







大赛官网:http://codecraft.huawei.com/
赛题解读:http://mp.weixin.qq.com/s/on_l5Rc3Be-DjgUOXftaNw
赛题案例以及编译官方软件包:HUAWEI_Code_Craft_2017_初赛软件包(readme.txt中有详细介绍)
从2017.3.15到2017.4.6,花费三个星期的时间投入到2017华为精英挑战赛。我是第一次参加这种类似于ACM的算法竞赛,虽然成绩从最初前32强最后跌出64强无缘复赛,但是真的学到了很多东西。大神好多,高手如云,继续努力!
在此分享一下比赛心得,总结在这次挑战赛中所做的努力和工作:

上图为G省网络拓扑图,黑色圆圈为网络节点,红色圆圈为消费节点,圆圈内的数字为节点编号。节点之间的连线为网络链路。链路上的标记(x, y)中,x表示链路总带宽(单位为Gbps),y表示每Gbps的网络租用费。消费节点相连链路上的数字为消费节点的带宽消耗需求(单位为Gbps)。
现在假设需要在该网络上部署视频内容服务器,满足所有消费节点的需求。一个成本较低的方案如下图所示(选择0,1,24作为服务器),其中绿色圆圈表示已部署的视频内容服务器,通往不同消费节点的网络路径用不同颜色标识,并附带了占用带宽的大小:
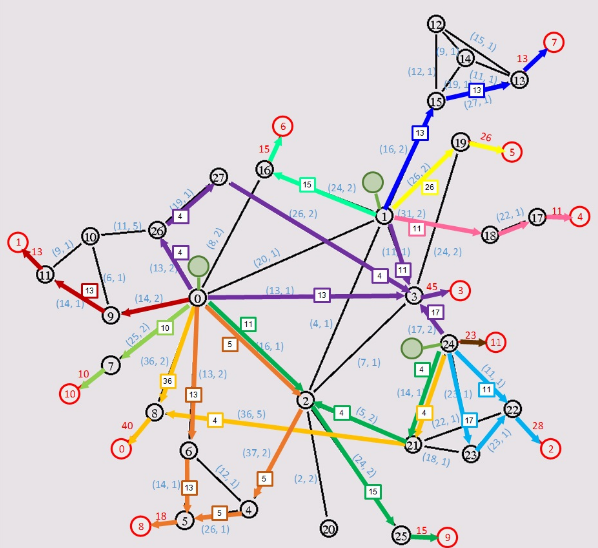
通过分析赛题我们小组发现可以总结为以下几个问题:
1.当选定服务器位置时,如何制定给消费节点提供带宽的策略?
举例:如图中,选择0,1,24作为服务器,如何制定策略在满足所有消费节点带宽需求的前提下,使所花费用最小。
2.如何选择服务器的位置?
l 初始服务器位置选择问题
l 更新服务器位置策略问题
解答:
针对问题1:
采用最小费用最大流的方法(该算法用来解决从一个点到另一个点,提供带宽最大时,所需的最小费用),将所有服务器连向一个超级服务器(源点),将所有消费节点连向一个超级消费节点(汇点)。例如:选择服务器0,1,24时,连接方案如下图所示。注意:源点到服务器带宽无限,费用为0,单向传输;消费节点到汇点带宽为自身所需带宽,费用为0,单向传输。此时只需计算源点到汇点的最小费用最大流就可以了。如果费用流最大带宽<所有节点所需带宽和(即汇点所需带宽),那么所选服务器无法满足要求,否则一定满足要求,并计算出了源点到汇点的最小费用。最后加上单个服务器费用*服务器个数即可求得此次的总最小花费。
如果不这样连接和考虑问题,在计算时会遇到计算逻辑复杂和计算速度慢的问题。通过不断地优化,我们最终在数据规模达到网络节点800点、消费节点360点时,计算一次费用流只需10ms左右。
针对问题2:
方法1:这个赛题明显是一个NP-Hard问题,最开始我们想用暴力的方法解决,首先与每个消费节点直接相连接的网络节点放置局服务器(即初始服务器位置选择,因为这样一定可以保证有解),然后全局网络节点考虑,对服务器集合要么随机采用减一个、换一个或者加一个服务器,然后利用每次选定的服务器集合去计算费用流,存储花费最小的一次费用流。迭代运行直到最后收敛或者达到题目运行时间限制。其中,什么时候减和加都是随机数随机选择的,而且减哪个加哪个网络节点也是由随机数随机选择的,这样就保证了一定随机性,防止陷入局部最优(实际上,我们还是没有很好解决这个问题)。

