







由于shuffle阶段涉及磁盘的读写和网络IO,因此shuffle性能的高低直接影响整个程序的性能和吞吐量。
【注:毕竟有些东西我没有实际应用、经历,所以文中难免有错,还请各路大神多多指正!】
1. spark的shuffle 是什么?过程? 怎么调优?
在MapReduce过程中需要将各个节点上的同一类数据汇集到一个节点进行计算。把这些分布在不同节点的数据按照一定规则聚集到一起的过程,就称之为shuffle(Shuffle是Map和Reduce之间的操作,Shuffle 过程本质上就是将 Map 端获得的数据使用分区器进行划分,并将数据发送给对应的 Reducer 的过程)。
分割线:18/3/6有增加些许内容
在Spark中,只有宽依赖才会进行数据shuffle【所以也称之为ShuffleDependency,根据宽依赖划分Stage】,窄依赖不会进行数据shuffle【称之为NarrowDependency,只会划分一个Stage】。从容灾的角度来说,宽依赖需要恢复所有的父RDD。
对于reduce来说,处理函数的输入是key相同的所有value,但是这些value所在的数据集(即map的输出)位于不同的节点上,因此需要对map的输出进行重新组织,使得同样的key进入相同的reducer。 shuffle移动了大量的数据,对计算、内存、网络和磁盘都有巨大的消耗,因此,只有确实需要shuffle的地方才应该进行shuffle。
过程如图:【注:其实过程远比这个图复杂很多很多,这只是极简的图】
想做的解释都放图中了,就不单独赘述了。
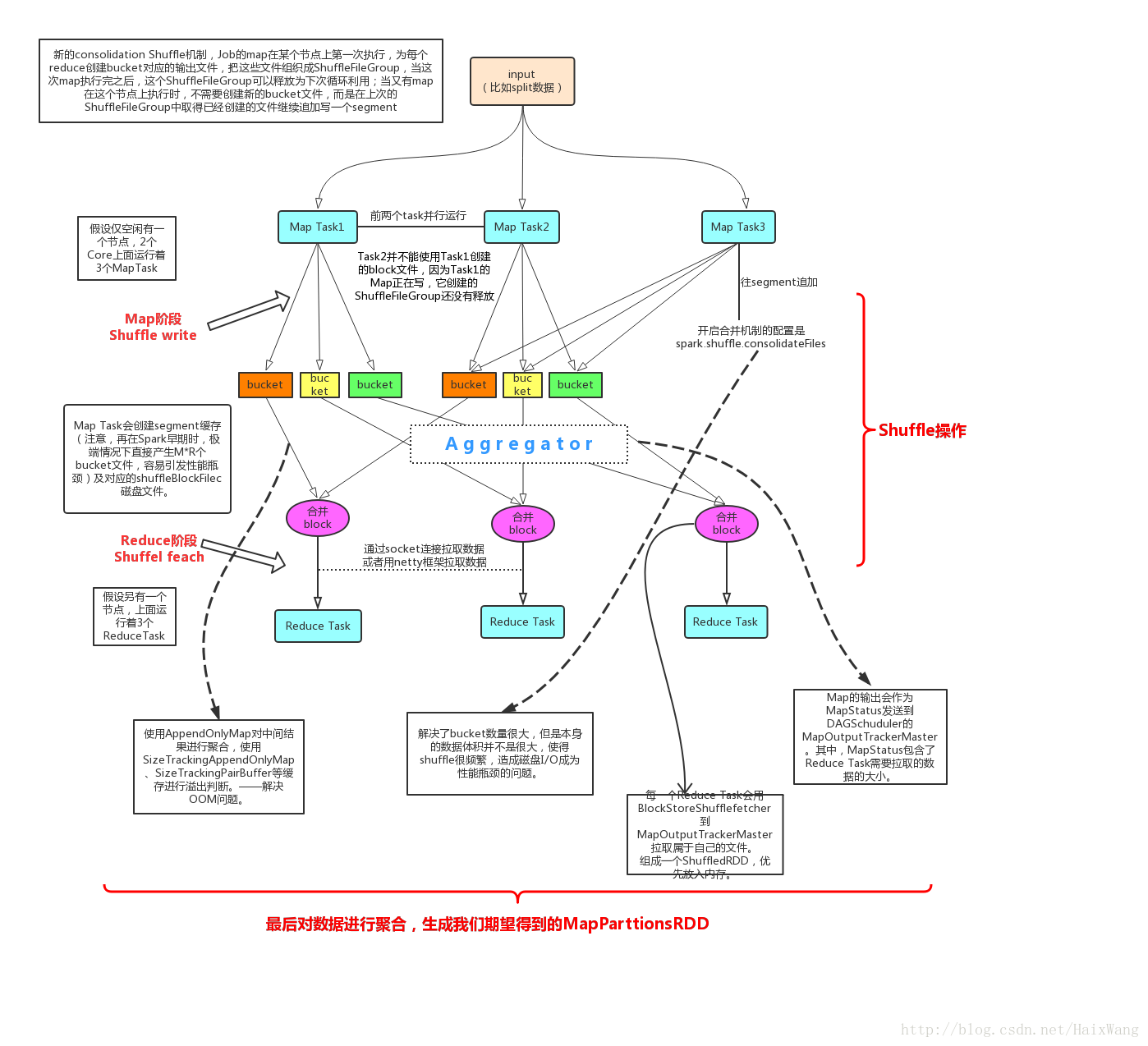
