




 本文深入探讨Java中String类的内部实现,包括不可变性、内存管理、字符串池的运作机制,以及String、StringBuffer和StringBuilder的区别。分析了字符串拼接、比较、转换等常见操作的性能考量。
本文深入探讨Java中String类的内部实现,包括不可变性、内存管理、字符串池的运作机制,以及String、StringBuffer和StringBuilder的区别。分析了字符串拼接、比较、转换等常见操作的性能考量。
- “+”操作符,它执行的加入对原始类型(如int和double),重载对String对象进行操作。’+'两个字符串操作数进行串联。 java不考虑让开发者支持运算符重载。在支持运算符重载像C++语言,可以把一个“+”操作符来执行减法,引起不良代码。 “+”操作符是重载的内部支持字符串连接在java中的唯一操作符。注意到,“+”不在两个任意对象上工作。
字符串的方法
| SN | 方法 | 描述 |
|---|---|---|
| 1 | char charAt(int index) | 返回指定索引处的字符 |
| 2 | int compareTo(Object o) | 该字符串的另一个对象比较 |
| 3 | int compareTo(String anotherString) | 字典顺序比较两个字符串 |
| 4 | int compareToIgnoreCase(String str) | 按字典顺序比较两个字符串,忽略大小写差异 |
| 5 | String concat(String str) | 将指定字符串添加到该字符串的结尾处 |
| 6 | boolean contentEquals(StringBuffer sb) | 当且仅当此String表示字符与指定StringBuffer的顺序相同时返回true |
| 7 | static String copyValueOf(char[] data) | 返回表示所指定的数组中的字符序列的字符串 |
| 8 | static String copyValueOf(char[] data, int offset, int count) | 返回表示所指定的数组中的字符序列的字符串 |
| 9 | boolean endsWith(String suffix) | 测试此字符串是否以指定的后缀结束 |
| 10 | boolean equals(Object anObject) | 比较此字符串指定的对象 |
| 11 | boolean equalsIgnoreCase(String anotherString) | 这个字符串与另一个字符串比较,不考虑大小写 |
| 12 | byte getBytes() | 将此String使用平台默认的字符集的字节序列解码,并将结果存储到一个新的字节数组 |
| 13 | byte[] getBytes(String charsetName) | 将此String使用指定字符集的字节序列解码,并将结果存储到一个新的字节数组。ISO8859-1或GBK或UTF-8 |
