







我所了解到的,将json串解析为DataFrame的方式主要有一样三种:
- 利用pandas自带的read_json直接解析字符串
- 利用json的loads和pandas的json_normalize进行解析
- 利用json的loads和pandas的DataFrame直接构造(这个过程需要手动修改loads得到的字典格式)
实验代码如下:
# -*- coding: UTF-8 -*-
from pandas.io.json import json_normalize
import pandas as pd
import json
import time
# 读入数据
data_str = open('data.json').read()
print data_str
# 测试json_normalize
start_time = time.time()
for i in range(0, 300):
data_list = json.loads(data_str)
df = json_normalize(data_list)
end_time = time.time()
print end_time - start_time
# 测试自己构造
start_time = time.time()
for i in range(0, 300):
data_list = json.loads(data_str)
data = [[d['timestamp'], d['value']] for d in data_list]
df = pd.DataFrame(data, columns=['timestamp', 'value'])
end_time = time.time()
print end_time - start_time
# 测试read_json
start_time = time.time()
for i in range(0, 300):
df = pd.read_json(data_str, orient='records')
end_time = time.time()
print end_time - start_time
实验结果如下:
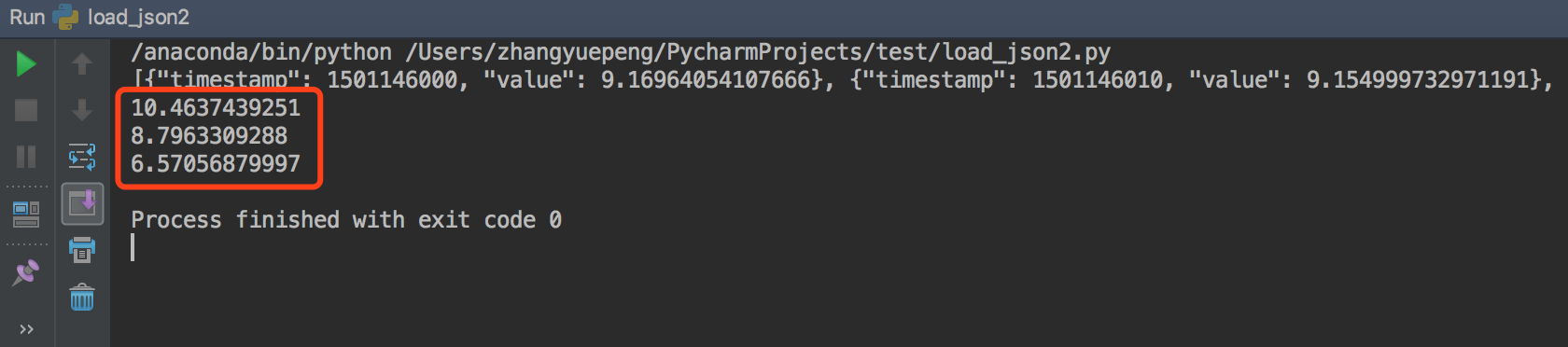
可以看出由于read_json直接对字符串进行的解析,其效率是最高的,但是其对JSON串的要求也是最高的,需要满足其规定的格式才能够读取。
其支持的格式可以在pandas的官网点击打开链接可以看到。然而json_normalize是解析json串构造的字典的,其灵活性比read_json要高很多。
但是令人意外的是,其效率还不如我自己解析来得快(自己解析时使用列表解析的功能比普通的for循环快很多)。当然最灵活的还是自己解析,可以
在构造DataFrame之前进行一些简单的数据处理。
# -*- coding: UTF-8 -*-
from pandas.io.json import json_normalize
import pandas as pd
import json
import time
# 读入数据
data_str = open('data.json').read()
print data_str
# 测试json_normalize
start_time = time.time()
for i in range(0, 300):
data_list = json.loads(data_str)
df = json_normalize(data_list)
end_time = time.time()
print end_time - start_time
# 测试自己构造
start_time = time.time()
for i in range(0, 300):
data_list = json.loads(data_str)
data = [[d['timestamp'], d['value']] for d in data_list]
df = pd.DataFrame(data, columns=['timestamp', 'value'])
end_time = time.time()
print end_time - start_time
# 测试read_json
start_time = time.time()
for i in range(0, 300):
df = pd.read_json(data_str, orient='records')
end_time = time.time()
print end_time - start_time
实验结果如下:















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









