






关注并星标
从此不迷路
计算机视觉研究院



公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
机器人越来越像人了!谷歌等的这项研究将现实世界的信息通过传感器纳入多模态语言模型,不但能执行机器人任务,还具有视觉问答、文本补全等功能。
转自《机器之心》
一直以来,人们都想拥有一款能听懂吩咐的机器人,比如「请帮我热一下午餐」,「请把遥控器帮我拿过来」。这些指令听上去简单,但一旦让机器人去做,失误率还是很高的。
在这一过程中,机器人需要克服很多困难,比如理解指令、分解任务、规划路线、识别物体等等,涉及到的能力跨语言、视觉等多个模态。
为了让机器人更加擅长这些任务,不少研究者都在尝试将大型语言模型与机器人结合起来,让大模型充当机器人的「大脑」,从而更出色地完成各项任务。这是「具身智能」领域一个比较热门的研究方向。
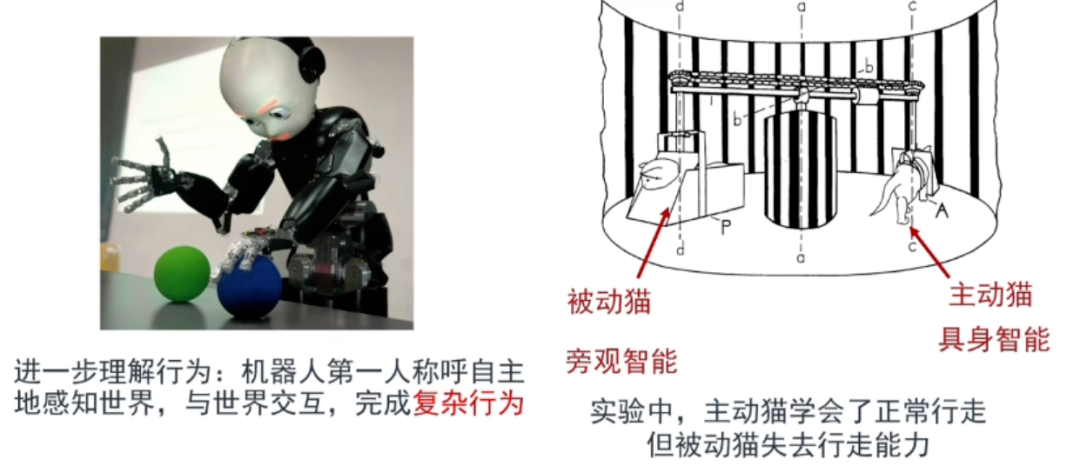
具身智能是具有身体体验的智能,是第一人称(而非第三人称)视角的智能。图源:卢策吾演讲 PPT,参见文末《为什么说具身智能是通往 AGI 值得探索的方向?上海交大教授卢策吾深度解读》。
在过去的一年中,我们已经看到了谷歌的 SayCan、UC 伯克利的 LM Nav 等多项工作。前者能够让机器人在大型语言模型的帮助下,完成一个包含 16 个步骤的长任务;后者则用三个大模型(视觉导航模型 ViNG、大型语言模型 GPT-3、视觉语言模型 CLIP)教会了机器人在不看地图的情况下按照语言指令到达目的地。

单独使用大型语言模型或者将视觉、语言、视觉 - 语言模型组合起来使用似乎都给机器人提供了很大的帮助,那如果直接训练一个更大的、单一的大型多模态模型呢?
最近,谷歌在这一方向上投入了大量资源,推出了一个参数量达 5620 亿的具身多模态语言模型 —— PaLM-E。具体来说, PaLM-E-562B 集成了参数量 540B 的 PaLM 和参数量 22B 的视觉 Transformer(ViT),是目前已知的最大的视觉 - 语言模型。
Vit 和 PaLM 融合的视频
在实验中,这个模型在很多任务中都表现出了强大的能力。
比如,在机器人任务中,它可以帮你从抽屉里拿东西,然后走过去递给你。在这一过程中,它既要听懂你的语言指令,还要会识别指定物体并规划任务步骤。
抽屉里拿东西
接下来,研究人员让机器人完成一个颜色归类任务,但给出的输入不限于语言指令,还掺杂了视觉信息。

