






Uncertainty-aware Self-ensembling Model for Semi-supervised 3D Left Atrium Segmentation
半监督学习:不确定感知自增强模型(UA-MT)在三维左心房分割中的应用
论文地址:https://arxiv.org/abs/1907.07034
Abstract:(BackGround)
·深度卷积神经网络的训练通常需要大量的有标签的数据。然而,在医疗图像分割任务中获取大量有标签的数据是昂贵且费时的。
·在医疗图像领域,由经验丰富的专家对3D图像进行逐层注释是昂贵且繁琐的。
Introduction:
·我们建立了学生模型和教师模型,学生模型通过最小化对有标签数据的分割损失和一致性损失来向教师模型学习。
·我们设计了UA-MT框架,使学生模型利用不确定性信息逐步的从有意义的和可靠的目标中学习。
·除了获得目标输出之外,teacher模型还通过蒙特卡罗抽样去估计每个每个目标预测的不确定性。在估计不确定性的指导之下,当计算一致性损失时我们滤去了那些不可靠的预测,只保留了可靠的预测(低不确定性的预测)。
一点补充:
由于本论文是半监督学习中的经典模型(Mean Teacher)和不确定性相结合,所以把Mean Teacher和不确定性都扩展说说:
Mean Teacher:
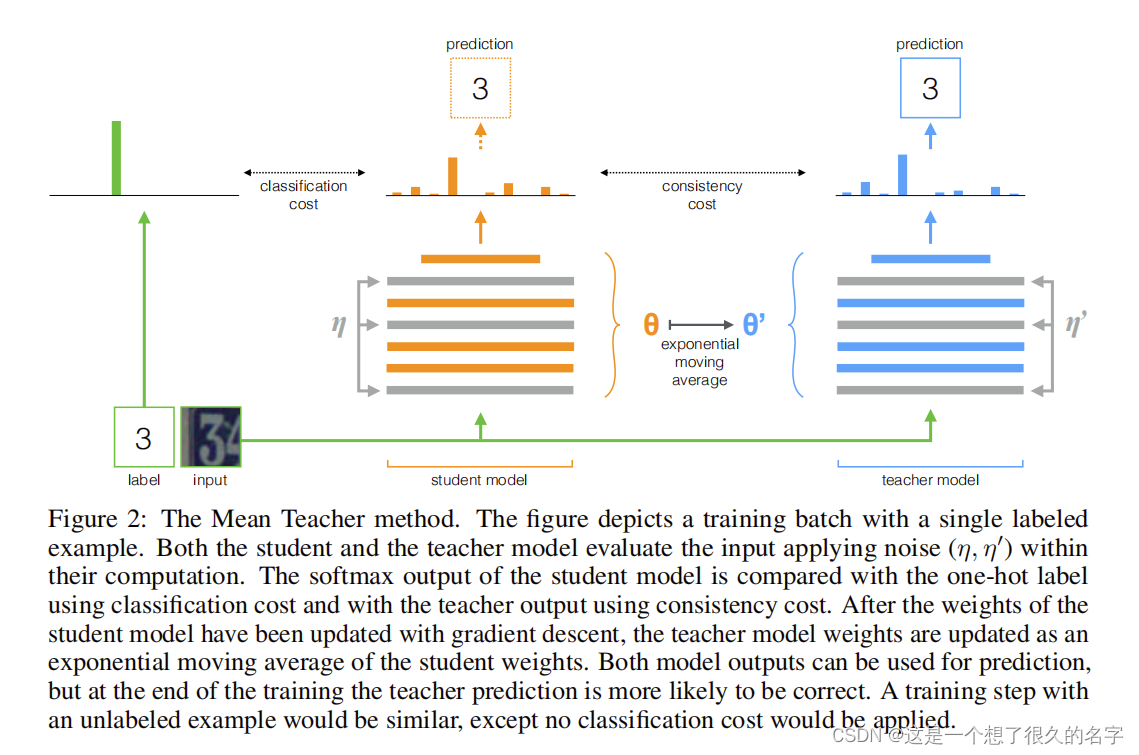
有标签数据和无标签数据都会输入到student和teacher model中,教师模型和学生模型的架构完全一致(神经网络层数之类的),学生模型利用lable data和预测值计算交叉熵L1,教师模型的预测值和学生模型的预测值计算一致性损失L2,最后L1+L2梯度下降更新学生模型的参数θ,教师模型的参数通过EMA的方式来更新。
不确定性:
1.数据的不确定性:也称为了偶然不确定性。是数据内在的噪声,这个现象不能通过增加采样数据来削弱。例如有时候拍照得手稍微颤抖会导致画面模糊,这种模糊是不能通过增加拍照次数来消除的,因此解决这个问题的方法一般是提升数据采集时的稳定性(治好手,不让他抖)。
2.模型的不确定性:也被称为认知不确定性。是模型自身对输入数据的估计可能因为训练不佳、训练数据不够等原因而不准确,与某一单独的数据无关。因此,认知不确定性测量的是训练过程本身所估计的模型参数的不确定性,这种不确定性是可以通过有针对性的调整(增加训练数据等方式)来缓解甚至是解决的。
如何引入不确定性?
