






背景
阿里云ACK(kubernetes容器服务),高弹性,高稳定性,低成本解决方案。
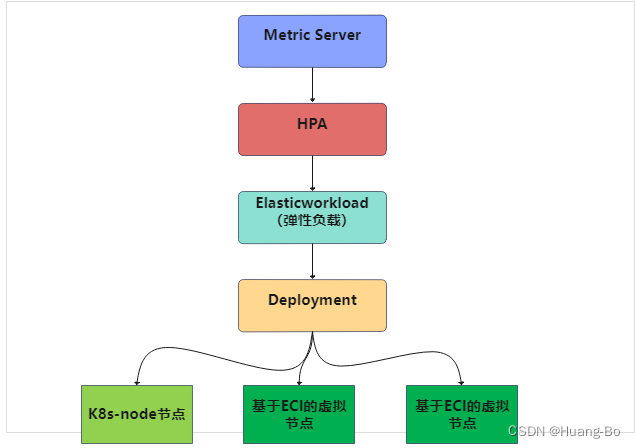
通过将ECI服务以虚拟节点的方式接入ACK容器集群,将集群中pod应用的固定量调度到现有的ACK容器服务的ECS node节点上,将集群中pod应用的弹性量通过ElasticWorkload组件调度的ECI服务的虚拟节点上。
ACK集群默认架构
以ACK容器服务托管版为例
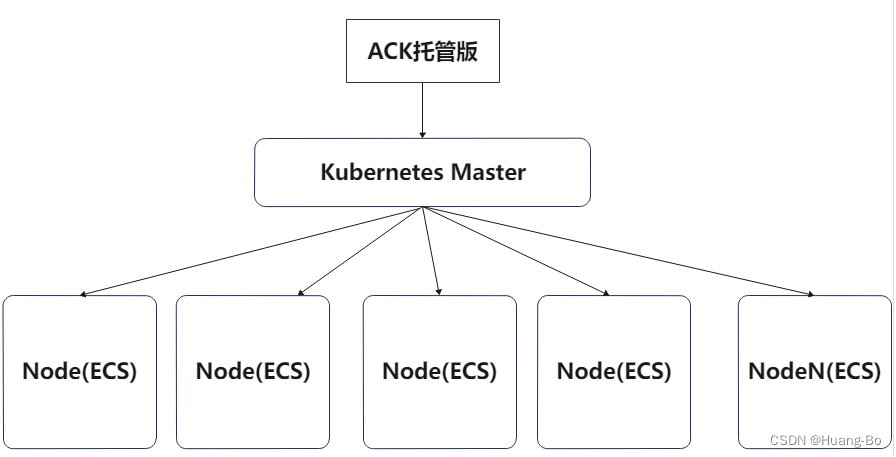
将ECI虚拟节点接入ACK集群后的容器集群架构
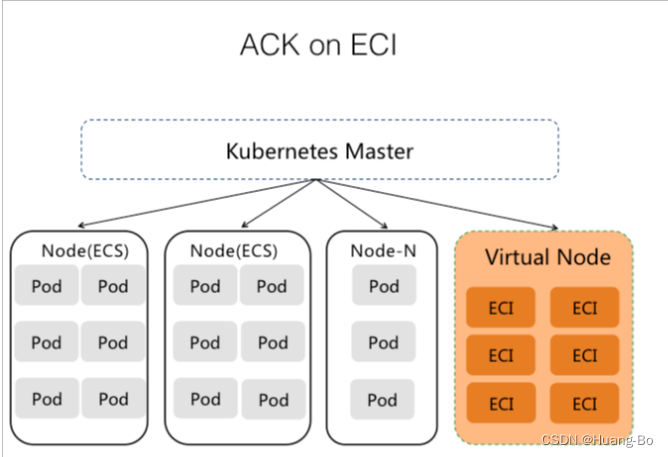
ECI具有以下几个特点
高弹性:快速秒级扩容,可轻松应对百倍突发流量,同时支持HPA及CronHPA。
低成本:根据流量动态使用资源,按需付费。
高可用:精细化应用伸缩,扩容时保留固定N个副本在ECS上运行,第N+1个以上副本调度到ECI;缩容时优先回收ECI上的Pod副本。
兼容性:支持有状态StatefulSet 、无状态Deployment 、任务Job和定时任务CronJob,并且完全兼容Kubernetes。
免运维:不需要管理集群,也不需要管理工作节点,只需要定义应用、服务和任务。
