






背景:
当前Apache Spark已经成为了大数据离线计算事实上的标准,随着大模型与大数据的发展,对历史数据的处理已经离不开Spark引擎。
虽然基于内存的Spark计算引擎相比于基于磁盘的Hive(mapreduce)计算引擎来说要快不少,但其稳定性却并没有显著提升。甚至很多场景下,Spark任务的稳定性不如Hive可靠。
这一方面是由于基于内存的计算存在易失性的特点,一旦部分task失败可能需要将整个链路上的任务都重新计算一遍。
另一方面是通用计算引擎要保证整体任务的高效稳定计算就需要对特定场景任务进行针对性调优。
自spark3.0 开始Spark核心已经从Spark Core转变到了Spark SQL, 然而很多的Spark性能调优文章仍然是针对RDD的调优,显然已经过时。
这其中Spark SQL的调优配置和Spark RDD的并非完全通用,曾看到很多人依然在混用两者配置,真实的情况是很多常见的优化配置对Spark SQL来说可能并不会生效。
此外,分析出一套适合特定任务的调优配置是比较麻烦的,甚至需要多次实验验证。
这对于很多只运行一次性的任务来说,并不适合。相反要求快速给出一套配置保证其不会失败挂掉即可,这可能就是本篇文章的目
一.Spark关键参数配置
Spark资源参数调优,主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使用的效率,从而提升Spark作业的执行性能。
以下参数就是Spark中主要的资源参数,每个参数都对应着作业运行原理中的某个部分,同时我也给出了一个调优的参考值。
(1)driver 相关资
源配置
|
|
这上述两个参数分别是driver申请使用的最大使用cpu(线程)数和内存资源。
一般driver节点只负责提交程序,只要操作中没有collect,show等回收到driver的操作,driver的默认配置使用上述配置就已经足够。
(2)executor 相关
资源配置
a.单个executor资源配置
|
|
前两个参数是单个executor申请的cpu线程数和内存资源,也是需要经常调整的参数;
最后一个是申请堆外内存大小的参数,如果你对join策略的细节不太清楚,一般采用默认配置就可以。
例如,当我们经常executor失败时,可以减小这个core和memory的配置,这样即使exector失败那么影响的task可能也只有3个。如果单个executor配置的进程资源太多,每次executor失败都会导致很多task重试。
所以建议不论任务的数据量如何,这两个参数配置都不要太大。
executor.cores默认配置3,4;executor.memory配置12g,16g即可。
如果遇到单个executor内存资源不足,可以调整executor.memory / executor.cores的比例。
单个Task内存计算方法为(executor.memory / executor.cores=12/3=4g)
b. 申请executor的数量
|
|
spark.executor.instances是一个静态配置参数,用于指定Spark应用程序启动时要使用的固定Executor实例数。
这种方式适用于对Executor数量有明确要求的场景,例如处理固定量的数据或在资源受限的环境中运行。
spark.dynamicAllocation.maxExecutors是一个动态Executor配置参数,它和spark.executor.instances建议不要混用。
在开启动态申请executor资源后,Spark会根据当前任务负载自动增加或减少Executor实例数量,以优化资源利用率。
maxExecutors参数定义了分配给应用程序的Executor实例的上限数量,在申请资源时不会超过这个设定的上限。
这里并没给出所有配置的默认值,需要根据任务数据量的大小进行调整,但也不建议配置超过3000的executor数。
有一个方法可以计算出需要多少executor数,了解自己任务的数据量,让数据量除以总的线程数(计算方式为spark.executor.cores * num-executors),保证每个Task的数据量大小为300~500M即可。
