







位运算
& 位操作运算
- X & 1 == 1 :判断是否是奇数(偶数)
- X & = (X - 1) :将最低位(LSB)的 1 清零
- X & -X :得到最低位(LSB)的
- 1 X & ~X = 0
异或运算
- x ^ 0 = x
- x ^ x = 0
- x ^ 11111……1111 = ~x 取反
- x ^ (~x) = 11111……1111
- a ^ b = c => a ^ c = b => b ^ c = a (交换律)
- a ^ b ^ c = a ^ (b ^ c) = (a ^ b)^ c (结合律)
将特殊位置放 0 或 1
- x & ( ~0 << n ) : 将 x 最右边的 n 位清零
- (x >> n) & 1 :获取 x 的第 n 位值(0 或者 1),
- x & (1 << (n - 1)) :获取 x 的第 n 位的幂值,
- x | (1 << n) :仅将第 n 位置为 1,
- x & (~(1 << n)):仅将第 n 位置为 0,
- x & ((1 << n) - 1) : 将 x 最⾼位⾄第 n 位(含)清零,
- x & (~((1 << (n + 1)) - 1)):将第 n 位⾄第 0 位(含)清零。
bitmap位图
位图大多用于节省大量的内存空间,java里一个int占的是32个字节,但一个byte只需要1个字节,在做一些记忆化存储的时候特别香。最经典的例子莫过于在10亿个数字里找出不重复的数字。
一些备用的知识:
- ASCII值只有256个
- char可以直接等于数值来存储到bitmap里:int index = s.charAt(1)
通用模板
public class BitClass {
public static void main(String[] args) {
// 参考系都会有一个稳定的数量
int len = 1000000;
// 初始化bitmap的大小,一般len+1
byte[] bitmap = new byte[len + 1];
for(int i = 0;i<len;i++) {
// 如果该下标为1, 则直接处理最终的逻辑
if(byte[i] == 1) {
// return xx;
}
// 如果符合逻辑条件,则该下标为1
if(true) {
byte[i] = 1;
}
}
}
}
二分搜索
需要注意的三点:
- 循环退出条件,注意是 left <= right,⽽不是 left < right。
- mid 的取值,mid = left + (right-left)>>1 ,注意如果是 (left+right)>>1会有越界的可能。
- left 和 right 的更新。left = mid + 1,right = mid - 1。
通用模板
int search(int[] nums, int target, int left, int right) {
// 1、制定循环规则
while (left <= right) {
// 2、求左右区间的中间值
int mid = left + (right-left)>>1;
// 3、中间值是否为目标
if (target == nums[mid]){
return mid;
}
// 4、判断目标在哪一区间
if (target < nums[mid]) {
right = mid - 1;
} else {
left = mid + 1;
}
}
// 没有符合的值
return -1;
}
递归
「递」的意思是将问题拆解成子问题来解决, 子问题再拆解成子子问题,…,直到被拆解的子问题可以立即求出解便无需再次拆解。
「归」是说从最小的子问题开始解决,一直往上一层子问题开始倒退解决,…,直到最开始的问题解决。
下图以阶乘 f(6) 为例来看下它的「递」和「归」。
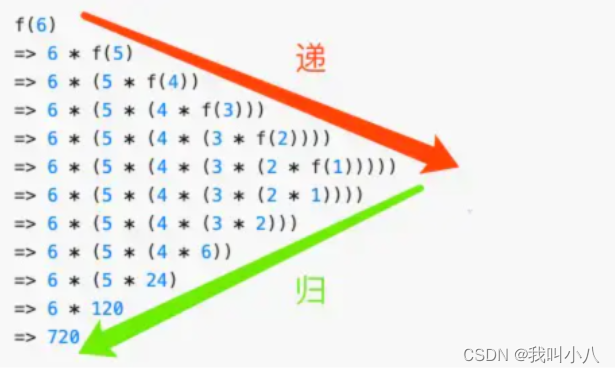
递归的注意点:
- 明确递归函数的功能,确定合不合适递归。
- 递归结束的条件,就是能直接得到“递”到最小问题的解的结束条件。
- 找出函数的等价关系式,或者说是除了最小问题的节点的与它下个节点的等价关系式,比如 f(n)=n * f(n-1)。
通用模板
public int recursionSearch(int n) {
// 最小问题的结束条件(可能有多个)
if (n == 1) {
return 1;
}
if (n == 2) {
return 2;
}
// 等价关系式
return n * recursionSearch(n-1);
}
动态规划
动态规划 = 递归 + 已算出解的记忆化存储,以最经典的斐波那契数列作为例子,它的公式为:
- f(0) = 0
- f(1) = 1
- f(n) = f(n-1) + f(n-2) n>1
如果我们以递归的方式去解决,举个节点为6的等价关系式f(6) = f(5) + f(4),那这时候我们就得分别计算 f(5)跟 f(4)的结果了,很明显计算下个节点的时候f(5) = f(4) + f(3),相当于计算了2次f(4),可想而知数量多了起来的话,这些重复计算的数量是成几何倍的速率增加的。
那如果我们在递归的过程中,对已经算过的解进行存储的话,那岂不是可以用少量的空间去替换大量的计算量,那怎么去计算跟存储呢?
