






今天是第2天,由于后台小哥哥忘了处理算力申请,所以继续用CPU的系统学习。
今天学习了:03-张量+04-数据集+05-数据变换。
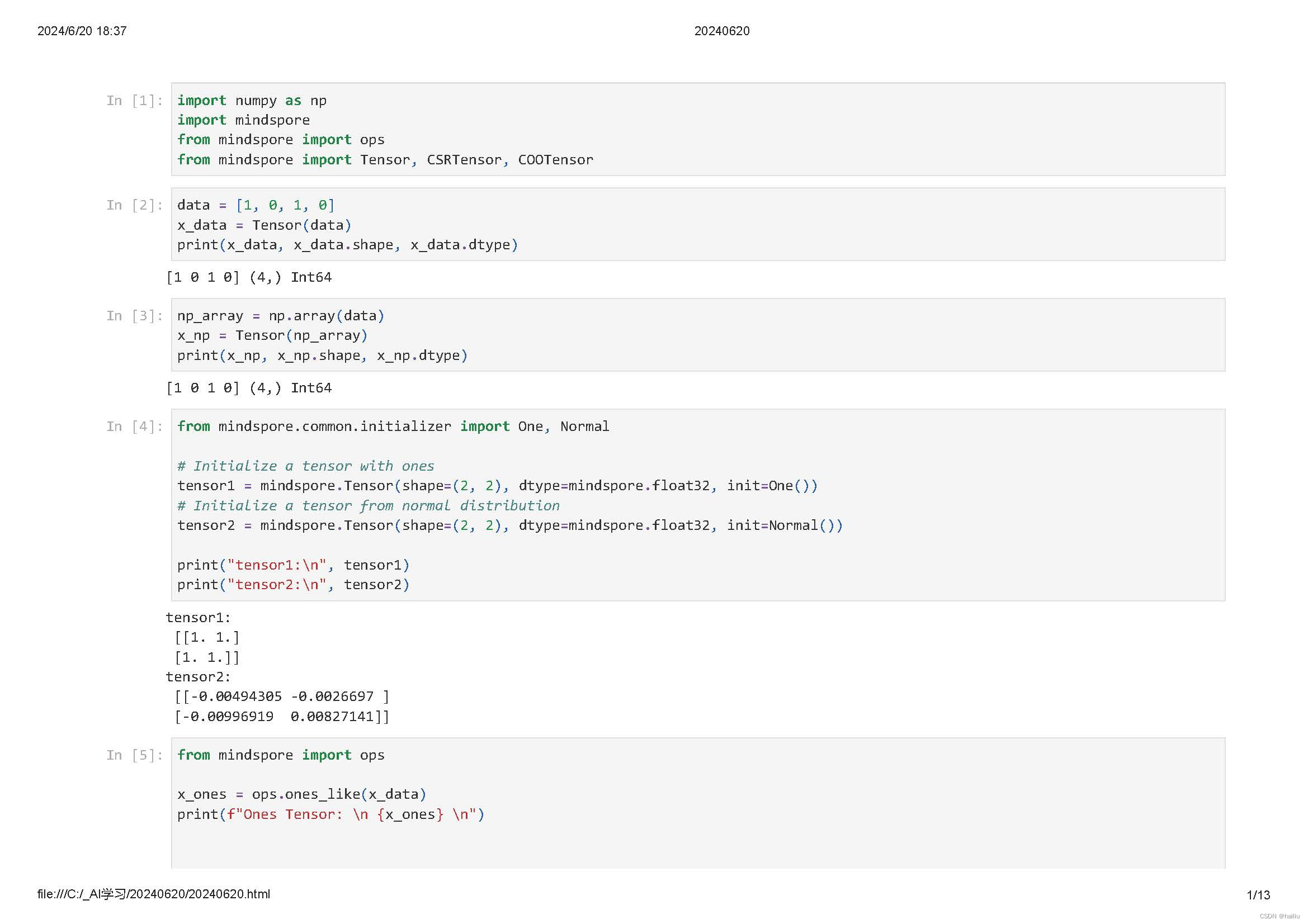
张量(Tensor)是一个可用来表示在一些矢量、标量和其他张量之间的线性关系的多线性函数,这些线性关系的基本例子有内积、外积、线性映射以及笛卡儿积。