spark2.0及之后的版本中只存在SortShuffleManager而将原来的HashShuffleManager废弃掉(在1.2版本之前的Shuffle方法);
开启了consolidation机制后,每个节点上Map write磁盘文件数量为:num(core)*num(redece task);
调优
i):针对应用对内存缓存大小进行调整——设置过大可能引发OOM;当缓存数据达到设置的阈值的时候就会往磁盘中写入,所以设置过小的话,又会有过多的磁盘io操作。
ii):TODO
2. hadoop的MapReduce以及shuffle过程,画图。怎么调优?
主要参考:[6]
MapReduce中,Map是一个将输入记录转换为中间记录的任务。已转换的中间记录不一定非得与输入记录具有相同的类型。一个给定的输入对可能映射到零个或多个输出对。Map数量通常由输入数据的大小决定,也就是输入数据的总的块数【(MRJobConfig.NUM_MAPS可设置】。Reducer接收的数据是Mapper中处理出来的已经排好序的数据。
在MapReduce过程中需要将各个节点上的同一类数据汇集到一个节点进行计算。把这些分布在不同节点的数据按照一定规则聚集到一起的过程,就称之为shuffle。
如图:
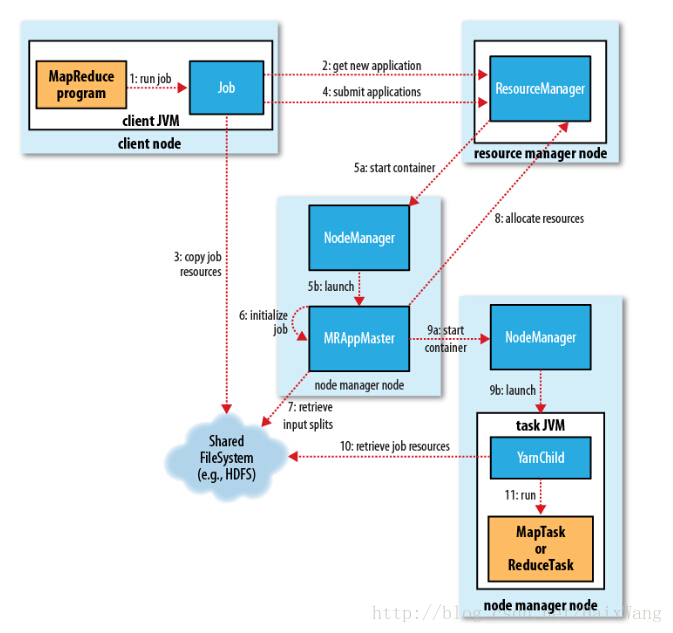
1、向client端提交MapReduce job.
2、随后yarn的ResourceManager对可用资源进行分配.
3、由NodeManager加载与监控containers.
4、通过applicationMaster与ResourceManager进行资源申请及状态交互,由NodeManagers进行MapReduce运行时job的管理.
