







本文尚在整理更新中,未完结
说明
- 首先需要搭建源码环境,不多说了,网上有很多,比如:https://www.cnblogs.com/jun1019/p/7989127.html
- 流程图:https://www.processon.com/view/link/6180a0461efad41d03fa6f62
- 思维导图:https://www.processon.com/view/link/614f1c35e0b34d69dd7a493a
- 注释的代码上传到了:https://gitee.com/HanFerm/kafka-source-2.1.0
- 流程可以参照流程图,本文以知识点为小节进行记录
- 本文学习方式:自己标注源码+2个B站视频引导关键点
生产者源码篇对开发的意义:
- 从源码角度分析发MQ时指定分区和key时各种情况会发生什么
- 知道了造成生产乱序的原因是inFlightRequest
- 知道了MQ大小是被batch大小限制的
- 发送的时机与控制的时间参数
- 怎么筛选发往leader的
对研究源码的意义:
- 熟悉NIO,尤其是像tomcat我们读的是服务端的源码,而此篇是NIO客户端的源码
- 粘包拆包的发生点和解决方案
- 回调机制
流程
请点击我的processOn画的图:https://www.processon.com/view/link/6180a0461efad41d03fa6f62
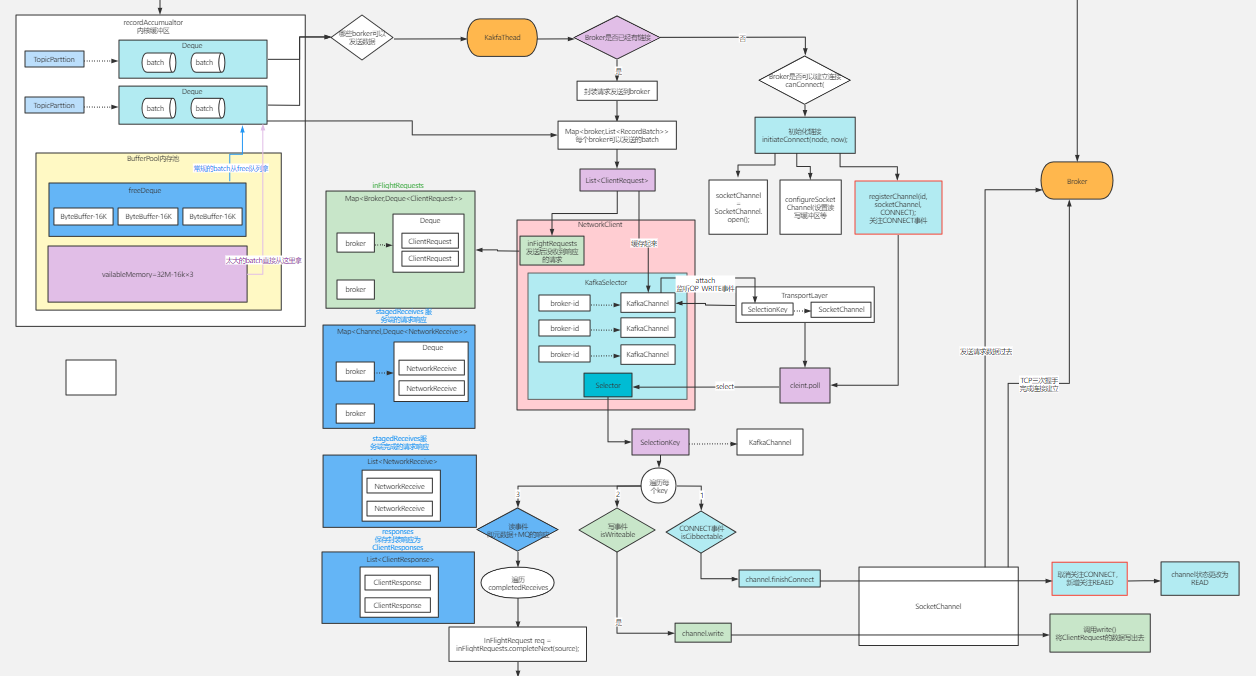
核心组件
(1)核心组件:Partitioner,用来决定每条消息是路由到Topic的哪个分区里
(2)核心组件:Metadata,这个是对于生产端来说非常核心的一个组件,他是用来从broker集群去拉取元数据的Topics(Topic -> Partitions(Leader+Followers,ISR)),后面如果写消息到Topic,才知道这个Topic有哪些Partitions,Partition Leader所在的Broker
- 初始化拉取:初始化的时候,直接调用Metadata组件的方法,去broker上拉取了一次集群的元数据过来
- 元数据定时更新:每隔一小段时间就再次发送请求刷新元数据,metadata.max.age.ms,默认每隔5分钟一定会强制刷新一下
- 元数据临时拉取:还有在发送消息的时候,如果发现你要写入的某个Topic对应的元数据不在本地,那么也会主动发送请求到broker尝试拉取这个topic对应的元数据,如果你在集群里增加了一台broker,也会涉及到元数据的变化
(3)核心参数:每个请求的最大大小(1mb),缓冲区的内存大小(32mb),重试时间间隔(100ms),缓冲区填满之后的阻塞时间(60s),请求超时时间(30s)
(4)核心组件:RecordAccumulator,缓冲区,负责消息的复杂的缓冲机制,发送到每个分区的消息会被打包成batch,一个broker上的多个分区对应的多个batch会被打包成一个request,batch size(16kb)
- 默认情况下,如果光光是考虑batch的机制的话,那么必须要等到足够多的消息打包成一个batch,才能通过request发送到broker上去;
- 但是,如果你发送了一条消息,但是等了很久都没有达到一个batch大小,所以说要设置一个
linger.ms(逗留时间),比如说5ms,如果5ms还没凑出来一个batch,那么就必须立即把这个消息发送出去
(5)核心组件:网络通信的组件,NetworkClient,一个网络连接最多空闲多长时间(9分钟),每个连接最多有几个request没收到响应(5个),重试连接的时间间隔(50ms),Socket发送缓冲区大小(128kb),Socket接收缓冲区大小(32kb)
