









 本文介绍了两种常见的数据预处理方法:最大最小值归一化和标准归一化。最大最小值归一化易受离群值影响,可能导致数据集中在0-1范围内的一端。标准归一化则通过计算均值和标准差进行缩放,对离群值的敏感性较低,适合样本量大的情况。在实际应用中,应当根据数据特性选择合适的归一化方法,并确保训练集和测试集的标准化一致。代码示例展示了如何使用sklearn库实现这两种归一化操作。
本文介绍了两种常见的数据预处理方法:最大最小值归一化和标准归一化。最大最小值归一化易受离群值影响,可能导致数据集中在0-1范围内的一端。标准归一化则通过计算均值和标准差进行缩放,对离群值的敏感性较低,适合样本量大的情况。在实际应用中,应当根据数据特性选择合适的归一化方法,并确保训练集和测试集的标准化一致。代码示例展示了如何使用sklearn库实现这两种归一化操作。
最大值最小值归一化
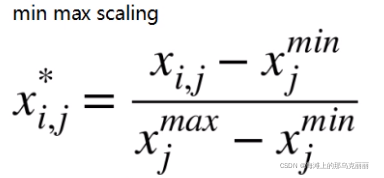
Xjmin是Xj所在列的最小值
Xjmax是Xj所在列的最大值
问题:
能做到归一化(0-1zhi之间),但是一旦数据中有一个离群值(特别大的值)就会出现这个离群值做完归一化后特别趋近于1,而其他值特别趋近于0。
异常值特别大的话那么最大值和最小值差距比较大。所以一般不会使用最大最小值归一化。
标准归一化
经过处理的数据符合标准正态分布即均值为0,标准差为1的标准正态分布。
Xmean:X所在列的均值
Standard Deviation:X所在列的标准差

标准差的公式会考虑到所有样本数据,所以受离群值影响会小一些。在样本足够多的情况下比较稳定。
但是如果使用标准归一化不一定会把数据缩放到0-1之间。
标准差是方差的开根号: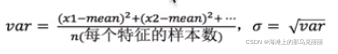
方差为0说明所有的特征都是平均值
方差很大说明所有特征都比较离散
如果样本都是正的,那么所有的的参数θ在调整的时候可能都朝着一个方向调整。
标准归一化可以是样本缩放的同时,也可以使样本有正有负,这样就可以让不同的
θ朝着不同方向调整直接到达最优解,减少迭代次数。
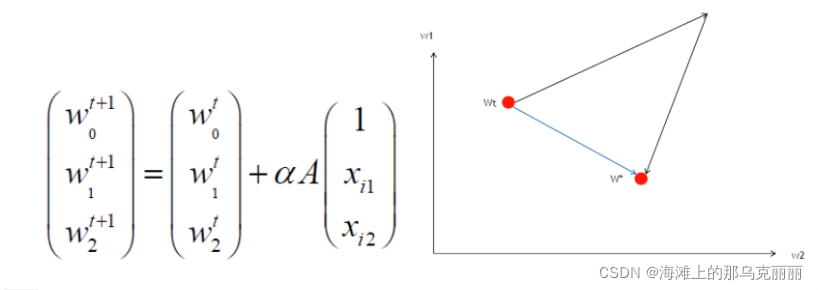
在用代码使用归一化的时候,测试集和训练集使用同一个scaler对象(持久化)训练,不过前提是测试集和训练集以及未来的新数据集是同分布的。
#基于sklearn代码实现最大最小值归一化
from sklearn.preprocessing import MinMaxScaler
# 数据归一化
def Maxminscale():
# feature_range指定2-3之间的范围
mm = MinMaxScaler(feature_range=(2, 3))
data = mm.fit_transform([[89, 79, 1, 14], [78, 111, 33, 754], [82, 234, 11, 23]])
print(data)结果缩放到2-3之间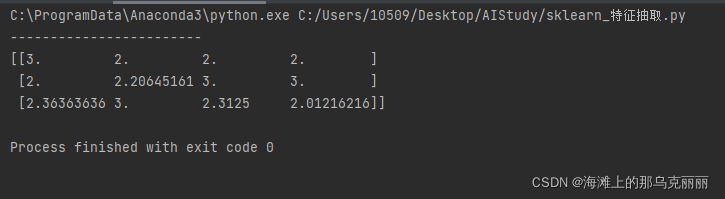
#基于sklearn代码实现标准归一化
from sklearn.preprocessing import StandardScaler
# 标准归一化
def standscaler():
ss = StandardScaler()
data = ss.fit_transform([[89, 79, 1, 14], [78, 111, 33, 754], [82, 234, 11, 23]])
print(data)标准差缩放后的结果


















 528
528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