Tensor可以和NumPy进行互相转换。
张量的属性包括形状、数据类型、转置张量、单个元素大小、占用字节数量、维数、元素个数和每一维步长。
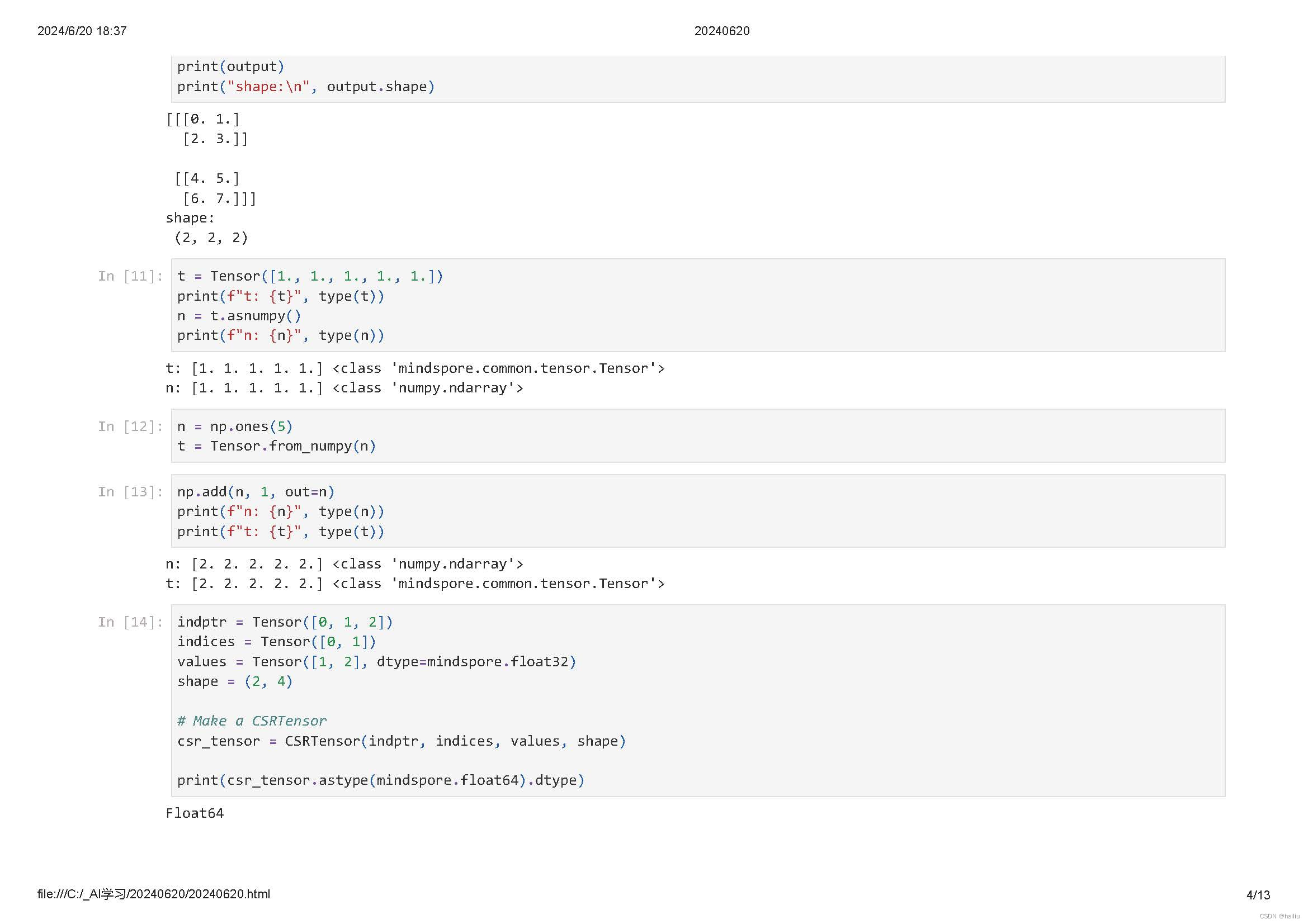
稀疏张量是一种特殊张量,其中绝大部分元素的值为零。
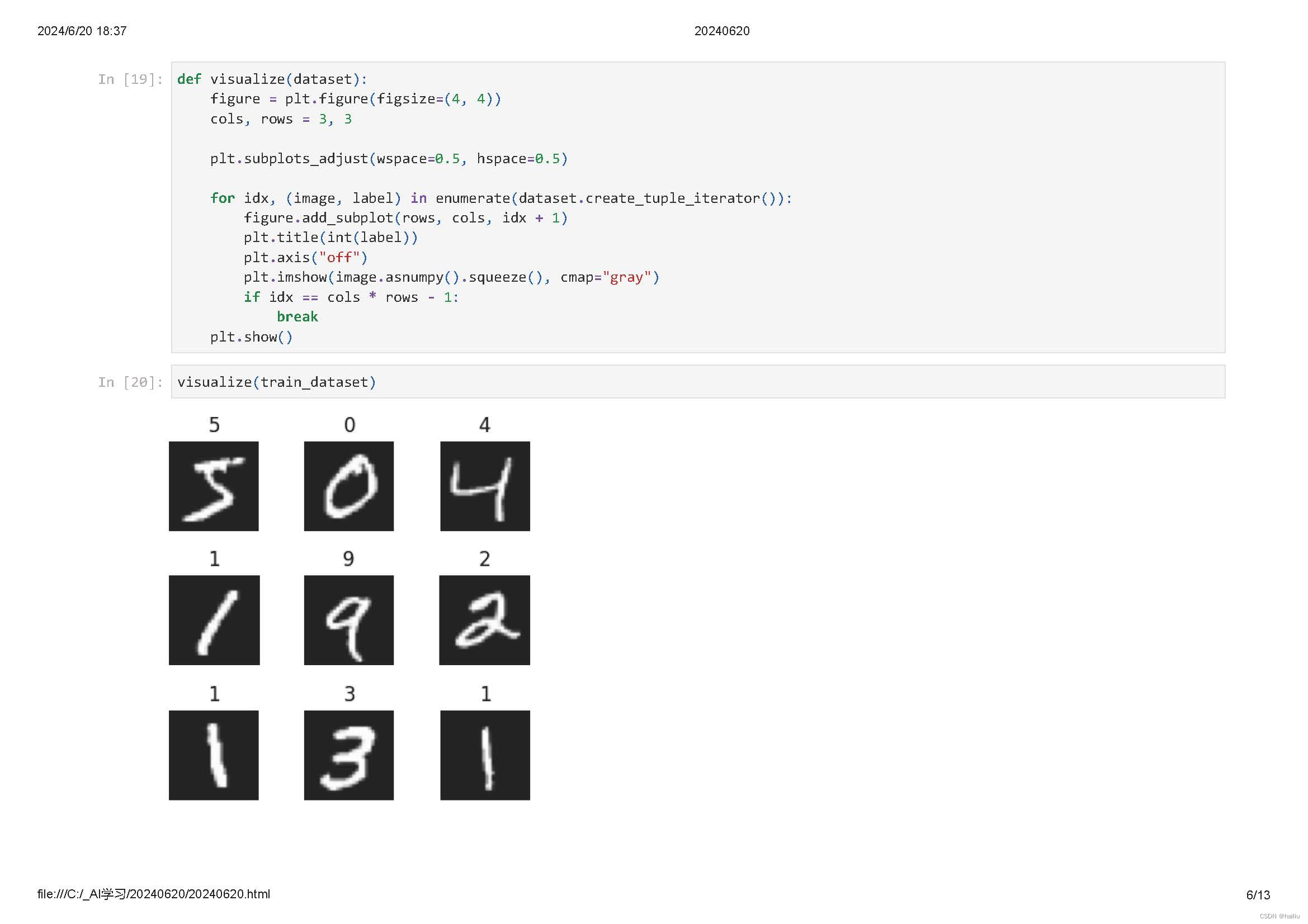
