka集群
去掉#号行和空行
sed -i '/^\s*#/d;/^\s*$/d' 文件名
kafka 的主配置文件为 / usr /local/ kafka / config / server.properties修改文件以下内容broker.id=1listeners=PLAINTEXT://192.168.126.129:9092log.dirs=/usr/local/kafka/logsnum.partitions=6log.retention.hours=60log.segment.bytes=1073741824zookeeper.connect=192.168.126.129:2181 #后面可以添加多几台服务器用逗号分开auto.create.topics.enable=truedelete.topic.enable=true
3、配置详解
* broker.id:每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况。* llisteners:设置kafka的监听地址与端口,可以将监听地址设置为主机名或IP地址,这里将监听地址设置为IP地址。* llog.dirs:这个参数用于配置kafka保存数据的位置,kafka中所有的消息都会存在这个目录下。可以通过逗号来指定多个路径, kafka会根据最少被使用的原则选择目录分配新的parition。需要注意的是,kafka在分配parition的时候选择的规则不是按照磁盘的空间大小来定的,而是根据分配的 parition的个数多小而定。* lnum.partitions:这个参数用于设置新创建的topic有多少个分区,可以根据消费者实际情况配置,配置过小会影响消费性能。这里配置6个。* llog.retention.hours:这个参数用于配置kafka中消息保存的时间,还支持log.retention.minutes和 log.retention.ms配置项。这三个参数都会控制删除过期数据的时间,推荐使用log.retention.ms。如果多个同时设置,那么会选择最小的那个。* llog.segment.bytes:配置partition中每个segment数据文件的大小,默认是1GB,超过这个大小会自动创建一个新的segment file。* lzookeeper.connect:这个参数用于指定zookeeper所在的地址,它存储了broker的元信息。 这个值可以通过逗号设置多个值,每个值的格式均为:hostname:port/path,每个部分的含义如下:* hostname:表示zookeeper服务器的主机名或者IP地址,这里设置为IP地址。* port: 表示是zookeeper服务器监听连接的端口号。* /path:表示kafka在zookeeper上的根目录。如果不设置,会使用根目录。* lauto.create.topics.enable:这个参数用于设置是否自动创建topic,如果请求一个topic时发现还没有创建, kafka会在broker上自动创建一个topic,如果需要严格的控制topic的创建,那么可以设置auto.create.topics.enable为false,禁止自动创建topic。* ldelete.topic.enable:在0.8.2版本之后,Kafka提供了删除topic的功能,但是默认并不会直接将topic数据物理删除。如果要从物理上删除(即删除topic后,数据文件也会一同删除),就需要设置此配置项为true。
4、启动kafka
#执行路径
[root@localhost bin]# pwd
/usr/local/kafka/bin
#放到后台启动,启动后,会在启动kafka的当前目录下生成一个nohup.out文件
[root@localhost bin]#nohup ./kafka-server-start.sh ../config/server.properties &

4、验证是否启动
QuorumPeerMain是zookeeper进程

同样样方式在两台服务器上安装配置zookpeer和kafka服务
5
、
kafka
集群基本命令操作
1
)显示
topic
列
表
bin/kafka-topics.sh --zookeeper 172.23.148.60:2181,172.23.148.61:2181,172.23.148.62:2181 --list
(
2
)创建一个
topic
,并指定
topic
属性(副本数、分区数等
)
它将被分为 3 个分区,并且每个分区将有 2 个副本
bin/kafka-topics.sh --zookeeper 172.23.148.60:2181,172.23.148.61:2181,172.23.148.62:2181 --create --topic my-topic --partitions 3 --replication-factor 2

