一、哈希表的底层数据结构
- jdk1.8之后,哈希表的底层数据结构就是数组+链表+红黑树。
- 引入链表的原因是为了解决哈希冲突。
- 引入红黑树的原因则是为了增加查找的效率。
- 如果不发生哈希冲突的话,哈希表的查找时间复杂度应该是O(1),如果发生了哈希冲突,则其查找时间复杂度应该是O(n),而一旦引入了红黑树,其查找的时间复杂度就会变为O(logn)。
- 这样就会出现两个问题:
- 为什么不直接使用红黑树,而是在链表的深度大于等于8,数组容量大于等于64时才使用红黑树(如果链表长度大于8,但是数组容量小于64,通过扩容处理)。
- 为什么使用红黑树而不是二叉排序树和AVL树(平衡二叉查找树)。
- 先来说第一个问题,为什么不直接使用红黑树:
- 这个原因很简单,因为如果直接使用红黑树的话,红黑树有一个自平衡的操作(左旋,右旋,变色),这是十分浪费CPU资源的。而且根据哈希表的源码,链表的节点深度能达到8个的概率是十分小的。所以,只有在大数据量的情况下才使用红黑树。
- 第二个问题,为什么使用红黑树而不是二叉排序树和AVL树:
- 首先,先来说下这三种树的定义:
- 二叉排序树(如下图):
- 二叉排序树(又称二叉查找树):
1)若左子树不为空,则左子树上所有结点的值均小于根结点的值。
2)若右子树不为空,则右子树上所有结点的值均大于根节点的值。
3)左右子树也为二叉排序树。

- 这样的树也是二叉排序树,很明显其左子树已经退化成链表了,这岂不是凉凉。所以不能用二叉排序树。
- 红黑树和AVL树(平衡二叉查找树):
- AVL树(平衡二叉查找树)
- AVL树其实就是在二叉查找树的基础上增加了自平衡操作。
- 一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡。
- 它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树(如下图)。

- 如上图所示右边的就是之前二叉排序树出现的退化成链表的现象,而左边的AVL树则解决了这一缺陷。
- 红黑树:
- 红黑树其实也是一种平衡二叉树,但他没有AVL树那么平衡,他是通过颜色来辨别是否需要平衡操作的,而且红黑树对左右子树的高度差也没有具体的要求,所以可以说他是一种弱平衡二叉树
- 所以,相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,我们就用红黑树。
- 最后,附上红黑树的定义:
- 每个结点或是红的,或是黑的
- 根节点是黑的
- 每个叶结点是黑的
- 如果一个结点是红的,则它的两个儿子都是黑的
- 可以有两个连在一起的黑色节点,不可以有两个连在一起的红色节点
- 对每个结点,从该结点到其子孙节点的所有路径上包含相同数目的黑结点
- 自平衡操作:变色,左旋,右旋

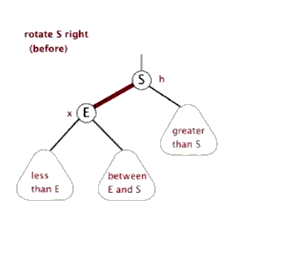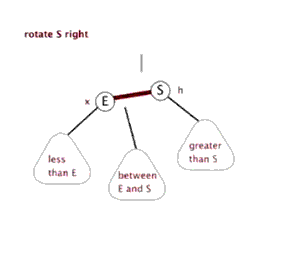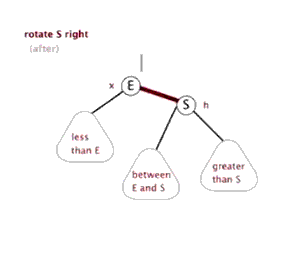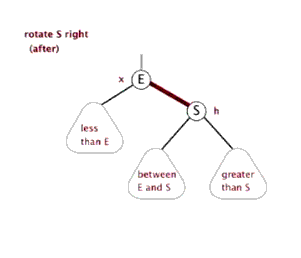
- 左旋
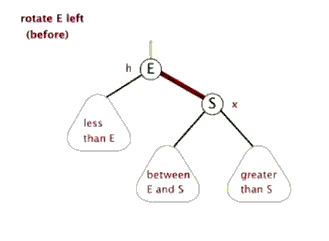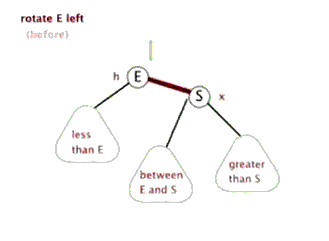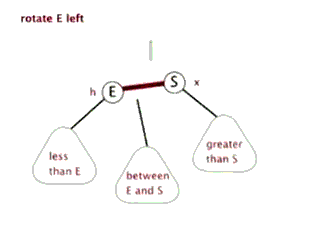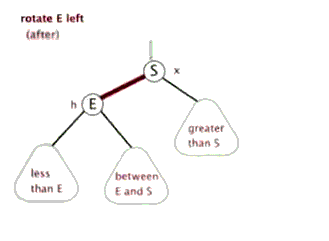
- 右旋
二、哈希表的put方法
- 这里要先声明一下,哈希表是在put() 方法的时候进行初始化的。
- 三种情况:a. 正常插入 b. 插入第一个元素 c. 插入之后需要扩容
- 判断是否有重复的值,如果有重复的值就替换,并返回之前的值
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}

三、哈希表的扩容(resize())
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1;
}
else if (oldThr > 0)
newCap = oldThr;
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
newCap = oldThr;
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}

四、如何把哈希表变成线程安全的
- 将其中的方法都加上synchronized关键字。(Hashtable)
- Collections.synchronizedMap给Hashmap包装一下。
eg:使用Map map = Collections.synchronizedMap(new HashMap()); - 使用ConcurrentHashMap,这个源码还没看明白,等看明白了再写吧
























 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









