






LlamaFactory 前言
LLaMA Factory 是一个用于微调大型语言模型的强大工具,特别是针对 LLaMA 系列模型。
可以适应不同的模型架构和大小。
支持多种微调技术,如全参数微调、LoRA( Low-Rank Adaptation )、QLoRA( Quantized LoRA )等。
还给我们提供了简单实用的命令行接口。
支持多 cpu 训练,多任务微调,还有各种内存优化技术,如梯度检查点、梯度累积等。
支持混合精度训练,提高训练效率。
本文不再赘述 LlamaFactory 的安装过程
LlamaFactory参数基本设置
打开我们 LlamaFactory 的 web 运行界面,进入根目录执行下列命令:
llamafactory-cli webui
看到下列界面

在浏览器打开我们开启的 webui 界面 http://127.0.0.1:7860:
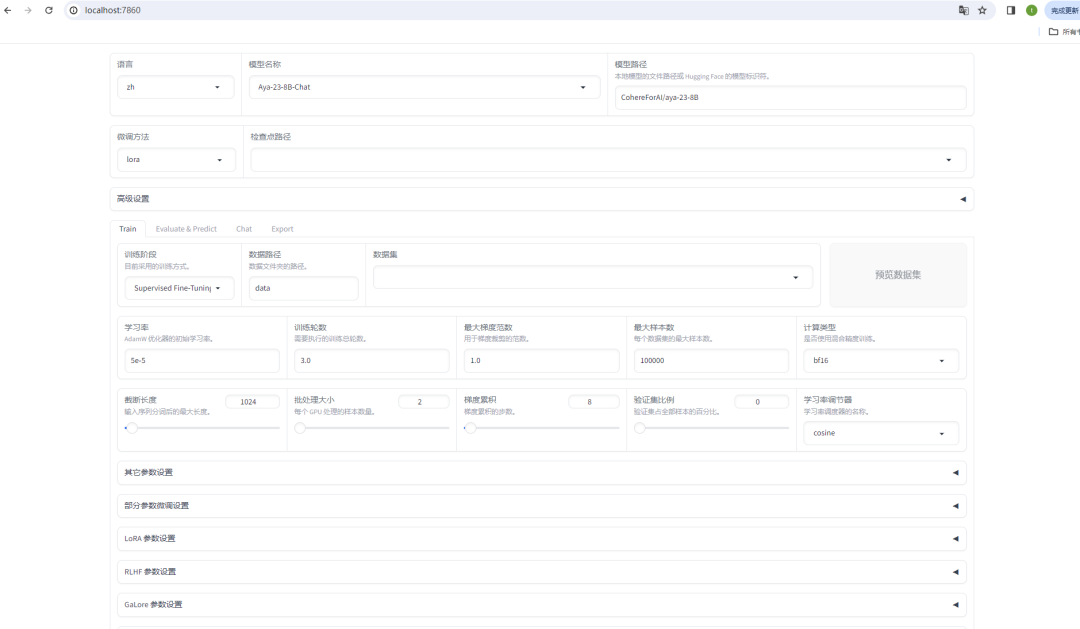
我们依次来解释每个参数的选择:
这里是语言选择
选择 zh 即可。
模型选择选择适合自己的模型,这里都会从 Hugging Face 里面下载,