(
3
)查看某个
topic
的状
态信息

(
4
)生产消
息
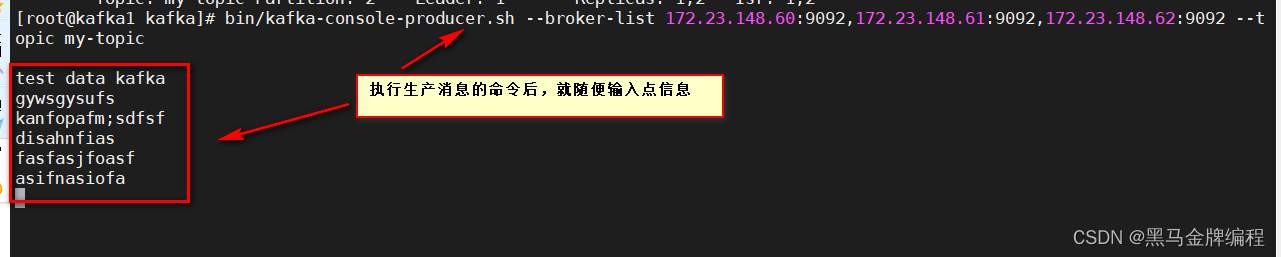
(
5
)消费消
息
bin/kafka-console-consumer.sh --zookeeper 172.23.148.60:2181,172.23.148.61:2181,172.23.148.62:2181 --topic my-topic
bin/kafka-console-consumer.sh --zookeeper 172.23.148.60:2181,172.23.148.61:2181,172.23.148.62:2181 --topic my-topic --from-beginning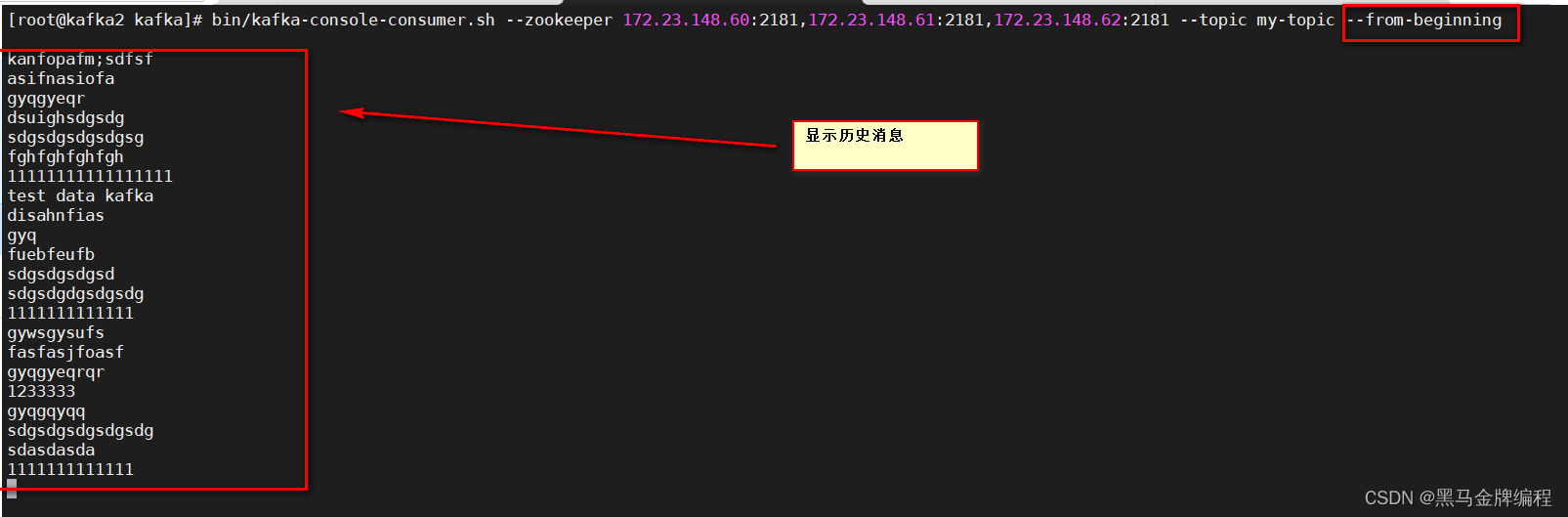
(
6
)删除
topic
bin/kafka-topics.sh --zookeeper 172.23.148.60:2181,172.23.148.61:2181,172.23.148.62:2181 --delete --topic my-topic
Topic my-topic is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.

Kafka 采用异步方式进行主题的删除操作。主题在被标记为删除后,并不会立即从元数据中移除。相反,Kafka 将继续在后台进行清理工作,并最终从元数据中彻底删除主题。
















 1308
1308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











