









我们学校的模式识别大作业,使用任意机器学习方法完成人脸识别并汇报结果。在询问了老师可以使用任意方法包括深度学习之后,果断选用不需要搞任何特征工程的简单的CNN啊。代码基于anaconda2+keras2.0.2+theano0.9
本条博客内容参考了该博客,网络搭建的跟他是同一个网络。
安装配置keras的部分略过,直接进入正题。
一般来说,人脸识别系统包括图像摄取、人脸定位、图像预处理、以及人脸识别(身份确认或者身份查找)。系统输入一般是一张或者一系列含有未确定身份的人脸图像(特征),以及人脸数据库中的若干已知身份的人脸图像或者相应的(特征),而其输出则是一系列相似度得分,表明待识别的人脸的身份。本次大作业主要关注“识别”这一个任务。
首先我们作业使用的数据集是CMU的PIE数据集。
训练集里面有一张比较奇怪的黑白图片可能是为了测试噪声影响?反正10000多就这一张噪声我也没懂。


后面三张在训练集里面是倒着的,在测试集里面也是倒着的,反而不影响。
其中训练集里面分为三种,mat['fea']读取所有的训练特征(图片内容),mat['isTest']为1的表示测试集,mat['gnd']得到所有的标签。做训练之前,我们先把原始的PIE数据集划分出训练集和测试集。代码如下:
def assembleData(filename): #读取一次数据并组合
data = sio.loadmat(filename)
train = data['fea']
labels = data['gnd']
istest = np.where(data['isTest'] == 1)
testIndex = list(istest[0])
t_labels = [] # 本次抽取的测试集
t_train = [] # 本次抽取的测试标签
for i in testIndex: # 抽取测试集和测试标签
t_train.append(train[i, :])
t_labels.append(labels[i][0])
train = np.delete(train, testIndex, axis=0) # 从样本中删除测试集
labels = np.delete(labels, testIndex, axis=0) # 从标签中删除测试标签
trainData.extend(train)
trainLabels.extend(labels[:,0])
testData.extend(t_train)
testLabels.extend(t_labels) filelist=["PIE dataset\Pose05_64x64.mat","PIE dataset\Pose07_64x64.mat","PIE dataset\Pose09_64x64.mat","PIE dataset\Pose27_64x64.mat","PIE dataset\Pose29_64x64.mat"]
for file in filelist:
assembleData(file)
trainData=np.array(trainData)
trainLabels=np.array(trainLabels)
testData=np.array(testData)
testLabels=np.array(testLabels)接下来我们搭建并编译(compile)一个网络并进行训练,这里有两种方式,一种方式是使用全部的训练集进行训练,另外一种方式是在训练集中划分一部分作为验证集(validation),不参与训练仅仅用来调整网络参数用。事实证明,这个数据集对于深度学习来讲还是小了点,差异性很小,如果去掉了一部分作为验证集不参与训练的话,训练出来的网络在测试集上表现会差一些(精度差1%~4%的样子)。完整的代码如下:
#coding=utf-8
import scipy.io as sio
import numpy as np
import pickle
import os
from sklearn.cross_validation import train_test_split
