






目录
-
故障分类与优先级
-
通用排查流程
-
常见故障场景与解决方案
-
工具与命令速查
-
预防性措施
-
典型案例分析
1. 故障分类与优先级
1.1 故障等级定义
| 等级 | 描述 | 响应时间要求 |
|---|---|---|
| P0 | 数据库完全不可用(如宕机、数据丢失) | ≤15分钟 |
| P1 | 核心业务功能受损(如性能下降50%) | ≤1小时 |
| P2 | 非核心功能异常(如备份失败) | ≤4小时 |
1.2 常见故障类型
| 故障类别 | 典型表现 |
|---|---|
| 连接问题 | "Too many connections" 错误 |
| 性能问题 | CPU长期>90%,查询响应超时 |
| 数据一致性 | 主从不一致、事务回滚失败 |
| 存储问题 | 磁盘空间不足、IO延迟飙升 |
| 备份/恢复失败 | 备份中断、恢复后数据缺失 |
2. 通用排查流程
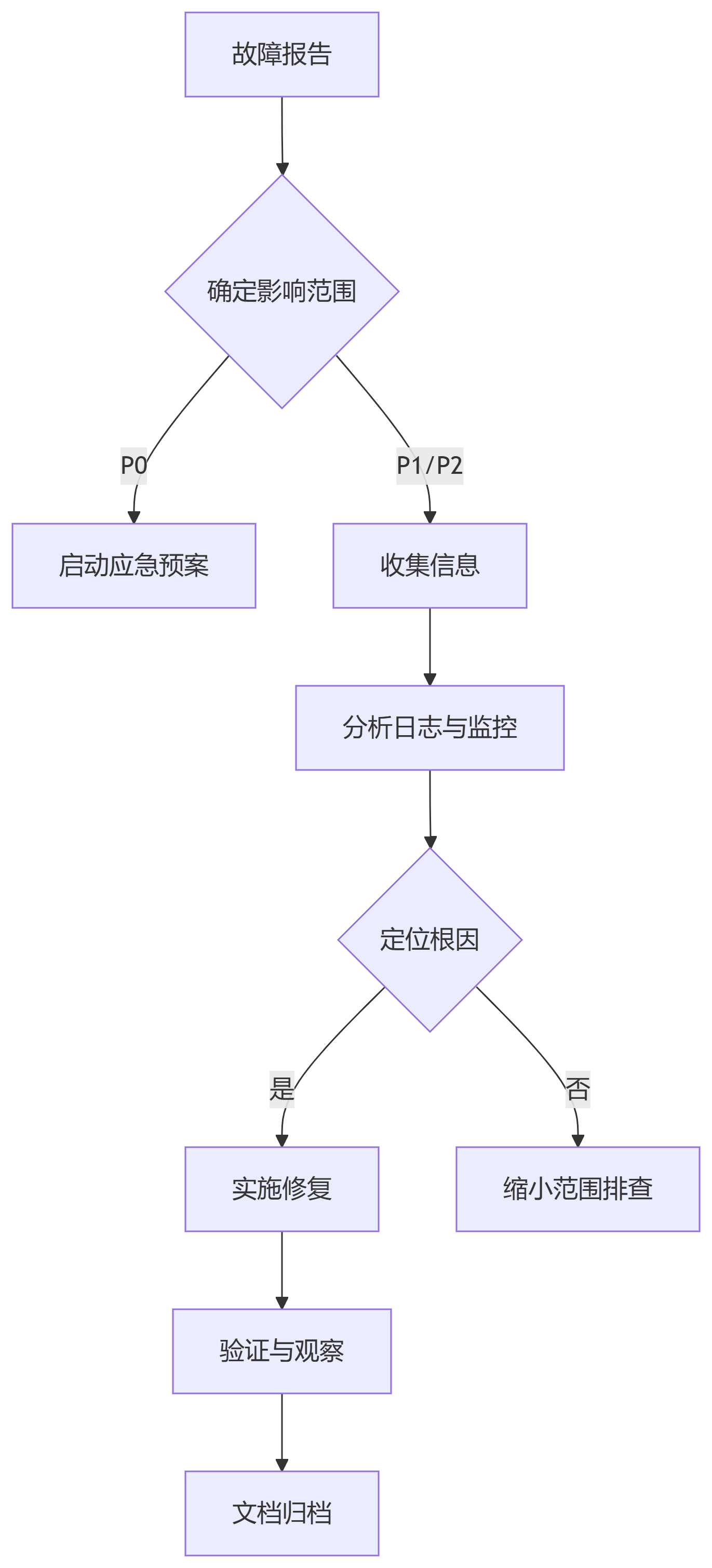
2.1 关键信息收集清单
-
数据库日志
# MySQL SHOW ENGINE INNODB STATUS; SELECT * FROM information_schema.INNODB_TRX; # PostgreSQL SELECT * FROM pg_stat_activity; SELECT * FROM pg_locks; -
系统资源监控
top -c # CPU/内存分析 iostat -x 2 # 磁盘IO监控 netstat -antp # 网络连接检查 -
慢查询识别
-- MySQL SET GLOBAL slow_query_log = 1; SELECT * FROM mysql.slow_log; -- SQL Server SELECT * FROM sys.dm_exec_query_stats;
3. 常见故障场景与解决方案
3.1 连接池耗尽
现象:ERROR 1040 (HY000): Too many connections
排查步骤:
-
检查当前连接数:
SHOW STATUS LIKE 'Threads_connected'; -
分析连接来源:
SELECT user, host, db, command FROM information_schema.PROCESSLIST; -
应急处理:
SET GLOBAL max_connections = 500; -- 临时扩容 KILL [PROCESS_ID]; -- 终止异常连接
3.2 慢查询导致CPU飙升
定位方法:
-- MySQL
SELECT * FROM sys.session WHERE time_ms > 1000;
-- PostgreSQL
SELECT pid, query, NOW() - query_start AS duration
FROM pg_stat_activity
WHERE state = 'active'; 优化方案:
-
添加缺失索引:
EXPLAIN SELECT * FROM orders WHERE user_id = 100; CREATE INDEX idx_user ON orders(user_id); -