方法2:由于当数据规模增大到一定程度时,方法1的算法无法在题目要求的90s内收敛,所以要求一个更快的收敛方案。第二个方法还是利用直连的方法布局初始服务器集合,而我们只在当前与消费节点直连服务器中随机减一个或者换一个,直到收敛,取最少费用的一次服务器布局。这样我们相当于将原来在800个点的网络节点中搜索解,转化为了在360个消费节点直连的网络节点中搜索点,显然我们的算法无法找到全局最优解,但是这样可以在有限的时间内更快的收敛,达到一个更小的费用。 由于一直在直连网络节点中搜索,所以对服务器单价不高的情况还是有不错的解的。并且因为一直在直连中计算费用流,在规定时间内计算费用流时间缩减了很多,所以在大案例中有不错的解。大案例(800网络节点)中我们测试得出迭代次数可以多达3万多次,而第一种方法仅有3000多次,快了10倍。在大案例中追求有限时间内搜索最优解还是很不错的idea,得益于此在大规模的比赛样例中我们取得了不错的成绩。
方法3:其实很明显,上面两种方法都会遇到跳不出局部最优解的问题,一旦我们陷入一个局部最优解根本跳不出去,显然还是需要一个启发式的方法,经典的算法像蚁群,爬山,模拟退火,遗传算法,粒子群等,大家可以查阅相关论文,这些都是经典TSP问题很好的解决方法,用在这里肯定也是可行的。 我们最后在服务器选址使用的是模拟退火,算法简单又快速,这也是我们第三种算法。第三种方法初始化还是使用的直连的方法,每次随机加一个服务器、减一个或者换一个,但是我们并不是将这个概率设死,不是对当前花费没有减小的效果就舍弃这次抉择,而是以一定概率去接受它,并且这个概率随着迭代深入慢慢减小,这就是经典的模拟退火的算法,一定程度上可以避免陷入局部最优。
待实现的方法:
但是很遗憾,想法是挺好的,由于没有经验,经过两天调参我们的效果还是不理想,没有解决陷入局部最优的困局。直到比赛结束这个问题也没有解决,最后很遗憾没有进入复赛。
其实解决局部最好方法就是增加随机性,一个是选择服务器的时候加大随机性,这里rand()所以使用时间作为srand参数自然是最好的。
另外初始服务器的随机性,所以一旦结果收敛我们应该重启再继续搜索,但是很遗憾这个方法我们没有时间实践了,就是服务器布局不要选择直连,而是全局随机选择跟消费节点数量相同的服务器,然后多次抉择直到收敛。
最后还有一个思想是经过模拟退火后,接受概率会越来越小,陷入局部最优解。之后我们应该将温度重新升温,即接受概率恢复到某一值,重新降温,如此反复。
我觉得我们失败就是败在了这里,有些遗憾,在最后才想明白。其它人的方法我就不知道,可能还有一些比较启发的选择方法,我们另外还根据每个网络节点的出度设计每个网络节点选择为服务器的权重,自然出度大情况我们更希望它被选择为服务器,但最终效果也不尽如人意。等比赛结束看看大神们的代码,膜拜一下,再重新思考一下该问题。
我们所做过的优化案例:
整个过程,我们对算法做了很多优化,虽然我们没有逃出局部最优解的困局,但是我敢说我们最小费用和整个算法优化是顶尖的。看讨论群里他们分享的速度都没有我们的快。
主要有以下的优化:
1、费用流计算中不管中间路线布局,我们将多源多汇问题优化为单元对单元,也就是模拟设计两个超级节点,一个连接所有服务器,一个连接所有消费节点,整个过程简化为单源单汇费用流问题;
2、每迭代一次不必重新加载所有图数据,我们采用个别数据还原再重新进行下一轮的最小费用流计算即可;
3、服务器集合存储的时候,我们采用标准模板库中set数据结构其实是最好的,第一服务器不会重复set很符合这个性质,第二set是基于红黑树实现的,插入删除很快速,所以使用set比其他任何数据结构都要好,这个设计又让我们的算法效率提高了不少;
4、在各种循环中,应考虑其提前终止的情况,避免没有意义的计算。
以上就是我的总结,虽然很遗憾没有进入复赛,但是过程还是学习了不少,继续加油!
最后提供我们的代码:https://github.com/DUTFangXiang/2017HuaWei_CraftCode















 5437
5437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