| String(…) | 利用构造函数编码 | |
| 14 | void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) | 将这个字符串的字符复制到目标字符数组 |
| 15 | int hashCode() | 返回此字符串的哈希码 |
| 16 | int indexOf(int ch) | 返回此字符串指定字符第一次出现处的索引 |
| 17 | int indexOf(int ch, int fromIndex) | 返回此字符串指定字符,从指定索引的搜索中第一次出现处的索引 |
| 18 | int indexOf(String str) | 返回此字符串的指定子第一次出现处的索引 |
| 19 | int indexOf(String str, int fromIndex) | 返回此字符串的指定从指定索引处的子字符串第一次出现的索引 |
| 20 | String intern() | 返回字符串对象规范表示形式 |
| 21 | int lastIndexOf(int ch) | 返回此字符串指定字符最后一次出现处的索引 |
| 22 | int lastIndexOf(int ch, int fromIndex) | 返回此字符串指定字符最后一次出现处的索引,从指定索引处开始向后搜索 |
| 23 | int lastIndexOf(String str) | 返回此字符串指定子最右边出现处的索引 |
| 24 | int lastIndexOf(String str, int fromIndex) | 返回此字符串的指定子最后一次出现处的索引,指定索引处向后开始搜索 |
| 25 | int length() | 返回此字符串的长度 |
| 26 | boolean matches(String regex) | 判断此字符串是否与给定的正则表达式匹配。 |
| 27 | boolean regionMatches(boolean ignoreCase, int toffset, String other, int ooffset, int len) | 检测两个字符串区域是否是相等的 |
| 28 | boolean regionMatches(int toffset, String other, int ooffset, int len) | 检测两个字符串区域是否是相等的 |
| 29 | String replace(char oldChar, char newChar) | 返回从此字符串中使用newChar替换oldChar所有出现的字符串 |
| 30 | String replaceAll(String regex, String replacement) | 这个替换字符串使用给定的正则表达式匹配并替换每个子字符串 |
| 31 | String replaceFirst(String regex, String replacement) | 这个替换字符串使用给定的正则表达式匹配替换第一个字符串 |
