







上篇博客写了如何在Windows下使用IntelliJ IDEA创建Maven工程,在本地完成一个Maven项目的编写后,需要将其打成jar包,以方便在集群上运行,本文将介绍使用IntelliJ IDEA生成jar包并在集群上运行的过程,具体过程如下(企业一般使用jdk1.7,这里将介绍使用jdk1.7进行编译的方法):
1、 设置java兼容
需要注意以下三个地方,将其调为jdk1.7兼容:
Project Structure中的Project language level
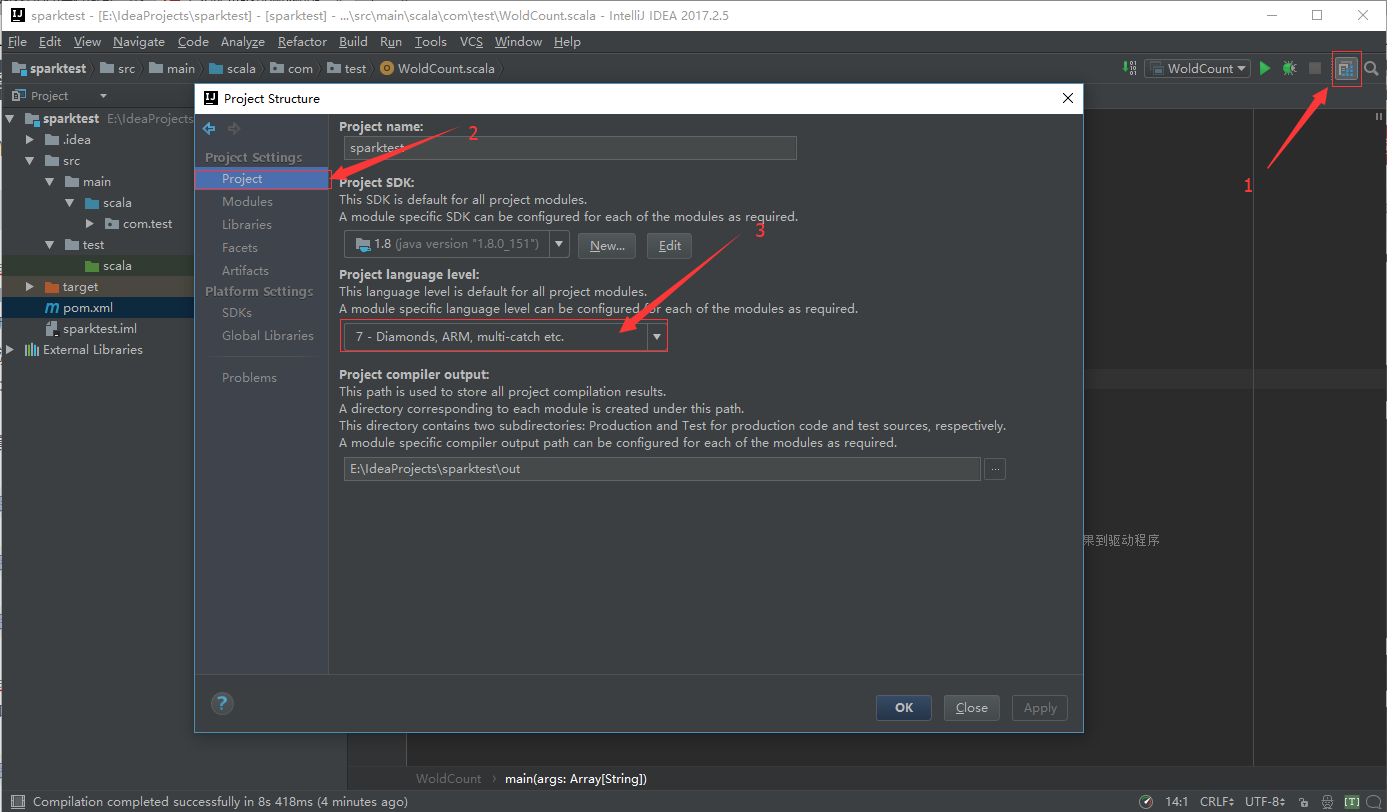
Project Structure中的Language level