反推即可,也就是我们从最小问题开始反推,比如f(2) = f(0) + f(1) ——> f(3) = f(1) + f(2) …,这样的话我们就可以把每个节点计算的结果都进行存储,直到计算到最开始的问题。
所以又可以简单地总结一下:动态规划 = 递归 + 已算出解的记忆化存储 = 反推 + 记忆化 ,他有三个关键点:
- 记忆化的存储方式。
- 最小问题的解的直接存储。
- 反推公式:dp[n] = func(dp[n-1],dp[n-2]…)
通用模板
public int dpSearch(int n) {
// 最小问题的可直接返回
if (n == 0) {
return 0;
}
if (n == 1) {
return 1;
}
// 记忆化的存储方式。
int[] dpArr = new int[n+1];
// 最小问题的解的直接存储。
dpArr[0] = 0;
dpArr[1] = 1;
// 开始反推,代入反推公式
for(int i=2;i<=n;i++) {
dpArr[i] = dpArr[i - 1] + dpArr[i - 2];
}
return dpArr[n];
}
BFS
广度优先搜索,理解它的搜索方式最重要。他是从第一层,一层层查到最后一层,如下图。
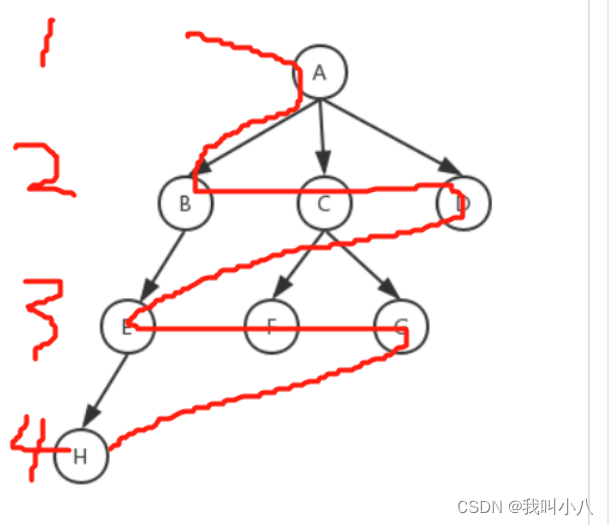
那么很明显,在遍历过程中,利用先入先出的队列性质,按照左到右的规则入队出队即可达到这种一层层的查找了。
拿上面的图示写个例子,假设我要寻找等于F的节点,则步骤为:
- 建立一个队列,把根节点加到队列里,队列用【】代表,红色代表出列,所以现在的状态为:【A】
- 把队列首元素A弹出,因为A不等于F,则把A的子节点BCD加到队列里:【A、B、C、D】
- 把队列首元素B弹出,因为B不等于F,则把B的子节点E加到队列里:【B、C、D、E】
- 把队列首元素C弹出,因为C不等于F,则把C的子节点FG加到队列里:【C、D、E、F、G】
- 把队列首元素D弹出,因为D不等于F,则把D的子节点(无就不加)加到队列里:【D、E、F、G】
- 把队列首元素E弹出,因为E不等于F,则把E的子节点H加到队列里:【E、F、G、H】
- 把队列首元素F弹出,因为F等于F,所以返回此节点。
通用模板
class Node {
public int value;
public List<Node> children;
}
public Node bfs(Node root, int target) {
// 1、根节点的判空
if (root == null) {
return null;
}
// 2、建立队列,并把根节点加进去
Queue<Node> queue = new LinkedList<>();
queue.add(root);
// 3、只要队列不为空便一直遍历
while (!queue.isEmpty()) {
// 4、弹出队列的首元素
Node node = queue.poll();
// 5、判断弹出的元素,也就是遍历到的元素是否是寻找目标,可直接结束寻找
if (node.value == target) {
return node;