| 32 | String[] split(String regex) | 围绕给定的正则表达式的匹配来拆分此字符串 |
| 33 | String[] split(String regex, int limit) | 围绕给定的正则表达式的匹配来拆分此字符串 |
| 34 | boolean startsWith(String prefix) | 测试此字符串是否以指定的前缀开始 |
| 35 | boolean startsWith(String prefix, int toffset) | 检测此字符串是否从指定索引开始以指定前缀开始 |
| 36 | CharSequence subSequence(int beginIndex, int endIndex) | 返回一个新的字符序列,它是此序列的子序列 |
| 37 | String substring(int beginIndex) | 返回一个新字符串,它是此字符串的子串 |
| 38 | String substring(int beginIndex, int endIndex) | 返回一个新字符串,它是此字符串的子串 |
| 39 | char[] toCharArray() | 这个字符串转换为一个新的字符数组 |
| 40 | String toLowerCase() | 将所有在这个字符串中的字符的使用默认语言环境的规则转为小写 |
| 41 | String toLowerCase(Locale locale) | 将所有在这个字符串中的字符使用给定Locale的规则转为小写 |
| 42 | String toString() | 这个对象(这已经是一个字符串!)本身返回。 |
| 43 | String toUpperCase() | 所有的字符在这个字符串使用默认语言环境的规则转换为大写。 |
| 44 | String toUpperCase(Locale locale) | 所有的字符在这个字符串使用给定的Locale规则转换为大写 |
| 45 | String trim() | 返回字符串的副本,开头和结尾的空白省略 |
| 46 | static String valueOf(primitive data type x) | 返回传递的数据类型参数的字符串表示 |
String
-
String是一个final类,代表不可变的字符序列 。String对象的字符内容是存储在一个字符数组value[]中的。
-
实现了Serializable接口:表示字符串是支持序列化的。
-
实现了Comparable接口:表示String可以比较大小
-
String内部定义了final char[] value用于存储字符串数据
String:代表不可变的字符序列。简称:不可变性。
体现:
- 当对字符串重新赋值时,需要重写指定内存区域赋值,不能使用原有的value进行赋值。
- 当对现有的字符串进行连接操作时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