高并发:支持1000/分钟Pod调度能力
创建ECI实例两种方式
指定ECS规格创建ECI实例
参考文档
主要从以下两个方面来优化集群的安全性,稳定性
节点层面
通过设置集群节点弹性伸缩组,来提升ACK容器集群的稳定性,以及高可用性。目的是为了预防集群node节点预留资源不满足pod应用所需资源,从而导致pod应用异常或者集群物理节点被打爆。
具体配置方法
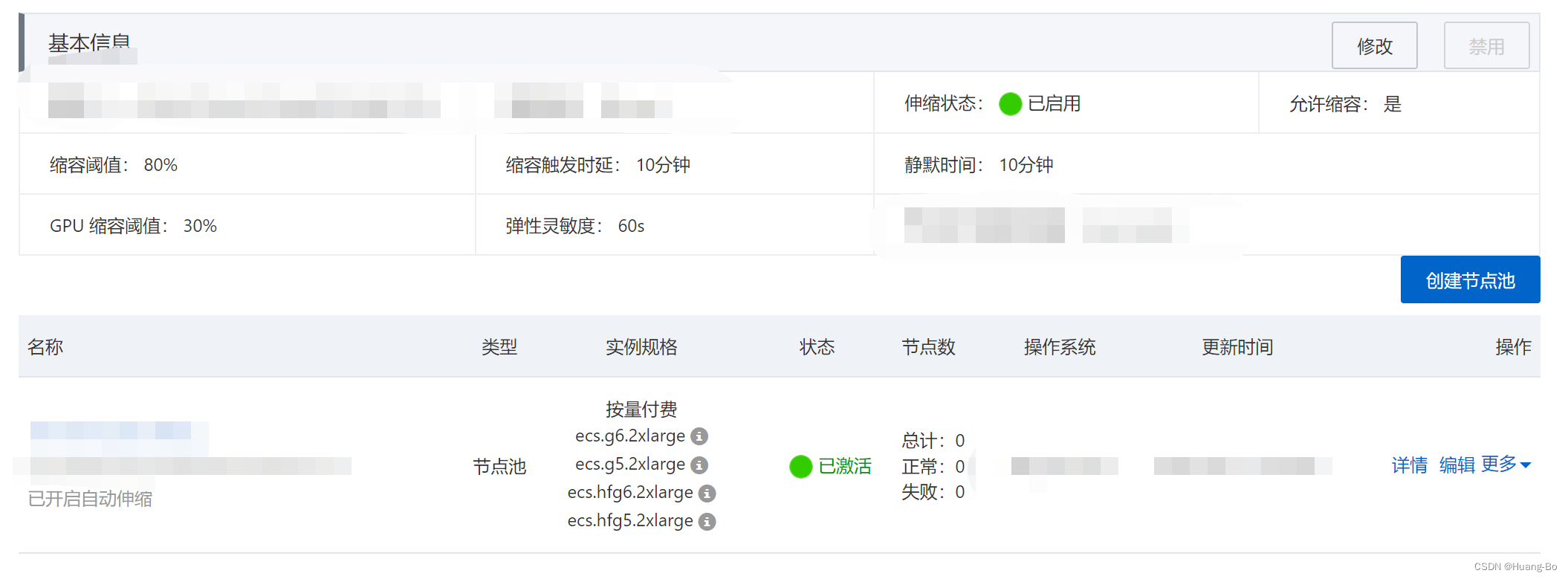
在ACK集群控制台找到我们的k8s集群点击自动伸缩,来创建弹性伸缩组,节点池是基于阿里云ESS弹性伸缩服务,通过事先定义节点实例规格,网络,安全组等再结合容器服务定义的阈值,来实现对节点的弹性伸缩操作
创建节点池以及定义伸缩组阈值
POD层面
通过ACK集群使用ElasticWorkload组件+HPA组件来实现对pod层面的弹性伸缩,集群配置完ECI虚拟节点后,可以通过对ElasticWorkload组件配置来实现将pod调度到ECS node节点上还是ECI 虚拟节点上。
具体实现方法如下:
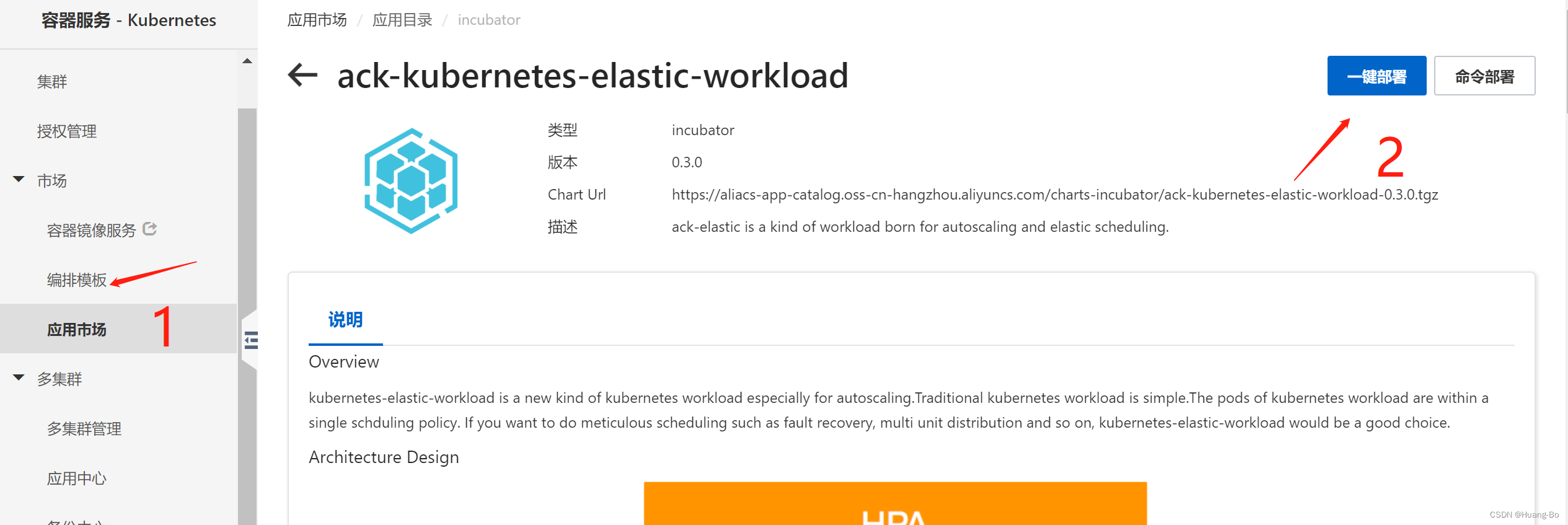
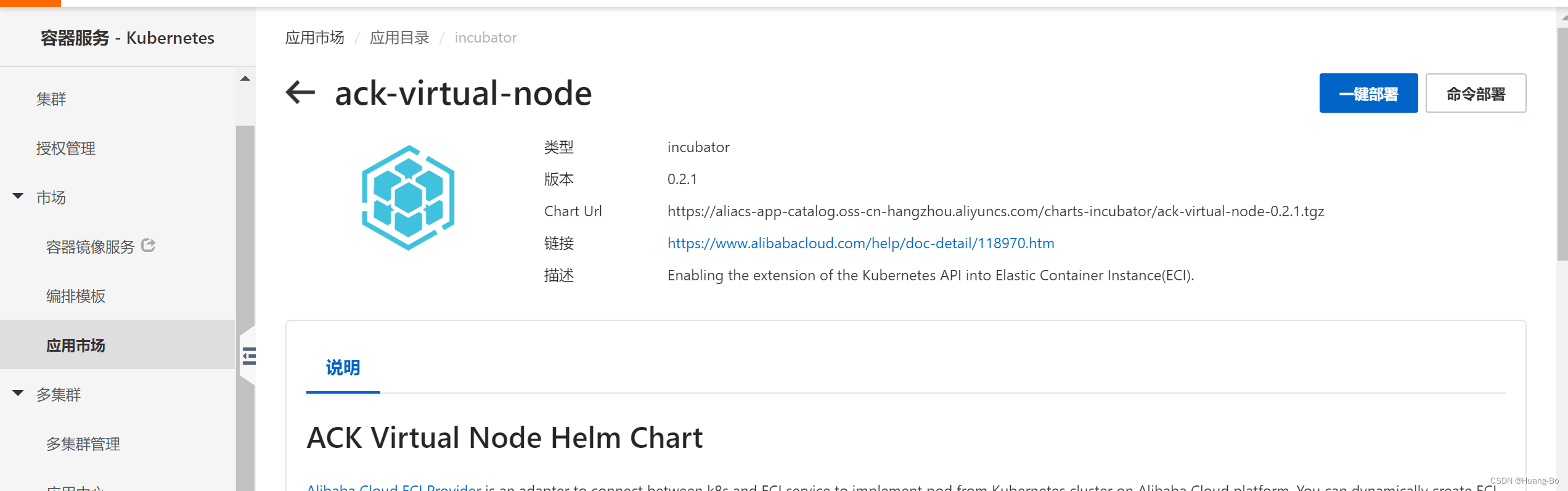
集群安装ack-kubernetes-elastic-workload组件、ACK Virtual Node组件