}
// 6、如果不是,则把自己的子节点按顺序加到队列里
if (node.children != null) {
for(Node childNode: node.children){
if (childNode != null) {
queue.add(childNode);
}
}
}
}
return null;
}
DFS
深度优先搜索,理解它的搜索方式最重要,从树的根节点 开始,沿着一个分支一直查到底,然后从这个分支的叶节点回退到上一个节点,再从另一个分支开始走到底…,不断重复此过程,直到查到目标元素或者所有的节点都遍历完成。它的特点是不撞南墙不回头,先笔直查完一个分支,再换一个分支继续查,如下图:
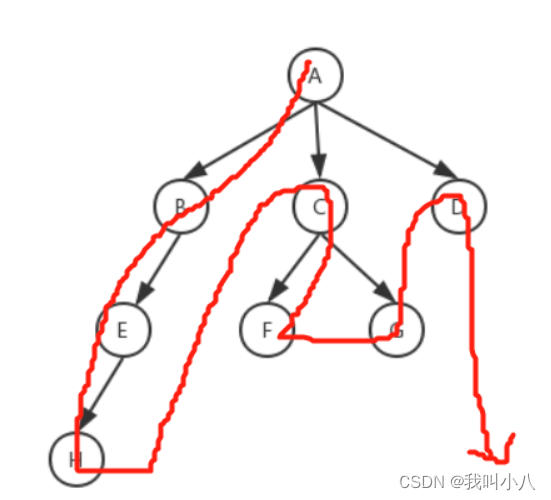
那么很明显,在遍历过程中,利用先入后出的栈性质,按照制定的规则入栈出栈即可达到这种深层式的查找了。
拿上面的图示写个例子,假设我要寻找等于F的节点,则步骤为:
- 建立一个栈,把根节点加到栈里,栈用【】代表,红色代表出栈,所以现在的状态为:【A】
- 把栈顶元素A弹出,因为A不等于F,则把A的子节点BCD加到栈里:【A、B、C、D】
- 把栈顶元素B弹出,因为B不等于F,则把B的子节点E加到栈里:【B、E、C、D】
- 把栈顶元素E弹出,因为E不等于F,则把E的子节点H加到栈里:【E、H、C、D】
- 把栈顶元素H弹出,因为H不等于F,则把H的子节点(无就不加)加到栈里:【H、C、D】
- 把栈顶元素C弹出,因为C不等于F,则把C的子节点FG加到栈里:【C、F、G、D】
- 把栈顶元素F弹出,因为F等于F,所以返回此节点。
注意的是,dfs也可以使用递归去实现的!递归的例子就不举了,在通用模板里写出。
通用模板
栈形式:
class Node {
public int value;
public List<Node> children;
}
public Node bfs(Node root, int target) {
// 1、根节点的判空
if (root == null) {
return null;
}
// 2、建立栈,并把根节点加进去
Stack<Node> stack = new Stack<>();
stack.push(root);
// 3、只要栈不为空便一直遍历
while (!stack.isEmpty()) {
// 4、弹出栈的首元素
Node node = stack.pop();
// 5、判断弹出的元素,也就是遍历到的元素是否是寻找目标,可直接结束寻找
if (node.value == target) {
return node;
}
// 6、如果不是,则把自己的子节点按倒序加到栈里
if (node.children != null) {
for(int i = node.children.size()-1; i>=0; i--){
Node childNode = node.children[i];
if (childNode != null) {
stack.push(node);
}
}
}
}
return null;
}
递归形式:
class Node {
public int value;
public List<Node> children;
}
public Node dfs(Node node, int target) {
// 1、当前节点的判空
if (root == null) {
return null;
}
// 2、判断当前节点是否与目标一致,直接返回
if (node.value == target) {
return node;
}
// 3、如果不是,则按顺序递归自己的子节点
if (node.children != null) {
for(Node childNode: node.children){
if (dfs(childNode, target) != null) {
return childNode;
}
}
}
return null;
}
滑动窗口
滑动窗口使用双指针解决问题,所以一般也叫双指针算法,因为两个指针间形成一个窗口,一般步骤为:
- 使用双指针中的左右指针技巧,初始化 left = right = 0,把索引闭区间 [left, right] 称为一个「窗口」。
- 先不断地增加 right 指针扩大到窗口初始化的大小。
- 根据需求,不断对left或者right去递增达到窗口移动的效果,进行逻辑处理。
- 直到 right 到达尽头。
滑动窗口本质是双指针的玩法,不同题目有不同的套路,从最简单的按照规律包夹,到快慢指针,再到无固定套路的因题而异的特殊算法。
其实按照规律包夹的套路属于碰撞指针范畴,一般对于排序好的数组,可以一步一步判断,或者用二分法判断,总之不用根据整体遍历来判断,效率自然高。
通用模板
class Solution {
public void windows(String s) {
// 初始化滑动窗口的左右指针
int left = 0;
int right = 0;
// 目标的长度
int len = s.length();
// 左右指针都要小于长度
while (left<len && right<len) {
// 如果当前的值没在窗口内,则处理相关逻辑,并且扩大窗口,右指针右移一位
if(true) {
// 处理相关逻辑
right++;
} else {
// 否则就缩小窗口,左指针右移一位
left++;
}
}
}
}
指针
通过设置多个指针进行移动来求出解,一般情况下都要求数组是有序的。
双指针的话,就是在left<right, right<arr.length的情况下,不断对left或right指针进行递增来处理逻辑,时间复杂度为O(n)。
三指针的话,相当于遍历第一个指针+双指针,也就是执行n次双指针来处理逻辑,时间复杂度为O(nn)。
以此类推,n指针的话,相当于执行n-2次双指针来处理逻辑,时间复杂度为O(nn(n-2次方))。
回溯与剪枝
● 回溯:一旦遇到不符合规则的节点,或者是已经到达最深处,则跳回上个节点继续遍历下种可能,比较拗口。
● 剪枝:跳过不符合规则的节点,不对它进行深度查询。
回溯与剪枝是相辅相成的,回溯的遍历方式就是DFS。下面举个例子来理解,给出三个数字123,然后求出所有组成2位数的个位十位不重复的结果。我们根据DFS的方式去遍历下图:
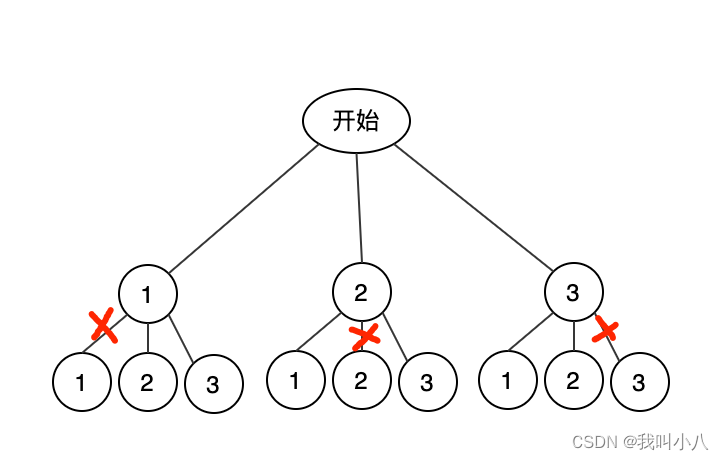
● 从1开始,记录下当前结果 [1],发现不是叶节点,则继续遍历子节点,遍历完毕,然后把当前结果删掉尾数变成[]
○ 遍历到1,发现当前结果存在1,则跳过。
○ 遍历到2,发现当前结果不存在2,记录下当前结果 [1,2],发现是叶节点,把当前结果加到全局结果中,然后把当前结果删掉尾数变成[1]
○ 遍历到3,发现当前结果不存在3,记录下当前结果 [1,3],发现是叶节点,把当前结果加到全局结果中,然后把当前结果删掉尾数变成[1]
● 从2开始,记录下当前结果 [2],发现不是叶节点,则继续遍历子节点,遍历完毕,然后把当前结果删掉尾数变成[]
○ 遍历到1,发现当前结果不存在1,记录下当前结果 [2,1],发现是叶节点,把当前结果加到全局结果中,然后把当前结果删掉尾数变成[2]
○ 遍历到2,发现当前结果存在2,则跳过。
○ 遍历到3,发现当前结果不存在3,记录下当前结果 [2,3],发现是叶节点,把当前结果加到全局结果中,然后把当前结果删掉尾数变成[2]
● 从3开始,记录下当前结果 [3],发现不是叶节点,则继续遍历子节点,遍历完毕,然后把当前结果删掉尾数变成[]
○ 遍历到1,发现当前结果不存在1,记录下当前结果 [3,1],发现是叶节点,把当前结果加到全局结果中,然后把当前结果删掉尾数变成[3]
○ 遍历到1,发现当前结果不存在2,记录下当前结果 [3,2],发现是叶节点,把当前结果加到全局结果中,然后把当前结果删掉尾数变成[3]
○ 遍历到2,发现当前结果存在3,则跳过。
堆
堆(heap)本质上就是一棵完全二叉树,它的每一个结点都必须大于等于或者小于等于其子节点。 通常,我们将结点都大于或者等于子树所有结点的堆称为最大堆 ;将结点都小于或者等于子树所有结点的堆称为最小堆 。
一般都是以数组来存储堆的数据的,如下图:
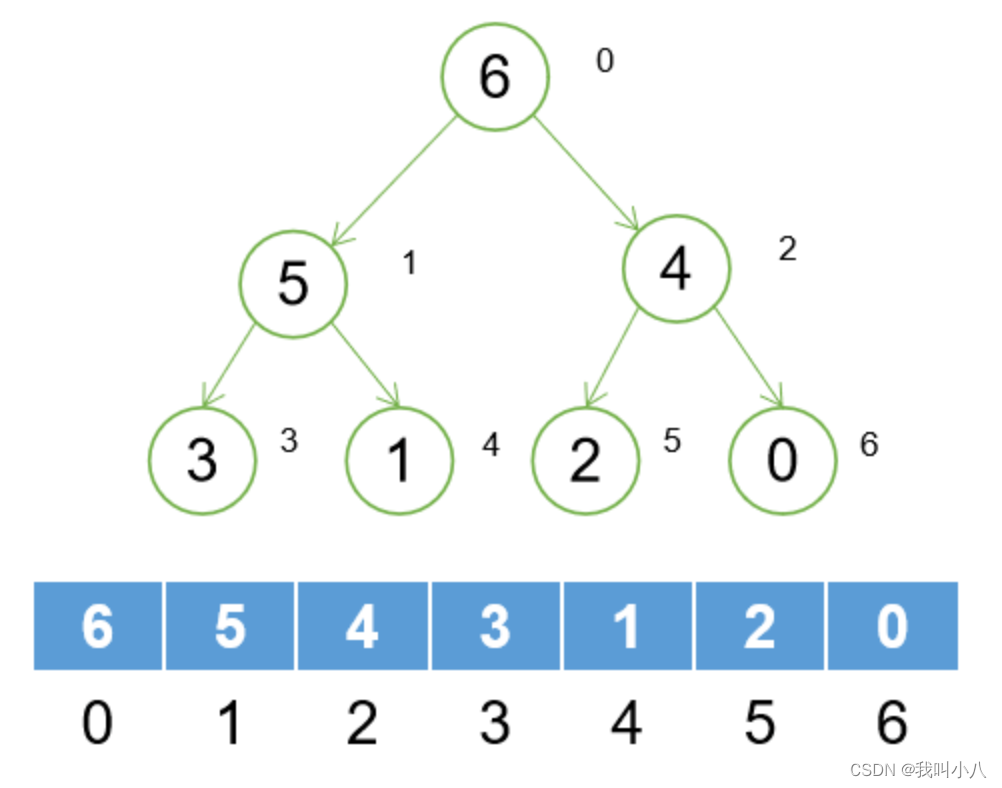
父节点与子节点的关系:
● 左子节点 (leftIndex-1) / 2= fatherIndex
● 左子节点 (leftIndex-2) / 2= fatherIndex
根据上面公式自然也能从父节点推算出2个子节点。
向堆中插入元素,也就是向数组尾部加入新元素,然后再调整新元素的位置,需要向上查找,找到它的父节点,经过对比满足交换条件则交换两个节点,重复该过程直到每个节点都满足堆的性质为止,这个过程我们称之为上浮操作。
而堆中取出堆顶节点,如果我们直接将下标为0的节点删除,然后后面的节点都往前挪一位,成本是很高的。所以这里采用了头节点与尾节点进行交换,这样堆顶的节点就到了尾部,我们再删除尾部即可取出,然后再把换到头部的节点,尾结点放入堆顶后,然后与它的子节点比较,经过对比满足交换条件则交换两个节点,交换后继续向下与子节点比较,直到当前结点的值与子节点对比不需要进行交换时,堆化就完成了,这个过程我们称之为下沉操作。
















 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