import seaborn
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
#from keras.optimizers import SGD
import keras.optimizers as optimizers
from keras.utils import np_utils
# 实际训练数据标签是1-68,,68个类
nb_classes = 69 #添加一个虚类0,这样不用labels可以直接用,不用每个类编号-1。
nb_epoch = 80 #迭代周期,这是取的最大的
batch_size = 40 #每批次样本数
lr=0.002 #学习率
decay=1e-6 # 学习率衰减
momentum=0.9 #冲量
# input image dimensions
img_rows, img_cols = 64, 64 #图片的行列数
# number of convolutional filters to use
nb_filters1, nb_filters2 = 5, 10 #卷积核数目
# size of pooling area for max pooling
nb_pool = 2 #池化大小
# convolution kernel size
nb_conv = 3 #卷积核大小
trainData=[]
trainLabels=[]
testData=[]
testLabels=[]
def assembleData(filename): #读取一次数据并组合
data = sio.loadmat(filename)
train = data['fea']
labels = data['gnd']
istest = np.where(data['isTest'] == 1)
testIndex = list(istest[0])
t_labels = [] # 本次抽取的测试集
t_train = [] # 本次抽取的测试标签
for i in testIndex: # 抽取测试集和测试标签
t_train.append(train[i, :])
t_labels.append(labels[i][0])
train = np.delete(train, testIndex, axis=0) # 从样本中删除测试集
labels = np.delete(labels, testIndex, axis=0) # 从标签中删除测试标签
trainData.extend(train)
trainLabels.extend(labels[:,0])
testData.extend(t_train)
testLabels.extend(t_labels)
def splitData():#划分训练集与验证集
train_x,val_x,train_y,val_y = train_test_split(trainData,trainLabels,test_size=0.3, random_state=1) # 划分训练集与验证集
rval = [(train_x, train_y), (val_x, val_y)]
return rval
def Net_model(lr=lr, decay=decay, momentum=momentum):#建立并编译模型
model = Sequential() #贯序模型
model.add(Conv2D(nb_filters1, (nb_conv, nb_conv),
padding='valid',
kernel_initializer='glorot_normal',
input_shape=(1, img_rows, img_cols),name='Conv2D_1'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
