







首先如果不知道kmp是什么东西的点这里。
刚刚看了kmp,和大家分享下我的理解。
首先,推荐一篇博文,我是看了这篇博文醍醐灌顶的,尤其是那图,看图,配合算法代码,自己想,我觉得比读文字要舒服多了。点击打开链接。
以下为核心代码:
void kmpGetNext()
{
int i=0, j=-1;
b[i]=j;
while (i<m)
{
while (j>=0 && p[i]!=p[j]) j=b[j];
i++; j++;
b[i]=j;
}
}首先,求next数组的算法我觉得是一个递推的过程。
其中,i是一直在增加的,它是next[]数组的下标,从0到数组末,挨个求出next[i]. 这点应该比较清楚,不用想太多。
然后就是那个j ,我想我可以把它叫做已匹配的最长前缀的下标,是用来帮助i来找出next[i]的值的。j=next[i] 。先看下图:
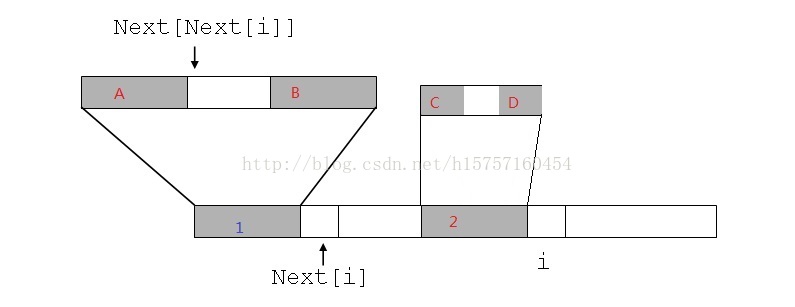
他就是让j不断通过 j=next[j] 这个赋值语句,不断往回找,有2种情况退出那个while循环,一种情况就是 p[i]==p[j],我们现在来假设一下这种情况,如上图,已知的是1和2两块区域是一样的,即 i 的next[i]是已经找到的,因为是个递推的过程,所以先如此假设之前的next已经找好了,不要纠结从1开始怎么找next[]。那么,如果p[i] == p[j] (j=next[i]),
也就是说1区域加上他后面那个字符 等于 2区域加上2区域后面的那个字符 ,也就是 next[i+1] =j+1(意义就是 p字符串中从0到 j 的位置 与 p字符串中间某一段开始到 i 是相等的)。
但是如果 p[i] 不等于 p[j] , j 就等于next[j],什么意思呢,就是把j再往前推一推,看看有没有 p[j]==p[i]. 如果等于,那么 next[i+1]=j+1。为什么呢,?看图,假设图中左上方那个next[next[i]] 就是我们找到的 j ,此时 p[j]==p[i],然后就能推出 next[i+1]=j+1. 这步如果不太明白,就再看图,区域1 和区域2是一样的,那么根据假设区域1中又能找到A和B是一样的,所以在区域2中也能找到C和D是一样的,且 A=B=C=D。那么好了,你看,A=D,又 A 后面一个字符 p[j] 等于 D后面一个字符 p[i] ,所以 next[i+1] =j+1。当然 如果在j往回推的时候,推到-1都还没有匹配到p[i]==p[j],也是符合情况的,那就是没找到嘛,那么p[i+1]=0,然后 j 又要从头开始找,找匹配的前缀,与后面的i去匹配。
再附上一段代码,这是又优化了一点的代码:
void get_nextval(char *T)
{
int i = 0, j = -1;
next[0] = -1;
while ( T[i] != '\0' )
{
if (j == -1 || T[i] == T[j])
{
++i; ++j;
if (T[i]!=T[j])
next[i] = j;
else
next[i] = next[j];
}
else
j = next[j];
}
}
如果不优化,if()中的语句应该是这么写:
if (j == -1 || T[i] == T[j])
{
++i; ++j;
next[i] = j;
}
因为如果 p[i] ==p[j] 且 p[i+1] == p[j+1] ,我们赋值next [i+1]=j+1。当kmp运算的时候,我们如果匹配到 p[i+1] 的时候 ,不一样,那么我们就会去找 p[next[i+1]] ,但是
p[next[i+1]]==p[j+1]==p[i+1] .我们是在p[i+1]不匹配的时候来找next数组的,可是找到的p[j+1]却是等于 p[i+1],那肯定也是不匹配的,所以这步是没必要的,我们还得继续
i=next[i],去匹配再前面一点的字符串。所以这个优化是指要在p[i+1] != p[j+1]的情况下才可以赋值 next [i+1]=j+1,不然就赋值next[i+1]=next[j+1] ,这点如果前面的都理解应该也
很好理解吧。 这个其实还是自己去比划比划比较清楚,我文字描述的我自己看起来都不舒服。。
哪里不对请多包涵。。。。。。














 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