结果显示,有 PaLM-E 加持的机器人确实会排列积木,把相同的颜色块放到一起:
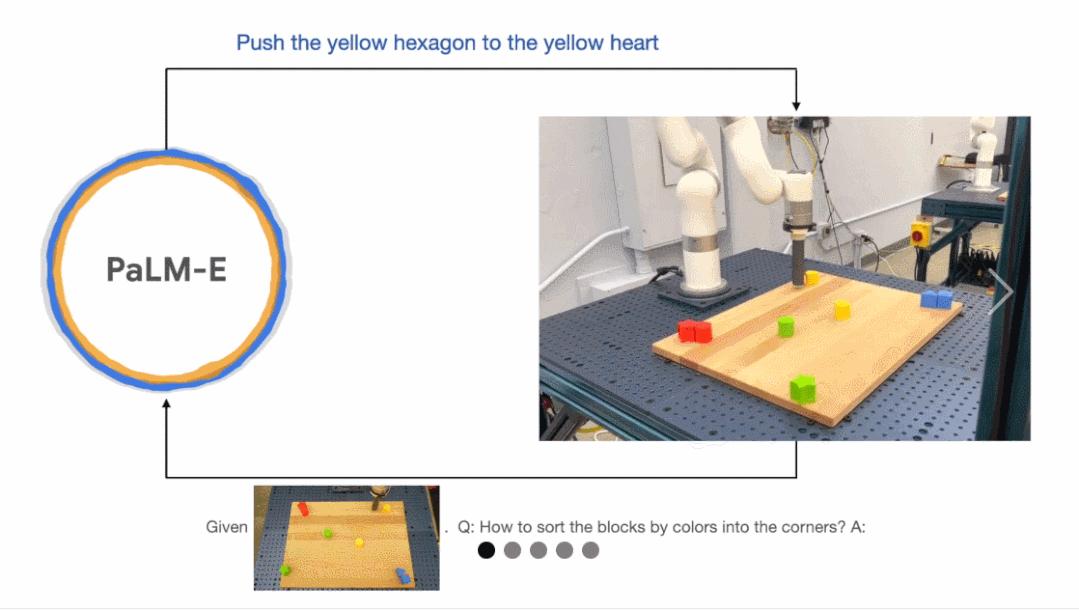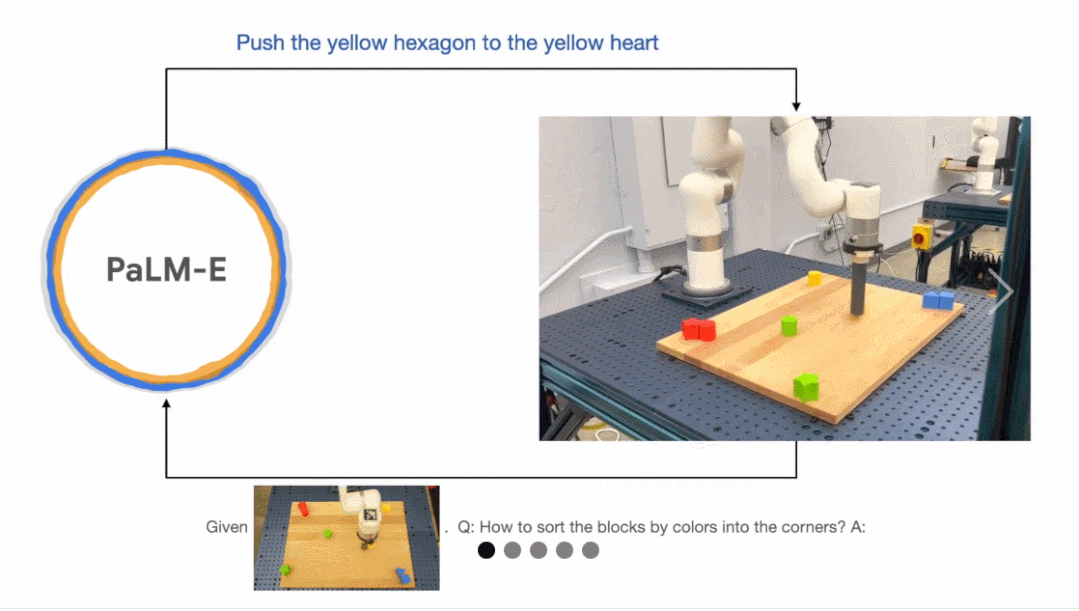