







图相关问题
作为指针三剑客之三,图是树的升级版。图通常分为有向(directed)或无向(undirected),有循环(cyclic)或无循环(acyclic),所有节点相连(connected)或不相连(disconnected)。树即是一个相连的无向无环图,而另一种很常见的图是有向无环图(Directed Acyclic Graph,DAG)
图通常有两种表示方法。假设图中一共有n 个节点、m 条边。第一种表示方法是邻接矩阵(adjacency matrix):我们可以建立一个n×n 的矩阵G,如果第i 个节点连向第j 个节点,则G[i][j]= 1,反之为0;如果图是无向的,则这个矩阵一定是对称矩阵,即G[i][j] = G[j][i]。第二种表示方法是邻接链表(adjacency list):我们可以建立一个大小为n 的数组,每个位置i 储存一个数组或者链表,表示第i 个节点连向的其它节点。邻接矩阵空间开销比邻接链表大,但是邻接链表不支持快速查找i 和j 是否相连,因此两种表示方法可以根据题目需要适当选择。除此之外,我们也可以直接用一个m×2 的矩阵储存所有的边。
785. Is Graph Bipartite? (Medium)
问题描述
给定一个图,判断其是否可以二分。(分成两种颜色,相邻两个节点之间颜色不相同)
输入输出样例
示例 1:
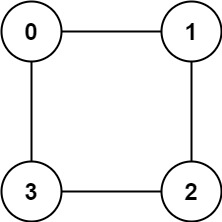
输入:graph = [[1,2,3],[0,2],[0,1,3],[0,2]]
输出:false
解释:不能将节点分割成两个独立的子集,以使每条边都连通一个子集中的一个节点与另一个子集中的一个节点。
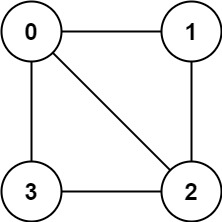
示例 2:
输入:graph = [[1,3],[0,2],[1,3],[0,2]]
输出:true
解释:可以将节点分成两组: {0, 2} 和 {1, 3} 。
思路
广度优先搜索图,每遍历一层,就将该层标记为上一层不同的颜色。如果遍历过程中发现两个相邻结点的颜色相同,则返回false。如果遍历完所有节点都没有返回false,则最终返回true。
注意:图广度优先搜索使用队列时,入队时就要标记其为访问过,否则有环存在时同一节点会入队两次。
代码
class Solution {
public boolean isBipartite(int[][] graph) {
int n = graph.length;
int[] visited = new int[n]; //0表示未访问过,1/2表示两种不同的颜色
for(int i=0;i<n;i++){
Deque<Integer> queue = new LinkedList<>();
if(visited[i]==0){
queue.offer(i);
visited[i]=1;
while (!queue.isEmpty()){
int tem = queue.poll();
for(int j:graph[tem]){
if(visited[j]==0){
queue.offer(j);
visited[j]=(visited[tem]==1?2:1);
}else if(visited[j]==visited[tem])return false;
}
}
}
}
return true;
}
}
210. Course Schedule II (Medium)
问题描述
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] = [ai, bi] ,表示在选修课程 ai 前 必须 先选修 bi 。
例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示:[0,1] 。
输入输出样例
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:[0,1]
解释:总共有 2 门课程。要学习课程 1,你需要先完成课程 0。因此,正确的课程顺序为 [0,1] 。
示例 2:
输入:numCourses = 4, prerequisites = [[1,0],[2,0],[3,1],[3,2]]
输出:[0,2,1,3]
解释:总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。并且课程 1 和课程 2 都应该排在课程 0 之后。
因此,一个正确的课程顺序是 [0,1,2,3] 。另一个正确的排序是 [0,2,1,3] 。
示例 3:
输入:numCourses = 1, prerequisites = []
输出:[0]
思路
首先将输入构建成一个邻接表的形式。本题实质上是一个拓扑排序的问题,需要从一个没有前驱节点(入度为0)的节点开始层次遍历,然后降下一层入度减一,之后继续遍历入度为0的节点,直到所有节点都访问完。
层次遍历完后某几个节点后入度仍为0,则说明存在环。
代码
class Solution {
public int[] findOrder(int numCourses, int[][] prerequisites) {
List<List<Integer>> graph = new LinkedList<>();
for (int i = 0; i < numCourses; i++) {
List<Integer> list = new LinkedList<>();
graph.add(list);
}
int[] degree = new int[numCourses];
for(int[] a:prerequisites){
int pre=a[1];
int post=a[0];
graph.get(pre).add(post);
degree[post]++;//统计入度
}
Deque<Integer> queue = new LinkedList<>();