model.add(Conv2D(nb_filters2, (nb_conv, nb_conv)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
# model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1000)) # Full connection
model.add(Activation('relu'))
# model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
sgd = optimizers.SGD(lr=lr, decay=decay, momentum=momentum, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd,metrics=['accuracy'])
return model
def train_model(model, X_train, Y_train, X_val, Y_val):#训练模型,返回训练过程记录
history=model.fit(X_train, Y_train, batch_size=batch_size, epochs=nb_epoch,verbose=2, validation_data=(X_val, Y_val))
return history
def getBesthistoryacc():#读取最好的结果
read_file = open('bestacc.pkl', 'rb')
best = pickle.load(read_file)
read_file.close()
return best
def saveHistory(history):#没啥卵用,打印history包括的东西的
# write_his = open('history', 'wb')
# pickle.dump(history.history['acc'], write_his, -1)
# pickle.dump(history.history['val_acc'], write_his, -1)
# write_his.close()
print(history.history.keys())
def displayHistory(history,mode=1):#显示训练过程的loss变化
print(history.history.keys())
write_his= open('history', 'wb')
if mode>0:
plt.plot(history.history['acc'])
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.legend(['acc', 'loss'], loc='upper left',fontsize='x-large')
# summarize history for acc
if mode>1:#有验证集
plt.plot(history.history['val_acc'])
plt.plot(history.history['val_loss'])
plt.legend(['acc', 'loss','val-acc', 'val-loss'], loc='upper left',fontsize='x-large')
plt.show()
write_his.close()
def loadModelAndPredict():#加载已训练的模型权重并进行预测
model.load_weights('model2_weights.h5')
classes = model.predict_classes(X_test, verbose=1)
test_accuracy = np.mean(np.equal(testLabels, classes))
print("accuracy:", test_accuracy)
if __name__ =="__main__":