安装方法:通过阿里云ACK集群的应用市场一键部署或者命令部署安装即可
这两个组件默认都安装在kuber-system名称空间下
HPA+ElasticWorkload调度逻辑
通过ElasticWorkload控制Deployment
HPA控制ElasticWorkload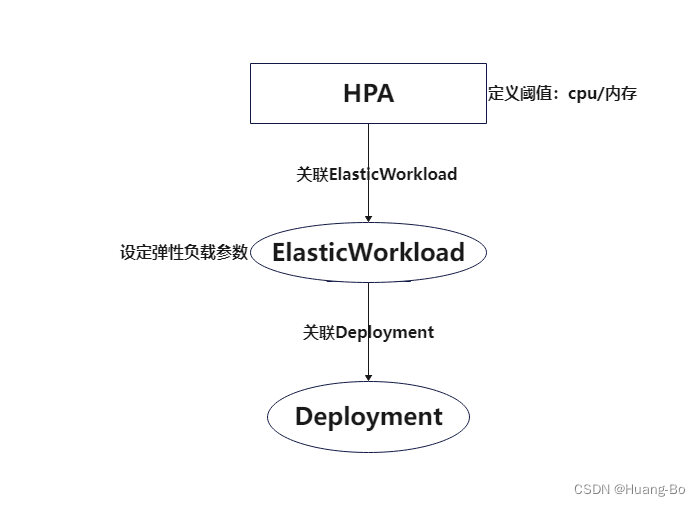
下面通过配置一个应用来实现下具体调度逻辑
ElasticWorkload文件配置如下
[root@k8s-master k8syaml]# cat ew-test-app-demo.yaml
apiVersion: autoscaling.alibabacloud.com/v1beta1
kind: ElasticWorkload
metadata:
annotations:
name: ew-test-app-demo
namespace: vk
spec:
elasticUnit:
- labels:
alibabacloud.com/eci: "true"
name: virtual-kubelet
#默认运行在ecs节点上的副本数量
replicas: 4
sourceTarget:
apiVersion: apps/v1
kind: Deployment
