






Basic Concepts in Machine Learning
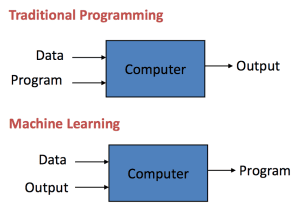
What is Machine Learning?
Machine learning is a subset of artificial intelligence that involves training algorithms to learn from data and make predictions or decisions without explicit programming. It enables computers to analyze patterns and make intelligent decisions based on the learned patterns.
❝"Machine learning is like having a personal chef who can magically turn your raw data into a gourmet meal of valuable insights. Just sit back, relax, and let the algorithms do the cooking!"
❞
Applications of Machine Learning
-
Image and Speech Recognition: Machine learning algorithms enable accurate identification and classification of images and speech. Applications include facial recognition systems, object detection, voice assistants, and automatic speech recognition. -
Natural Language Processing (NLP): Machine learning helps computers understand and interpret human language. It is used in language translation, sentiment analysis, chatbots, and text generation. -
Recommendation Systems: Machine learning algorithms analyze user preferences and behavior to provide personalized recommendations. This is seen in recommendation engines used by streaming platforms, e-commerce websites, and social media platforms. -
Fraud Detection: Machine learning algorithms can detect patterns and anomalies in large datasets to identify fraudulent activities in areas such as credit card transactions, insurance claims, and cybersecurity. -
Healthcare: Machine learning plays a vital role in medical image analysis, disease diagnosis, drug discovery, and personalized medicine. It helps in early detection of diseases, treatment planning, and predicting patient outcomes. -
Autonomous Vehicles: Machine learning algorithms enable self-driving cars to perceive their surroundings, make real-time decisions, and navigate safely on roads. -
Financial Services: Machine learning is used for credit scoring, risk assessment, algorithmic trading, fraud detection, and customer relationship management in the financial industry. -
Manufacturing and Supply Chain: Machine learning helps optimize production processes, predict equipment failures, and optimize inventory management to improve efficiency and reduce costs. -
Energy and Utilities: Machine learning algorithms analyze energy consumption patterns, predict demand, optimize energy distribution, and improve energy efficiency. -
Agriculture: Machine learning is utilized for crop yield prediction, disease detection in plants, precision agriculture, and optimizing resource allocation for improved farming practices.
Key Elements of Machine Learning
-
==Data==: Data is the 「foundation」 of machine learning. It comprises the input that the algorithm learns from and the output it aims to predict or classify. 「High-quality, relevant, and representative data」 is crucial for training accurate and reliable machine learning models. -
==Features==: Features are the measurable characteristics or attributes extracted from the data that are used as 「input」 for the machine learning algorithm. Selecting appropriate features is important as they directly impact the model's performance and ability to capture relevant patterns. -
==Algorithms==: Machine learning algorithms are mathematical models or computational procedures that process input data to generate desired outputs. There are various types of algorithms, such as decision trees, neural networks, support vector machines, and clustering algorithms, each suited for different tasks and data types. -
==Training==: Training is the process of feeding the machine learning algorithm with labeled or unlabeled data to learn patterns and relationships. During training, the algorithm adjusts its internal parameters based on the provided data to optimize its performance. -
==Evaluation==: After training, the machine learning model needs to be evaluated to assess its performance and generalization ability. Evaluation metrics such as accuracy, precision, recall, and F1 score are used to measure how well the model predicts or classifies new, unseen data. -
==Validation and Testing==: Validation and testing are essential steps to ensure the model's reliability and effectiveness. Validation involves tuning the model's hyperparameters and assessing its performance on a separate validation dataset. Testing involves evaluating the model's performance on a completely new and independent test dataset to estimate its real-world performance. -
==Iteration and Improvement==: Machine learning is an iterative process. The model is refined through multiple iterations by adjusting algorithms, features, or data to improve its performance. Feedback from evaluation and testing helps identify areas for improvement and guides the iterative refinement process.