filelist=["PIE dataset\Pose05_64x64.mat","PIE dataset\Pose07_64x64.mat","PIE dataset\Pose09_64x64.mat","PIE dataset\Pose27_64x64.mat","PIE dataset\Pose29_64x64.mat"]
for file in filelist:
assembleData(file)
trainData=np.array(trainData)
trainLabels=np.array(trainLabels)
testData=np.array(testData)
testLabels=np.array(testLabels)
(X_train, Y_train), (X_val, y_val) = splitData()
print ("X_train:",X_train.shape)
print ("Y_train:",Y_train.shape)
print ("X_val:",X_val.shape)
print ("y_val:",y_val.shape)
X_train = X_train.reshape(X_train.shape[0], 1, img_rows, img_cols) #输入是样本数、通道数、行列数
X_val = X_val.reshape(X_val.shape[0], 1, img_rows, img_cols)
X_test = testData.reshape(testData.shape[0], 1, img_rows, img_cols)
X_train = X_train.astype('float32')
X_val =X_val.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_val /= 255
X_test /= 255
print(X_train.shape[0], 'train samples')
print(X_val.shape[0], 'validate samples')
print(X_test.shape[0], 'test samples')
Y_train = np_utils.to_categorical(Y_train,nb_classes)#贯序模型多分类keras要求格式为binary class matrices,转化一下(就是转化为分类矩阵,Kij=1表示i个样本分为第j类)
Y_val = np_utils.to_categorical(y_val,nb_classes)
Y_test = np_utils.to_categorical(testLabels,nb_classes)
#
print Y_train.shape
print Y_val.shape
print Y_test.shape
model = Net_model()
history = train_model(model, X_train, Y_train,X_val,Y_val)
classes = model.predict_classes(X_test, verbose=1)#立即预测结果
test_accuracy = np.mean(np.equal(testLabels, classes))
print("accuracy:", test_accuracy)
if os.path.exists('bestacc.pkl'):#保存预测结果
read_file = open('bestacc.pkl', 'rb')
bestacc = pickle.load(read_file)
read_file.close()
if(bestacc<test_accuracy):
write_file = open('bestacc.pkl', 'wb')
pickle.dump(test_accuracy, write_file, -1)
model.save_weights('model2_weights.h5', overwrite=True)