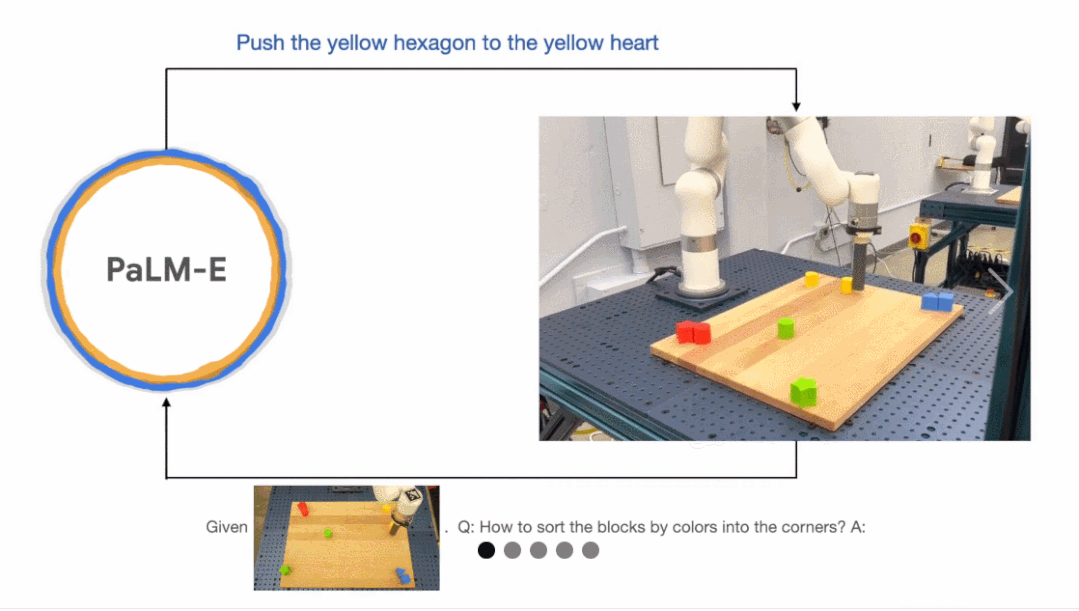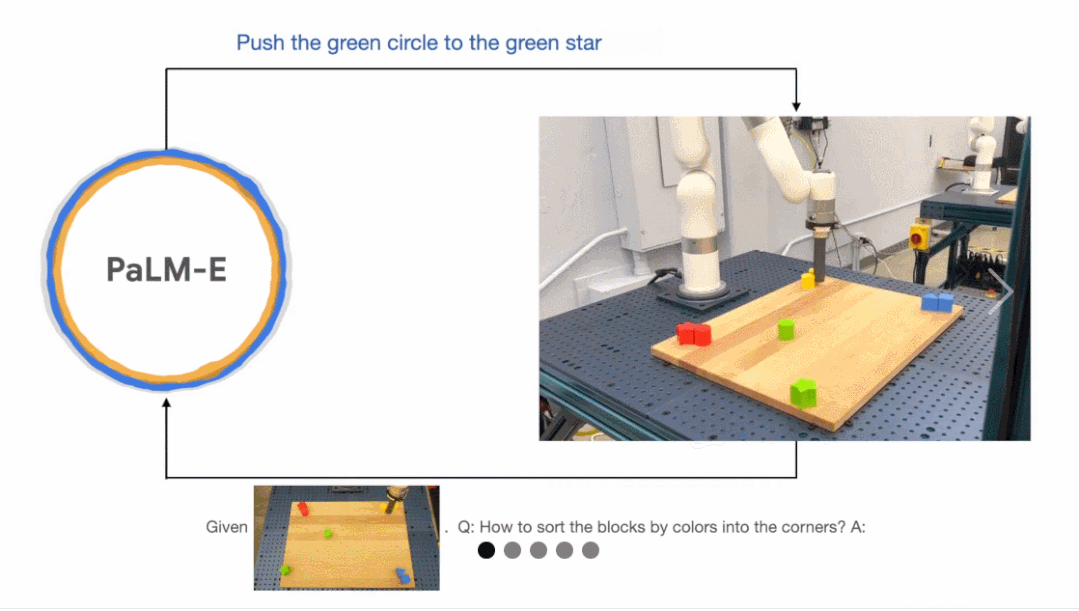
你还能命令 PaLM-E 将红色积木推到咖啡杯旁边而不会出错:

除了解锁机器人相关任务外,PaLM-E 还是一个合格的视觉 - 语言或纯语言模型,具有视觉问答、文本补全等功能。

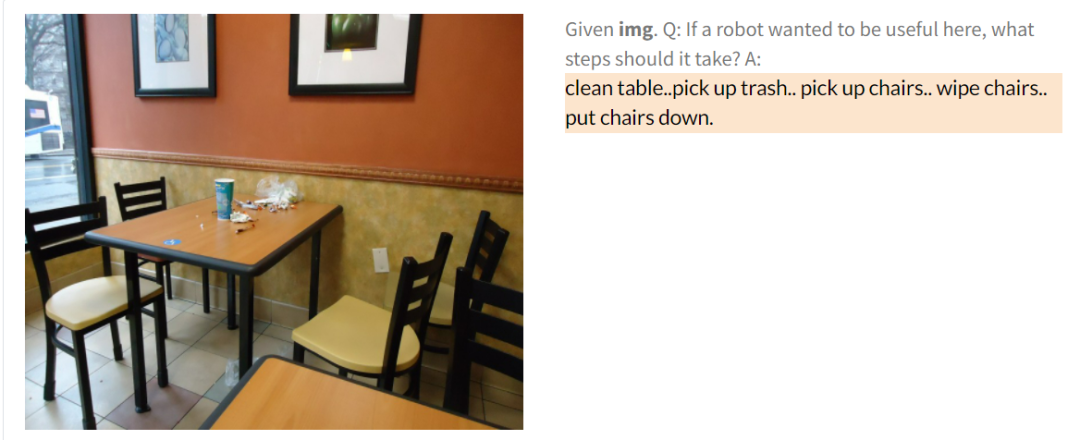
如下图,给定一张图像,并向 PaLM-E 提问:「如果一个机器人想在这里发挥作用,它应该采取哪些步骤?」PaLM-E 给出的回答是:首先清理桌子,清理垃圾,然后挪动椅子,擦椅子,最后把椅子放回原处。PaLM-E 的回答看起来很符合逻辑。
除了谷歌之外,微软最近似乎也在探索大模型与机器人的结合。前段时间,他们发表了一篇论文,探讨如何将 ChatGPT 的功能扩展到机器人领域,从而让我们用语言直观控制如机械臂、无人机、家庭辅助机器人等多个平台。

正如上海交大教授卢策吾所说,早在 1950 年,图灵就在他的论文中首次提出了具身智能的概念,在之后的几十年里,大家都觉得这是一个很重要的概念,但具身智能并没有取得很大的进展,因为当时的技术还不足以支撑其发展。到了今天,多学科的技术已经改变了这一局面,可以让我们去研究具身智能的一些本质问题。
接下来,我们将详细介绍 PaLM-E 这篇论文。
论文概览
首先我们先来了解一下背景,才能更好的理解本文。
众所周知,大型语言模型(LLM)在各个领域表现出强大的推理能力,包括对话、逐步推理、解决数学问题、代码编写等方面。然而,这种模型在现实世界中又面临推理性能不好的短板,即虽然 LLM 是在大型数据集上训练而成,可以生成与物理世界相关的表示,但将这些表示与现实世界中的视觉和物理传感器连接起来时又存在很多困难。
2022 年 Ahn 等人在 SayCan 的论文中提出将 LLM 的输出与学习到的机器人策略相结合以做出决策,但其局限性在于 LLM 本身仅提供文本输入,对图像输入还没有涉及,这对于许多任务来说是不够的。此外,当前 SOTA 视觉语言模型是在典型的视觉语言任务(如视觉问答(VQA))上训练而成,不能直接用来解决机器人推理任务。
谷歌推出的具身语言模型 PaLM-E 可以很好地解决上述问题,它可以将连续的传感器数据直接整合到语言模型里,从而使得语言模型能够做出更有根据的推理。值得一提的是,他们之所以将此模型命名为 PaLM-E,是因为本文使用了 2022 年谷歌发布的 PaLM 作为预训练语言模型。
PaLM-E-562B 在 OK-VQA 基准上实现了 SOTA 性能,而不依赖特定于任务的微调。除此以外,PaLM-E-562B 在其他任务上也表现良好,包括零样本多模态思维链 (CoT) 推理、少样本提示、OCR-free 数学推理和多图像推理等。

