







前言:
1、BM匹配算法适用于,在一个字符串originStr中,搜索targetStr是否存在于originStr中。其中,bm无特殊含义,在话术上,称originStr为主串,targetStr为模式串;
2、在主串中寻找模式串,最简单的方法莫过于暴力搜索。即拿模式串的每一位与主串相比,如果模式串的每一位都在主串中匹配上,则认为找到了。否则,模式串向后滑动一位,紧接着如上操作。直到找到,或找不到。该方法称为BF;
3、BF的最大时间复杂度为O(n*m),其中n为主串长度,m为模式串长度。乍一看,BF并不高效,但在主串长度小,模式串长度小的情况下,特别是模式串长度小的情况下,是非常适用的;
4、BF稍微改造下,可变成RK,RK算法没有从本质上改善BF的时间复杂度。它利用哈希技巧,将模式串的每位比较,改变为一次模式串哈希值比较。但主串的子串哈希值,以及模式串的哈希值,总还是需要根据串中的每一位字符计算得出;
5、BM算法与RK、BF有本质区别,BM算法根据已比较过的子串,来得出模式串应向后滑动多少位,而不是像RK、BF仅向后固定滑动一位;
6、BM算法由坏字符规则、好后缀规则组成,模式串向后滑动的位数取这两个规则下的最大滑动位数;
一、BM算法的匹配方向;
BM匹配时,会拿最后一位字符作为匹配的开始,其匹配方向为向前匹配。
举例:abc与dbc的匹配顺序如下:
1)拿abc的c,与dbc的c比较;
2)拿abc的b,与dbc的b比较;
3)拿abc的a,与dbc的d比较。
二、坏字符规则;
假设主串:abcacabdc
模式串为:abd
1)第一次比较时,主串孩子则为abc;
2)第一个匹配,为c与d的匹配;
3)c与d不相等,c被称为坏字符(坏字符为主串上不与模式串相等的字符)。
4)如果坏字符c,在模式串中不存在,那意味着坏字符无法在模式串的任意一个字符上匹配上。这个时候,可以将模式串向后移动与模式串长度的位数。

5)如果坏字符c,在模式串中存在,那意味着可以将模式串的c与坏字符的c对齐。
因为如果模式串的下一次移动刚好能匹配上主串的子串的话,那么模式串的c与坏字符的c就肯定是对齐的。
需要特别注意的是,假如模式串中存在多个字符与坏字符相等,为避免模式串过度滑动,那么应该是模式串的最后一个c与坏字符对齐。因为模式串最后一个c,与坏字符的距离总是最近的。

三、坏字符规则实现代码;
/**
* 获取坏字符规则下的位移
* @param badChar
* @param target
* @param badIndex
* @return
*/
private static int getBadCharShift(String badChar, String target, int badIndex) {
boolean isBadCharExistInTarget = false;
int lastMatch = -1;
for(int i = 0; (i+1) <= target.length(); i++) {
String s = target.substring(i, i+1);
if(badChar.equals(s)) {
isBadCharExistInTarget = true;
lastMatch = i;
}
}
if(isBadCharExistInTarget) {
return badIndex-lastMatch;
}
return target.length();
}待优化点:模式串中向前查找坏字符更为合理。
四、好后缀规则;
假设主串:a a a b a b
模式串为:a b a b
1)匹配位置如下时:
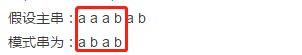
2)孩子主串aaab与模式串abab比较时,后缀有ab是相同的,这样的后缀称为好后缀;具体如下图:
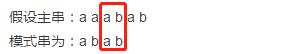
3)如果模式串中存在另外一个与好后缀相同的子串,这意味着重新移动模式串,使该子串与好后缀对齐,就有可能在主串上得到完全与模式串匹配的子串;举例如下:
假设主串、模式串、好后缀如图001;

这个时候,在模式串中可以找到另一个与好后缀相同的子串,将模式串向后移动两位,模式串刚好就与主串的某个子串完全匹配上,见图002;

4)如果在模式串中没有找到另外一个子串与好后缀完全相同的子串,这个时候,并不能武断地将模式串过度地滑动越过好后缀。因为模式串中有可能存在子串与好后缀的后缀子串相同,后缀子串与好后缀的效果是完全一样的。具体如下图:
a a a b a b b a b
b b a b
好后缀为ab,在模式串bbab中并没有找到另外一个好后缀ab,如图003:

但是模式串存在好后缀的后缀子串b,将模式串移动两位,使模式串上,最靠近好后缀子串的好后缀子串,对准好后缀子串。恰好就在主串上得到了一个完全与模式串匹配的子串,如图004:

5)好后缀子串的定义举例如下,比如好后缀abcd,那么其好后缀子串如下:
abcd、bcd、cd、d
五、好后缀规则代码;
1)获取好后缀规则下的位移;
/**
* 获取好后缀规则下的位移
* @param target
* @param goodTail
* @param badIndex
* @return
*/
private static int getGoodTailShift(String target, String goodTail, int badIndex) {
if(goodTail == null || goodTail.length() < 1) {
return -1;
}
return otherGoodTailLastInTarget(target, goodTail, badIndex);
}2)获取模式串中最靠近好后缀的另一个好后缀位置;
/**
* 获取模式串中最靠近好后缀的另一个好后缀位置
* @param target
* @param goodTail
* @param badIndex
* @return
*/
private static int otherGoodTailLastInTarget(String target, String goodTail, int badIndex) {
int index = -1;
List<String> goodTailChildList = goodTailChildList(goodTail);
for(int i = 0; i < goodTailChildList.size(); i++) {
String goodTailChild = goodTailChildList.get(i);
index = goodTailChildLastInTarget(target, goodTailChild, badIndex);
if(index >= 0) {
index = target.length() - index - 1;
break;
}
}
return index;
}3)获取好后缀的所有好后缀孩子串;
/**
* 获取好后缀的所有好后缀孩子串,时间复杂度为O(n),n为goodTail的长度
* 举例:ABCD的所有好后缀孩子串为ABCD、BCD、CD、D
* @param goodTail
* @return
*/
private static List<String> goodTailChildList(String goodTail){
List<String> result = new ArrayList<String>();
for(int i = 0; i < goodTail.length(); i++) {
String s = goodTail.substring(i, goodTail.length());
result.add(s);
}
return result;
}4)获取模式串中最靠近指定好后缀孩子的另一个好后缀孩子位置;
/**
* 获取模式串中最靠近指定好后缀孩子的另一个好后缀孩子位置,时间复杂度O(n*m),n为target长度,m为goodTail长度
* @param target
* @param goodTail
* @param badIndex
* @return
*/
private static int goodTailChildLastInTarget(String target, String goodTail, int badIndex) {
int goodTailLen = goodTail.length();
for(int i = (target.length()-1); (i-goodTailLen) >= 0; i--) {
int startIndex = i-goodTailLen;
String maybeGoodTail = target.substring(startIndex, i);
if(isEqual(maybeGoodTail, goodTail)) {
return startIndex;
}
}
return -1;
}五、其它;















 6463
6463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