write_file.close()
else:
write_file = open('bestacc.pkl', 'wb')
pickle.dump(test_accuracy, write_file, -1)
model.save_weights('model2_weights.h5', overwrite=True)
write_file.close()
displayHistory(history, mode=2)
best=getBesthistoryacc()
print("best accuracy:",best)
基本跟我参考的博客参数弄的是一样的(后面实验也会证明,这个参数基本上是这个网络跑在这个小的人脸识别数据集上的最优参数)。加了一点点初始化权重的方式改变,激活函数改了一下(其实没必要改,relu收敛更快,但是这收敛已经很快了)以及加入了一点训练过程中评价输出,然后数据不一样,显示了训练过程。编译网络和训练网络也是一样的。只是我加入了最佳结果保存的函数。
网络结构图大概是这样:
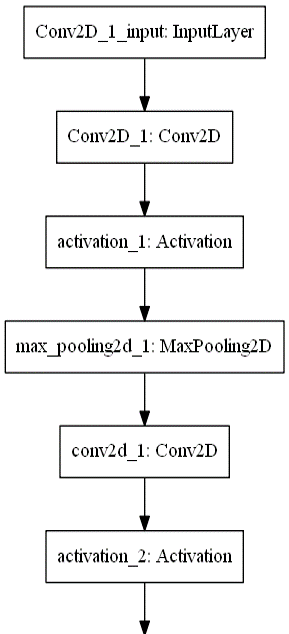
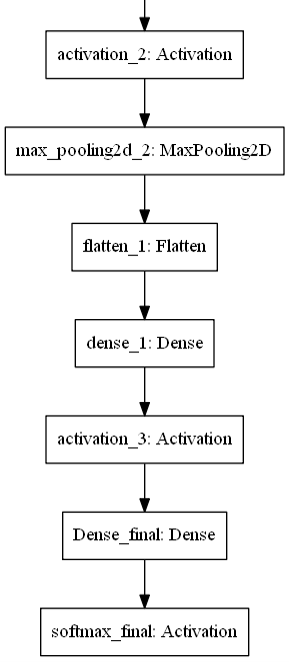
基本上就是个LeNet,只是一些参数不一样,然后少了点防止过拟合的dropout层。
参数设置,最后的实验结果表明的最优参数:
这个是我的代码里面的prhomework2-LeNet-validation.py,也就是划分训练集的,最高精度的模型其实是拿不划分训练集的prhomework2-withoutval.py跑出来的,然后代码里面还有prhomework2-test.py用来加载训练好的权重,直接进行测试,并且在里面也加入了一些代码可以输出一些中间层的结果用来进行试验分析。plotfigure.py是我用来记录实验结果并画各种图的脚本。
最后展示一下结果:在PIE上跑,最高精度是99.45%。还有个小的ORL的精度就不是很高,在97.5%。在划分和不划分的训练集上训练过程如下:
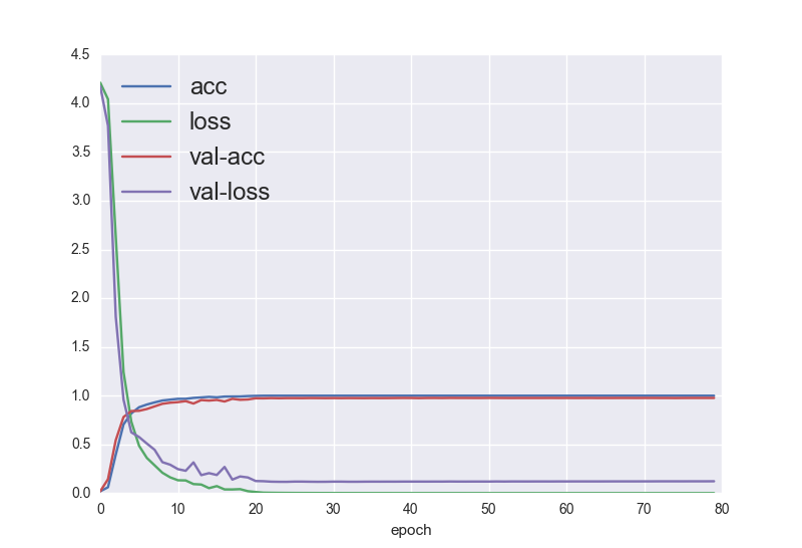
上图是划分训练集,大概20个批次收敛。
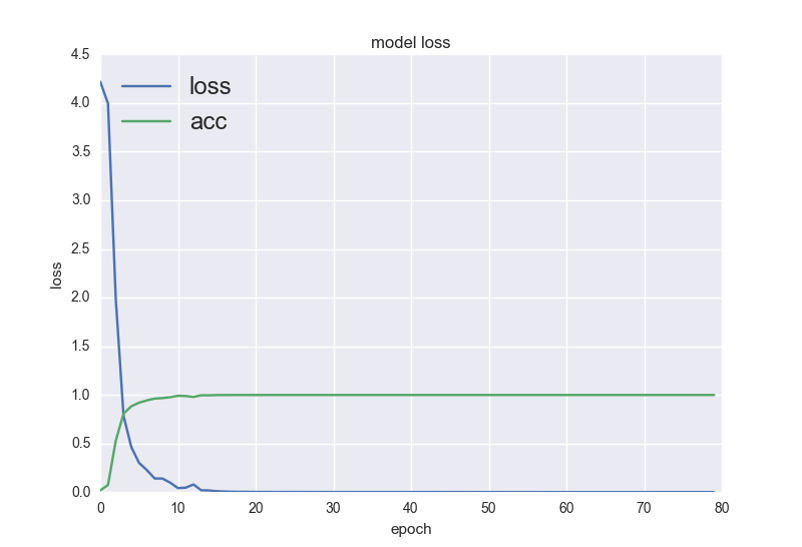
无验证集下收敛似乎更快一点,最后模型精度也高一点点(1%)。然后又画了画68个类的P、R、以及F1值:
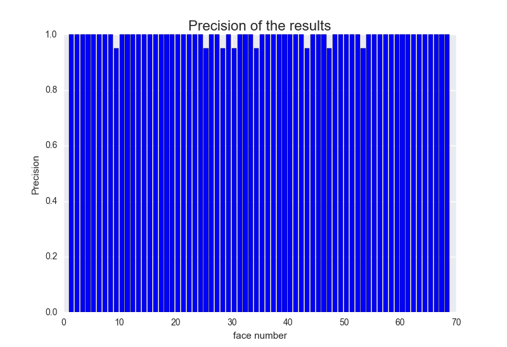
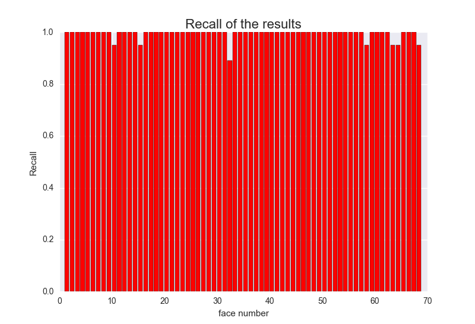
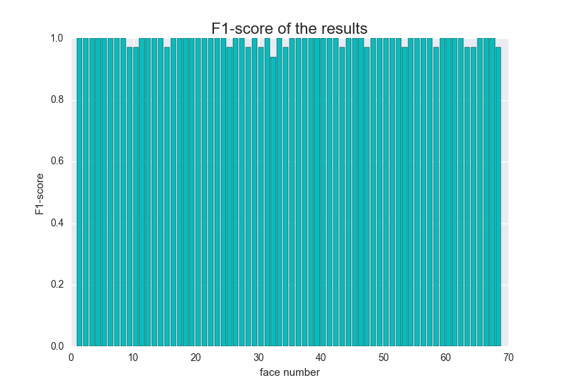
可以看到,好多类的P、R、F1值都是1,这意味着这几类完全正确,没有任何漏分或者错分的情况,还是比较稳的= =。最后看一下分错的几张图片:

共同特点就是都是闭眼的:那么我们可以理解为,这个LeNet在PIE数据集上提取出来的特征,有一个可能更加类似“眼睛”这种有点带旋转不变性的特征权重比较高。
我同学用的传统方法做,做之前发觉有些人脸灰度不同(有些太暗),所以他做了个直方图均衡化过后的结果,类似于下面的效果:


然后我把他的数据借来跑了跑,发现精度只有98%出头,也就是比原来不做任何预处理的结果还低一点。所以就这次实验来说,这个简单的LeNet结果可以总结如下:
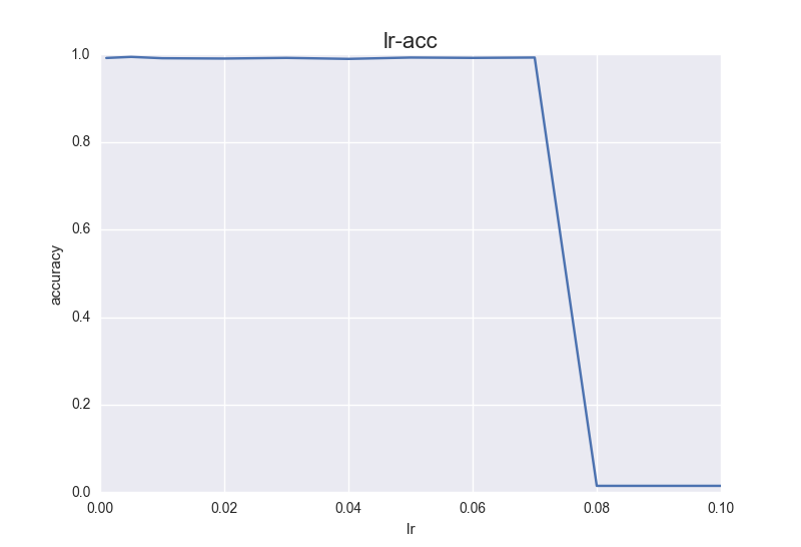
首先,采用的批量梯度下降算法训练,所以试了试lr的影响,这里真的是神奇,就改lr一个参数,从0.001开始,取0.005,0.01,0.02,0.03……直到0.1一直慢慢调大,结果前面精度都差不多,至少也在98%以上,在0.08的时候突然下降到了14.5%…而且训练再也没有收敛过,一直都是14.5%,想不通为什么,难道就因为这0.01学习率变化导致一直震荡没办法取最小值?可是这精度降得太多了啊,我感觉是theano的bug……如果有谁知道为什么,一定请给我留言!!!