论文地址:https://palm-e.github.io/assets/palm-e.pdf
论文主页:https://palm-e.github.io/
方法概览
至于实现过程,总结而言,PaLM-E 的架构思想是将连续的具身观察结果(例如图像、状态估计或其他传感器模态)注入到预训练语言模型的语言嵌入空间中。PaLM-E 将连续信息以类似于语言 token 的方式注入到语言模型中。它不是那种常见的编码器 - 解码器架构模型,而是一种只具有解码器的 LLM。
具体到输入上,PaLM-E 的输入包括文本和(多个)连续观察。与这些观察相对应的多模态 token 与文本交错形成多模态句子。例如多模态句子 Q(给出一个提问):What happened between <img_1> and <img_2> ? 其中 < img_i > 表示图像的嵌入。PaLM-E 的输出是由模型自回归生成的文本,可以是问题的答案,也可以是 PaLM-E 以文本形式生成的应该由机器人执行的一系列决策。

在论文第 3 章,作者详细介绍了他们使用的方法。
有人猜测,这项工作可能是受到「红色代码」影响而做出的成果?三个月前谷歌拉响「红色代码」警报,以应对 ChatGPT 带来的威胁。不过这也只是一种猜测,总归,谷歌是将传感器数据给整合到语言模型里了。

实验结果
该研究进行了大量的实验。首先是模型的迁移能力:下图表明,在不同任务和数据集上训练完成 PaLM-E 显著优于那些在单独任务上训练的模型。
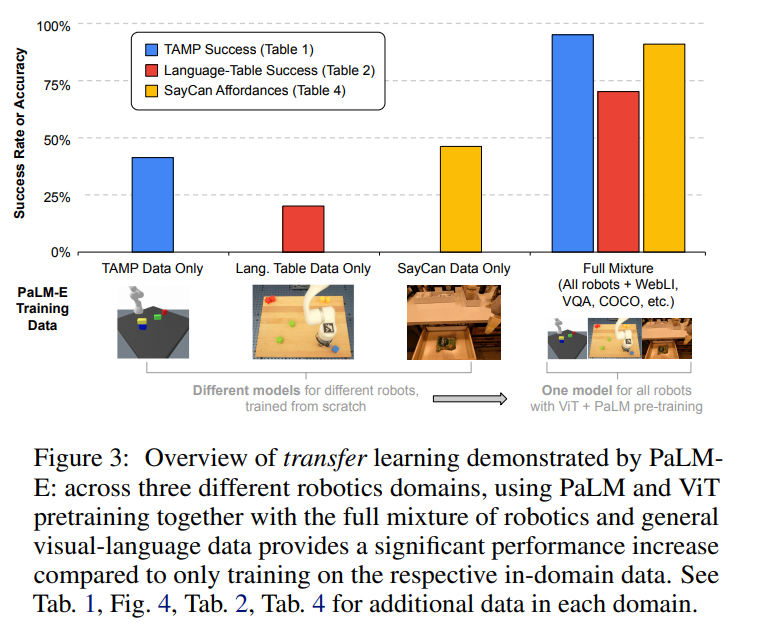
图 4 表明,LLM 在 full mixture 训练模式下,比其他训练模式性能提高了一倍以上。
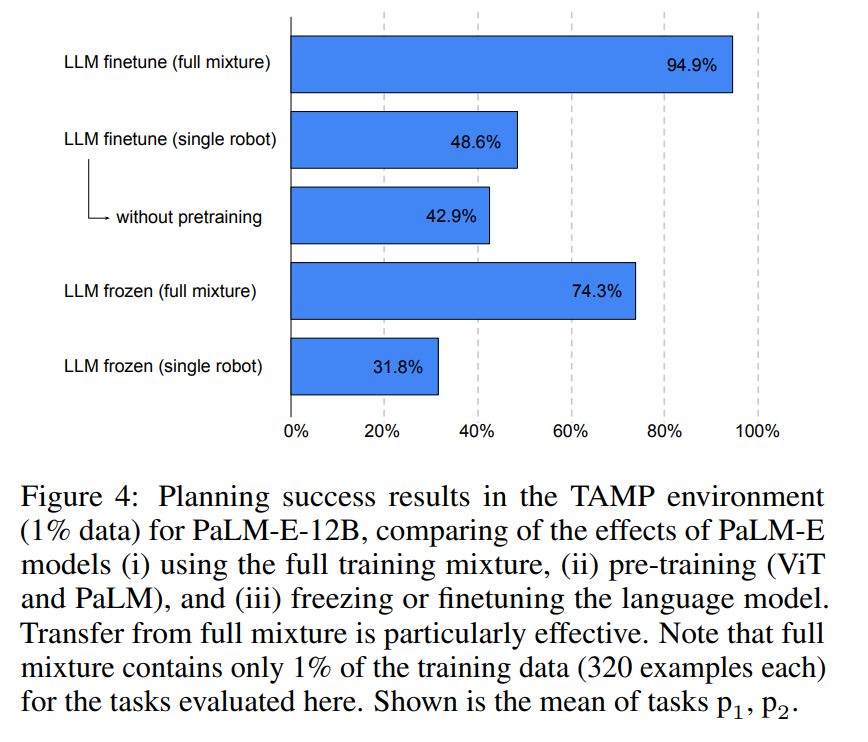
表 9 显示了不同模型在移动操作环境下对故障检测的能力,评价标准为精度和召回:

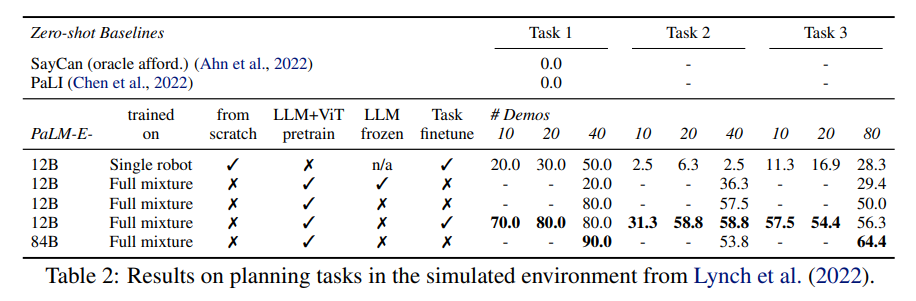
同样的,下表 2 为模型在模拟环境中对规划任务的结果
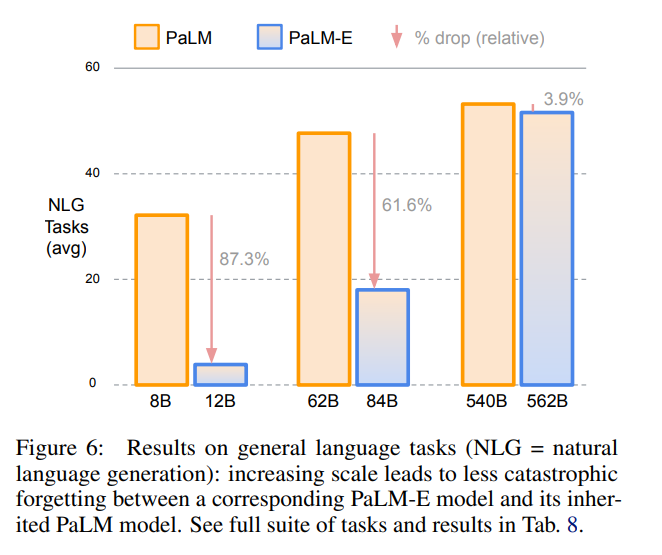
该研究还展示了模型在语言方面的能力,当对整个模型进行端到端训练时,随着模型规模的增加,模型保留了更多的原始语言性能(图 6)。
© The Ending
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
🔗















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









