






PLT (Procedure Linkage Table) 和 GOT (Global Offset Table) 是 GCC 中生成shared library的重要元素。至于为何一定要这两个表?
GOT的功用
以gcc內建的libc.so 为例,因为你不可能用到libc.so 里面所有的函数,所以其实不用知道所有函数在内存的绝对位置。其中GOT只列出你会用到的function 或者是 global variable的绝对位置。这样会节省许多解析时间。
以下面的图为例,图里面是一个简化的例子,这和实际编译情况不同,但适合说明GOT。
当我要从main()内去调用 shared binary 中的foo()方法的时候,在编译过程中(调用$gcc main.c 的时候)编译器会生成一个可执行文件,假设生成的可执行文件名字为a.out,在这个生成的文件中原先的main.c 中的foo()被替换为 b @GOT+0x14 ,这行代码的作用是,跳转到GOT内所记录的位置上去,地址就是GOT表的起始地址加上0x14,内容是 0x76fc6578,这个地址也就是foo() 在 shared library 的觉得位置。
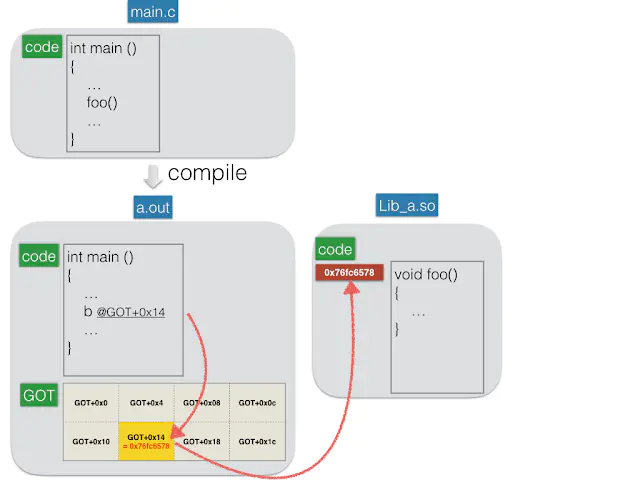
image.png
PLT的功用
既然GOT已经列出了需要的东西,那照理说工作就结束了,为啥还需要PLT?
试想,当你的程序大到和libc.so 库一样大的时候,你可能会调用上百个libc里面的函数,所以当你的程序加载进内存的时候,linker会解析你需要的函数,这个过程会消耗一些时间,并导致使用者认为程序运行很慢。为了解决这个问题,所以GCC改为在调用 共享库(libxxx.so) 里面的函数之前,才去吧绝对位置填入到GOT里面。而PLT的功能就是调用linker 去填入GOT表里面的表项,这个机制就是延迟绑定(lazy binding)。
要注意 lazy binding和 lazy loading的差异。Lazy loading 是通过调用dlopen()等函数将library(动态库)动态加载进内存。GCC並沒有自动提供lazy loading的机制,所以的shared library都是一次加载进内存,除非你使用dlopen()。
下面用几张图来说明一下:
Step 1: 呼叫 Linker
在解释动作前,先看一下 GOT表格,其中 GOT+0x14的內容暂时填入 linker 的位置,這需要 linker 去解析然后回填到GOT+0x14。原先main()要调用的 foo()被替换成 "foo()@plt" 的函式,而这个函数又会跳转到 GOT+0x14的地址去。请仔细看,这个地址是要跳去 linker,而非foo(),因为这时候 foo()的地址还沒有被解析。
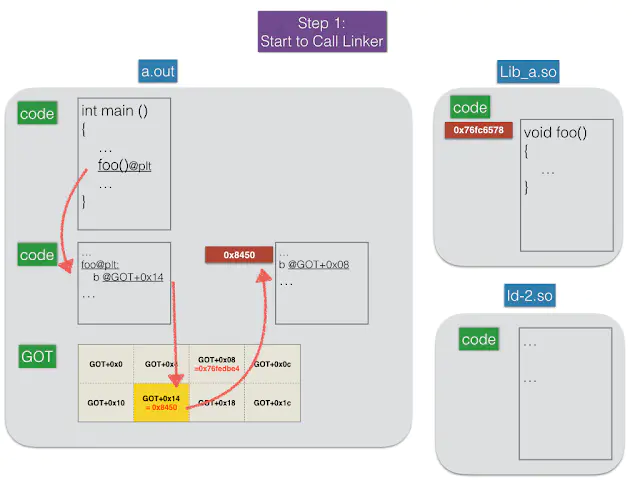
Step 1.png
Step 2: 解析 foo() 的地址
Linker "ld-2.so"会把 foo()在 shared library的绝对地址填入 GOT+0x14的内存中。请注意,ld代表的意思是 Linker/Loader。
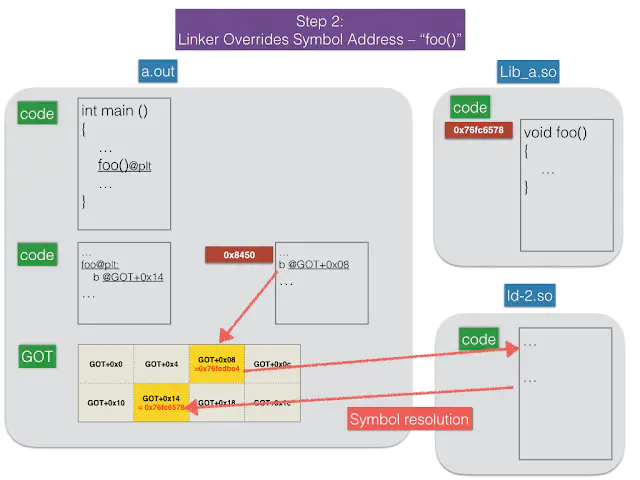
Step 2.png
Step 3: 跳转到 foo()
接着Linker会跳转到foo(),大功告成
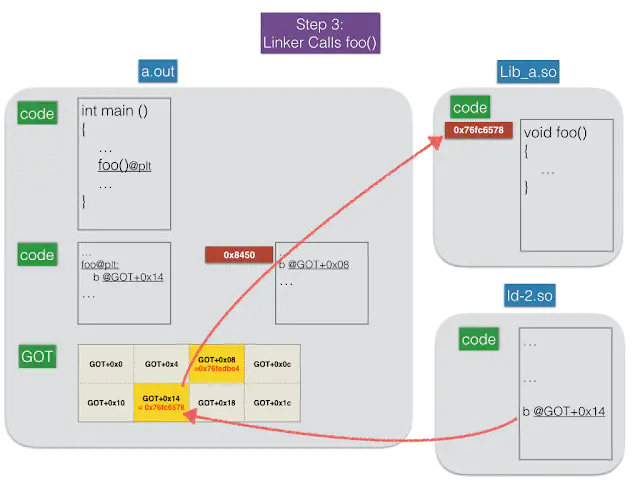
Step 3.png
一个真实的例子的概述
上面介绍了GOT 和PLT的概念,下面搞一个实际的例子来看下结果。
例子是参考《程序员的自我修养--链接、装载与库.pdf》这本书中的地7.3.3 节的列子。列子的代码可以在GitHub上下载点我
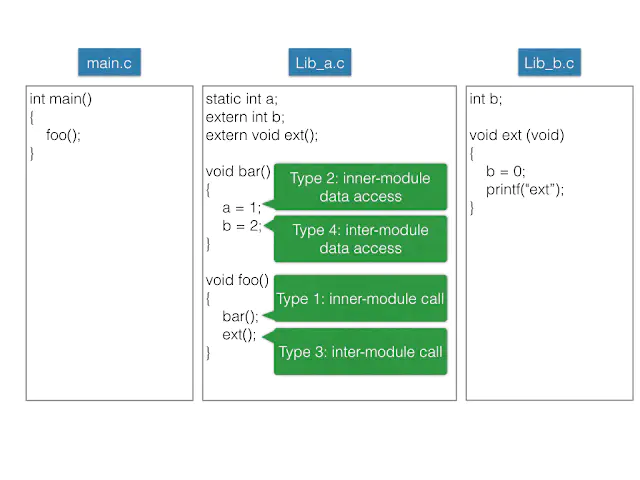
例子.png
例子虽然简单,但是目的却很有趣,一共四个:
- Type 1: Inner-module call (模块内部函数调用,跳转)
- Type 2: Inner-module data access(模块内部数据访问,比如模块中定义的全局变量,静态变量等)
- Type 3: Inter-module call(模块外部的函数调用,跳转等)