(6)核心组件:Sender线程,负责从缓冲区里获取消息发送到broker上去,request最大大小(1mb),acks(1代表只要leader写入成功就认为成功),重试次数(0,无重试),请求超时的时间(30s),sender线程类叫做“KafkaThread”,线程名字叫做“kafka-producer-network-thread”,此处线程直接被启动
(7)核心组件:序列化组件,拦截器组件
元数据
元数据信息保存在类Cluster中
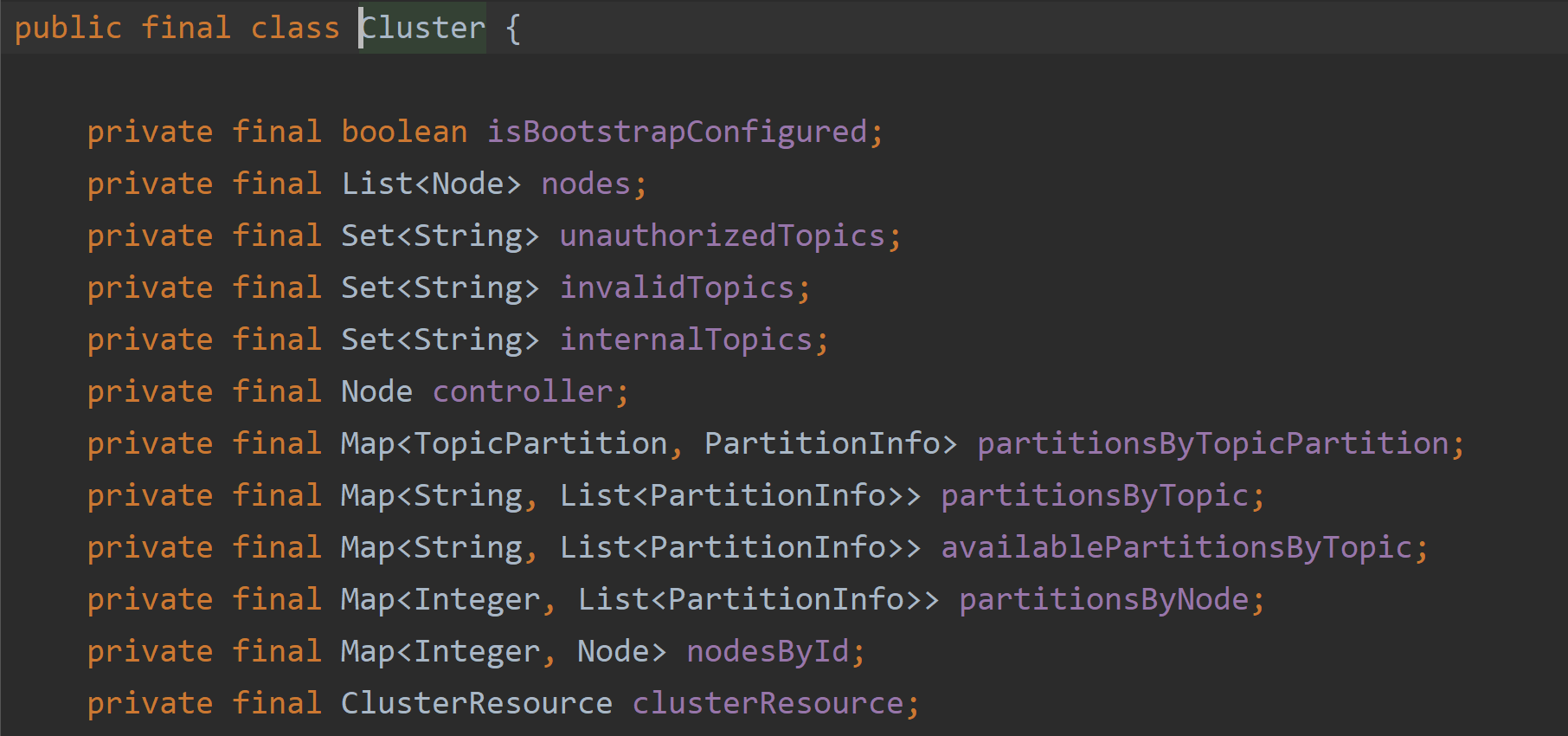
一般通过这个方法可以知道当前是否有元数据信息(每隔一段时间会失效)
- 本地是否有元数据:Cluster cluster = metadata.fetch();
- 远程拉取元数据metadata.awaitUpdate(version, remainingWaitMs);
生产者初始化
KafkaProducer在初始化的时候是不会去拉取集群的元数据的,做了一个最最基本的初始化,也就是仅仅把我们配置的那个broker的地址放了进去,在客户端缓存集群元数据的时候,采用了哪些数据结构
producer启动的时候会初始化一个send线程,该send线程用来拉取broker的元数据信息。
KafkaProducer.java构造器
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
// 另一个线程
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
// 去看run方法
/**@see KafkaThread#run() */
this.ioThread.start();
生产者发送流程
https://gitee.com/HanFerm/kafka-source-2.1.0/blob/master/clients/src/main/java/org/apache/kafka/clients/producer/KafkaProducer.java
KafkaProducer.doSend
我们先大致来看一下KafkaProducer.send()方法发送消息时大致的运行的流程
(1)回调自定义的拦截器
(2)同步阻塞等待获取topic元数据
如果你要往一个topic里发送消息,必须是得有这个topic的元数据的,你必须要知道这个topic有哪些分区,然后根据Partitioner组件去选择一个分区,然后知道这个分区对应的leader所在的broker,才能跟那个broker建立连接,发送消息
所以在发送MQ的时候,先调用同步阻塞的方法,去等待先得获取到那个topic对应的元数据,如果此时客户端还没缓存那个topic的元数据,那么一定会发送网络请求到broker去拉取那个topic的元数据过来,但是下一次就可以直接根据缓存好的元数据来发送了
刚开始他没有去拉取集群的元数据,而是在后面根据你发送消息时候的需要,要给哪个topic发送消息,再去拉取那个topic对应的元数据,这就是懒加载的设计思想,按需加载思想
(3)序列化key和value
你的key和value可以是各种各样的类型,比如说String、Double、Boolean,或者是自定义的对象,但是如果要发送消息到broker,必须对这个key和value进行序列化,把那些类型的数据转换成byte[]字节数组的形式
(4)基于获取到的topic元数据,使用Partitioner组件计算消息对应的分区
