










本文主要内容:
knn K近邻算法原理
sklearn knn的使用,以及cross validation交叉验证
numpy 实现knn
knn改进方法
1 knn K近邻算法原理
K近邻算法:给定一个训练数据集,对新的的输入实例,在训练数据集中找到与该实例最邻近的的K个实例,这K个实例的多数属于某个类,就把该实例分为这个类。
KNN 是 supervised learning, non parametric(无参数) instance-based(基于实例) learning algorithm.
K值选择、距离度量、以及分类决策(一般多数表决)为K近邻算法的三个基本要素。
1.1 K值选择
Wikipedia上的KNN词条中有一个比较经典的图如下:
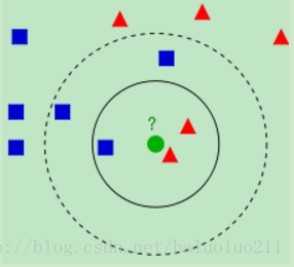
从上图中我们可以看到,图中的有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
可见K值的选择对分类的结果还是有很大的影响。
1.2 距离度量


2. sklearn knn的使用,以及cross validation交叉验证
2.1 数据集的准备
数据集来源:https://archive.ics.uci.edu/ml/datasets/Iris
代码github地址以及数据集github地址,见本人的github

import numpy as np
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cross_validation import train_test_split, cross_val_score
import pandas as pd
import matplotlib.pyplot as plt
def load_data():
names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'class']
# loading training data
path = '../dataset/knn/iris_data.txt'
df = pd.read_csv(path, header=None, names=names)
# print df.head()
x = np.array(df.ix[:, 0: 4])
y = np.array(df['class'])
print x.shape, y.shape
# x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.33, random_state=40)
return train_test_split(x, y, test_size=0.33, random_state=40)
2.2 验证预测效果
def predict():
x_train, x_test, y_train, y_test = load_data()
k = 3
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(x_train, y_train)
pred = knn.predict(x_test)
print accuracy_score(y_test, pred)2.3 交叉验证
def cross_validation():
x_train, x_test, y_train, y_test = load_data()
k_lst = list(range(1, 30))
lst_scores = []
for k in k_lst:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, x_train, y_train, cv=10, scoring='accuracy')
lst_scores.append(scores.mean())
# changing to misclassification error
MSE = [1 - x for x in lst_scores]
optimal_k = k_lst[MSE.index(min(MSE))]
print "The optimal number of neighbors is %d" % optimal_k
# plot misclassification error vs k
# plt.plot(k_lst, MSE)
# plt.ylabel('Misclassification Error')
plt.plot(k_lst, lst_scores)
plt.xlabel('Number of Neighbors K')
plt.ylabel('correct classification rate')
plt.show()
numpy 实现knn
from collections import Counter
import numpy as np
class KnnScratch(object):
def fit(self, x_train, y_train):
self.x_train = x_train
self.y_train = y_train
def predict_once(self, x_test, k):
lst_distance = []
lst_predict = []
for i in xrange(len(self.x_train)):
# euclidean distance
distance = np.linalg.norm(x_test - self.x_train[i, :])
lst_distance = sorted(lst_distance)
for i in xrange(k):
idx = lst_distance[i][1]
lst_predict.append(self.y_train[idx])
return Counter(lst_predict).most_common(1)[0][0]
def predict(self, x_test, k):
lst_predict = []
for i in xrange(len(x_test)):
lst_predict.append(self.predict_once(x_test[i, :], k))
return lst_predict
if __name__ == '__main__':
x_train = np.array([[1, 1, 1], [2, 2, 2], [10, 10, 10], [13, 13, 13]])
y_train = ['aa', 'aa', 'bb', 'bb']
x_test = np.array([[3, 2, 4], [9, 13, 11]])
knn = KnnScratch()
knn.fit(x_train, y_train)
print knn.predict_once(x_test[0], 2)
# aa
print knn.predict(x_test, 2)
# ['aa', 'bb']knn改进方法
不同的K值加权
距离度量标准根据实际问题,使用不同的距离
特征归一化,例如,身高和体重x=[180,70],升高计算明显,更影响结果,所有需要对两者分别求平均值,然后归一化。
如果维数过大,可以做PCA降维处理
参考:
https://kevinzakka.github.io/2016/07/13/k-nearest-neighbor/
https://machinelearningmastery.com/tutorial-to-implement-k-nearest-neighbors-in-python-from-scratch/
http://coolshell.cn/articles/8052.html
李航《统计学习方法》
转载注明出处,并在下面留言!!!















 2024
2024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









