






介绍:
决策树算法属于有监督机器学习的一种,起源非常早,非常直观,现在更多是基于决策树的一些集成学习的算法。
决策树分为分类树和回归树。
特点:
1.可以处理非线性的问题
2.可解释性强,没有θ
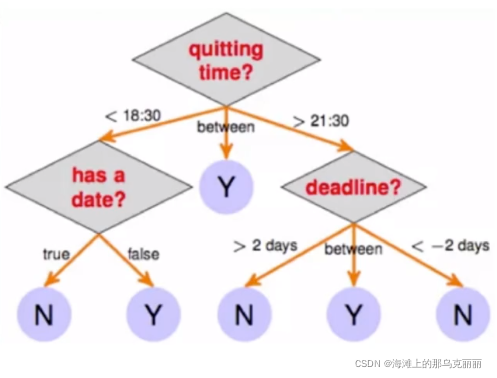
3.模型简单,预测效率高if else,if为真走左边,else走另一边。
4.决策树不太容易写出来函数表达式。
决策树模型生成和预测
模型生成:通过大量数据生成一颗非常好的树,用这棵树来预测新来的数据
预测:来一条新数据,按照生成好的树标准,落到某一个节点上。
决策树的数学表达形式
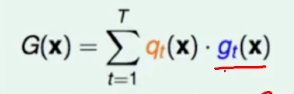
gt(x):某个x进入到树形结构,最终落到某个叶子节点,这个叶子节点所对应的数值就是gt(x),t代表叶子节点是第几个。
qt(x):要么是1,要么是0。对于落在那个叶子节点,那个叶子节点就是1,而其他叶子节点就是0。
求和得到G(x):不管是那个样本,都可以写成上式泛化的形式,不管是哪个样本,都可以给出所对应的结果,一棵树表达成路径和路径上的分值组成。
迭代的表达方式
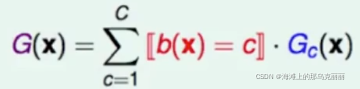
一棵大树是有多个子树组成。x进入子树,所对应子树的结果就是最终的结果。
Gc(x):代表某一棵子树
[b(x) = c]:要么是1,要么是0。
加和:把子树所对应的结果,去乘1或0。
分类树sklearn代码封装介绍
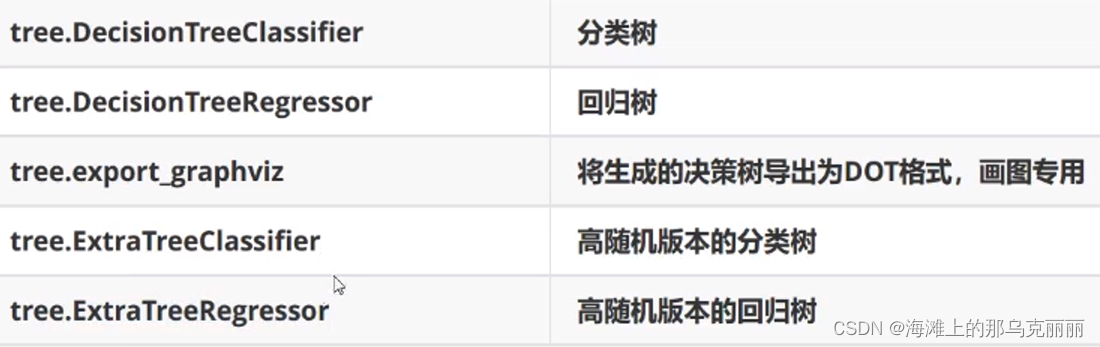
sklearn参数介绍
1.criterion:计算不纯度的方法。(不纯度越低代表分类效果越好)
参数:gini(基尼系数,sklearn默认方法),entropy(信息增益)
(1)数据维度很大的时候噪音很大时候用基尼系数。
(2)纬度低数据比较清晰的时候信息熵和基尼系数没有区别。
(3)当决策树拟合程度不够的时候,使用信息熵。通常两个都试一下
打印这颗决策树使用了哪些特征,以及特征的重要程度
print(clf.feature_importances_)

# 返回每个测试样本所在叶子结点的索引
clf.apply(X_test)
[20 10 19 4 4 19 6 10 19 17 13 4 4 13 11 13 13 20 20 13 8 20 4 20
20 19 20 20 19 13 13 6 13 20 10 16 20 20 13 20 4 7 4 11 13]
[*zip(wine.feature_names, clf.feature_importances_)]