二. 分区和参数控制
Spark sql默认shuffle分区个数为200,参数由spark.sql.shuffle.partitions控制,此参数只能控制Spark sql、DataFrame、DataSet分区个数。不能控制RDD分区个数
所以如果两表进行join形成一张新表,如果新表的分区不进行缩小分区操作,那么就会有200份文件插入到hdfs上,这样就有可能导致小文件过多的问题。那么一般在插入表数据前都会进行缩小分区操作来解决小文件过多问题。
|
|
上述两个参数是控制算子分区并发的配置,spark.default.parallelism 配置负责控制默认RDD的partithion数,spark.sql.shuffle.partitions 执行sql或sql类算子时shuffle分区数。
需要注意的是spark.default.parallelism 主要用于控制 RDD 操作的默认并行度级别,而不是 Spark SQL,所以对于 Spark SQL 并不生效。
实际上,Spark SQL 会自动根据数据的分区情况进行任务的划分和调度,用户不能设置。不过对于“性能杀手”shuffle阶段,spark SQL提供了spark.sql.shuffle.partitions用于调整shuffle的并行度。
合理利用CPU资源
根据提交命令spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --queue spark --class com.atguigu.sparksqltuning.PartitionTuning spark-sql-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
去向yarn申请的executor vcore资源个数为12个(num-executors*executor-cores),如果不修改spark sql分区个数,那么就会像上图所展示存在cpu空转的情况。这个时候需要合理控制shuffle分区个数。如果想要让任务运行的最快当然是一个task对应一个vcore,但是数仓一般不会这样设置,为了合理利用资源,一般会将分区(也就是task)设置成vcore的2倍到3倍。
修改参数spark.sql.shuffle.partitions,此参数默认值为200。

那么根据我们当前任务的提交参数,将此参数设置为24或36为最优效果。
三.广播join
(1)join策略中参数
|
|
spark.sql.autoBroadcastJoinThreshold 参数用于控制 Spark SQL 中自动广播连接(join)的阈值,默认是10MB。
这意味着当一个表的大小小于该阈值时,Spark SQL 将自动选择广播连接,使用广播连接可以大大的提升计算性能。
如果你的小表大于10M,但又不是非常大的情况下,可以调整spark.sql.autoBroadcastJoinThreshold的数值,让其大于小表的大小,那么在join计算时就会走广播连接。
但是有些情况下,即使你的小表较小但出现了大量的网络连接失败的日志或大量Task重试,这时可能由于网络拥塞或其他原因导致任务失败。
这种情况下可以将spark.sql.autoBroadcastJoinThreshold=-1设置为-1禁用自动广播join操作,提升计算任务的稳定性。
四.数据倾斜
4.1查看数据倾斜场景
根据此业务,为三表join,即课程表join购物车表再join支付表,造数据时,故意将购物车表数据的courseid(课程id)101和103数据各造了500万条,使两边join时产生数据倾斜。通过spark ui查看数据倾斜场景,先将广播join关闭,因为如果是小表join大表产生数据倾斜了广播join是可以优化掉数据倾斜的
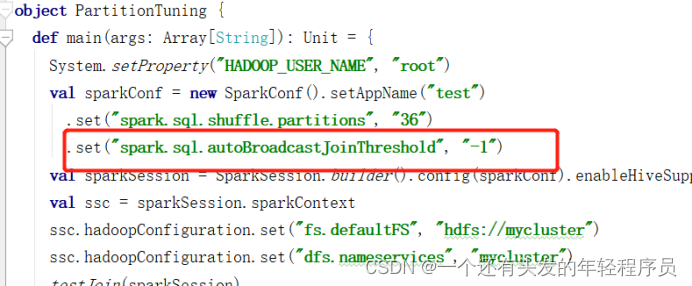
打成jar包,提交yarn运行任务。数据倾斜是在第一个join,小表join大表,所以我们查看stage对应的第一个产生shuffle并且分区是36的stage.