(5)检查要发送的这条消息是否超出了请求最大大小,以及内存缓冲最大大小
(8)设置好自定义的callback回调函数以及对应的interceptor拦截器的回调函数
(7)将消息添加到内存缓冲里去,该工作是由RecordAccumulator组件负责的
(8)如果某个分区对应的batch填满了,或者是新创建了一个batch,此时就会唤醒Sender线程,让他来进行工作,负责发送batch
如果发送MQ时设置了异步发送方式,通过先进入内存缓冲,同时设置一个callback回调函数的思路,在发送完成之后来回调你的函数通知你消息发送的结果,异步运行的后台线程配合起来使用,基于异步线程来发送消息
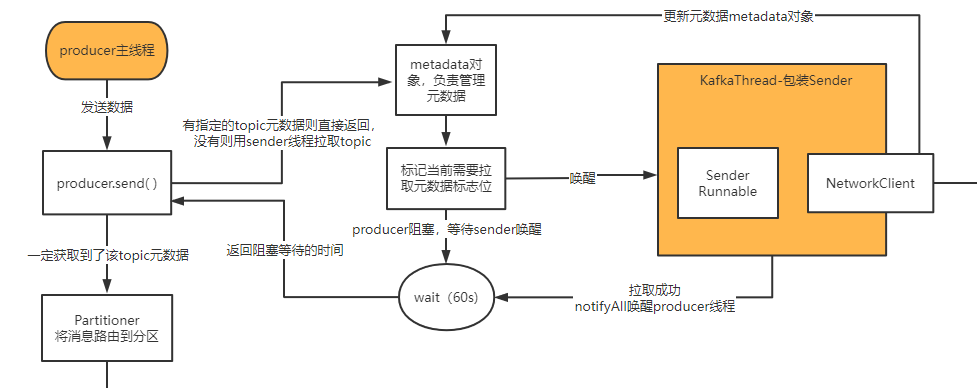
topic元数据拉取
kafka采用异步的方式拉取topic元数据(也就是说使用的是sender线程),但是他们是生产者与消费者的关系,也就是说product线程会await等待sender线程唤醒。
sender从broker拉取对应的topic的元数据,
接下来肯定是分为两种情况:
(1)Sender线程成功的在60s内把topic元数据加载到了,然后缓存到了Metadata里去,更新了version版本号,而且此时一定会尝试把wait阻塞等待的主线程给唤醒,让主线程直接返回阻塞等待的时长
(2)如果wait(60s)一直超时了,你的Sender线程都没加载成功元数据,此时人家在60s后自动醒来了,此时会直接超时抛异常
总之,发送MQ第一步就是拉取topic对应的元数据,没有则阻塞等sender唤醒
源码对应这块:

阻塞时间
maxBlockTimeMs,决定了你调用product.send()方法的时候,最多会被阻塞多长时间,所以这个方法决定了你的send在一些异常的情况下,比如说拉取topic的元数据,结果跟broker网络有问题,在一段时间后还是拉取不到
在你把数据放到内存缓冲的时候,如果内存缓冲满了,此时最多就只能阻塞这么长时间就必须返回了,如果你希望send()方法被阻塞的时间可以延长或者缩减,此时你可以自己去动手配置这个参数
在客户端的方法尝试等待获取topic元数据的过程中,核心的逻辑,就是说先必须唤醒Sender线程,然后呢就会通过一个while循环,直接去wait释放锁,尝试最多就是等待默认的60s的时间
分区规则
拥有元数据后,就根据根据topic对应的分区来进行将MQ路由到指定的分区上了,分区路由有3种策略
- 如果指定了分区,则发往对应的分区
- 如果没有指定分区,则根据key哈希(murmur2算法)得到一个要发往的分区
- 如果没有指定key
- topic维护一个AtomicInteger,初始值是一个随机的integer类型的数字,就可以对该
数字+1%分区数即可得到当前应该发送到哪个分区了,从而均匀地发往各个分区
- topic维护一个AtomicInteger,初始值是一个随机的integer类型的数字,就可以对该
Sender
KafkaThread封装sender,sender封装NetworkClient
生产者三个存储结构
内存池>分区的队列>batch
而free队列是整个kafka共享的
缓存池
入口:KafkaProducer.doSend
然后看下面的步骤
/** 第七步 把消息放入RecordAccumulator(消息收集器)
* 然后由RecordAccumulator将消息封装成一个批次一批次地去发送 */
RecordAccumulator.RecordAppendResult result =
accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