Types of Learning
-
「Supervised Learning」: In supervised learning, the algorithm is trained on a ==labeled== dataset where both input data and corresponding output labels are provided. The goal is to 「learn a mapping function that can predict the correct output for new, unseen inputs」. Examples include image classification, sentiment analysis, and spam detection. -
「Unsupervised Learning」: In unsupervised learning, the algorithm is trained on an ==unlabeled== dataset without any specific output labels. 「The goal is to discover patterns, relationships, or hidden structures in the data.」 It can be used for tasks like clustering, anomaly detection, and dimensionality reduction. -
「Semi-Supervised Learning」: Semi-supervised learning is a 「combination」 of supervised and unsupervised learning. It involves training a model using a small amount of labeled data and a larger amount of unlabeled data. 「The labeled data helps guide the learning process, while the unlabeled data aids in discovering additional patterns or improving generalization.」 -
「Reinforcement Learning」: Reinforcement learning involves training an agent to 「make sequential decisions in an environment to maximize a reward signal」. The agent learns through trial and error, receiving feedback in the form of rewards or penalties based on its actions. It is commonly used in applications like game playing, robotics, and autonomous systems. -
「Transfer Learning」: Transfer learning is a technique where 「knowledge or representations learned from one task or domain are applied to another related task or domain」. It allows models to leverage pre-trained features or knowledge from one task to improve performance on another task, especially when labeled data is limited. -
「Online Learning」: Online learning, also known as incremental or streaming learning, is a learning approach where the model is 「continuously updated as new data arrives in a sequential manner」. It is suitable for scenarios where data is dynamically changing or arriving in streams, such as online advertising, fraud detection, and recommendation systems.
==Supervised learning== is the most mature, the most studied and the type of learning used by most machine learning algorithms. Learning with supervision is much easier than learning without supervision.
Inductive Learning is where we are given examples of a function in the form of data (x) and the output of the function (f(x)). The goal of inductive learning is to learn the function for new data (x).
-
「Classification」: when the function being learned is discrete. -
「Regression」: when the function being learned is continuous. -
「Probability Estimation」: when the output of the function is a probability.
Inductive Learning
This is the general theory behind supervised learning.
❝归纳学习就像是从具体的例子中找出规律。想象一下,你有一堆水果,有苹果、橙子、香蕉等等,每个水果都有特定的颜色、形状和大小。通过观察这些水果,你可以归纳出一些规律,例如苹果通常是红色或绿色,圆形或略带扁形,而香蕉则是黄色,弯曲的形状等等。这些规律就是你通过归纳学习得出的。接下来,当你看到一个你从未见过的水果时,比如一个红色、圆形的水果,你可以根据之前的归纳学习得出的规律猜测它可能是苹果。归纳学习的目的就是通过观察具体例子,找到一般规律,然后应用这些规律来预测未知的情况。
❞
Here are a few practical examples to illustrate the concept of induction:
-
Animal Classification: Suppose you have been given a dataset with labeled examples of different animals along with their features such as number of legs, habitat, and diet. By observing these specific instances, you can induce general rules or patterns to classify animals into categories like mammals, birds, reptiles, and so on. For example, if you observe that animals with feathers and beaks tend to fly, you can generalize that birds are a category of animals that can fly. -
Spam Filtering: In the context of email spam filtering, you can use induction to identify patterns in the characteristics of spam emails. By analyzing a large set of labeled examples, you can infer common features such as specific keywords, suspicious sender domains, or email formatting that are indicative of spam. These observed patterns can then be used to generalize and predict whether new, unseen emails are likely to be spam or not. -
Medical Diagnosis: In the field of medicine, induction can be applied to diagnose diseases based on symptoms and patient data. By analyzing historical patient records and their corresponding diagnoses, you can induce patterns and relationships between symptoms and diseases. For example, if you observe that patients with fever, cough, and shortness of breath often have pneumonia, you can generalize this pattern and predict the likelihood of pneumonia in a new patient with similar symptoms. -
Stock Market Prediction: In financial markets, induction can be used to analyze historical stock price data and identify patterns that indicate potential future trends. By observing specific instances of price movements, volume patterns, and other market indicators, you can induce rules or models that capture the underlying patterns. These models can then be used to predict future stock price movements and make investment decisions.