#运行在ecs节点上的最大副本数量,超过默认副本数的话超出量会被调度到虚拟节点
max: 4
min: 4
name: test-app-demo
hpa文件配置
[root@k8s-master k8syaml]# cat scm-vendor-web-hpa.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: test-app-demo
namespace: vk
spec:
scaleTargetRef:
apiVersion: autoscaling.alibabacloud.com/v1beta1
kind: ElasticWorkload
name: ew-test-app-demo
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 6400
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 800
HPA CPU,以及内存阈值计算逻辑(针对于request和limit不是1:1的场景)
容器组当前使用量=pod当前使用量*pod数
HPA统计的pod当前使用量为容器组的平均使用量
容器组平均使用量=所有pod使用量之和
我们可以看到下图当前容器的cpu使用量是190m这个是容器组的平均值
当前使用量百分比=pod当前使用量/容器reques值
如下图所示该应用当前使用量是190m
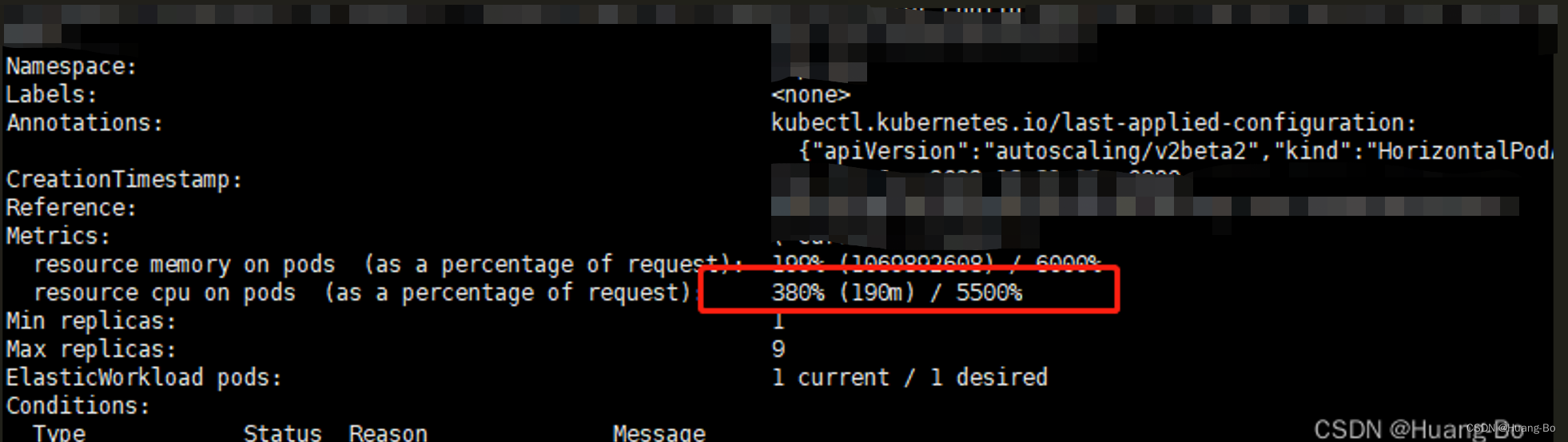
容器request值为0.05转化为毫核就是50m
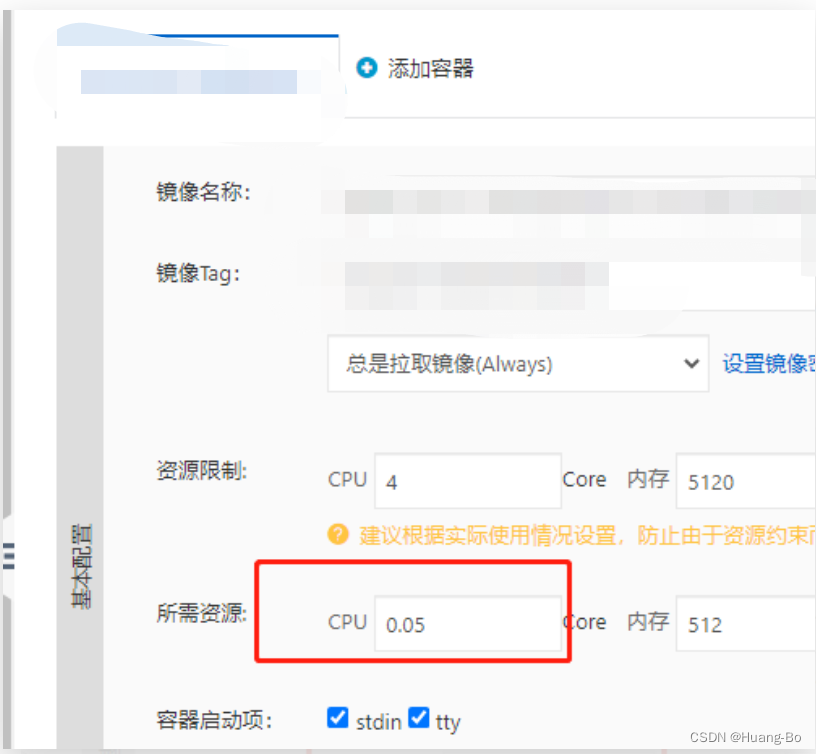
190m/50m=3.8转化为百分比也就是380%(该值为容器组的当前平均使用量)
先把limit单位转化为毫核
(Targets值)容器组总使用量=(limit值/request)*pod数
总Limit值=(4*1000)*4(pod数)=16000mm
总reques值=(0.05*1000)*4(pod数)=200mm
(Targets值)容器组使用量百分比=16000/200=80(转化为百分比就是8000%)
我们设定该应用cpu使用率大于等于百分之八十触发HPA伸缩动作
(Targets值)阈值(80%)=80*0.8=64(转化为百分比就是6400%)
内存计算公式同理
HPA预估POD副本数逻辑
期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)]















 430
430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