点击stage,查看task详情,点击duration,让task根据耗时排序
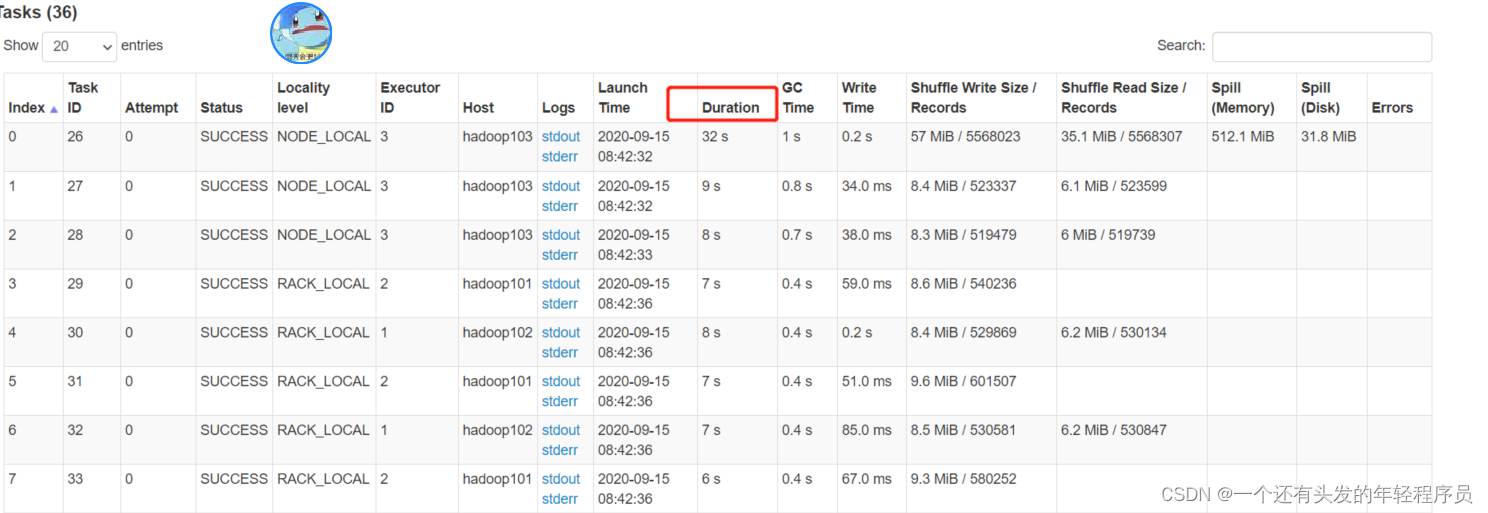

4.2提高并行度(没有用)
2提高并行度(没有用)
网上有很多帖子,说提高并行度可以解决数据倾斜,这种说法是错误的,数据倾斜的本质是某个key的数据量过大,经过shuffle都聚到同一个task了,所以这个时候只是把分区增大也是没用的。下面来测试下,修改spark.sql.shuffle.partitions分区数,将此参数设置为1000。
再来提交任务,查看spark ui图。
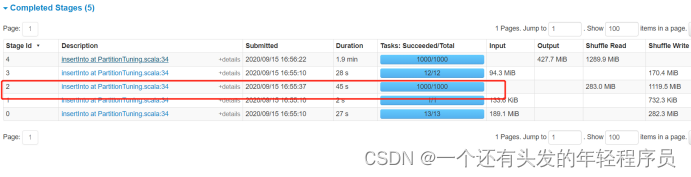
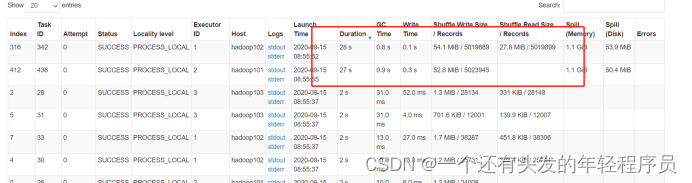
仍然存在数据倾斜情况

所以仅仅是提高并行度,是不能解决数据倾斜问题的。
4.3 广播join
此方案这里就不在演示了,上面广播join已经单独演示过,在小表join大表时如果产生数据倾斜,那么广播join可以直接规避掉此shuffle阶段。直接优化掉stage。并且广播join也是Spark Sql中最常用的优化方案
4.4 打散大表 扩容小表
此方案是先将大表打散比如,现在业务中courseid是101和103两个值过多产生了数据倾斜,那么这个时候可以将大表的数据针对courseid进行打散操作,加上随机值,比如在courseid前加上0-9的随机值打散10分形成0_101,1_101,...,9_101。
打散之后为了让大表和小表join上,那么小表需进行扩容操作和大表对应的随机key能匹配上,那么小表就需要进行扩容操作。小表当中比如存在1条101数据,那么这个时候小表数据量得扩大10倍,并且加上前缀让key变成0_101,1_101,...,9_101。这样能与大表数据join上。
以下为代码处理,这里的实现思路
- 打散大表:实际就是数据一进一出进行处理,对courseid前拼上随机前缀实现打散
- 扩容小表:实际就是将DataFrame中每一条数据,转成一个集合,并往这个集合里循环添加10条数据,最后使用flatmap压平此集合,达到扩容的效果.