- Type 4: Inter-module data access(模块外部数据访问,比如其他模块中定义的全局变量)
在观察这几个例子之前,我们先来编译这几个c文件,然后反编译生成的文件 (实验的环境是 arm cortex-a7 32bits、gcc 4.6.3)。
首先生成 Lib_a.o 和 Lib_b.o(不知道为啥,在Mac上这个东西编译不过)
$ gcc -g -shared -fPIC Lib_b.c -o Lib_b.o
$ gcc -g -shared -fPIC Lib_a.c -o Lib_a.o
然后生成可执行文件:
$ gcc -g main.c ./Lib_a.o ./Lib_b.o
然后反编译Lib_a.o、Lib_b.o、a.out:
$ objdump -sSdD a.out > objdump.txt
$ objdump -sSdD Lib_a.o > objdump.txt-Lib_a
$ objdump -sSdD Lib_b.o > objdump.txt-Lib_b
做完上面的准备工作之后,先来看下 function call 相关的 Type1 和 Type3 的流程,也就是 inner-module call和 inter-module call。在开始之前,我们照直观的想法,inter-module call一定会用到GOT,而 inner-module call 因为不需要跳转,所以应该不需要用到GOT。我们可以使用 $ readelf -r 这个命令行工具去看看 relocation section,这个section 的功能就是表示GOT表中每个表项的定义。
注:objdump 和 readelf 是两个命令行工具,在Linux系统上可以搜索安装,Mac下我是用的greadelf 和 gobjdump
先看 main.c的GOT
$ readelf -r a.out
Relocation section '.rel.dyn' at offset 0x41c contains 1 entries:
Offset Info Type Sym.Value Sym. Name
00010708 00000115 R_ARM_GLOB_DAT 00000000 __gmon_start__
Relocation section '.rel.plt' at offset 0x424 contains 4 entries:
Offset Info Type Sym.Value Sym. Name
000106f8 00000d16 R_ARM_JUMP_SLOT 00000000 __libc_start_main
000106fc 00000116 R_ARM_JUMP_SLOT 00000000 __gmon_start__
00010700 00000516 R_ARM_JUMP_SLOT 00000000 foo
00010704 00000916 R_ARM_JUMP_SLOT 00000000 abort
.rel.dyn:每个表项对应了除了外部过程调用的符号以外的所有重定位对象,(比如通过全局函数指针来调用外部函数).rel.plt表项对应了所有外部过程(function)调用符号的重定位信息
也可以从"R_ARM_GLOB_DAT" 和 "R_ARM_JUMP_SLOT" 看出来。
进一步来看一下各个symbol:
__gmon_start__: 如果用gcc编译的时候,加上-pg这个参数选项,那么这个symbol就会起作用(比如gcc -pg main.c),具体介绍看这里__libc_start_main: 这是c程序运行之前一定会执行的一个函数,问的是加载需要的library ,具体看这里foo:这个是Lib_a.o 里面的程序abort: 这是c90标准定义里面的预设function 看这里
虽然在上面查看到条目里面有很多没遇到过的function,但是foo() 还是按照我们预期出现了。
接下来看 Lib_a.o的relocation section
$ readelf -r Lib_a.o
Relocation section '.rel.dyn' at offset 0x3bc contains 7 entries:
Offset Info Type Sym.Value Sym. Name
