






支撑点选择算法及其并行化研究
背景
题目是关于支撑点选取算法的。为了应对数据多样化的挑战,常用的方法是将多种不同类型的数据抽象成一个统一的通用数据类型。这里用到了一个概念是大数据泛构:以度量空间作为该通用类型。度量空间定义为一个二元组(S,d),S是数据集合,而d是距离函数,定义如下:
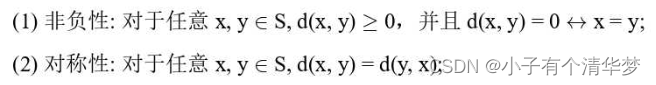
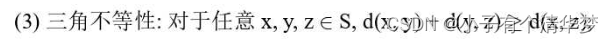
在相似性搜索的时候,可以利用上述性质进行一些搜索的优化,比如下图:
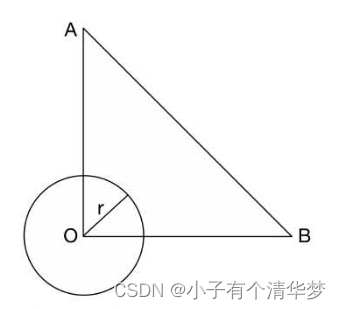
①如果|AB-AO|>r 因为|AB-AO|<OB 所以可以推出OB>r,就是说OB不在搜索范围内
②如果AB+AO<r 因为AB+AO>OB 所以可以推出OB<r,就是说OB在范围内
上述两种情况可以不计算OB距离就判断B是否在搜索范围内,大大加速了检索速度。利用用户自定义的距离函数和三角不等式的性质去掉无关的数据。
在这次的实验中,距离度量函数是切比雪夫距离的和
1.1 支撑点选择算法
①最远优先遍历算法(FFT)
FFT算法:可以用来筛选出评价集。但是FFT会先选出边界上的点,再去中间均匀抽样,这样往往取得的不是最优解。
特点①一开始不会选出性能最优的支撑点。如果想选出稍微偏离拐角的最优点,FFT要选出更多的点,时间复杂度退化到O(N2)。

②RFT算法(recent farthest traversal)
近期最远遍历
主要思想:如果在选择下一个点的时候,只以近期被选出的几个点作为基准,就可能可以避免选出内部数据的情况。
时间复杂度O(kn),空间复杂度O(n).因为要给每个数据维护一个队列,这个队列大小固定,通常为1或者2.
队列的大小固定设置为recentsize;不保存数据到点集的距离,直接将当前距离dis入队,不管是不是最小值。由于队列是先进先出的,队列中就保持了近期的recentsize个值。
有研究表明,recentsize=1或者2的时候RFT选出的支撑点只分布在拐角和周边,而且相近的点可以同时被选出,期望加快选出性能最优的支撑点。
③Incremental算法
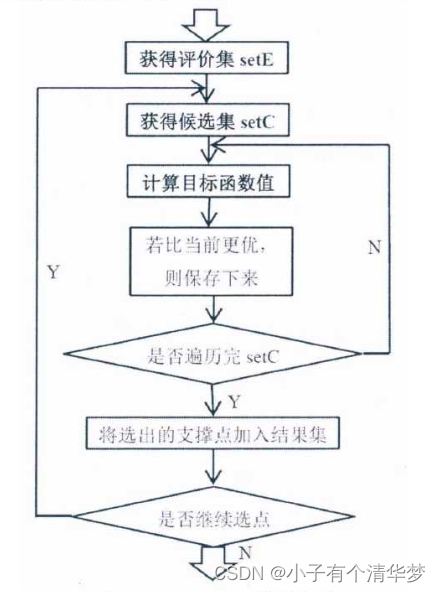
虽然FFT算法选点的优异性和命中率显著低于RFT,但他对空间的均匀抽样效果是很好的。我们基于PSS算法框架下,以RFT构建候选集,FFT作为评价集。
流程:一般先以FFT或者RFT选出的点作为候选集,因为不是最优的。然后用其他办法选出最优的。 Incremental算法是贪心的,但不一定是全局最优的。因为每次都以目标函数值为标准选出两个支撑点组合。
④PSS算法

这样的算法最坏时间复杂度特别高,是O(Cnk * Cn2 * p)
原始的暴力枚举
复杂度是O(Cnk * kn * Cn2 * k)
1.2 暴力枚举的并行化设计
因为内层的操作都是在确定了某个支撑点的组合上进行的,我们可以将最外层的Cnk个支撑点组合均匀分开,每个分块在一个核上运行。假设有p个内核,每个分块就分到了Cnk/p个组合。特殊情况:如果一个分块不够分了,将其单独作为一个分块一个分块对应一个子进程。
由于Cnm的组合数据量太大了,不可能用数组来存储。如何让每个核只执行自己的分块呢?
一个直接的想法是:每个子进程都从0号分块开始,只跑自己的上下界,其他的直接放空不执行。但效率很低,后面的进程跑空的很多。这样负载均衡很低。
该问题可以归结为:如何给定一个数字(在0到Cnm-1之间的数),找到对应的支撑点组合?
————————————————————待更
串行代码解读
注意递归的时候可以用临时变量存储,减少递归次数,尽量不要多次出现同个递归。
遍历每个点对求切比雪夫距离的时候,可以只算下三角,减少一半的计算次数。
SumDistance就是做了一个求L的过程:转换成距离向量,求两两节点间的切比雪夫距离,累加返回L。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