五. Spark3.0 AQE
|
|
AQE中实际上是包含了三大特性:
-
自动分区合并:在 Shuffle 过后,Reduce Task 数据分布参差不齐,AQE 将自动合并过小的数据分区。
-
Join 策略调整:如果某张表在过滤之后,尺寸小于广播变量阈值,这张表参与的数据关联就会从 Shuffle Sort Merge Join 降级(Demote)为执行效率更高的 Broadcast Hash Join。
-
自动倾斜处理:结合配置项,AQE 自动拆分 Reduce 阶段过大的数据分区,降低单个 Reduce Task 的工作负载。
他们细节配置如上所示。
因为在SparkSQL中我们只能设置固定的Shuffle 分区数,而且当我们配置spark.sql.shuffle.partition 后会默认给所有的join或agg过程中的shuffle设置统一的分区数,这是不合适的。
而且Spark SQL中的数据倾斜严重影响了Spark 任务的成功率,所以强烈建议用户了解Spark AQE功能,它将更好的提升Spark运行稳定性和性能。
参考文章:超全 SparkSQL 任务快速调优技巧 (qq.com)
六. Spark3.0 DPP
启动DPP
|
|
在大表Join小表的场景中,可以充分利用过滤之后的小表,在运行时动态的来大幅削减大表的数据扫描量(把维度表中的过滤条件, 通过关联关系传导到事实表,从而完成事实表的优化),从整体上提升关联计算的执行性能。
具体可以参考如下文章:[SPARK][SQL] 聊一聊Spark 3.0中的DPP特性 (qq.com)
七. Spark任务调优策略
现象一:所有Task启动时间差很多
如果你的任务本身并不是很大,SparkUI显示Task任务启动时间却相差较大。
这个现象说明Spark Job分配了很多Task, 但却没有足够的并发能够同时启动这些Task执行。
由于分批启动,即等部分executor中的Task释放后,才会启动等待的新一批Task,所以导致Spark执行时间较长。
可以的优化方向,通过调整Spark的并发,即spark.executor.cores * num-executors。
现象二:Spark中个别Task发生spill
一般来说,spark.executor.cores : spark.executor.memory 比例保持在1:4比较合适。
如果需要调整的时候,建议保持spark.executor.cores不动(一般是3或4),只调节spark.executor.memory。
若shuffle数据量很大,出现个别任务发生spill,则说明单个task需要更多的内存,这个时候可以同时调节这两个值。
通过减少cores数或者增加spark.executor.memory,来提高平均每个task的可用内存。
另外需要注意的是:stage发生spill不是失败,只是task想要的内存量比较大,由于内存不足发生写磁盘,故发生spill任务一定会变慢。
现象三:大量的Executor中gc占比较高
首先,判断任务是否出现了数据倾斜严重,数据倾斜可能会导致某些任务消耗大量内存,进而引发频繁的 GC。
其次,如果资源配置的内存使用不合理,就有可能会导致频繁的垃圾回收(GC)现象,从而降低应用程序的性能。
一般来说,我们可以通过调整 spark.executor.memory 参数来增加每个 Executor 的内存分配。
如果任务需要更多的内存,可以通过增加 Executor 数量将负载分摊到更多的节点上,减少单个 Executor 的内存压力。
此外,可以判断下Spark任务使用内存序列化方式是否为Kryo 序列化。Spark默认情况下会使用 Java 序列化来进行对象序列化和反序列化。
但是,Java 序列化会产生较大的对象大小,导致更多的数据在网络传输和存储过程中。可以考虑使用内存序列化(如 Kryo 序列化)来减少对象的大小,降低垃圾回收的压力。
现象四:日志中出现大量的Fetch failure
Spark task日志中发生fetch failure报错,一般都是由于磁盘繁忙所致。
解决方式可以选择集群不繁忙的时间提交任务,或者使用PBS或RSS处理shuffle任务。
现象五:出现数据倾斜
其实判断数据倾斜的方法非常简单,通过Spark UI Stage的Summary的统计信息,是否小部分Task的shuffle writer和shuffle read数据量比较大。