重写低效SQL:
-- 反例:全表扫描 SELECT * FROM logs WHERE DATE(create_time) = '2023-10-01'; -- 优化后:范围查询 SELECT * FROM logs WHERE create_time BETWEEN '2023-10-01 00:00:00' AND '2023-10-01 23:59:59';
4. 工具与命令速查
4.1 常用诊断工具
| 工具 | 用途 | 示例命令 |
|---|---|---|
| pt-query-digest | MySQL慢查询分析 | pt-query-digest slow.log |
| pgBadger | PostgreSQL日志分析 | pgbadger postgresql.log |
| mytop | 实时MySQL监控 | mytop -u root -p 123456 |
4.2 紧急恢复命令
-- 强制主从切换(MySQL)
STOP SLAVE;
RESET SLAVE ALL;
CHANGE MASTER TO ...
START SLAVE;
-- 数据误删恢复(需开启binlog)
mysqlbinlog --start-position=123456 binlog.000001 | mysql -u root 5. 预防性措施
5.1 监控体系建设
| 监控项 | 推荐阈值 | 工具集成 |
|---|---|---|
| 连接数使用率 | >80% 告警 | Prometheus + Grafana |
| 复制延迟 | >60秒 告警 | Zabbix |
| 磁盘空间 | >85% 告警 | Nagios |
5.2 定期健康检查
# MySQL检查脚本示例
#!/bin/bash
mysql -e "CHECK TABLE important_table;"
mysql -e "ANALYZE TABLE user_profile;"
mysqldump --single-transaction --all-databases > /backup/full_backup.sql 6. 典型案例分析
案例1:死锁导致事务堆积
现象:
-
每秒事务量从200骤降至5
-
出现大量
Lock wait timeout错误
排查过程:
-
检查当前锁状态:
SHOW ENGINE INNODB STATUS\G -
发现多个事务持有
X锁互相等待 -
解决方案:
-
优化事务逻辑,减少锁范围
-
设置合理的
innodb_lock_wait_timeout
-
案例2:磁盘IO瓶颈
现象:
-
查询响应时间波动大
-
iowait持续高于30%
根因分析:
-
通过
iostat发现磁盘利用率达100% -
检查发现未启用SSD缓存
-
改进措施:
-
升级为NVMe SSD
-
调整
innodb_io_capacity参数
-
附录:


















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