5、通过hdfs进行job配置文件、jar包的各节点分发。
Map阶段:
i): map任务输出结果到一个环状的内存缓冲区,缓冲区的大小可通过修改配置项mpareduce.task.io.sort.mb进行修改,当写入内存的大小到达一定比例,默认为80%(可通过mapreduce.map.sort.spill.percent配置项修改),便开始写入磁盘。
ii): 这里将map输出的结果进行压缩会大大减少磁盘IO与网络传输的开销(配置参数mapreduce.map .output.compress 设置为true,如果使用第三方压缩jar,可通过mapreduce.map.output.compress.codec进行设置)
iii): 随后这些paritions输出文件将会通过HTTP发送至reducers,传送的最大启动线程通过mapreduce.shuffle.max.threads进行配置。
Reduce阶段:
i): 首先上面每个节点的map都将结果写入了本地磁盘中,现在reduce需要将map的结果通过集群拉取过来,这里要注意的是,需要等到所有map任务结束后,reduce才会对map的结果进行拷贝,由于reduce函数有少数几个复制线程,以至于它可以同时拉取多个map的输出结果。默认的为5个线程(可通过修改配置mapreduce.reduce.shuffle.parallelcopies来修改其个数)
reducers怎么知道从哪些机器拉取数据呢?
ii): 当所有map的任务结束后,applicationMaster通过心跳机制(heartbeat mechanism),由心跳机制获知mapping的输出结果与机器host,所以reducer会定时的通过一个线程访问applicationmaster请求map的输出结果。
iii): Map的结果将会被拷贝到reduce task的JVM的内存中(内存大小可在mapreduce.reduce.shuffle.input.buffer.percent中设置)如果不够用,则会写入磁盘。当内存缓冲区的大小到达一定比例时(可通过mapreduce.reduce.shuffle.merge.percent设置)或map的输出结果文件过多时(可通过配置mapreduce.reduce.merge.inmen.threshold),将会合并(merged)随之写入磁盘。
iv): 要注意,所有的map结果这时都是被压缩过的,需要先在内存中进行解压缩,以便后续合并它们。(合并最终文件的数量可通过mapreduce.task.io.sort.factor进行配置) 最终reduce进行运算进行输出。
调优,TODO:
3. spark的shuffle和Hadoop的shuffle(mapreduce)的联系和区别是什么
联系:两者都是将 mapper(Spark 里是 ShuffleMapTask)的输出进行 partition,不同的 partition 送到不同的 reducer(Spark 里 reducer 可能是DAG中下一个 stage 里的 ShuffleMapTask,也可能是 ResultTask)。Reducer 以内存作缓冲区,边 shuffle 边 aggregate 数据,等到数据 aggregate 好以后进行 reduce() (Spark 里可能是后续的一系列操作)。Spark中的很多计算是作为MapReduce计算框架的一种优化实现。
区别在于:
从底层来看:最开始Spark尽量避免Hadoop多余的排序(MapReduce 为了方便对存在于不同 partition 的 key/value Records进行Group,就提前对 key 进行排序,这样做的好处在于 combine/reduce() 可以处理大规模的数据。Spark 认为很多应用不需要对 key 排序,所以Spark提供了基于hash的Shuffle写,通常使用 HashMap 来对 shuffle 来的数据进行 aggregate,这种方法不会对数据进行提前排序,并且在1.2版本之前,这种方法是默认方法——但是现在的默认方法还是基于排序的Shuffle,并且在在spark2.0及之后的版本中只存在SortShuffleManager而将原来的HashShuffleManager废弃掉(但是shuffleWriter的子类BypassMergeSortShuffleWriter和已经被废弃掉的HashShuffleWriter类似))[1][4]
从实现角度来看: Hadoop MapReduce 将处理流程划分出明显的几个阶段:map(), spill, merge, shuffle, sort, reduce() 等。每个阶段各司其职,可以按照过程式的编程思想来逐一实现每个阶段的功能。在 Spark 中,没有这样功能明确的阶段,只有不同的 stage 和一系列的 transformation操作,所以 spill, merge, aggregate 等操作需要蕴含在一些transformation操作中。