00008598 00000017 R_ARM_RELATIVE
0000859c 00000017 R_ARM_RELATIVE
000086b8 00000017 R_ARM_RELATIVE
000086a8 00000315 R_ARM_GLOB_DAT 00000000 __cxa_finalize
000086ac 00000415 R_ARM_GLOB_DAT 00000000 b
000086b0 00000515 R_ARM_GLOB_DAT 00000000 __gmon_start__
000086b4 00000715 R_ARM_GLOB_DAT 00000000 _Jv_RegisterClasses
Relocation section '.rel.plt' at offset 0x3f4 contains 4 entries:
Offset Info Type Sym.Value Sym. Name
00008698 00000316 R_ARM_JUMP_SLOT 00000000 __cxa_finalize
0000869c 00000a16 R_ARM_JUMP_SLOT 00000530 bar
000086a0 00000516 R_ARM_JUMP_SLOT 00000000 __gmon_start__
000086a4 00000616 R_ARM_JUMP_SLOT 00000000 ext
和上面a.out 相比这里少了abort() ,但是出现了一些新的东西:
- __cxa_finalize : 当shared library unload时,会调用他。(参考资料)
- b : 这是Lib_b.o 内部全局变量
- bar: 这是Lib_a.o 内的function
- ext : 这是Lib_b.o 内部function
有趣的是,即便bar() 定义在Lib_a.o 内,也需要GOT,和之前猜测不一样哦,所以"Type 2: Inner-module data access"是需要GOT的。另外,变量 "static int a" 并没有在GOT内,非常合理。
我们继续看最后一个 动态库,"Lib_b.o"的relocation section:
$ readelf -r Lib_b.o
Relocation section '.rel.dyn' at offset 0x3a4 contains 7 entries:
Offset Info Type Sym.Value Sym. Name
00008594 00000017 R_ARM_RELATIVE
00008598 00000017 R_ARM_RELATIVE
000086b0 00000017 R_ARM_RELATIVE
000086a0 00000315 R_ARM_GLOB_DAT 00000000 __cxa_finalize
000086a4 00000e15 R_ARM_GLOB_DAT 000086b8 b
000086a8 00000515 R_ARM_GLOB_DAT 00000000 __gmon_start__
000086ac 00000615 R_ARM_GLOB_DAT 00000000 _Jv_RegisterClasses
Relocation section '.rel.plt' at offset 0x3dc contains 3 entries:
Offset Info Type Sym.Value Sym. Name
00008694 00000316 R_ARM_JUMP_SLOT 00000000 __cxa_finalize
00008698 00000416 R_ARM_JUMP_SLOT 00000000 printf
0000869c 00000516 R_ARM_JUMP_SLOT 00000000 __gmon_start__
其余的符号不解释了,只看我们感兴趣的两个:
- b : Lib_b.o本身的全域变量
- printf : libc提供的function
即便 int b就在Lib_b.o内,也需要GOT来存取。
跟踪反编译后的代码 ( main.c)
实际 Trace Code 来看看 GOT + PLT 的用途
先看 main.c的反编译结果