mindspore.dataset提供了内置的文本、图像、音频等数据集加载接口,并提供了自定义数据集加载接口。
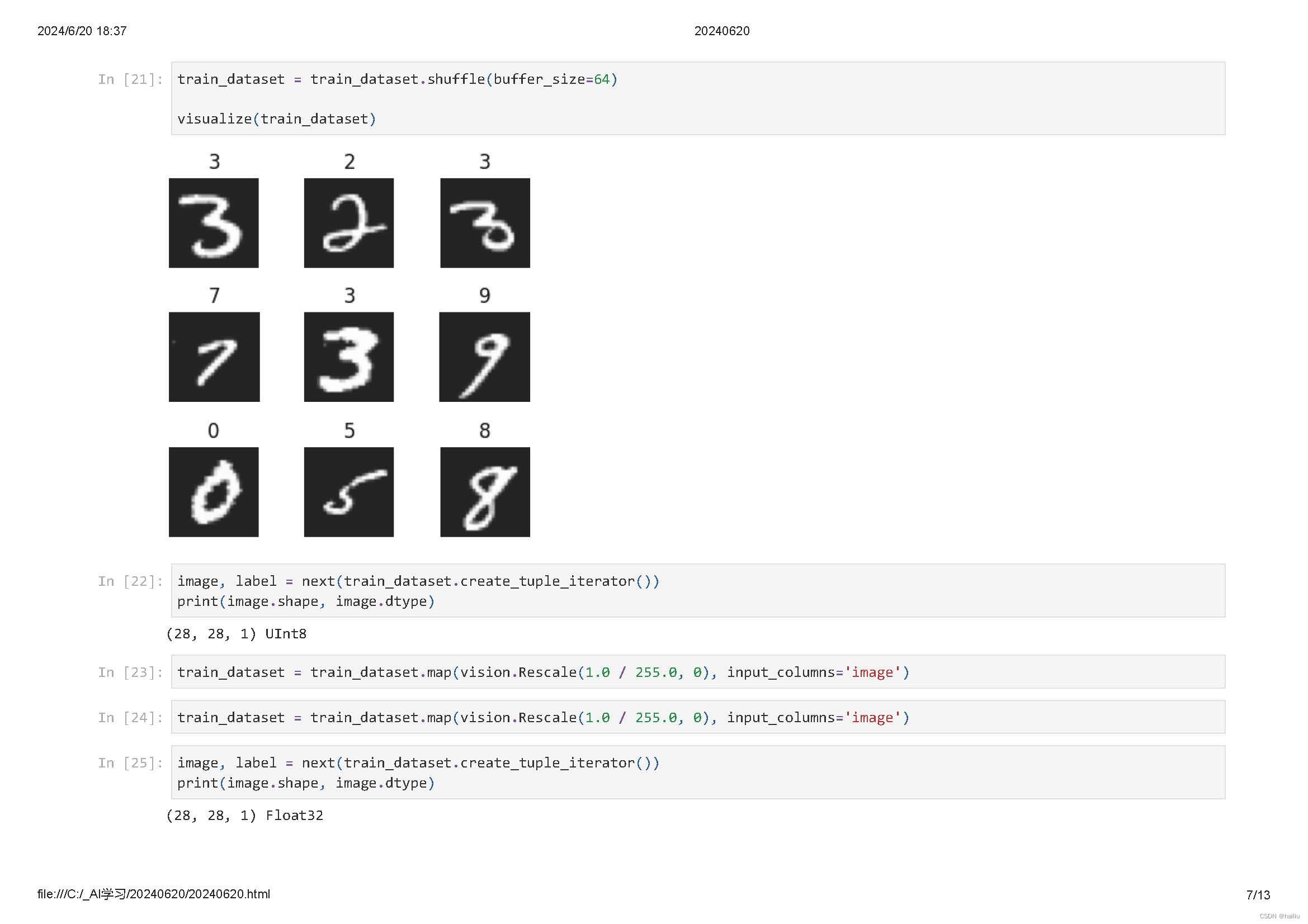
数据集随机shuffle可以消除数据排列造成的分布不均问题。
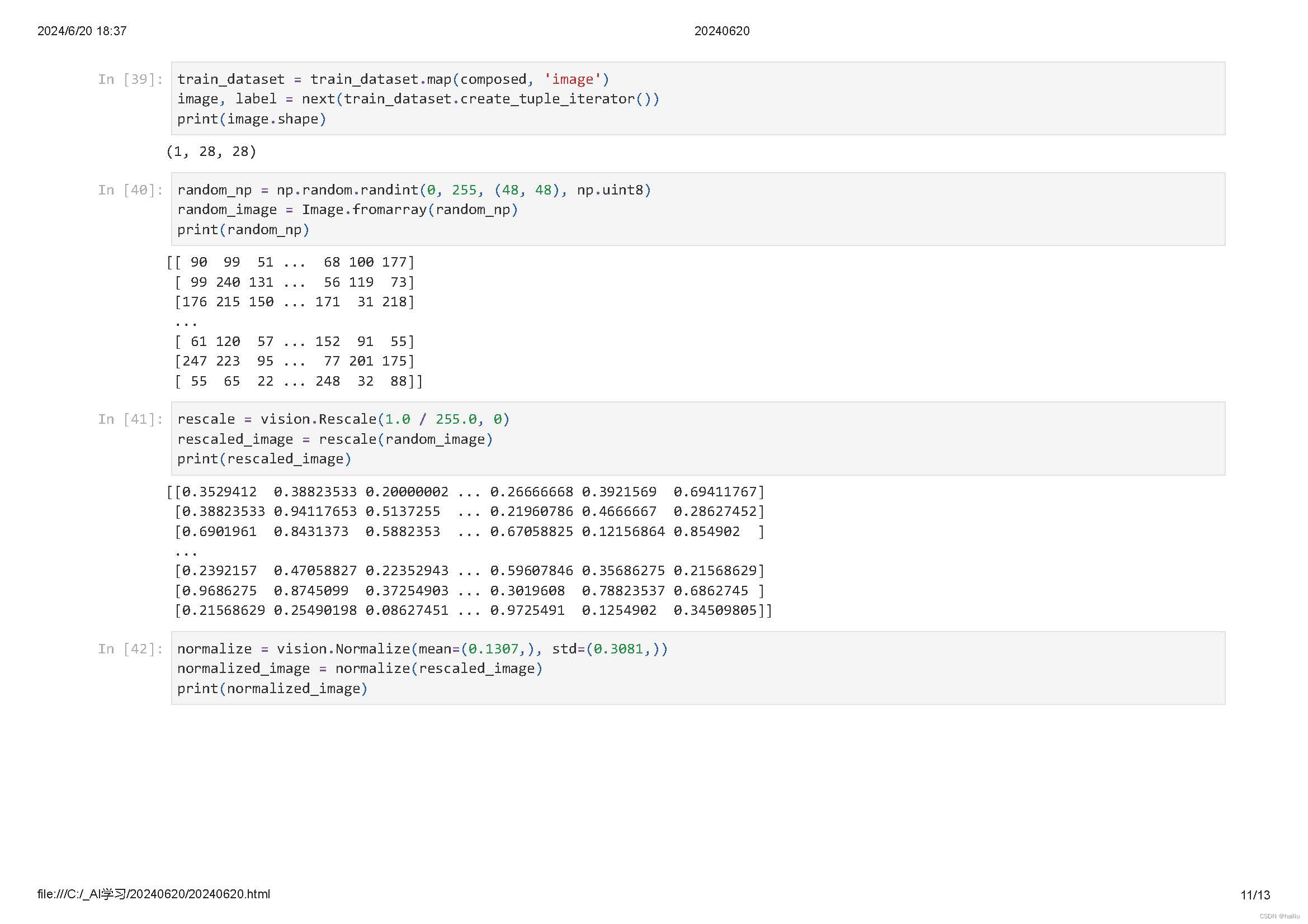
