









1. 前言
在上周的项目优化中,涉及到项目提速的问题。其中通过打日志计算时间的方法,发现了项目中有很大一部分时间消耗在javabean集合的填充上,由于集合的填充之间并不存在彼此的一个相关性,所以可以通过将串行转为并行的方式来进行一个优化。
通过异步线程可以方便的进行并行的操作,由于在工程中我们大量的采用了lamda表达式,因而直接通过stream操作提供的并行运算即可以在最大限度的保留原始工程架构的前提下完成项目的优化。
下面我们就来进行stream的并行操作的介绍。
2. 如何使用并行流
有两种方式可以使用并行stream:
* 直接通过Collection.parallelStream来构建。
* 通过BaseStream.parallel来构建。
//以下方式就是直接通过Collection.parallelStream来进行构建的
double average = roster
.parallelStream()
.filter(p -> p.getGender() == Person.Sex.MALE)
.mapToInt(Person::getAge)
.average()
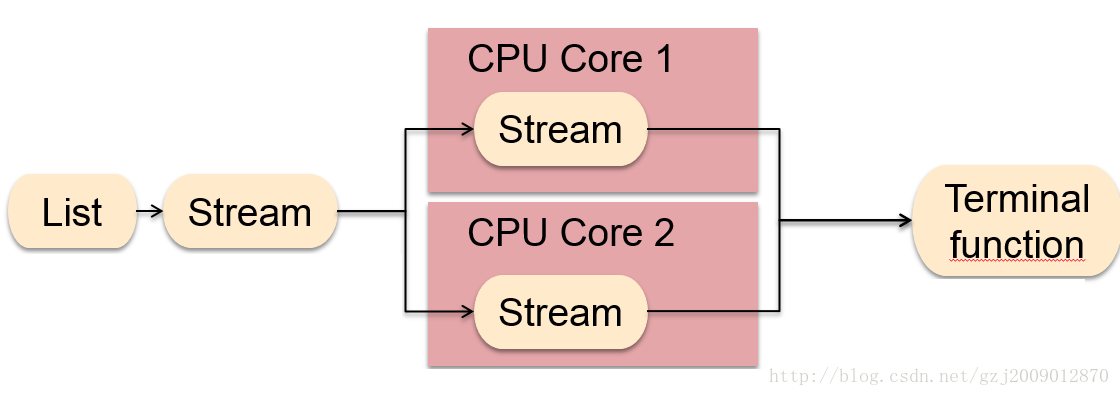
.getAsDouble();parallel stream 的示意图如下所示,很好理解:
3. 并发reduction
当使用并发流的时候,在进行reduction的时候应采用以下的方式:
ConcurrentMap<Person.Sex, List<Person>> byGender = roster
.parallelStream()
.collect(Collectors.groupingByConcurrent(Person::getGender));通过该方式等价于:
ConcurrentMap<Person.Sex, List<Person>> byGender = roster
.parallelStream()
.collect(Collectors.groupingByConcurrent(Person::getGender));通过concurrent reduction得到的map为ConcurrentMap,同时在处理parallel stream时的效率更高。
4. 顺序
由与parallel stream采用的是异步的方式,所以对于流的操作结果的顺序是不确定的。比如以下实验所示:
Integer[] array = new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9};
List<Integer> nums = new ArrayList<Integer>(Arrays.asList(array));
for (int i = 0; i < 5; i++) {
nums.parallelStream().forEach(e -> System.out.print(e + " "));
System.out.println("");
}输出如下:
3 6 4 2 8 7 1 5 9
3 8 2 9 4 7 6 1 5
3 8 7 9 4 6 1 2 5
3 8 4 9 2 7 1 6 5
3 8 2 9 6 4 7 1 5 如果希望结果的顺序和构建stream时的一致,只需要如下:
nums.parallelStream().forEachOrdered(e -> System.out.print(e + " "));通过该种方式,我们就能得到正确顺序的输出。如果我们细看forEachOrdered的话,会发现其api中写道:
Performs an action for each element of this stream, in the encounter order of the stream if the stream has a defined encounter order.
其中,encounter order指的就是流提供它的元素的顺序,比如数组的encounter order是它的元素的排序顺序,List是它的迭代顺序(iteration order),对于HashSet,它本身就没有encounter order。
5. ForkJoinPool
stream的parallel是如何实现的呢?同我们常用的异步线程池一样,并行流操作也是通过线程池来进行的,只不过与我们经常使用的ThreadPoolExecutor不一样的是,其拥有这更加好的特性。
ThreadPoolExecutor是1.5引入的,而ForkJoinPool是1.7新引入的工具。ForkJoinPool与之前传统的线程池最大的不同便是采用了“分治法”(Divide-and-Conquer Algorithm)的思想,因而适用“于一个应用能被分解成多个子任务,并且组合多个子任务的结果就能够获得最终的答案”的场景。
ForkJoinPool使用的工作窃取的方式能够在最大方式上充分利用CPU的资源,一般流程是fork分解,join结合。本质是将一个任务分解成多个子任务,每个子任务用单独的线程去处理。
在文章深入浅出parallelStream举了一个通俗易懂的例子来解释ForkJoinPool通过分治算法来解决大规模的问题时的优势:
要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。而使用ForkJoinPool时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
stream的并行流底端便是采用的ForkJoinPool进行操作的实现。于是我们知道,如果我们想修改并行操作线程的数量等参数,便需要通过修改ForkJoinPool进行实现。
不过Java 8为ForkJoinPool添加了一个通用线程池,这个线程池用来处理那些没有被显式提交到任何线程池的任务。它是ForkJoinPool类型上的一个静态元素,它拥有的默认线程数量等于运行计算机上的处理器数量。当调用Arrays类上添加的新方法时,自动并行化就会发生。比如用来排序一个数组的并行快速排序,用来对一个数组中的元素进行并行遍历。自动并行化也被运用在Java 8新添加的Stream API中。
于是我们在通过parallel stream进行操作时,实际是将任务提交到了这个通用线程池中进行操作。于是我们可以通过设置系统属性:
-Djava.util.concurrent.ForkJoinPool.common.parallelism=N 来调整ForkJoinPool的线程数量。
不过还有一种方式是通过创建一个ForkJoinPool来显式的进行任务的提交6:
ForkJoinPool forkJoinPool = new ForkJoinPool(2);
forkJoinPool.submit(() ->
//parallel task here, for example
IntStream.range(1, 1_000_000).parallel().filter(PrimesPrint::isPrime).collect(toList())
).get();8. 参考
站在巨人的肩膀上,我们才能看的更高。感谢以下作者的贡献:
parallelism javadoc文档 1
深入浅出parallelStream 2
Parallel stream processing in Java 8 – performance of sequential vs. parallel stream processing 3
Java Stream 详解 4
Java 并发编程笔记:如何使用 ForkJoinPool 以及原理 5
Custom thread pool in Java 8 parallel stream6















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









