







聚类分析的总结
人们区别事物的方法为:判别方法与聚类方法。
判别方法事先已经知道食物的面貌,也已经知道到底应该分成哪几个类,通过建立函数来判别新出现的事物该被分入哪个类。
聚类方法则什么也不知道。
接下来对聚类分析进行详述:
几个tips:
1.变量越多越好这句话是错的,因为过多的话聚类结果过于复杂了,就失去了其真实含义;
2.能够使用聚类分析的前提是,指标必须有一定的相关关系(这个相关关系不一定要高度相关),反正他们不可以正交;
聚类分析分为样品聚类和变量聚类,前者是将相近的样品放在一起,后者的意思则是挑选出彼此独立并且比较有代表性的指标(有代表性是指能够涵盖大部分的信息,也就是这几个指标贡献了绝大多数的方差)。
下面来谈谈聚类分析的步骤:
1.数据标准化。
针对前文的矩阵,我们计算出每一列的平均值,然后将每一个数字都与对应列平均值作差,除以列对应的方差;
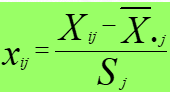
2.挑选点之间的距离的计算方法。
这里就需要我们挑选出适合的距离计算方法了,我们一般默认是欧式距离。
3.类与类之间距离计算?
这里的方法有三种:
两类之间距离最远或者最近的点
两类所有点距离平方的均值
按照某一规则选取点代表某类
聚类分析的几个作法:
凝聚法
分解法
调优法
以下是具体介绍:

但这里我着实很懵,聚类法和分解法意义在哪里啊,我怎么感觉白分了……
算了之后再琢磨。
之后就是两个具体的聚类方法介绍了。
首先是K-means聚类方法。

可以看得出,它其实就是调优法的一种。
要求:1.事先能知道分几类
2.只适合样本分类
3.所使用的变量必须是连续变量
层次聚类法:
分为自上而下的分解法与自下而上的凝聚法。
K均值聚类无要求,但缺点是样本量太大或变量数目较多时,时间过慢了。
接下来是spss操作了。
老师提到了一个前提操作,就是如何处理有缺失指标的样本,有两个方法,第一个是按列表排除个案(Excluded cases listwise)和按对排除个案(Excluded cases pairwise),前者只要一个样本有一个指标缺失就踢掉这个样本,后者是当所有指标缺失就踢掉这个样本。
首先是K-means,我们首先必须得定好分类最终得到几个类。在这里,我们的迭代结束有两个条件,第一,达到了最大迭代次数,即使我们的结果不是最优也不得不结束了;
第二,达到了收敛性标准,自动结束。


第一张图是初始划分的两类中心点的指标,第二张图是迭代的历史记录,横轴为中心点的改变量,如果是零的话就说明没变过了,然后终止了迭代。
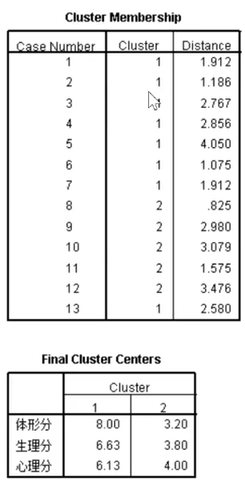
这张图挺简单的,仍然是看看就能明白啦~
最后我们可以用语言简单地描述我们划分出来的两类——优秀的运动员与不优秀的运动员。
层次聚类法:

可以在菜单里选择对变量还是样本聚类,而输出方案也有三种可能性可以选择。
选项一:
输出过程、输出单个方案、输出多个方案
选项二:
将分类结果存成新的一列变量吗
图示?树状图、冰柱图















 1780
1780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