map操作是数据预处理的关键操作,可以针对数据集指定列(column)添加数据变换(Transforms),将数据变换应用于该列数据的每个元素,并返回包含变换后元素的新数据集。
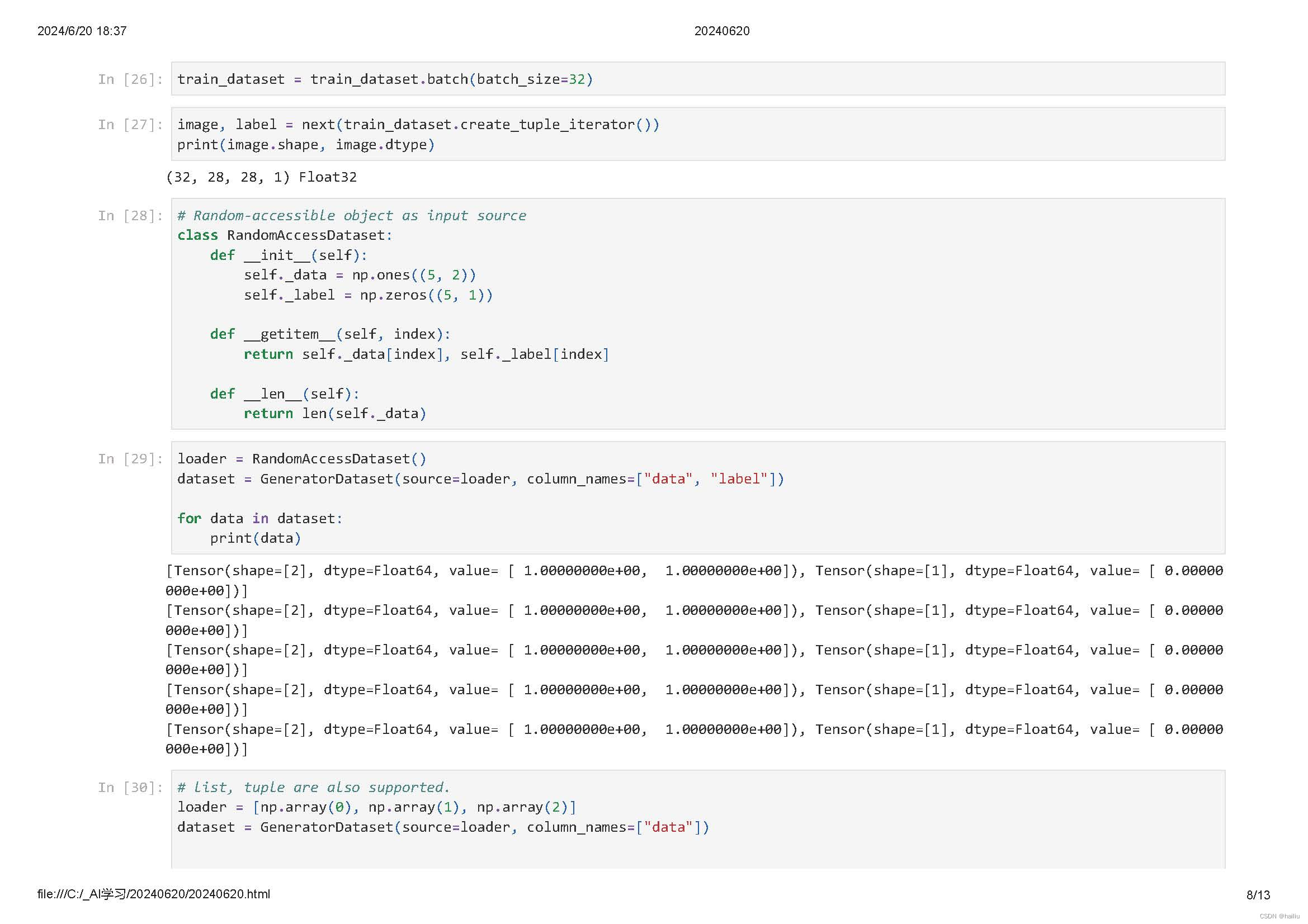
将数据集打包为固定大小的batch是在有限硬件资源下使用梯度下降进行模型优化的折中方法,可以保证梯度下降的随机性和优化计算量。