2.random_state:如果不设置这个值,决策树会在所有特征中随机选取几个值,导致虽然用同样的数据训练,但最后得到的分数不同。可以设置一个随机种子,每次训练都会选择同样的特征。
dtc = DecisionTreeClassifier(criterion='entropy', random_state=30)
这个参数默认是None。
所以对一一些低维度数据集像鸢尾花数据集,采用决策树分类很少能感知有无random_state的区别,因为本身维度就少再怎么随机,结果还是同样的值。
splitter:best(默认),random
best默认的参数,选择特征重要性高的特征
random随机选择(能够防止过拟合)
clf = DecisionTreeClassifier(criterion='entropy', random_state=30, splitter='random')
3.剪枝参数(5个):决策树在训练集生长的过于茂盛,使得训练集表现很好,但他找出的规则必然包含了训练集的噪声。结果在测试集上表现一般。为了提高决策树的泛化能力,对其进行剪枝操作。
max_depth:限制树的深度,建议从3开始。
min_samples_leaf=5:限制每棵树的节点样本数量,如果这棵树样本数量少于设置的值,那么就剪枝这个节点。一般和max_depth搭配使用。
min_samples_split=5:如果叶子节点少于5个样本,那么这个叶子节点就不会在分下去,
max_features:直接限制特征的数量进行剪枝,超过设定个数的特征将会被舍弃。默认是特征总数开平方(如果特征特别多,我们一般会使用PCV等方法进行降维。)
min_imputrity_decrease:如果在计算信息增益的过程中,信息熵减小的低于设定的值,那么就不再分裂。
每次调参都要手动的话很麻烦,用循环输入参数值。类似于网格搜索。
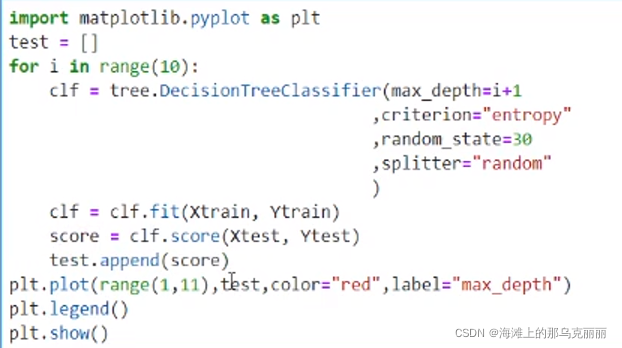
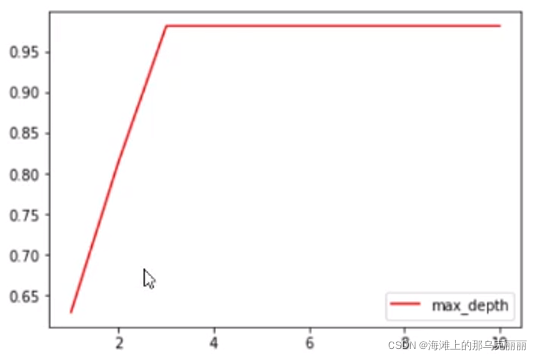
import pandas as pd
from sklearn.feature_extraction import DictVectorizer # 字典特征抽取
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
def descision():
"""
决策树对泰坦尼克号上面的人员预测生死
:return:
"""
# 获取数据
taitan = pd.read_csv('C:/Users/10509/Desktop/AI练习数据/titanic.csv')
# 选择特征和目标值
x = taitan[['pclass', 'age', 'sex']]
y = taitan['survived']
# 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# 分割训练集测试集
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 特征工程,当特征里面是类别的时候,需要做OneHot编码
dict = DictVectorizer(sparse=False)
X_train = dict.fit_transform(X_train.to_dict(orient="records"))
X_test = dict.transform(X_test.to_dict(orient="records"))
print(X_train)
# 用决策树进行预测
dec = DecisionTreeClassifier(max_depth=8)
dec.fit(X_train, y_train)
y_predict = dec.predict(X_test)
print("准确率是:", dec.score(X_test, y_test))
if __name__ == "__main__":
descision()
回归树sklearn代码封装介绍
回归树的参数和分类树是一样的
但是相对于分类树来说,回归树没有所谓的不纯度的概念,所以也不会有分类指标(基尼系数,信息增益)
1.criterion衡量分支质量的指标
mse:父节点和叶子节点之间的均方误差的差额被用来特征选择的标准。
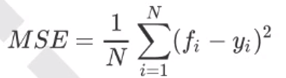
回归树接口score返回的是不是MSE。
这里说明一下u是残差平方和,v是总平方和。sklearn默认是,但是我们一般不会使用
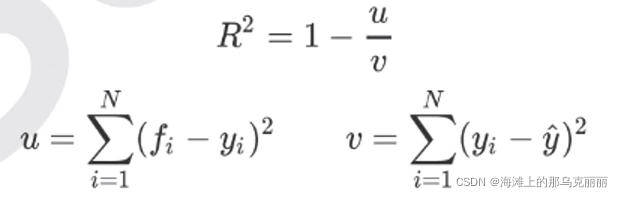
def reg():
boston = load_boston()
X = boston.data
y = boston.target
dtr = DecisionTreeRegressor(max_depth=6, random_state=10)
# scoring="neg_mean_squared_error" 相当于告诉交叉验证,请把负均方误差当作衡量指标来评估模型
score = cross_val_score(dtr, X, y, cv=5, scoring="neg_mean_squared_error")
print(score)
决策树
优点:
(1)理解简单,可视化性强
(2)不用做归一化处理,需要很少的数据准备
缺点:
(1)训练树的过程中给容易过拟合。
改进:
(1)剪枝
(2)使用随机森林
每个模型都有自己决策的上限,所以如果一个模型你如何调整都无法得到满意的分数时,就可以考虑换一个分类模型,对于月亮型的数据比较适合用knn近邻算法分类,换形状数据适合用knn和高斯,半月型适合用朴素贝叶斯,神经网络,随机森林。

















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