看看其他参数影响:
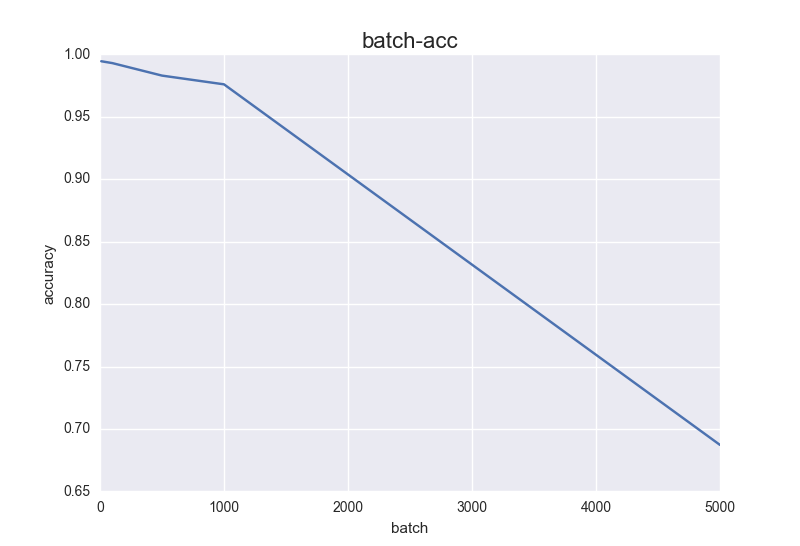
基本符合预期,随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。(当然在这个任务上不多,只是我限制了只迭代80次),batch_size太大的话,还可能导致一系列问题,比如样本差异不那么大,但是标签不同,可能学不到什么东西,过大的batchsize的结果是网络很容易收敛到一些不好的局部最优点……反正这个也是个玄学调参,不同数据集batch_size不同,尽量大,别太大(当然显存一般不允许我们设置过大的batch)。
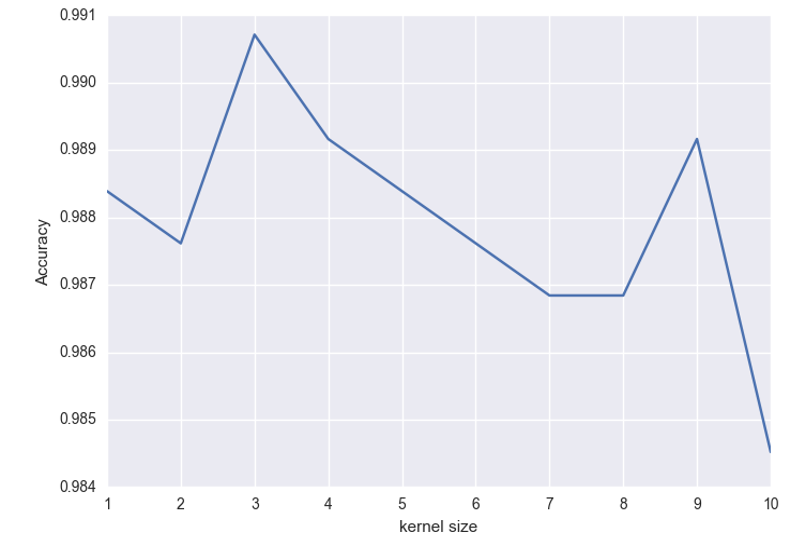
卷积核大小的影响:尽量选择小点的卷积核吧
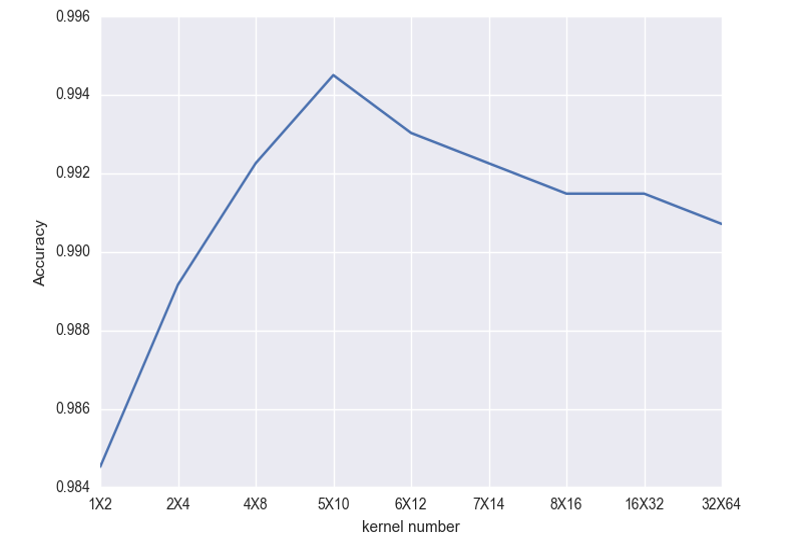
卷积核数目的影响:只要先小后大,好像都还可以…影响不是很大,横坐标的MxN表示第一层卷积层卷积核M个,第二层卷积层卷积核N个。
最后,用到的代码打包放在我的csdn资源里面免费下载,用到的CMU的PIE数据集放在网盘里面提供下载。















 2782
2782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