Key issues in machine learning
-
Data Quality: Machine learning models heavily rely on the quality of the data used for training. Issues such as missing values, outliers, imbalanced datasets, or noisy data can negatively impact the performance and accuracy of the models. Data preprocessing techniques and careful data collection strategies are necessary to address these challenges. -
Overfitting and Underfitting: Overfitting occurs when a model becomes too complex and starts to memorize the training data, resulting in poor performance on new, unseen data. Underfitting, on the other hand, happens when a model is too simple and fails to capture the underlying patterns in the data. Balancing model complexity and generalization is crucial to mitigate these issues. -
Bias and Fairness: Machine learning models can inherit biases from the data they are trained on, leading to discriminatory outcomes or unfair decisions. It is important to address bias in both the data and the algorithms to ensure fairness and avoid perpetuating societal biases and inequalities. -
Interpretability and Explainability: Many machine learning models, such as deep neural networks, are often considered "black boxes" because they lack transparency in how they arrive at their predictions. Interpreting and explaining the decisions made by these models is a significant challenge, especially in high-stakes applications like healthcare and finance. -
Scalability and Efficiency: As datasets grow larger and more complex, machine learning algorithms need to scale and process the data efficiently. Developing algorithms that can handle big data, parallel processing, and distributed computing is essential to address scalability and efficiency issues. -
Privacy and Security: Machine learning models often require access to sensitive data, raising concerns about privacy and security. Protecting data privacy, ensuring secure model deployment, and preventing adversarial attacks are important considerations in machine learning. -
Ethical and Legal Implications: Machine learning brings about ethical and legal challenges, such as the potential for automation bias, unintended consequences, or legal and regulatory compliance. Ethical guidelines and frameworks need to be developed to ensure responsible and accountable use of machine learning technologies.
Key Takeaways
-
Machine Learning Definition: Machine learning is a branch of artificial intelligence that focuses on developing algorithms and models that enable computers to learn from and make predictions or decisions based on data. -
Supervised Learning: Supervised learning is a type of machine learning where the algorithm learns from labeled training data, consisting of input features and their corresponding output labels, to make predictions or classifications on new, unseen data. -
Unsupervised Learning: Unsupervised learning involves learning from unlabeled data to discover underlying patterns or structures without specific output labels. It is used for tasks such as clustering, anomaly detection, and dimensionality reduction. -
Training and Testing Data: Machine learning models require a dataset divided into training and testing subsets. The training data is used to train the model, while the testing data is used to evaluate its performance and generalization. -
Feature Engineering: Feature engineering involves selecting, transforming, and creating relevant features from the raw data to improve the performance of machine learning models. It requires domain knowledge and understanding of the problem at hand. -
Model Evaluation: Model evaluation is the process of assessing the performance of a machine learning model. Common evaluation metrics include accuracy, precision, recall, F1 score, and area under the ROC curve (AUC-ROC). -
Overfitting and Underfitting: Overfitting occurs when a model becomes too complex and fits the training data too closely, resulting in poor performance on new data. Underfitting happens when a model is too simple and fails to capture the underlying patterns. Balancing these issues is crucial for good model performance. -
Bias-Variance Tradeoff: The bias-variance tradeoff refers to the relationship between a model's ability to fit the training data (low bias) and its ability to generalize to new data (low variance). Finding the right balance is essential to prevent underfitting or overfitting. -
Cross-Validation: Cross-validation is a technique used to assess the performance of a model by splitting the data into multiple subsets and iteratively training and evaluating the model on different subsets. It helps estimate the model's generalization performance. -
Hyperparameter Tuning: Hyperparameters are configuration settings that are not learned from the data but are set prior to training a model. Hyperparameter tuning involves selecting the optimal values for these parameters to improve the model's performance.
Basic Interview Questions
What is machine learning, and how does it differ from traditional programming?
Machine learning is a branch of artificial intelligence that focuses on developing algorithms and models that allow computers to learn and make predictions or decisions based on data. Unlike traditional programming, where explicit instructions are provided to solve a specific task, in machine learning, the algorithms learn from data to discover patterns and make predictions without being explicitly programmed for every possible scenario.
What are the main types of machine learning algorithms?
-
Supervised Learning: Algorithms learn from labeled training data to make predictions or classifications on new, unseen data. -
Unsupervised Learning: Algorithms learn from unlabeled data to discover patterns or structures without specific output labels. -
Semi-supervised Learning: Algorithms learn from a combination of labeled and unlabeled data. -
Reinforcement Learning: Algorithms learn through interactions with an environment, receiving feedback in the form of rewards or penalties.
What is the difference between supervised and unsupervised learning?