然后我们进入accumulator.append()方法
https://gitee.com/HanFerm/kafka-source-2.1.0/blob/master/clients/src/main/java/org/apache/kafka/clients/producer/internals/RecordAccumulator.java
RecordAccumulator这个类我们主要关注append()方法,他会多次使用tryAppend()方法来将消息放入队列,但是tryAppend()方法有个问题是它不会创建batch,而只会用现成的batch(新创建的或者别的MQ没有用完的空间),所以需要append()来完成创建batch的操作
batch
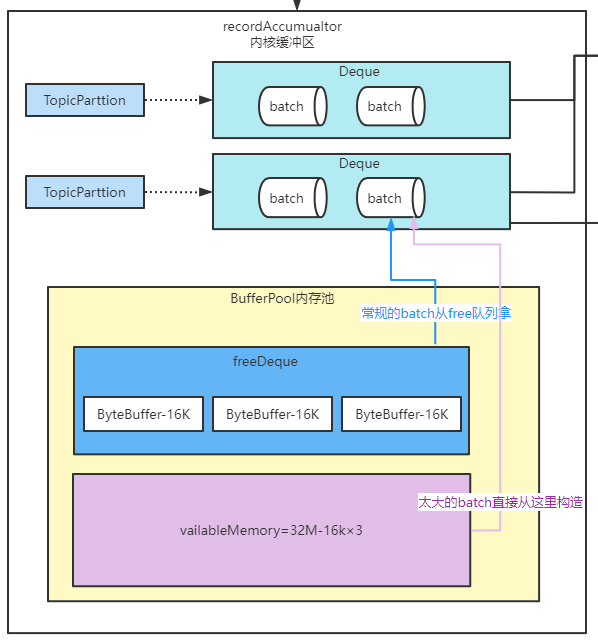
1)、给batch分配内存
入口:doSend–>RecordAccumulator.append–> free.allocate(size, maxTimeToBlock);
代码:https://gitee.com/HanFerm/kafka-source-2.1.0/blob/master/clients/src/main/java/org/apache/kafka/clients/producer/internals/BufferPool.java
这里的逻辑其实不难,区分下面的2个区别即可
- tryAppend()是追加到现有batch
- append()是构造batch
batch引用着每个buffer
分配batch大小的时候会分两种情况来分配:
- 正常batch:如果16KB够用,就分配16KB。并且如果free队列有空batch,优先使用空batch,没有空batch则缩减nonPooledAvailableMemory
- 大batch:如果MQ大小>16KB,则使用MQ大小作为batch。永远跟free队列无关,只使用nonPooledAvailableMemory,并且如果nonPooledAvailableMemory不够用还会尽可能少地释放free队列的batch
- 如果最终还不够用,会阻塞添加进waiters,如果超过maxBlockMs就抛异常。当有batch内存放回来bufferPool的时候就唤醒waiters。具体后面讲
分配完batch就可以调用batch.tryAppend()成功了
回收:
- 正常batch:回收到free队列
- 大batch:使用立即回收,直接进入内存池
// 如果是16KB,clear后放到free列表中
if (size == this.poolableSize && size == buffer.capacity()) {
buffer.clear();
this.free.add(buffer);
} else {
// 如果不是16KB,如1M,直接放回nonPooledAvailableMemory,而不是放回内存池
this.nonPooledAvailableMemory += size;
}
双重检查:2个线程都去申请内存时,因为有如下的double check,所以不会分配2个batch,但是问题在于已经分配过空间了,那么线程2的空间应该释放掉。在2.1版本中解决方案是:如果空间分配过了,buffer对象被batch引用,然后buffer=null赋值为空。在finally块中,if(buffer!=null)释放buffer。这块代码去这里查看吧。https://gitee.com/HanFerm/kafka-source-2.1.0/blob/master/clients/src/main/java/org/apache/kafka/clients/producer/internals/RecordAccumulator.java
