







1. 在Windows平台下搭建Spark开发环境(Intellij IDEA+Maven)
1.1 集成开发环境IDE
为了方便应用程序开发与测试,提高开发效率,一般使用集成开发工具IDE。同样,为了方便Spark应用程序编写和测试,可以选择集成开发工具Intellij IDEA或Eclipse。由于Intellij IDEA对Scala更好的支持,大多Spark开发团队选择了Intellij IDEA作为开发环境。
1.2 安装JDK
在实际生产环境下,首先是在Windows平台进行应用程序编写和调试,然后,程序编译后发布到服务器端运行。所以,这里需要介绍的是Windows平台下JDK8的安装与配置。
(1)下载
登录Oracle官网http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html,接受协议,选择对应版本。因为我的本机是64位Windows,所以需要下载64位(Windows x64)JDK安装包。

Windows下安装JDK非常方便,双击安装程序后,直接单击下一步即可,默认安装到D:\Program Files\Java目录下。其间会安装JRE,默认一下步即可。
(3)设置环境变量
右键单击桌面上的“计算机”图标(在Windows10下是“此电脑”),在弹出的右键快捷菜单中选择最后一个“属性”选项;在弹出的系统窗口中,单击左侧“高级系统设置”选项,弹出“系统属性”对话框,如下图。



新建CLASS_PATH,如下图:

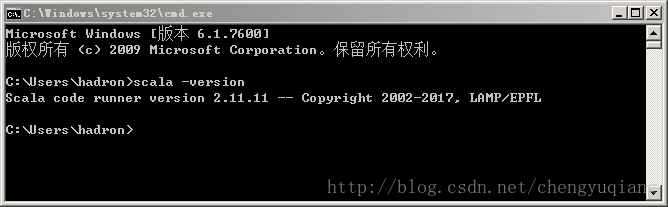
检验配置是否成功,在cmd中运行java -version出现以下结果则说明jdk安装配置成功

1.3 安装Scala
(1)下载
通过Spark官网下载页面http://spark.apache.org/downloads.html 可知“Note: Starting version 2.0, Spark is built with Scala 2.11 by default.”,建议下载Spark2.2对应的 Scala 2.11。
登录Scala官网http://www.scala-lang.org/,单击download按钮,然后再“Other Releases”标题下找到“Last 2.11.x maintenance release - Scala 2.11.11”链接
进入http://www.scala-lang.org/download/2.11.11.html页面,下拉找到如下图内容,下载msi格式的安装包即可。 
(2)安装
默认安装到C:\Program Files (x86)\scala目录下 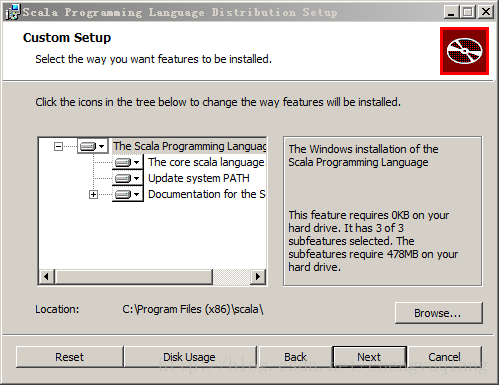
(3)环境变量
与设置Java环境变量类型,
SCALA_HOME=C:\Program Files (x86)\scala
Path环境变量在最后追加;%SCALA_HOME%\bin
1.4 安装Maven
Maven的安装与配置请参考:
https://blog.csdn.net/haijiege/article/details/80798936
(一般新版本的Intellij IDEA都会自带Maven,也可以自己安装与配置)
1.5 Intellij IDEA下载与配置
(1)下载与安装
登录官网https://www.jetbrains.com/idea/download/,按照自己的需求下载(ultimate,旗舰版)或者(Community,社区版)。Ultimate版本是商业软件,需要付费,Community 版为免费版,足够平时日常开发需要。比如这里直接下载Community
 。
。
安装完成后,单击IntelliJ IDEA图标即可启动IntelliJ IDEA.
(3)导入设置
由于是第一次安装,所以不需要导入配置。默认选项即可。
(4)选择“Evaluate for free”进入免费版
(5)可以根据自身的习惯选择风格,并点击左下角“Skip Remaining and Set Default”



(6)安装scala插件
点击左下角:Configure->Plugins

然后我们点击Install JetBrain Plugins 如下图

搜索并安装scala

安装完成后重启IDEA,否则无法配置全局scala SDK
(7)配置JDK
首先打开Project Structure,如下图

然后我们添加上文安装的JDK,配置完成后点击OK,如下图:

(7)配置JDK 配置全局scala SDK
选中“Global Libraries”,点击“+”号,在弹出的菜单中选中“Scala SDK”,如下图:

在弹出的“Select JAR's for the new Scala SDK”中选择与本机scala版本一致的Version,在这里由于我的scala版本是2.11 所以我选择的是2.11.8版本

点击右下角OK完成配置
1.6 创建Maven项目
(1)单击“Create New Project”

选择maven
注意:如果是第一次利用maven构建scala开发spark环境的话,这里面的会有一个选择scala SDK和Module SDK的步骤,这里路径选择你安装scala时候的路径和jdk的路径就可以了

点击Next,填写GroupID和ArtifactID

点击Next,如下图:

点击Finish,如下图:(在此步骤可以更改Content root 和 Module file location 的路径)

将scala框架添加到项目(若不设置有可能无法创建 scala class)
在IDEA启动后进入的界面中,可以看到界面左侧的项目界面,已经有一个名称为simpleSpark的工程。请在该工程名称上右键单击,在弹出的菜单中,选择Add Framework Surport ,在左侧有一排可勾选项,找到scala,勾选即可

