









一、什么是支持向量机(SVM)?
支持向量机(Support Vector Machine)听起就来是一个很难理解的概念,的确,刚开始听这一概念完全不知其是什么东西。在参考了网上的一些大神通俗的解释后,对于这一概念有了初步的认识。自己也很难想出比这更好的解释,在这里就直接引用知乎大神简之的解释了[1]:点击查看原文地址
大神以一个故事来说明这个问题:在很久以前的情人节,大侠要去救他的爱人,但魔鬼和他玩了一个游戏。魔鬼在桌子上似乎有规律放了两种颜色的球,说:“你用一根棍分开它们?要求:尽量在放更多球之后,仍然适用。

于是大侠这样放,干的不错?

然后魔鬼,又在桌上放了更多的球,似乎有一个球站错了阵营。

SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。

现在即使魔鬼放了更多的球,棍仍然是一个好的分界线。

然后,在SVM 工具箱中有另一个更加重要的 trick。 魔鬼看到大侠已经学会了一个trick,于是魔鬼给了大侠一个新的挑战。

现在,大侠没有棍可以很好帮他分开两种球了,现在怎么办呢?当然像所有武侠片中一样大侠桌子一拍,球飞到空中。然后,凭借大侠的轻功,大侠抓起一张纸,插到了两种球的中间。