1.2)申请不到够大的batch
如果最终还不够用,会阻塞添加进waiters,如果超过maxBlockMs就抛异常。当有batch内存放回来bufferPool的时候就唤醒waiters。
- 创建condition:Condition moreMemory = this.lock.newCondition();
- 添加进waiters:waiters.addLast(moreMemory);
- while(获得大小<需求大小)
- 是否超时 = !await(时间)
- 谁来通知await:sender完成
- await超时的话抛异常
- 优先是否free队列,free队列没了的时候再拿nonPooledAvailableMemory
- 是否超时 = !await(时间)
Condition moreMemory = this.lock.newCondition();
this.waiters.addLast(moreMemory);
2)给batch追加MQ-tryAppend()
上个知识点:给batch分配内存 以及 获取还有空间的batch
相关代码:https://gitee.com/HanFerm/kafka-source-2.1.0/blob/master/clients/src/main/java/org/apache/kafka/clients/producer/internals/ProducerBatch.java
入口:doSend–>申请buffer–>封装buffer为batch–>将MQ添加进batch–>ProducerBatch.tryAppend()
KafkaProducer支持多线程来发送MQ,并且保证了线程安全。要关注他的线程安全性,关注
ProducerBatch.tryAppend()即可tryAppend的线程安全由上层的
synchronized (dq)保证,也就是对batch操作要锁队列
Record
https://gitee.com/HanFerm/kafka-source-2.1.0/blob/master/clients/src/main/java/org/apache/kafka/common/record/Record.java
队列
要发送消息时,通过map.get(分区)获取对应的队列,没有则创建队列,创建分区的队列就是map.put(分区,队列)
在kafka中队列被CopyOnWriteM要发送消息时,通过map.get(分区)获取对应的队列,没有则创建队列,创建分区的队列就是map.put(分区,队列)ap封装着,Map<分区,队列>,它使用了读写分离的思想,只有新创建队列时才是写,下面几种说法等价
- put时为写
- 为分区创建队列时才是put,为队列添加batch并不是put
https://gitee.com/HanFerm/kafka-source-2.1.0/blob/master/clients/src/main/java/org/apache/kafka/common/utils/CopyOnWriteMap.java
还是跟随消息收集器来追溯,分区与batch的对应关系是通过CopyOnWriteMap来保存的
// 而RecordAccumulator构造器中
batches = new CopyOnWriteMap<TopicPartition, Deque<ProducerBatch>>();