主要的方式是贝叶斯神经网络和模型相融合,但是在计算后验估计的时候贝叶斯的分母部分积分又不好计算,怎么办?
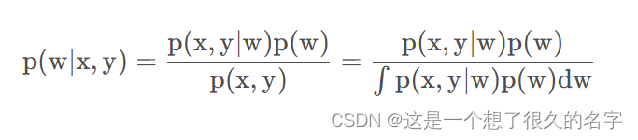
计算的三种方式:马尔科夫链蒙特卡罗,变分推理,蒙特卡罗dropout。
其中蒙特卡罗drop是近几年运用的比较多的方式。下面有关于贝叶斯网络和蒙特卡罗的论文和链接。
https://blog.csdn.net/caozongjing/article/details/123815144?spm=1001.2014.3001.5506
http://arxiv.org/abs/1506.02142
接着是本论文的方法部分:
Method:
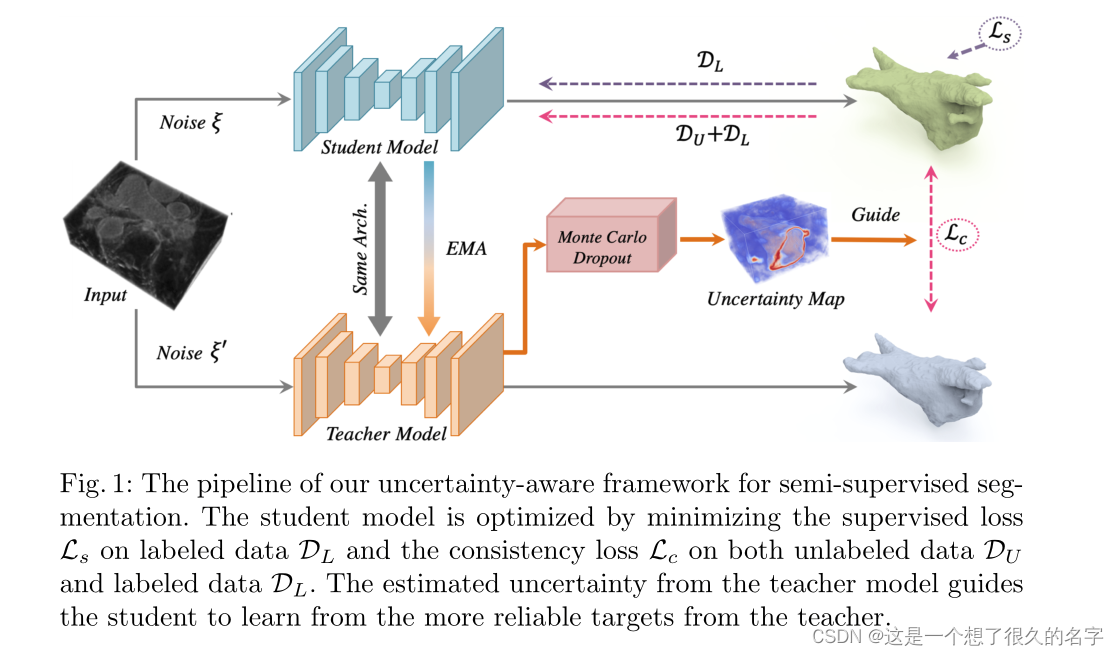
左侧是经典的Mean Teacher框架,在Mt的基础上作者对教师模型通过蒙特卡罗抽象估计每个目标预测的不确定性,得到了不确定性Map,通过不确定性Map去指导一致性损失。再由一致性损失和交叉熵反向传播更新学生模型参数,教师模型的参数通过EMA方式来更新。
半监督分割:
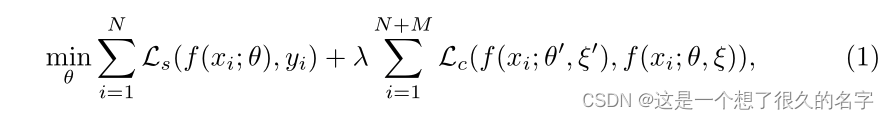
N:有标签数据个数
M:无标签数据个数
Ls:交叉熵
Lc:一致性损失
![]()
α:控制EMA的更新速度的的参数
θt:学生模型第t次迭代训练中的参数
不确定感知MT框架:
拿到一批训练图像时,teacher模型不仅产生目标预测,还评估他们的不确定性。学生模型在学习过程中只选具有更低的不确定性的数据计算一致性损失。
不确定性估计:
对于每一个输入数据进行T次前向传播获得预测结果,每一次都随机对输入数据加入高斯噪声。因此,对于每一个体素都有T个预测结果,表示为![]() 。
。
选取预测熵来衡量不确定性:
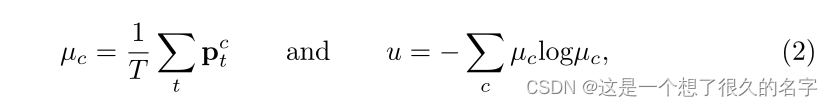