LinkedList<Integer> ans = new LinkedList<>();
for (int i = 0; i < numCourses; i++) {
if(degree[i]==0){//从入度为零的节点开始遍历
queue.offer(i);
}
}
while (!queue.isEmpty()){
int tem = queue.poll();
ans.add(tem);
for(int j:graph.get(tem)){
degree[j]--;
if(degree[j]==0){
queue.offer(j);
}
}
}
for (int i = 0; i < numCourses; i++) {
if(degree[i]!=0)return new int[0];
}
int[] res = new int[numCourses];
for (int i = 0; i < numCourses; i++) {
res[i]=ans.pop();
}
return res;
}
}
并查集相关问题
并查集(union-find, 或disjoint set)可以动态地连通两个点,并且可以非常快速地判断两个点是否连通。假设存在n 个节点,我们先将所有节点的父亲标为自己;每次要连接节点i 和j 时,我们可以将i 的父亲标为j;每次要查询两个节点是否相连时,我们可以查找i 和j 的祖先是否最终为同一个人。
684. Redundant Connection (Medium)
问题描述
给定往一棵 n 个节点 (节点值 1~n) 的树中添加一条边后的图。添加的边的两个顶点包含在 1 到 n 中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为 n 的二维数组 edges ,edges[i] = [ai, bi] 表示图中在 ai 和 bi 之间存在一条边。
请找出一条可以删去的边,删除后可使得剩余部分是一个有着 n 个节点的树。如果有多个答案,则返回数组 edges 中最后出现的边。
输入输出样例
示例 1:
输入: edges = [[1,2], [1,3], [2,3]]
输出: [2,3]
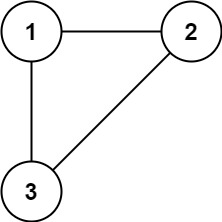
思路
使用并查集,每遍历一条边,如果这两个端点不在同一个集合中,则将它们合并。如果这两个端点在同一个集合中,说明出现了环,此时该边就是可以删除的边,保存该结果,继续遍历直到找到最靠后的结果。
代码
class Solution {
public int[] findRedundantConnection(int[][] edges) {
int n = edges.length;
UF uf = new UF(n);
int[] ans = new int[0];
for(int[] edge:edges){
int v1 = edge[0];
int v2 = edge[1];
if(uf.isConnect(v1-1,v2-1)){
ans = edge;
}else {
uf.union(v1-1,v2-1);
}
}
return ans;
}
}
class UF{
private int[] pre;
public UF(int n){
pre = new int[n];
for (int i = 0; i < n; i++) {
pre[i]=i;
}
}
public int find(int a){
int tem = pre[a];
if(tem == a) return a;
return find(pre[a]);
}
public void union(int a,int b){
int p = find(a);
pre[find(b)] = p;
}
public boolean isConnect(int a,int b){
return find(a)==find(b);
}
}
ps:并查集可以压缩路径进行一定优化,优化的代码可以参考《数据结构java版》那篇文章。
复合数据结构
146. LRU Cache (Medium)
问题描述
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
思路
首先可以继承一个LinkedHashMap来实现一个LRU队列,由于LinkeHashMap有序,且是一个哈希表结构,满足时间复杂度为1的条件。
代码
class LRUCache extends LinkedHashMap<Integer,Integer>{
int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75F, true); //注意初始化父类
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key,-1);
}
public void put(int key, int value) {
super.put(key,value);
}
//该函数是一个回调函数,表示移除最久未使用的一个元素,需要覆盖重写该类,定义自己的逻辑
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return this.size()>capacity; //当数据量超过容量时,删除最久未使用的元素
}
}
代码二(手动实现双向链表)
思路:使用一个hashmap保存元素,key为查找的索引,value为指向双向链表的节点引用。查找时,可以直接在map中找到对应节点的位置。get操作时,如果有该结点,删除它并加到头结点后方,没有则返回-1;put操作,如果有该结点,更新值并将其放在头结点后方,如果没有新建一个节点加入哈希表中,并添加到头结点后方。
class LRUCache{
class Node{
int key;
int value;
Node pre;
Node next;