在Spark3.0中,出现这种情况的最简单的处理办法就是开启AQE。
--conf spark.sql.adaptive.enabled=true
--conf spark.shuffle.statistics.verbose=true
--conf spark.sql.adaptive.skewedJoin.enabled=true
--conf spark.sql.adaptive.forceOptimizeSkewedJoin=true
当然更多的处理办法可以参考文章:
现象六:出现数据膨胀
判断数据膨胀,也可以通过Spark UI Stage的Summary的统计信息看出。
一般是shuffle reader的数据量远小于shuffle writer的数据量(例如10倍),这种情况下就是发生了数据膨胀效应。
和数据倾斜类似的时,数据膨胀也可以通过AQE来进行处理优化。
现象七:出现broadcastTimeout或大量网络超时
例如,日志中出现了大量Exception thrown in awaitResult等记录,或者是出现BroadcastExchange失败日志。
那说明spark sql在join采用了BroadcastJoin策略且非常慢了,这种情况下我们就可以禁用自动广播join操作,提升计算任务的稳定性。
可以采用以下配置:
--conf spark.sql.autoBroadcastJoinThreshold=-1
或调小配置增加超时时间
--conf spark.sql.autoBroadcastJoinThreshold=10485760
--conf spark.sql.broadcastTimeout=xxx
现象八:读写hive或parquet时间较长且失败
在读写hive和parquet数据源时,可以通过Spark UI查看当前的Task数。
如果Task数较小,但表的数据量较大,说明任务每个分区上的input比较大,单个task计算量较大甚至引起spill导致任务执行慢。
可以通过调整以下配置来调整读写并发,改善其性能。
--conf spark.sql.files.maxPartitionBytes=128M
--conf spark.sql.sources.parallelPartitionDiscovery.threshold=32
此外,对于文件的数据源时,可以配置并发列出文件的阈值。如果输入路径的数量大于此阈值,Spark 将使用 Spark 分布式作业列出文件。
现象九:出现长尾任务
首先,排除数据倾斜的现象,即在处理数据基本均匀的情况下,依然有个别Task运行的时间非常长,这时就是长尾任务。
针对长尾任务,一般可能由于个别机器的原因或者网络的原因,这时可以kill掉卡住的Task,让其重新调度重试。
现象十:定时Spark任务运行时间变长
对于些长时间未改变spark代码和数据的定时任务来说,偶尔其运行时间会变的很长,可能会给人一种Spark性能时好时坏的感觉,但是实际上也行其真实的运行时间并没有多大波动。
如何分辨这种情况呢?
Spark总的运行时间包括 = AM申请资源时间 + 计算执行时间
Spark真正的执行时间需要去掉申请资源的时间。如果Spark任务长时间显示 ”Application ··· accept“,就说明队列资源紧张,这时应该调整资源的配比。
总结
当然,Spark性能调优有很多配置,这里我们只介绍简单可以快速解决问题的。
首先,很多时候较好的代码可以避免90%的问题,那么这就需完整对Spark体系的认知。
然而,很多时候Spark执行失败,对于些这些急需解决的失败问题的处理,就没有那么多时间进行系统化的学习。那么就可以快速参考这篇文件,对出现的场景进行匹配并尝试优化。
对于Spark执行较慢的任务来说,我们首先应该明白,Spark的性能杀手主要在Shuffle和Join。
我们应该分析Spark运行较慢的任务是否出现上述的对应的场景,例如数据倾斜、膨胀或者长尾任务等,如果上述办法解决不了再分析其瓶颈在哪里,如CPU、网络带宽还是内存,最后在进行针对性优化。















 1785
1785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