其中是 对在第t次前向传播中对属于第c类别概率的预测。最终可以构成一个不确定性张量![]() 。
。
不确定性一致性损失:
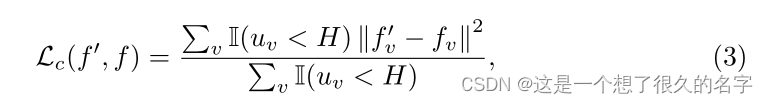
I(·):是一个指示函数,条件成立返回1,否则为0。用于筛出可靠样本。
fv : 教师和学生网络在第v个体素位置的预测结果。
μv:不确定张量U在第v个体素上的值。
H : 过滤不确定预测的阈值。
H = 3/4Umax and Umax = ln2
实验细节:
为了在V-Net调整为贝叶斯神经网络去估计不确定性,在V-Net左侧第五层和右侧第一层分别加入了丢失率为0.5的丢失层。
我们根据经验讲EMA参数设置为0.99。
为了控制有监督和无监督的一致性损失之间的平衡,我们使用高斯升温函数:
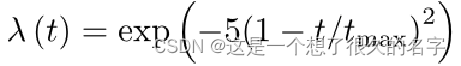
t:当前训练步骤
对半监督分割的评估:
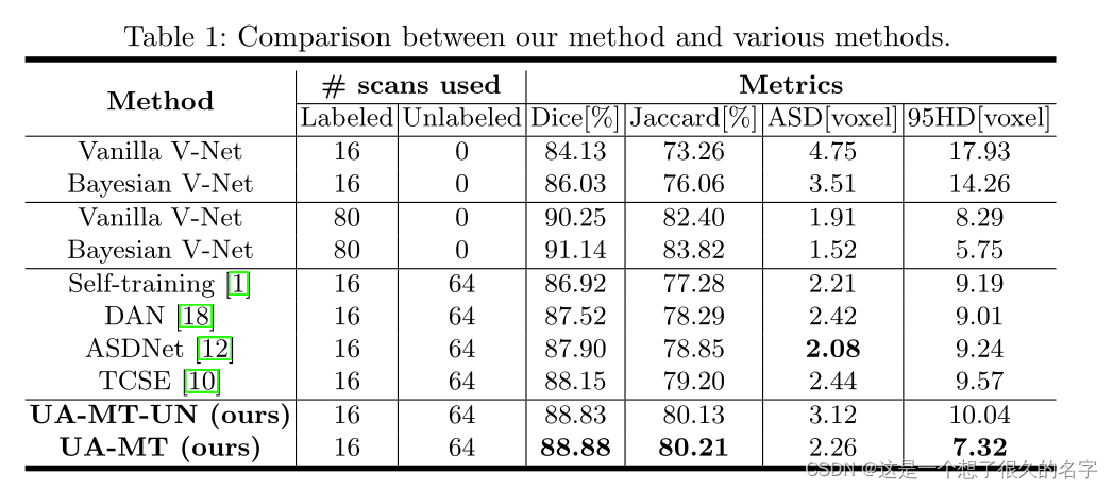
分别用Dice,Jaccard,ASD,95HD来衡量分割性能,拿前两行(使用16个带标签数据的基线V-Net和贝叶斯V-Net)和最后一行相比可以得出:贝叶斯V-Net可以改变基线V-Net的性能,UA-MT之中的无标签数据也大大的提升了分割性能。并且接近于性能上界(80个带标签的贝叶斯V-Net)。与当前比较先进的半监督方法中只是ASD值低于ASDNet,说明我们的不确定感知MT模型完全有能力从未标记数据中提取信息。
蓝色的是预测值,红色的是ground truth,与监督方法相比,我们的结果和ground truth更接近,误差更小,d图说明了不确定性估计对边界和模糊区域预测的更好。
结论:
我们的方法鼓励在不同扰动下对相同的输入进行一致分割。更重要的是,我们探索了模型的不确定性以提高分割目标的质量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