513 00008540 <main>:
514 #include <stdio.h>
515 #include "Lib_a.h"
516
517 int main(int argc, char* argv[])
518 {
519 8540: e92d4800 push {fp, lr}
520 8544: e28db004 add fp, sp, #4
521 8548: e24dd008 sub sp, sp, #8
522 854c: e50b0008 str r0, [fp, #-8]
523 8550: e50b100c str r1, [fp, #-12]
524 foo();
525 8554: ebffffc8 bl 847c <foo@plt>
526 }
527 8558: e1a00003 mov r0, r3
528 855c: e24bd004 sub sp, fp, #4
529 8560: e8bd8800 pop {fp, pc}
Line 525 可以看到为了调用foo()直接跳到0x847c的位置,但是注解写的function名称是foo@plt,有点奇怪。不过直接去看0x847c
450 0000847c <foo@plt>:
451 847c: e28fc600 add ip, pc, #0, 12
452 8480: e28cca08 add ip, ip, #8, 20 ; 0x8000
453 8484: e5bcf27c ldr pc, [ip, #636]! ; 0x27c
这个arm的代码有点烦,不过一行行解读就行了
Line 451: add ip, pc, #0, 12
其中pc指的是下两行指令的地址,也就是 Line 453标注的位置 0x8484。整个指令的作用为 "ip = pc + 0x0 << 12",所以 ip = 0x8484 + 0x0 = 0x8484。
稍微解释一下:因为 arm 处理器使用 3 级流水线(取指,译码,执行),所以无论处理器处于何种状态,程序计数器R15(PC)总是指向“正在取指”的指令,而不是指向“正在执行”的指令或者正在“译码”的指令。
处理器处于ARM状态时,每条指令为4个字节,所以PC值为正在执行的指令地址加8字节,即是:PC值 = 当前程序执行位置 + 8字节;
处理器处于Thumb状态时,每条指令为2字节,所以PC值为正在执行的指令地址加4字节,即是:PC值 = 当前程序执行位置 + 4字节。
人们一般会习惯性的将正在执行的指令作为参考点,即当前第1条指令。所以,PC总是指向第3条指令,或者说PC总是指向当前正在执行的指令地址再加2条指令的地址。
接着往下一行看:
Line 452: add ip, ip, #8, 20
指令等价于 "ip = ip + 0x8 << 20",因为我使用的机器是 32bit arm cortex-a7,所以向右做circular bit shift等于是向右位移 (32-20 = 12) bit,所以指令变为 "ip = ip + 0x8 << 12 = ip + 0x8000 = 0x8484 + 0x8000 = 0x10484"
再往下一行看
Line 453: ldr pc, [ip, #636]!
pc = [ip + d'636] = [0x10484 + d'636] = [0x10484+0x27c] =[0x10700]
看一下0x10700内存的值是什么:
126 Contents of section .got:
127 106ec ec050100 00000000 00000000 50840000 ............P...
128 106fc 50840000 50840000 50840000 00000000 P...P...P.......
所以 [0x10700]是0x8450,注意这是little endian的排列方式。所以pc会载入0x8450吗??
记得这只是反编译的內容,而非 linker载入程序后的结果,有可能linker会去修改GOT內的值,保险起见,还是通过 gdb去看看这个值。

















 203
203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