In supervised learning, the algorithm learns from labeled training data, where each data point is associated with a specific output label. The goal is to learn a mapping function that can predict output labels for new, unseen data. In unsupervised learning, the algorithm learns from unlabeled data, searching for patterns or structures without specific output labels. The goal is to discover hidden relationships or groupings in the data.
What is the purpose of training and testing data sets in machine learning?
The purpose of training and testing data sets in machine learning is to evaluate the performance and generalization ability of a model. The training data set is used to train the model by adjusting its internal parameters to minimize the prediction errors. The testing data set is then used to assess how well the model performs on new, unseen data.
By using separate data sets for training and testing, it helps to evaluate the model's ability to generalize and make accurate predictions on data it hasn't seen before. This helps in estimating the model's performance in real-world scenarios and prevents overfitting, where the model memorizes the training data but fails to generalize well.
Explain the concepts of overfitting and underfitting in machine learning.
Overfitting occurs when a machine learning model performs well on the training data but fails to generalize to new, unseen data. It happens when the model becomes overly complex and captures noise or random variations in the training data instead of the underlying patterns. Underfitting, on the other hand, occurs when a model is too simple and fails to capture the underlying patterns in the data, resulting in poor performance on both training and testing data. Balancing model complexity and generalization is important to avoid overfitting and underfitting.
What is the bias-variance tradeoff, and why is it important in machine learning?
The bias-variance tradeoff is a key concept in machine learning. Bias refers to the error introduced by approximating a real-world problem with a simplified model. High bias leads to underfitting. Variance refers to the model's sensitivity to fluctuations in the training data. High variance leads to overfitting. The goal is to find the right balance between bias and variance to achieve good model performance on new, unseen data.
What is cross-validation, and why is it used?
Cross-validation is a technique used to assess the performance of a machine learning model. It involves splitting the available data into multiple subsets or "folds." The model is trained on a combination of these folds and tested on the remaining fold. This process is repeated multiple times, each time with a different fold held out for testing. Cross-validation helps estimate the model's generalization performance, evaluate its stability, and avoid issues like overfitting.
What are hyperparameters in machine learning, and how do they affect the model?
Hyperparameters are configuration settings that are 「set prior to」 training a machine learning model and are not learned from the data. Examples include the learning rate, number of hidden layers in a neural network, or the regularization parameter. Hyperparameters control the behavior and complexity of the model. Selecting appropriate hyperparameter values is crucial as they directly affect the model's performance, training time, and generalization ability. Hyperparameter tuning is the process of finding the optimal combination of hyperparameters to achieve the best model performance.
What evaluation metrics can be used to assess the performance of a machine learning model?
-
Accuracy: It measures the proportion of correct predictions made by the model over the total number of predictions. -
Precision: It quantifies the proportion of true positive predictions out of all positive predictions, indicating the model's ability to avoid false positives. -
Recall (Sensitivity or True Positive Rate): It calculates the proportion of true positive predictions out of all actual positive instances, representing the model's ability to identify all relevant instances. -
F1 Score: It combines precision and recall into a single metric, providing a balance between the two. It is the harmonic mean of precision and recall. -
Area Under the ROC Curve (AUC-ROC): It evaluates the model's ability to discriminate between positive and negative instances by plotting the true positive rate against the false positive rate. -
Mean Squared Error (MSE): It measures the average squared difference between the predicted and actual values, commonly used for regression problems. -
Mean Absolute Error (MAE): It measures the average absolute difference between the predicted and actual values, also used for regression problems. -
R-squared (Coefficient of Determination): It quantifies the proportion of the variance in the target variable that can be explained by the model.
Explain the concept of feature engineering and its importance in machine learning.
Feature engineering refers to the process of selecting, transforming, and creating relevant features from the raw data to improve the performance of a machine learning model. It involves extracting meaningful information from the input data that can help the model learn and make accurate predictions. Feature engineering can include tasks such as removing irrelevant features, scaling or normalizing the data, handling missing values, encoding categorical variables, creating interaction or polynomial features, and more.
Feature engineering is important because the quality and relevance of features have a significant impact on the model's performance. Well-engineered features can capture the underlying patterns and relationships in the data, leading to improved model accuracy. Effective feature engineering requires domain knowledge, understanding of the problem at hand, and iterative experimentation to find the most informative features.
本文由 mdnice 多平台发布















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