CopyOnWriteMap是自己定义的,实现线程安全和读写分离
public class CopyOnWriteMap<K, V> implements ConcurrentMap<K, V> {
private volatile Map<K, V> map;
@Override
public synchronized V put(K k, V v) {
// 开辟新的空间实现读写分离
Map<K, V> copy = new HashMap<K, V>(this.map);
// 插入数据
V prev = copy.put(k, v);
// 替换
this.map = Collections.unmodifiableMap(copy);
return prev;
}
写时复制的思想
写时复制适合读多写少的场景,每次更新的时候,都是copy一个副本,在副本里来更新,接着替换原来的副本。
最根本的好处是:写的时候不会阻塞读
写时复制如何保证线程安全:只在更新引用时加锁
kafka中的写时复制:kafka线程安全,可以多个线程并发调用send()方法,他使用一个map来存储所有的分区对应的队列(该队列存储batch)。在kafka中map是ConcurrentMap的,通过如下的方式确保创建唯一的队列
private Deque<ProducerBatch> getOrCreateDeque(TopicPartition tp) {
// 获取分区对应的队列
Deque<ProducerBatch> d = this.batches.get(tp);
// 如果已经有了队列,不存在线程安全问题了
if (d != null)
return d;
// 如果两个线程都判断为null后,都创建
d = new ArrayDeque<>();
// 用putIfAbsent来代替double check,起到的效果是一样的,所以还是线程安全
Deque<ProducerBatch> previous = this.batches.putIfAbsent(tp, d);
if (previous == null)
return d;
else
return previous;
}
从下面可以看出来,虽然继承了ConcurrentMap,但是 跟ConcurrentMap没事关系,都是利用HashMap+synchronized来玩的,每个线程有自己的map,new map时也是传入了原map,所以这里只是保证了每个队列的引用不会乱。
kafka获取到队列后,队列不是线程安全的,他使用的是synchronized来保证add batch时线程安全
public class CopyOnWriteMap<K, V> implements ConcurrentMap<K, V> {
private volatile Map<K, V> map;
@Override
public synchronized V put(K k, V v) {
// 开辟新的空间实现读写分离
Map<K, V> copy = new HashMap<K, V>(this.map);
// 插入数据
V prev = copy.put(k, v);
// 替换
this.map = Collections.unmodifiableMap(copy);
return prev;
}
唤醒sender尝试发送batch时机
可以看下面的batch是否该发送了的小节
前提知识点:给batch追加MQ
入口:doSend–>给batch追加MQ,即accumulator.append(–>唤醒sender线程–>异步线程sender.run