这一步是自定义路径一般就用选择好的默认路径即可。

微调方法:
这里有三种,full全参数微调, Freeze(冻结部分参数) LoRA(Low-Rank Adaptation),还有 QLoRA 等。
全参数微调可以最大的模型适应性,可以全面调整模型以适应新任务。通常能达到最佳性能。
Freeze 训练速度比全参数微调快,会降低计算资源需求。
LoRA :显著减少了可训练参数数量,降低内存需求,训练速度快,计算效率高。还可以为不同任务保存多个小型适配器,减少了过拟合风险。
QLoRA训练速度跟 LoRA 差不多,基本保持了 LoRa 的优势,会进一步减少内存使用。
综合速度,灵活性考虑 选择 LoRA 或者 QLorRA 。
检查点路径:
检查点是模型训练过程中的一个快照,保存了模型的权重、优化器状态等信息。
主要用于保存训练进度允许从中断点恢复训练,性能评估等。
LlamaFactory参数高级设置
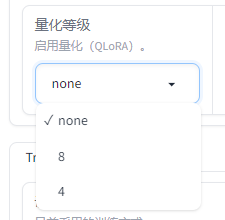
量化等级
量化等级有8位量化( INT8)和4位量化( INT4 ),QLoRA 它允许在使用低位量化(如4位)的同时,通过 LoRA 方法进行高效的微调。
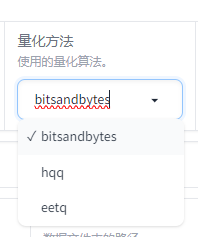
量化方法
bitsandbytes 与 hqq:
Bitsandbytes:内存效率高,可以显著减少 GPU 内存使用
Hqq: 提供更多的量化选项和更细粒度的控制,使用可能稍微复杂一些,需要更多的配置。
提示模板
就是构建结构化输入的一种方式,好的提示模板可以显著提高模型的性能和适用性,为了适应不同的需求,我们要自定义模板。
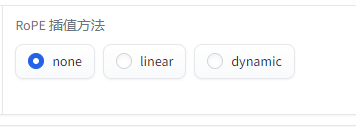
RoPE 插值方法:
线性插值和动态 NTK 缩放,线性插值简单直观,动态 NTK 缩放更灵活,可以适应不同长度的输入。
加速方式
auto,unsloth,flashattn2。
auto自动模式会根据你的硬件配置和当前的训练任务自动选择最适合的加速技术。这是最简单的一种方式,不需要用户进行任何额外配置。
FlashAttention2 是一种优化的注意力机制,旨在加速 Transformer 模型的训练。它通过优化内存访问和计算流程来提高训练速度。
Unsloth 是一种特定的优化技术,用于减少训练过程中的计算冗余和内存占用,从而加快训练速度。
图像输入对于多模态模型的训练,要结合图像和文本数据进行训练和推理。
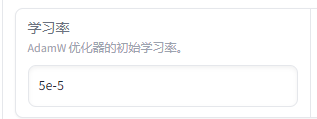
学习率
AdamW的学习率通常在1e-5 到 3e-5之间,于大型语言模型(如 BERT、GPT 等)的微调,常用的学习率范围是 2e-5 到5e-5,从一个相对较小的值开始,如 2e-5 。
如果训练不稳定或损失波动很大,可以尝试降低学习率,如果训练进展太慢,可以尝试略微增加学习率。
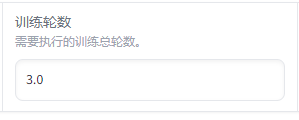
**训练轮数:**对于大语言模型的微调,通常在 2 到 10 个 epoch 之间, 轮数过多可能导致过拟合,特别是在小数据集上。
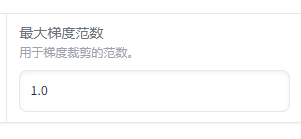
最大梯度范数
(Max Gradient Norm)是一种用于防止梯度爆炸的技术,也称为梯度裁剪(Gradient Clipping)。这个参数设置了梯度的最大允许值,如果梯度超过这个值,就会被缩放到这个最大值。
通常在 0.1 到 10 之间,太小:可能会限制模型学习,太大:可能无法有效防止梯度爆炸。
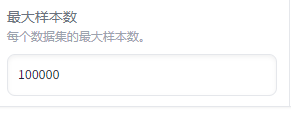
最大样本数
它决定了每个数据集中使用多少样本进行训练‘’
如果原始数据集很大,设置一个合理的最大样本数可以减少训练时间,如果计算资源有限,较小的样本数可以加快训练速度。
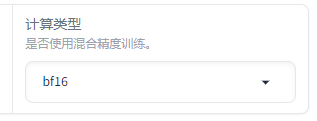
计算类型
有 bf16 fp16 fp32 purebf16,如果你的硬件支持 bfloat16,且你希望最大化内存效率和计算速度,可以选择 bf16 或 purebf16。
如果你的硬件支持 fp16,你希望加速训练过程且能够接受较低的数值精度,可以选择 fp16。
如果你不确定你的硬件支持哪些类型,或你需要高精度计算,可以选择 fp32。
在这里插入图片描述
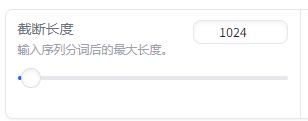
截断长度:
截断长度是指在处理输入序列时,模型所能接受的最大标记(token)数量。
如果输入序列超过了这个长度,多余的部分将被截断,以确保输入序列长度不会超出模型的处理能力。
对于文本分类任务,通常截断到 128 或 256 个标记可能就足够了;而对于更复杂的任务,如文本生成或翻译,可能需要更长的长度。
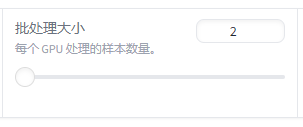
批处理大小:
批处理大小是指在每次迭代中输入到模型中的样本数量。
在深度学习训练过程中,数据通常会被分成多个批次(batch)进行处理,每个批次包含一组样本。
较大的批处理大小会占用更多的内存(显存)。
如果批处理大小过大,可能导致显存不足,训练无法进行。
合理的批处理大小可以提高计算效率,大批量的数据可以更有效地利用 GPU 进行并行计算。
梯度累计:
是一种有效的策略,用于在受限的 GPU 内存情况下模拟更大的批处理大小。
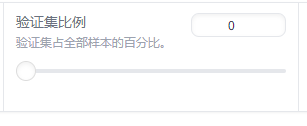
验证集比例:
是指在机器学习和深度学习模型训练过程中,从训练数据集中划分出来的一部分数据,用于评估模型的性能。
验证集的数据不参与模型的训练,仅用于在训练过程中监控模型的表现,以防止过拟合和调整模型的超参数,常见的比例有 10%、20% 等,具体选择取决于数据集的大小和具体的应用场景。
学习率调整:
训练过程中保持学习率不变。随着训练进行,逐步减小学习率。
每隔一定的训练轮数(epoch),将学习率按某个比例缩小。
在每个周期内,学习率呈现余弦函数形态变化。如 Adam 、Adagrad 、RMSprop 等,根据梯度变化动态调整学习率。 
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