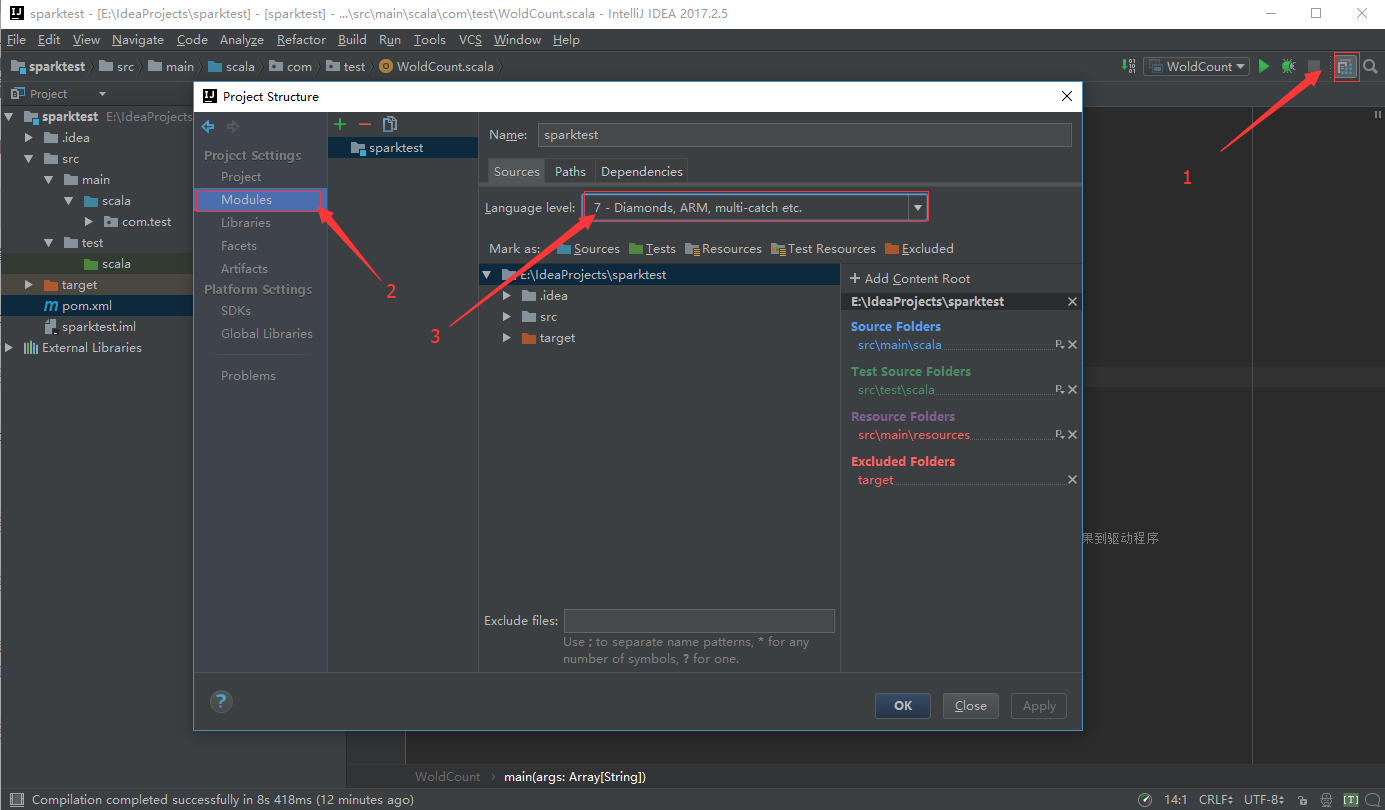
- Setting中的Java Complier
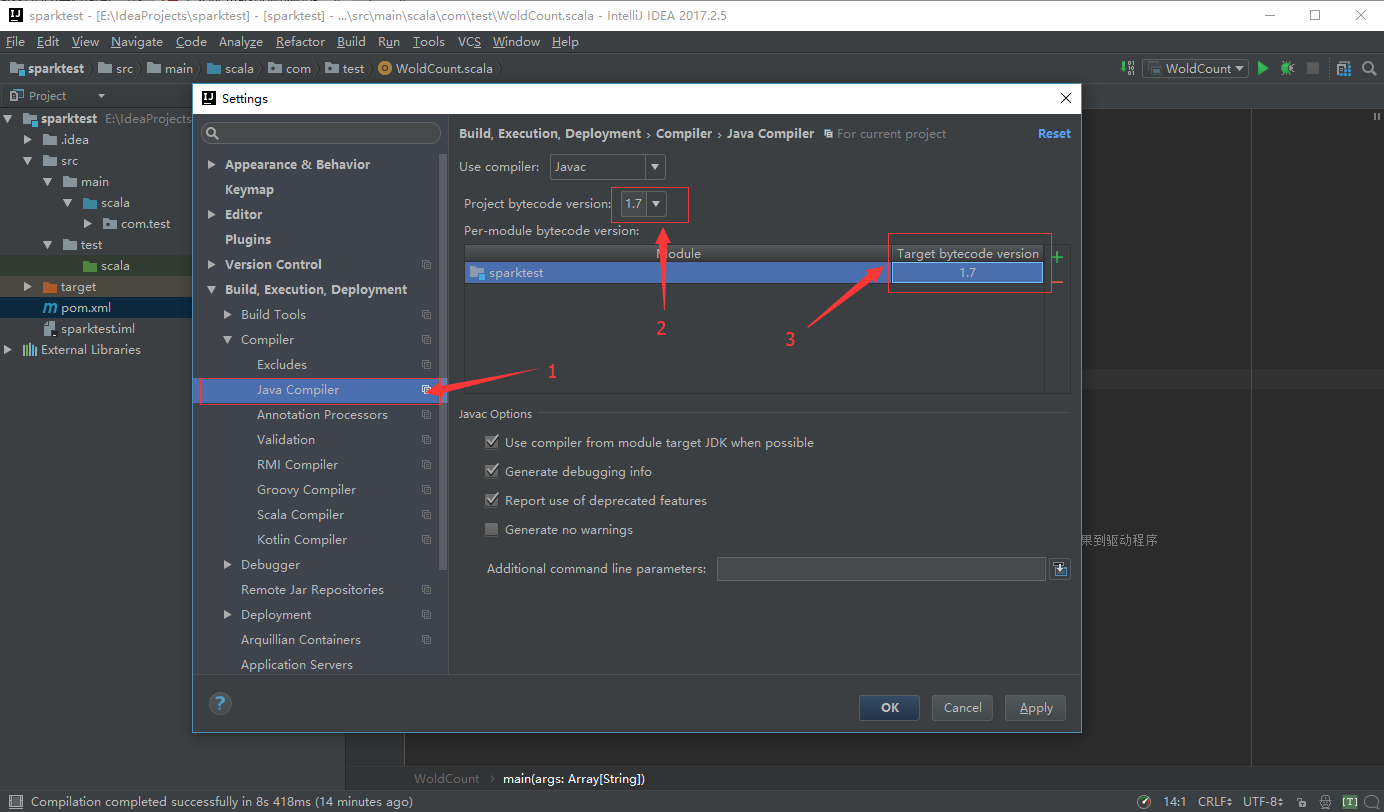
2、使用Maven打jar包
打包前要注意将项目中.setMaster("local[]*")注释掉
上述设置完成后,连按两次alt键(第二次按住不放)可在右侧栏显示Maven Project选项,按顺序执行clean、compleiler和jar命令即可以在项目target目录下生成jar包,如图所示:
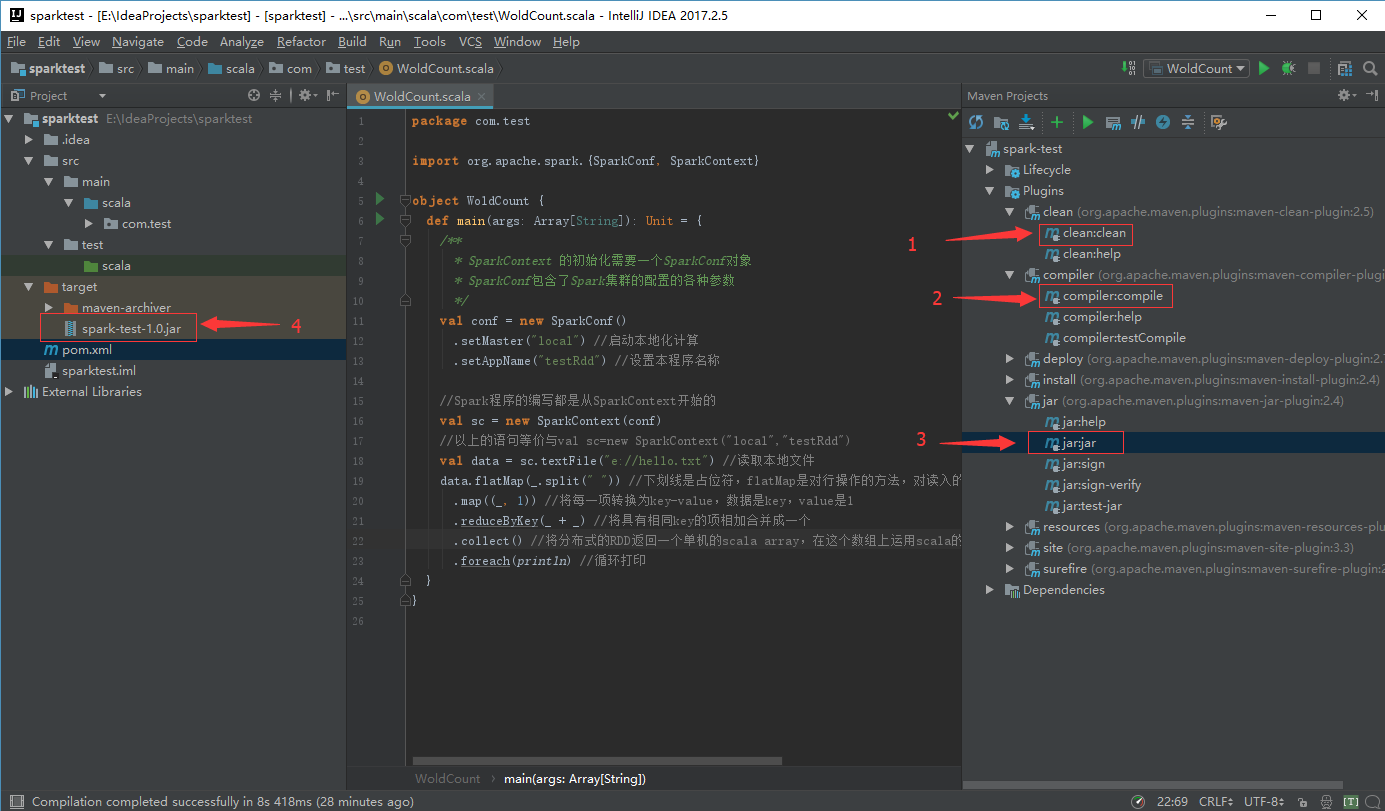
注:可以直接在项目根目录下使用如下命令行打包:
mvn clean package3、在集群上运行
3.1 local模式
./bin/spark-submit \
--class "SimpleApp" \ #指定运行的类
--master local[4] \ #指定local模式,4核心
spark-test-1.0.jar #指定jar包3.2 standalone模式
./bin/spark-submit \
--master spark://ip:7070 \ #指定服务器
--deploy-mode cluster \ #指定运行模式
--class "SimpleApp" \ #指定运行的类
spark-test-1.0.jar #指定jar包DeoloyMode(表示Driver执行的位置):
- client表示driver执行在执行spark-submit命令的机器上
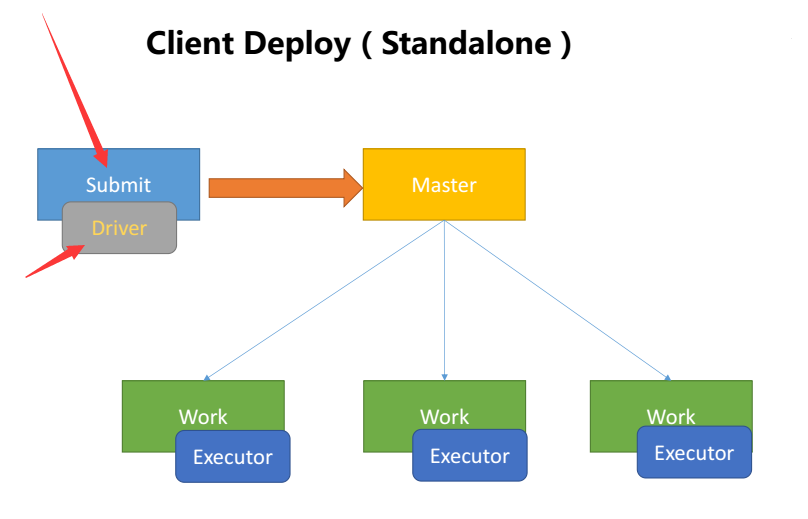
- cluster表示driver会运行在集群中选择的某一台机器上。
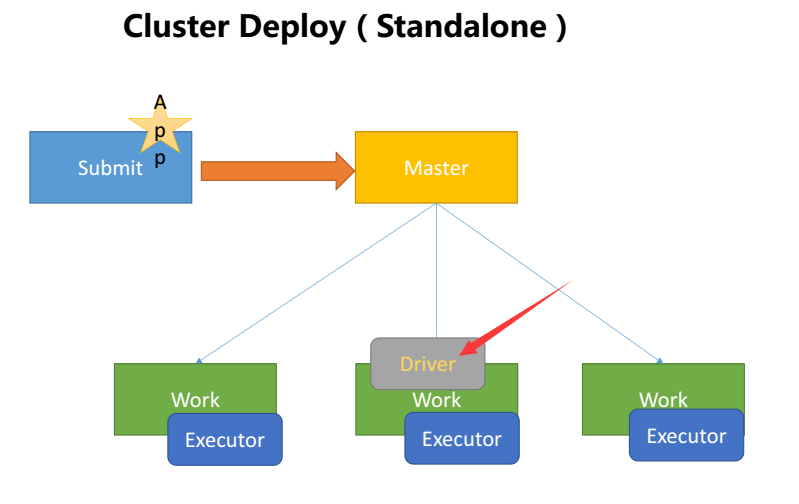
附:常用参数列表:
| 参数 | 用法/含义 |
|---|---|
| –master MASTER_URL | spark://host:port, mesos://host:port, yarn, or local |
| –deploy-mode DEPLOY_MODE | 执行方式,默认为client |
| –class CLASS_NAME | Java或Scala的主类 |
| –name NAME | 程序名称 |
| –driver-memory MEM | 指定内存(1M,2G等) |
| –driver-cores NUM | 核心数量 |
参考链接:
http://blog.csdn.net/high2011/article/details/52812746
http://www.cnblogs.com/juncaoit/p/6381562.html















 5468
5468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