现在,从魔鬼的角度看这些球,这些球看起来像是被一条曲线分开了。

再之后,无聊的大人们,把这些球叫做 「data」,把棍子 叫做 「classifier」, 最大间隙trick 叫做「optimization」, 拍桌子叫做「kernelling」, 那张纸叫做「hyperplane」。
总结一下,我们将分割数据集的直线称为分割超平面,数据集是二维的情况下,分割超平面是一条直线,数据集是三维的情况下,分割超平面是一个曲面,当数据集为N为空间时,分割超平面就是一个N-1维的超平面。
二、寻找最大间隔
2.1 点到超平面的距离
显然要找到这个最佳分割超平面,我们就要计算点到平面的距离,这里首先给出高中时候学过的点到二维平面的距离:
d=|Ax0+By0+Cz0+D|A2+B2+C2√
d
=
|
A
x
0
+
B
y
0
+
C
z
0
+
D
|
A
2
+
B
2
+
C
2
将其推广到n维空间:
d=wTA+b∥w∥
d
=
w
T
A
+
b
‖
w
‖
2.2分类器求解的优化问题
首先SVM分类器的标签与Logistics回归不同,Logistics回归的类标签是0或1,而SVM分类器的类标签是-1或+1,因为SVM分类器是根据之前距离来进行分类的,所以不能使用0,而+1和-1能明确地表明距离,例如当点位于分割超平面的正方向时,距离
label∗wTA+b
l
a
b
e
l
∗
w
T
A
+
b
为一个很大的正数,而当点位于分割超平面的负方向时,距离
label∗wTA+b
l
a
b
e
l
∗
w
T
A
+
b
仍是一个很大的正数。
然后我们要做的求w和b,为此我们要找到具有最小间隔的数据点,也就是所谓的“支持向量”,然后最间隔最大化:
argmaxw,b{minn(label⋅(wT+b))⋅1∥w∥}
a
r
g
m
a
x
w
,
b
{
m
i
n
n
(
l
a
b
e
l
⋅
(
w
T
+
b
)
)
⋅
1
‖
w
‖
}
求解以上问题比较困难,为此给定了一些约束条件
label∗(wTx+b)≥1.0
l
a
b
e
l
∗
(
w
T
x
+
b
)
≥
1.0
。对于此类优化问题,我们引入了一个著名的解法拉格朗日乘子法,引入拉格朗日乘子法,我们就可以将超平面携程数据点的形式,于是优化后的目标函数可以写成:
maxα[∑mi=1α−12∑mi,j=1label(i)⋅label(j)⋅αi⋅αj⟨x(i),x(j)⟩]
m
a
x
α
[
∑
i
=
1
m
α
−
1
2
∑
i
,
j
=
1
m
l
a
b
e
l
(
i
)
⋅
l
a
b
e
l
(
j
)
⋅
α
i
⋅
α
j
⟨
x
(
i
)
,
x
(
j
)
⟩
]
其约束条件为:
α≥0,和∑mi=1αi⋅label(i)=0
α
≥
0
,
和
∑
i
=
1
m
α
i
⋅
l
a
b
e
l
(
i
)
=
0
当然以上约束条件成立的前提是数据必须100%线性可分,显然这是个理想的状态,考虑到有的数据并不是线性可分的,我们引入一个松弛变量来允许有一些数据点出现在分割面的另一侧,此时新的约束条件变为:
C≥ α≥0,和∑mi=1αi⋅label(i)=0
C
≥
α
≥
0
,
和
∑
i
=
1
m
α
i
⋅
l
a
b
e
l
(
i
)
=
0
这里常数C用于控制“最大化间隔”和“保证大部分点的函数间隔小于1.0”这两个目标的权重。在算法中常数C是一个参数,可以通过调节这个参数来得到不同的结果,SVM的主要工作就是就是求出所有的alpha,然后用alpha来表达分割超平面。
三、SMO算法
SMO(序列最小化)算法,是John Platt发布的用于训练SVM的算法,算法将大的优化问题分解为多个小优化问题来处理,大大地提高了效率。
SMO算法的目标是求出一系列的alpha和b,然后计算出权重向量并得到分割超平面。
SMO算法的工作原理是:每次循环中选择两个alpha进行优化处理。一旦找到了一对合适的alpha,那么就增大其中一个同时减小另一个。这里所谓的”合适”就是指两个alpha必须符合以下两个条件,条件之一就是两个alpha必须要在间隔边界之外,而且第二个条件则是这两个alpha还没有进行过区间化处理或者不在边界上。
3.1 SMO算法的步骤
(这里参考了Jack-Cui师兄的一篇博客,关于算法推导和步骤总结的非常好。点击查看引用原文)
- 步骤1:计算误差:
-
- 步骤2:计算上下界L和H:
- 步骤3:计算η:
- 步骤4:更新αj:
- 步骤5:根据取值范围修剪αj:
- 步骤6:更新αi:
- 步骤7:更新b1和b2:
- 步骤8:根据b1和b2更新b:
- ####3.2 简化版的SMO算法 书中首先给出的是简化版的SMO算法,以便理解算法的基本工作思路,简化版的算法代码量少,但执行速度慢。完整版算法中的外循环确定要优化的最佳alpha对,而简化版代码跳过了这一部分,首先在数据集熵遍历每一个alpha,然后在剩下的alpha集合中随机选择另一个alpha,从而构建alpha对。这里有一点相当重要,就是我们要同时改变两个alpha,之所以这样做是因为我们有一个约束条件
∑mi=1αi⋅label(i)=0
∑
i
=
1
m
α
i
⋅
l
a
b
e
l
(
i
)
=
0
存在,只改变一个alpha可能会导致该条件失效,因此我们总是同时改变两个alpha。 实现以上算法还需要三个辅助函数;
def loadDataSet(filename): dataMat = [];labelMat = [] fr = open(filename) for line in fr.readlines(): lineArr = line.strip().split('\t') dataMat.append([float(lineArr[0]),float(lineArr[1])]) labelMat.append(float(lineArr[2])) return dataMat,labelMat def selectJrand(i,m): j=i while(j==i): j=int(random.uniform(0,m)) return j def clipAlpha(aj,H,L): if aj>H: aj = H if L>aj: aj = L return aj第一个函数loadDataSet()是对文件进行处理的函数,函数打开指定文件,获取数据和类标签。
第二个函数selectJrand()有两个参数,i和m,分别是alpha的下标和数量,用于随机选择alpha的值。
第三个函数clipAlpha(),用于调整alpha的值,使其介于L和H之间。
简化版SMO的代码如下:def smoSimple(dataMatIn, classLabels, C, toler, maxIter): dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose() b = 0; m,n = shape(dataMatrix) alphas = mat(zeros((m,1))) iter = 0 while (iter < maxIter): alphaPairsChanged = 0 for i in range(m): fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b Ei = fXi - float(labelMat[i]) #误差 if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) \ and (alphas[i] > 0)): #判断是否满足约束条件 j = selectJrand(i,m) fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b Ej = fXj - float(labelMat[j]) alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy(); if (labelMat[i] != labelMat[j]): #计算L和H L = max(0, alphas[j] - alphas[i]) H = min(C, C + alphas[j] - alphas[i]) else: L = max(0, alphas[j] + alphas[i] - C) H = min(C, alphas[j] + alphas[i]) if L==H: print ("L==H"); continue eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T\ - dataMatrix[j,:]*dataMatrix[j,:].T #计算eta if eta >= 0: print( "eta>=0"); continue alphas[j] -= labelMat[j]*(Ei - Ej)/eta #更新alpha的值 alphas[j] = clipAlpha(alphas[j],H,L) #处理alpha的值 if (abs(alphas[j] - alphaJold) < 0.00001): print ("j not moving enough"); continue alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j]) b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T \ - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T#计算b1和b2 b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T -\ labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T if (0 < alphas[i]) and (C > alphas[i]): b = b1 #更新b的值 elif (0 < alphas[j]) and (C > alphas[j]): b = b2 else: b = (b1 + b2)/2.0 alphaPairsChanged += 1 print ("iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)) if (alphaPairsChanged == 0): iter += 1 else: iter = 0 print ("iteration number: %d" % iter) return b,alphas参考资料:
1.知乎上某大神对SVM通俗易懂的解释:https://www.zhihu.com/question/21094489/answer/86273196
2.Jack-Cui师兄博客对SVM详细的整理:http://blog.csdn.net/c406495762/article/details/78072313
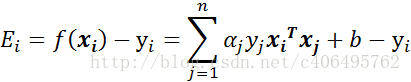
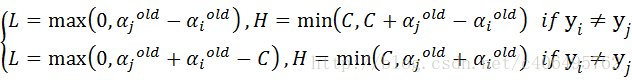
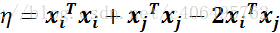
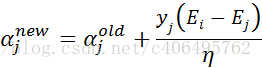

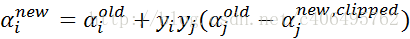
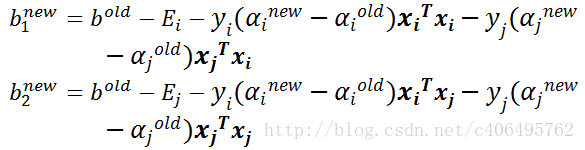
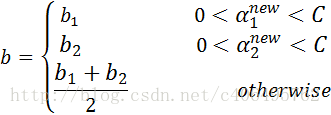















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