从下面的代码可以看出来,是batch满了或者后一个batch已经被创建好了
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
/** 第八步 唤醒sender线程,它是真正发送数据的线程
* @see handleCompletedMetadataResponse
* @see Metadata#update(Cluster newCluster, Set<String> unavailableTopics, long now) {
* */
this.sender.wakeup();
}
这里没解释清楚,唤醒sender,按理说sender会自己判断的,这里只是初步唤醒了sender
batch什么时候满
ProducerBatch.tryAppend里有recordsBuilder.hasRoomFor(
是介于MemoryRecordsBuilder.java这个类来判断的,总体就一句this.writeLimit >= estimatedBytesWritten() + recordSize;即容量<需要的大小
然后buffer.flip从写转成读
producer线程发送MQ阻塞吗?
前面的分析告诉我们主线程只是把MQ封装到batch后放到accumulator,然后唤醒sender线程,自己就退出了,什么时候发送MQ是sender线程控制的
如果你非要producer线程阻塞,可以在外部调用get方法。这里的逻辑可以参照

sender线程异步
从前面我们也能知道,主线程调用唤醒sender线程时并没有告诉sender线程该发送哪个topic了,而只是唤醒sender线程去轮询检查那些topic、分区、batch可以去发送了
sender发送MQ
前提知识点:batch发送时机
入口:给batch追加MQ后唤醒sender线程–>sender继续执行run
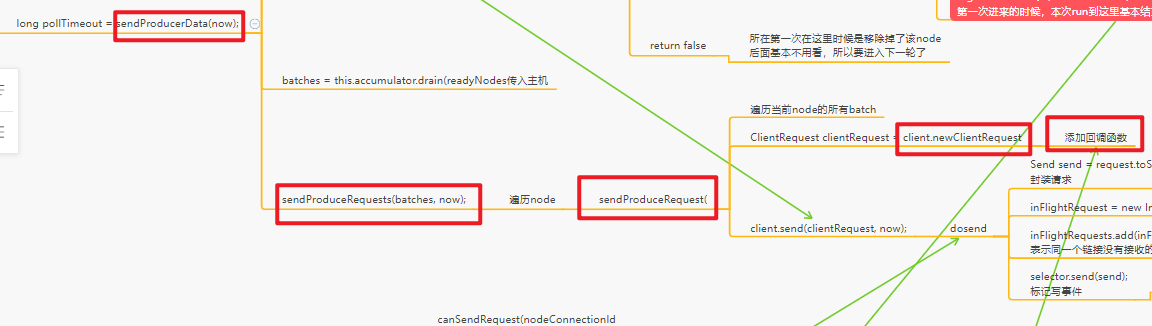
sender.run()
void run(long now) {
/** 准备发送的数据请求 */
long pollTimeout = sendProducerData(now);
/** 把准备好的消息请求真正发送出去 NIO.poll */
client.poll(pollTimeout, now);
}
所以我们进入sendProducerData(now);方法,去该发送批次要发送那些batch
准备发送内容
前提知识点:发送MQ
入口:给batch追加MQ后唤醒sender线程–>sender继续执行run–>准备发送的内容,即Sender.sendProducerData–>RecordAccumulator.ready
遍历所有的分区队列–>找到leader
- 找到leader:取出队头batch,进行判断batch是否该发送了
- 也就是说,是否可以发送是以leader为单位的,准备好也是
readyNodes.add(leader) - 判断batch是否可以发送出去不是判断哪个batch可以发送了,也不是用分区来判断的,而是判断broker
- 也就是说,是否可以发送是以leader为单位的,准备好也是
- 没找到leader:unknownLeaderTopics.add(part.topic());
把判断为发送的batch添加到集合readyNodes.add(leader);
发送的单位
对每个Broker都创建一个ClientReqeust,包括了多个Batch,就是在这个Broker上的多个Leader Partition所对应的Batch,聚合起来组成一个ClientRequest,形成一个请求,发送到Broker上去