- 当调用String的replace()方法修改指定字符或字符串时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
- 通过字面量的方式(区别于new)给一个字符串赋值,此时的字符串值声明在字符串常量池中。
- 字符串常量池中是不会存储相同内容的字符串的。
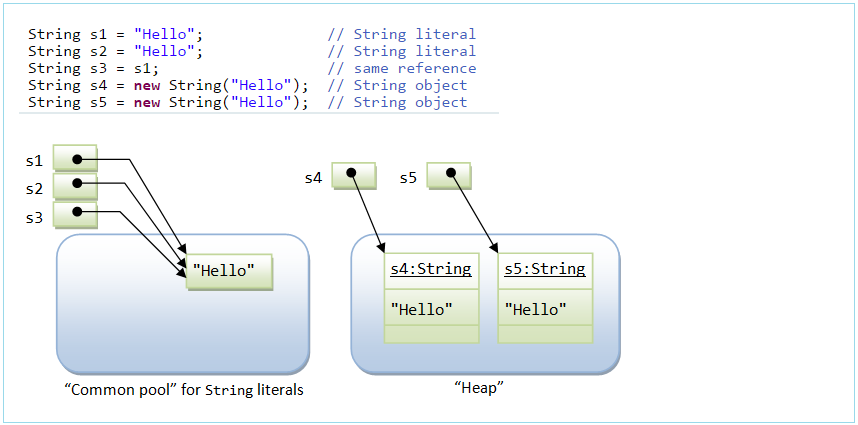
String s1 = "abc";//字面量的定义方式
String s2 = "abc";
System.out.println(s1 == s2);//比较s1和s2的地址值//true
\2. String位于java.lang包中,java程序默认导入java.lang包下的所有类。
\3. java字符串就是Unicode字符序列,例如字符串“java”就是4个Unicode字符’J’、’a’、’v’、’a’组成的。
\4. java没有内置的字符串类型,而是在标准java类库中提供了一个预定义的类String,每个用双引号括起来的字符串都是String类的一个实例。
构造器
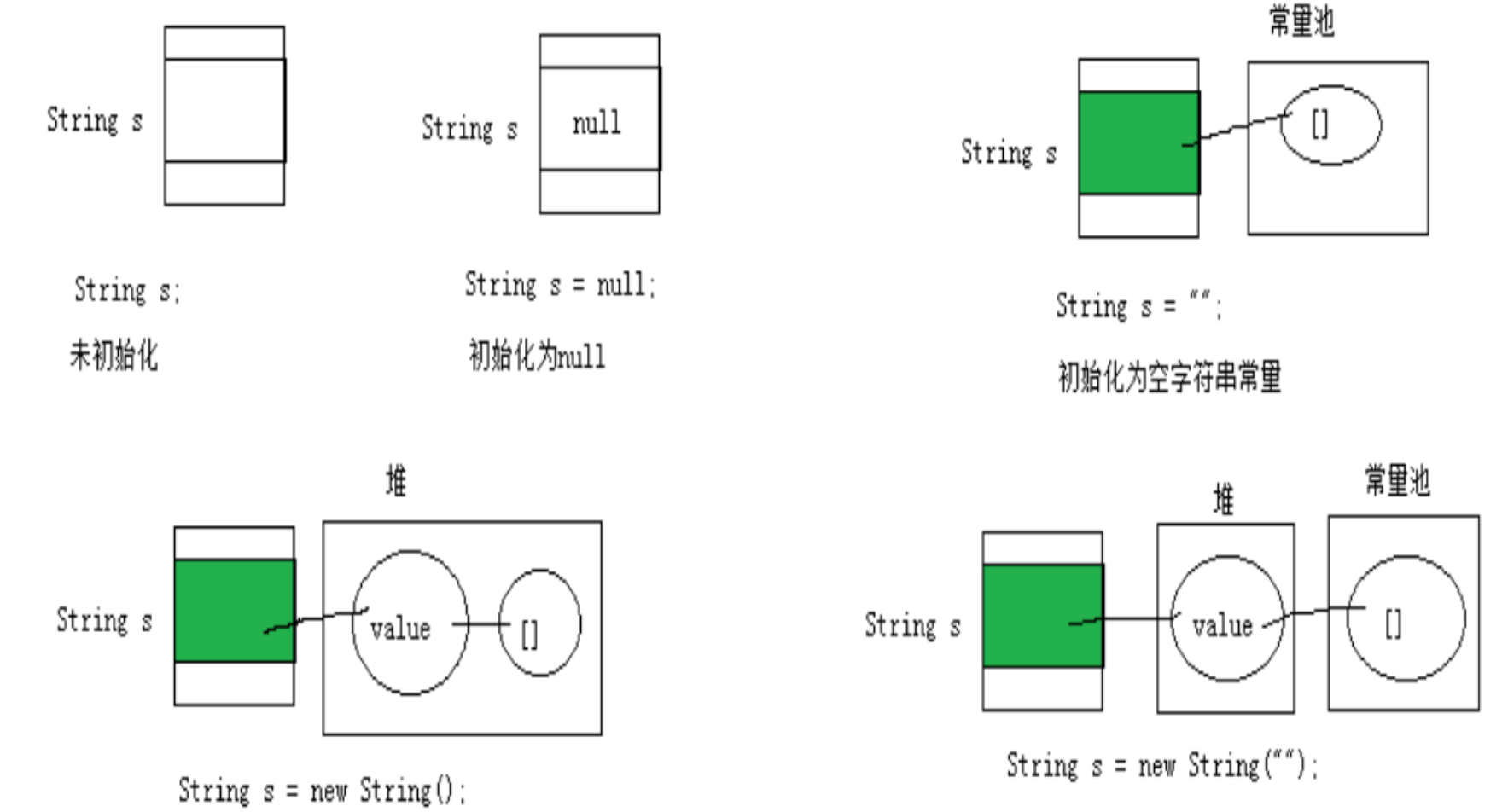
String str = "hello";//放在方法区(常量池)
//本质上this.value = new char[0];
String s1 = new String();//放在堆区
//this.value = original.value;
String s2 = new String(String original);
//this.value = Arrays.copyOf(value, value.length);
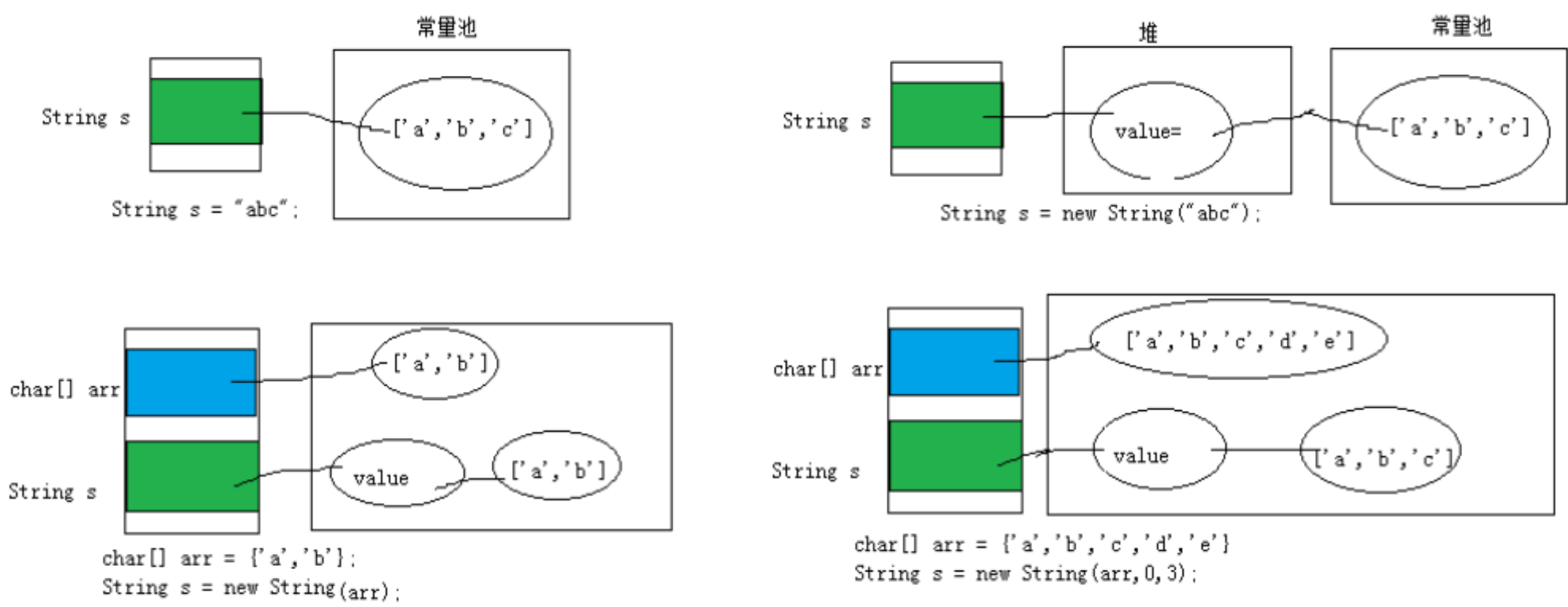
String s3 = new String(char[] a);
String s4 = new String(char[] a,int startIndex,int count);
判断String为空☆★
public static boolean isNotEmptyString(String str){
if (str != null && !"".equals(str.trim()) && !"null".equals(str)){
return true;
}
return false;
}
1. null表示这个字符串不指向任何的东西,如果这时候你调用它的方法,那么就会出现空指针异常。
2. ""表示它指向一个长度为0的字符串,这时候调用它的方法是安全的。
3. null不是对象,""是对象,所以null没有分配空间,""分配了空间,例如:
String str1 = null; str引用为空
String str2 = ""; str应用一个空串
str1还不是一个实例化的对象,儿str2已经实例化。
对象用equals比较,null用等号比较。
如果str1=null;下面的写法错误:
if(str1.equals("")||str1==null){
}
正确的写法是 if(str1==null||str1.equals("")){