Node(int key,int value){
this.key = key;
this.value = value;
this.pre = null;
this.next = null;
}
}
Node head,tail;
Map<Integer,Node> map;
int capacity;
public LRUCache(int capacity) {
head = new Node(-1,-1);
tail = new Node(-1,-1);
head.next = tail;
tail.pre = head;
map = new HashMap<>();
this.capacity = capacity;
}
public int get(int key) {
if(map.containsKey(key)){
Node node = map.get(key);//通过哈希表直接定位双向链表中的位置
refresh(node);//更新到头结点后方
return node.value;
}
return -1;
}
//更新到头结点后方
void refresh(Node node){
delete(node);
node.next = head.next;
head.next.pre = node;
head.next = node;
node.pre = head;
}
//从双向链表中删除当前节点
void delete(Node node){
if(node.pre!=null){//前驱接点不为空,说明链表不为空
Node p = node.pre;
p.next = node.next;
node.next.pre = p;
}
}
public void put(int key, int value) {
if(map.containsKey(key)){ //存在则找到该结点,更新值和位置
Node node = map.get(key);
node.value = value;
refresh(node);
}else {
if(map.size() == capacity){//满了删除最后一个节点
Node p = tail.pre;
map.remove(p.key);
delete(p);
}
Node p = new Node(key,value);//不存在且有位置,则分别添加到map中和双向链表中
map.put(key,p);
refresh(p);
}
}
}
380. Insert Delete GetRandom O(1) (Medium)
问题描述
实现RandomizedSet 类:
RandomizedSet() 初始化 RandomizedSet 对象
bool insert(int val) 当元素 val 不存在时,向集合中插入该项,并返回 true ;否则,返回 false 。
bool remove(int val) 当元素 val 存在时,从集合中移除该项,并返回 true ;否则,返回 false 。
int getRandom() 随机返回现有集合中的一项(测试用例保证调用此方法时集合中至少存在一个元素)。每个元素应该有 相同的概率 被返回。
你必须实现类的所有函数,并满足每个函数的 平均 时间复杂度为 O(1) 。
思路
查找需要O(1)时间复杂度,则选择想到使用哈希表结构。使用一个map,分别记录值以及该值所在的位置。删除和随机查找都需要O(1),选择使用LinkedList集合。
代码
class RandomizedSet {
Map<Integer,Integer> map;
List<Integer> list;
Random random;
public RandomizedSet() {
map = new HashMap<>();
list = new LinkedList<>();
random = new Random();
}
public boolean insert(int val) {
if(map.containsKey(val)) return false;
int index = list.size();
list.add(val);
map.put(val,index);
return true;
}
//注意,list.remove方法时,该索引位置会被后面的覆盖掉。所以选择先把该位置修改为末尾元素,然后再删除末尾元素。
public boolean remove(int val) {
if(!map.containsKey(val))return false;
int index = map.get(val);
int last = list.get(list.size()-1);
list.set(index,last);
map.put(last,index); //注意操作顺序,remove要在最后,否则只有一个元素时删除操作有误
list.remove(list.size()-1);
map.remove(val);//别忘记从哈希表中删除val
return true;
}
public int getRandom() {
int rand = random.nextInt(list.size());
return list.get(rand);
}
}
/**
* Your RandomizedSet object will be instantiated and called as such:
* RandomizedSet obj = new RandomizedSet();
* boolean param_1 = obj.insert(val);
* boolean param_2 = obj.remove(val);
* int param_3 = obj.getRandom();
*/















 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