将项目文件设置为source root ,选中scala–>右键快捷菜单–>Mark Directory as –>Sources root

1.7 编辑代码
(1)pom.xml
Spark2.2 Maven库请参见 http://mvnrepository.com/artifact/org.apache.spark/spark-core_2.10/2.2.0
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.jie_h</groupId>
<artifactId>simpleSpark</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.2.0</spark.version>
</properties>
<repositories>
<repository>
<id>nexus-aliyun</id>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</repository>
</repositories>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core_2.10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.3</version>
<configuration>
<classifier>dist</classifier>
<appendAssemblyId>true</appendAssemblyId>
<descriptorRefs>
<descriptor>jar-with-dependencies</descriptor>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
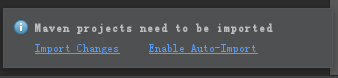
</project>保存pom.xml文件后,如果Intellij IDEA右下角出现如下提示,请单击“Enable Auto-Import”
(2)新建Scala Class类WordCount.scala,Scala源文件后缀名是.scala
通过右键刚刚设置为sources root的scala文件夹,就有了new->scala class的选项。
我们新建一个scala class,并且命名WordCount,选择object类型

打开建好的WordCount.scala文件,清空!然后黏贴以下代码:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "D:\\data\\Hamlet.txt"
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}1.8 数据文件
从网络上下载一部文本格式的小说,比如Hamlet.txt,存放到D:\data目录。
1.9 运行
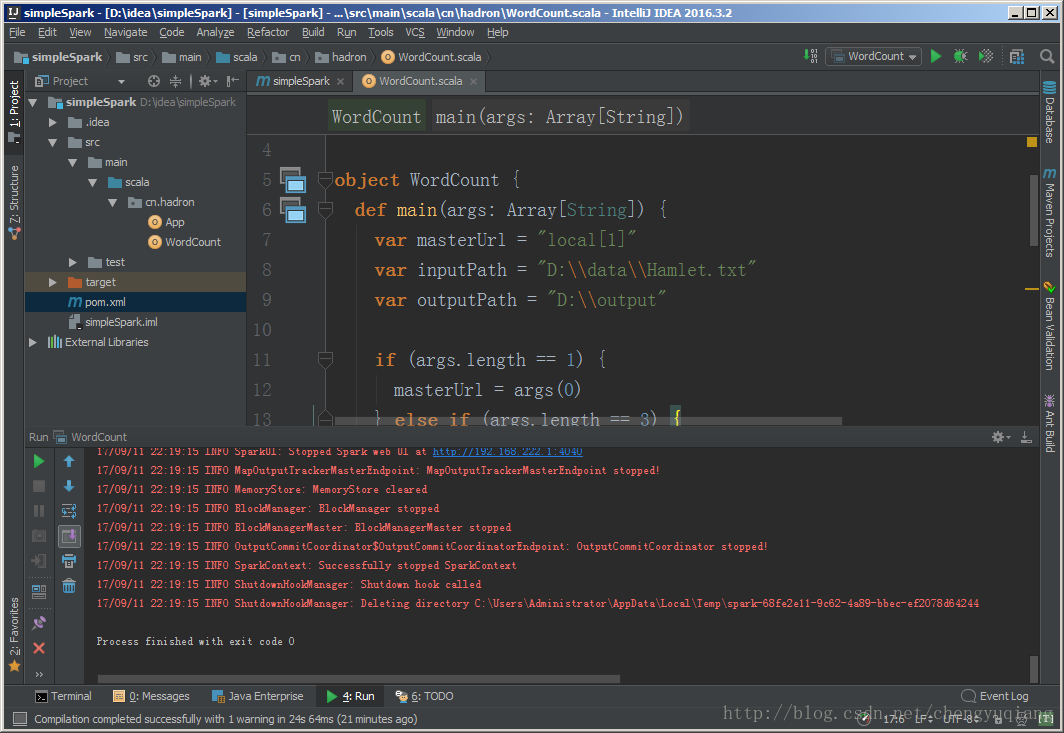
在源文件代码中右键单击–>Run “WordCount”


2.打包WordCount程序的jar包
首先打开File->ProjectStructure
然后选择Artifacts->绿色加号->Jar->Frommoduleswith dependencies…
选择Main Class,
然后因为我们只是在Spark上运行的,相关jar包都存在为了减小jar包的体积,所以我们要删除下图红框里多余的部分,保留WordCount.jar以及‘WordCount’ compile output。(小提示,这里可以利用Ctrl+A全选功能,选中全部选项,然后,配合Crtl+鼠标左键进行反选,也就是按住Ctrl键的同时用鼠标左键分别点击WordCount.jar和‘WordCount’compile output,从而不选中这两项,最后,点击页面中的删除按钮(是一个减号图标),这样就把其他选项都删除,只保留了WordCount.jar以及‘WordCount’ compile output。)
然后我们点击Apply,再点击OK,
接着我们就可以导出Jar包了。选择Build->Build Artifacts…,在弹出的窗口选择Bulid就可以了。
导出的Jar包会在工程文件“/home/wordcount/”目录下的“out/artifacts/WordCount_jar”目录下。我们把他复制到/home/hadoop目录下。也就是主文件夹目录下,
实际上,可以用命令来复制WordCount.jar文件,请打开一个Linux终端,输入如下命令:
1. cd ~
2. cp /home/hadoop/WordCount/out/artifacts/WordCount_jar/WordCount.jar/home/hadoop
Shell命令
然后我们在终端执行以下命令,运行Jar包:
1. cd ~
2. /usr/local/spark/bin/spark-submit--class WordCount /home/hadoop/WordCount.jar
Shell命令
运行结果如下(输出的信息较多请上下翻一下就能找到),要求还是跟上述一样要有那个文件存在。
到此我们就完成了本次的任务了。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