可随机访问数据集是实现了__getitem__和__len__方法的数据集,表示可以通过索引/键直接访问对应位置的数据样本。
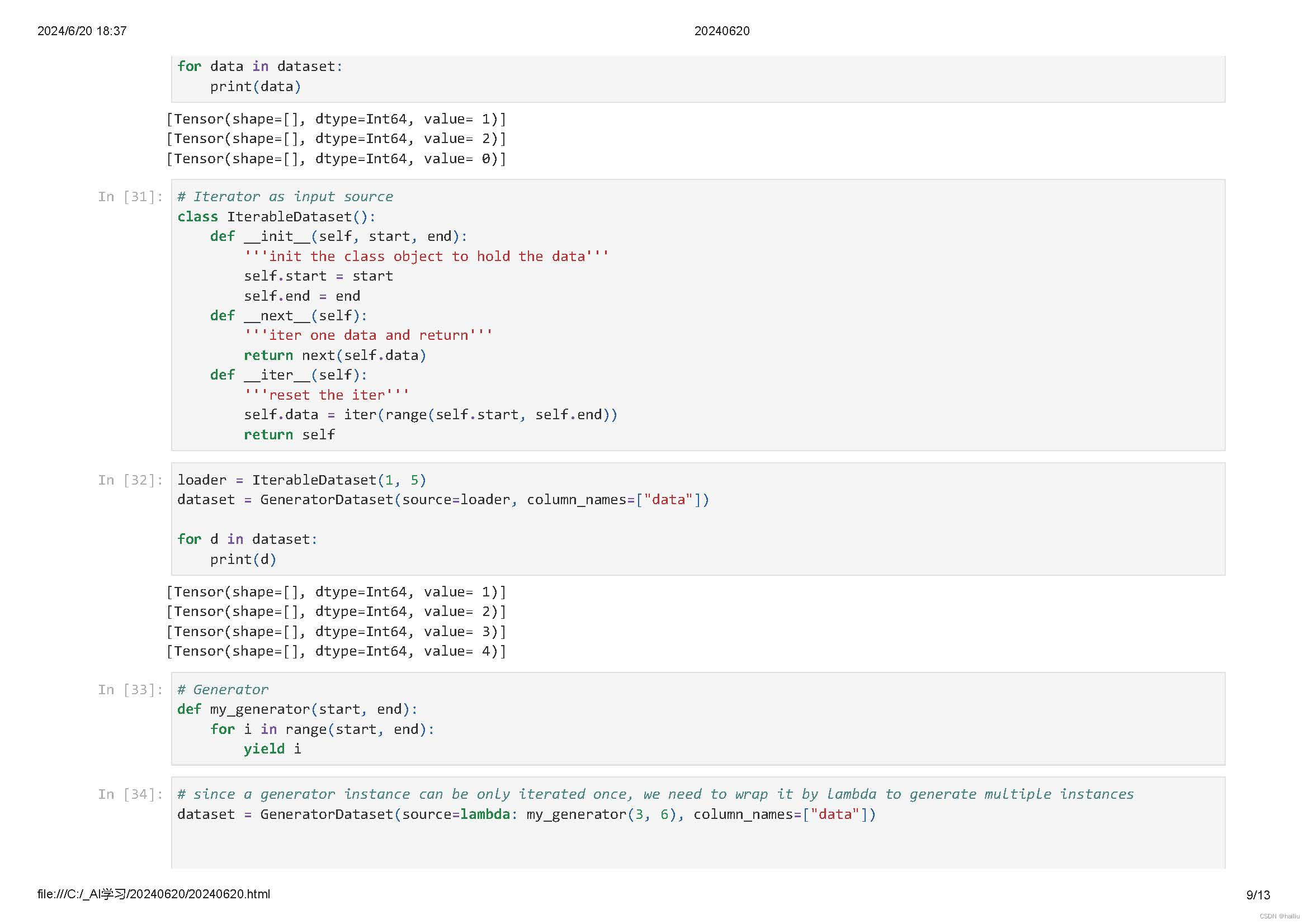
可迭代的数据集是实现了__iter__和__next__方法的数据集,表示可以通过迭代的方式逐步获取数据样本。