//先判断是不是对象,如果是,再判断是不是空字符串 }
4. 所以,判断一个字符串是否为空,首先就要确保他不是null,然后再判断他的长度。
String str = xxx;
if(str != null && str.length() != 0) {
}
https://www.cnblogs.com/Nico-luo/p/8024781.html
内存:堆和常量池
- s=“abc”;//放在了字符串常量池
- s =new String();//放在了堆区,value指向也是堆区[]
- s=new String("");//放在了堆区,但是value数组指向常量池
- s=new String(“abc”);//放在了堆区,但是value指向常量池中同一个abc
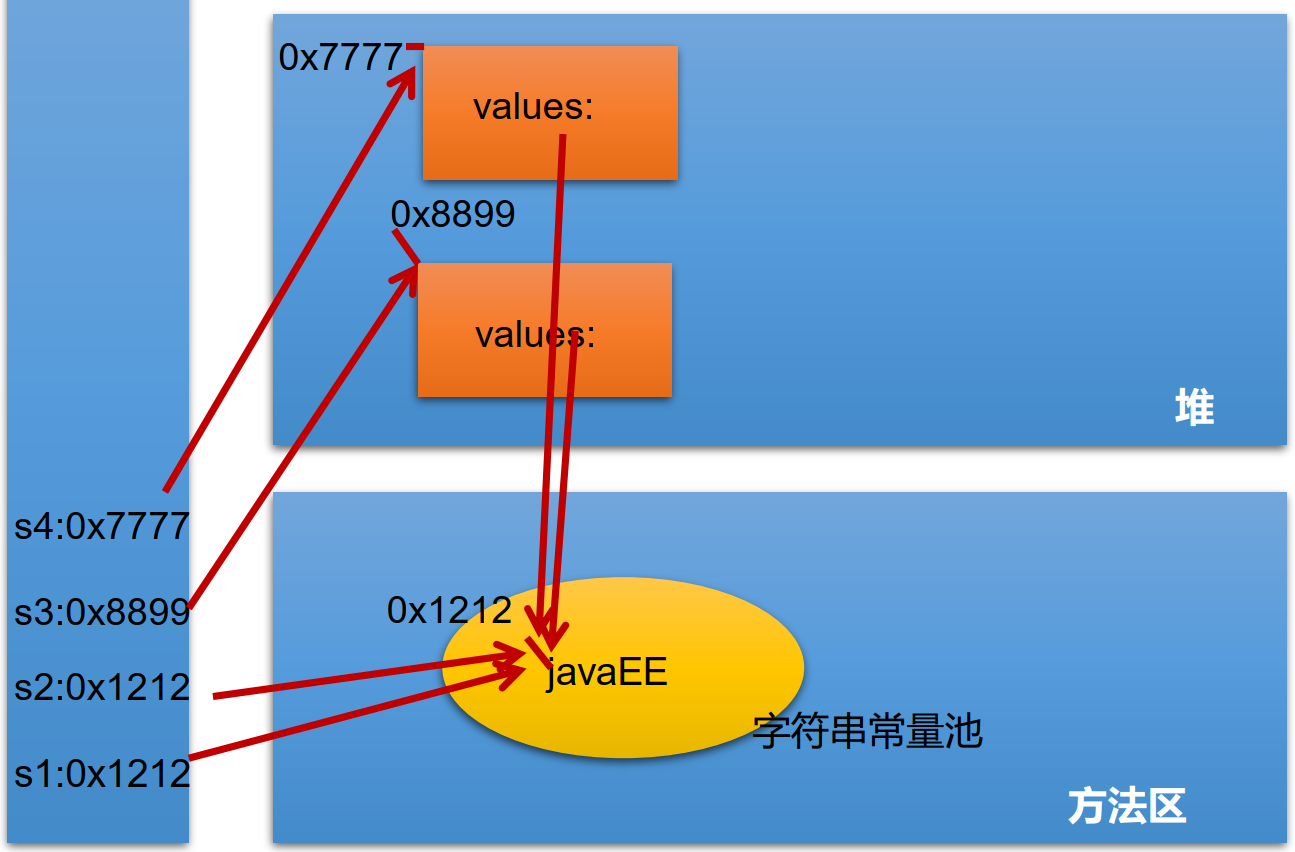
例子
//如下4个语句,只在常量池中有一个javaEE
String s1 = "javaEE";
String s2 = "javaEE";
String s3 = new String("javaEE");//value指向常量池
String s4 = new String("javaEE");
System.out.println(s1 == s2);//true
System.out.println(s1 == s3);//false
System.out.println(s1 == s4);//false
System.out.println(s3 == s4);//false
//Person类中有成员String name和int age。构造器Person(String name, int age)
Person p1 = new Person();
p1.name = "atguigu";
Person p2 = new Person();
p2.name = "atguigu";
System.out.println(p1.name .equals( p2.name)); //
System.out.println(p1.name == p2.name); //
System.out.println(p1.name == "atguigu"); //
String s1 = new String("bcde");
String s2 = new String("bcde");
System.out.println(s1==s2); //
Person p1 = new Person("Tom",12);
Person p2 = new Person("Tom",12);
System.out.println(p1.name == p2.name);//true//value指向常量池 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6726
6726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