从数据流角度:Mapr只能从一个map stage接受数据,Spark 可以从多个 Map Stages shuffle 数据(这是 DAG 型数据流中宽依赖的优势,可以表达复杂的数据流操作)。
从数据粒度角度:Spark 粒度更细,可以更即时的将获取到的 record 与 HashMap 中相同 key 的 records 进行合并。
从性能优化角度来讲:Spark考虑的更全面。Spark 针对不同类型的操作、不同类型的参数,会使用不同的 shuffle write 方式。比如 Shuffle write 有三种实现方式 [2]

但是hadoop的2.7.1开始,新增了一个加密shuffle:加密Shuffle功能允许使用HTTPS和可选的客户端身份验证(也称为双向HTTPS或带客户端证书的HTTPS)对MapReduce shuffle进行加密 [3]
4. 哪些算子涉及到shuffle操作
sortByKey、groupByKey、reduceByKey、countByKey、join、cogroup等聚合操作。
扩展:[5]
(1)MapReduce Shuffle发展史
【阶段1】:MapReduce Shuffle的发展也并不是一马平川的,刚开始(0.10.0版本之前)采用了“每个Map Task产生R个文件”的方案,前面提到,该方案会产生大量的随机读写IO,对于大数据处理而言,非常不利。
【阶段2】:为了避免Map Task产生大量文件,HADOOP-331尝试对该方案进行优化,优化方法:为每个Map Task提供一个环形buffer,一旦buffer满了后,则将内存数据spill到磁盘上(外加一个索引文件,保存每个partition的偏移量),最终合并产生的这些spill文件,同时创建一个索引文件,保存每个partition的偏移量。
(阶段2):这个阶段并没有对shuffle架构做调成,只是对shuffle的环形buffer进行了优化。在Hadoop 2.0版本之前,对MapReduce作业进行参数调优时,Map阶段的buffer调优非常复杂的,涉及到多个参数,这是由于buffer被切分成两部分使用:一部分保存索引(比如parition、key和value偏移量和长度),一部分保存实际的数据,这两段buffer均会影响spill文件数目,因此,需要根据数据特点对多个参数进行调优,非常繁琐。而MAPREDUCE-64则解决了该问题,该方案让索引和数据共享一个环形缓冲区,不再将其分成两部分独立使用,这样只需设置一个参数控制spill频率。
【阶段3(进行中)】:目前shuffle被当做一个子阶段被嵌到Reduce阶段中的。由于MapReduce模型中,Map Task和Reduce Task可以同时运行,因此一个作业前期启动的Reduce Task将一直处于shuffle阶段,直到所有Map Task运行完成,而在这个过程中,Reduce Task占用着资源,但这部分资源利用率非常低,基本上只使用了IO资源。为了提高资源利用率,一种非常好的方法是将shuffle从Reduce阶段中独立处理,变成一个独立的阶段/服务,由专门的shuffler service负责数据拷贝,目前百度已经实现了该功能(准备开源?),且收益明显,具体参考:MAPREDUCE-2354。
(2) Spark Shuffle发展史
目前看来,Spark Shuffle的发展史与MapReduce发展史非常类似。初期Spark在Map阶段采用了“每个Map Task产生R个文件”的方法,在Reduce阶段采用了map分组方法,但随Spark变得流行,用户逐渐发现这种方案在处理大数据时存在严重瓶颈问题,因此尝试对Spark进行优化和改进,相关链接有:External Sorting for Aggregator and CoGroupedRDDs,“Optimizing Shuffle Performance in Spark”,“Consolidating Shuffle Files in Spark”,优化动机和思路与MapReduce非常类似。
Spark在前期设计中过多依赖于内存,使得一些运行在MapReduce之上的大作业难以直接运行在Spark之上(可能遇到OOM问题)。目前Spark在处理大数据集方面尚不完善,用户需根据作业特点选择性的将一部分作业迁移到Spark上,而不是整体迁移。随着Spark的完善,很多内部关键模块的设计思路将变得与MapReduce升级版Tez非常类似。
参考:
[1]github:4-shuffleDetails.md
[2]知乎:对问题2的讨论
[3]hadoop 2.7.1:加密shuffle
[4]简书:Spark Shuffle(ExternalSorter)
[5]董西成
[6]MapReduce运行原理详解















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