这种类型的数据集特别适用于随机访问成本太高或者不可行的情况。
生成器也属于可迭代的数据集类型,其直接依赖Python的生成器类型generator返回数据,直至生成器抛出StopIteration异常。
MindSpore提供不同种类的数据变换(Transforms),配合数据处理Pipeline来实现数据预处理。所有的Transforms均可通过map方法传入,实现对指定数据列的处理。
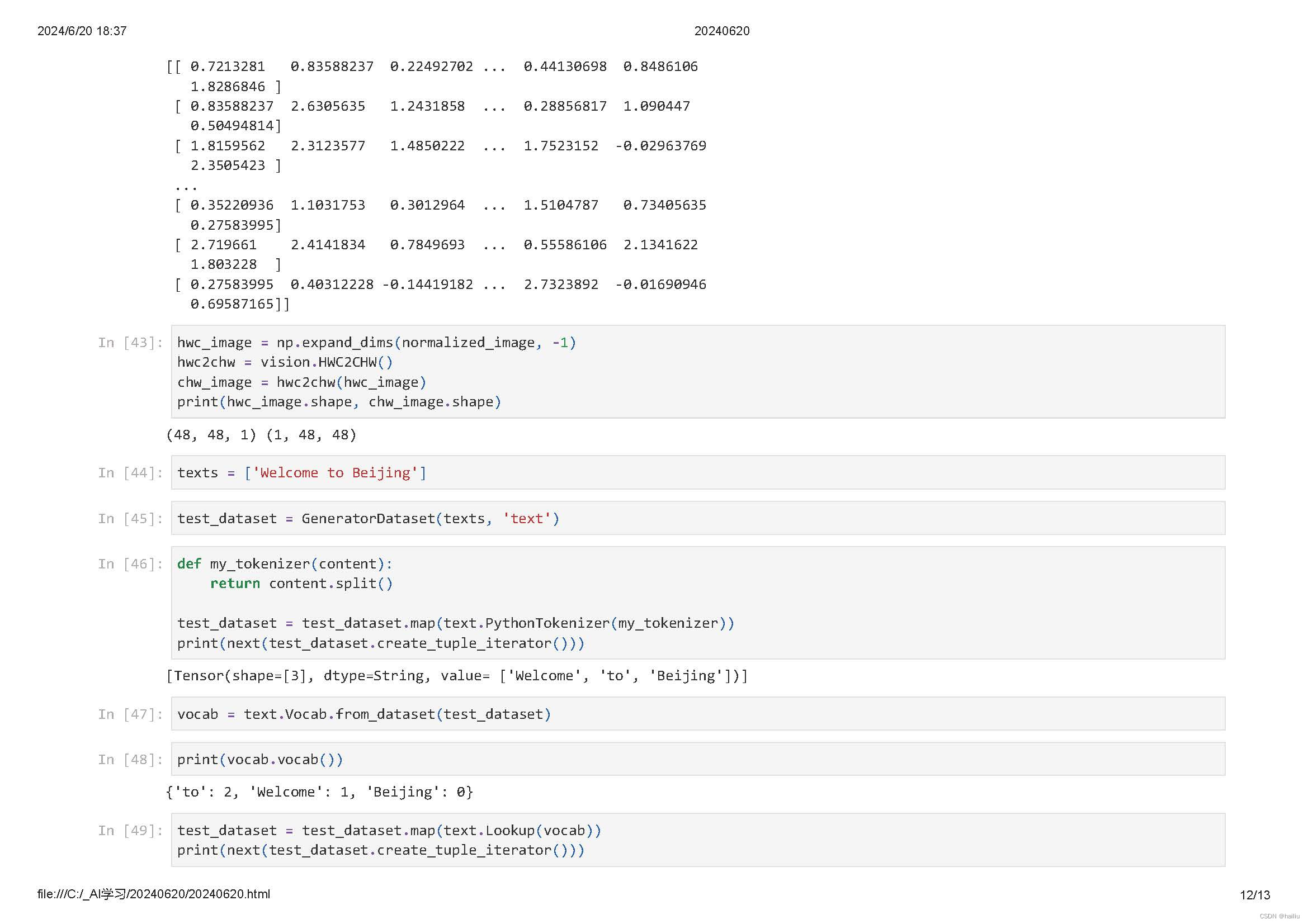
mindspore.dataset提供了面向图像、文本、音频等不同数据类型的Transforms,同时也支持使用Lambda函数。
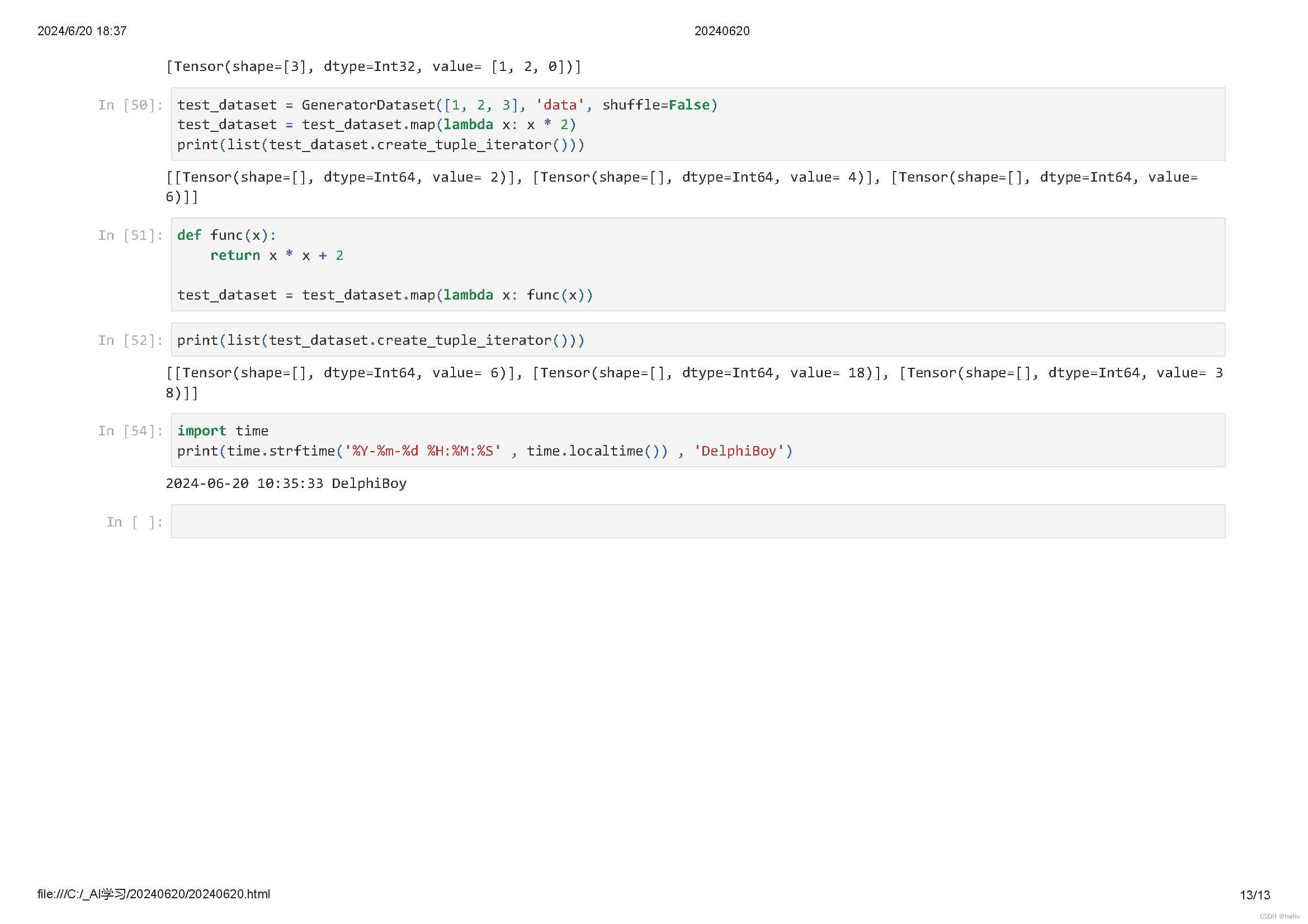
Lambda函数是一种不需要名字、由一个单独表达式组成的匿名函数,表达式会在调用时被求值。Lambda Transforms可以加载任意定义的Lambda函数,提供足够的灵活度。

















 673
673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