如果此时判断出来这个Batch是可以发送出去的,此时就会将这个Batch对应的那个Partiton的Leader Broker给放入到一个Set里去,他在这里找的不是说找哪些Partition可以发送数据,也不是找Batch
他在这里找的是哪些Broker有数据可以发送过去,而且通过Set进行了去重,可能对于一个Broker而言,是有多个Partiton的Batch可以发送过去的
代码编写的技巧,如果你的方法要返回的是一个复杂的数据结构,此时可以定义一些Bean,里面封装你要返回的数据,哪些Broker可以发送数据过去,下一次来检查是否有Batch可以发送的时间间隔,是否有Partiton还不知道自己的Leader所在的Broker
判断batch是否该发送了
这里不要考虑是否支持重试,全部支持重试
只会判断队头batch是否该发送了
总的判断为
boolean sendable = full || expired || exhausted || closed || flushInProgress();
if (sendable && !backingOff) {
- full:batch满的batch
- 该batch不是队尾了 || batch的full标志位为true
- expired:超过了重试和逗留时间,这两个事件用timeToWaitMs整体表示
- 第一次:batch的attempts参数为0,所以不是重试,
timeToWaitMs=逗留时间。看的是逗留时间 - 第二次:失败时间<要求的重试时间,则不重试,防止重试太频繁
timeToWaitMs=逗留时间;超过时间可以重试了,则timeToWaitMs=重试时间
- 第一次:batch的attempts参数为0,所以不是重试,
- exhausted:有waiters申请不到内存了,赶紧发送出去吧
- closed:生产者关闭了
- flushInProgress:是否有现车在等待flush
注意:判断为该发送后添加的是broker,而不是batch和分区
注意,这里的判断只是为了初始把leader对应的node添加进要发送的node而已
既然有上面的用法,就说明我们只是为了判断node而已,没有必要遍历全部batch的,仅仅需要看一下每个deque的第一个batch即可。
比如,有10个分区,每个分区一个deque,有的Dequeue里可能有多个Batch,但是这个算法一轮下来,每个Parititon只会查看他的first Batch,此时就会判断他的first Batch是否可以发送。
如果这个Partiion的first Batch可以发送,此时就把这个Partition leader所在的Broker放入一个readyNodes集合里,而不是对一个Partiton的所有Dequeue进行遍历。这里只看first Batch,非常的关键
假设有4个Partiton的first Batch可以发送,这4个Partiton Leader分别对应在2个Broker上,每个Broker有两个Partition Leader,此时readyNodes里就有两个Node,2个Broker会在里面
但是如果一个Partition的first Batch都不可以发送,此时会利用这个Batch来计算一下nextReadyCehckDelayMs,假设此时有6个Partitio的first Batch都不可以发送,会综合利用这个6个Partiton的firstBatch的timeToLeft(linger.ms - 已经等待的时间),取一个最小值,就代表说最快可以发送的那个batch的等待时间
下一次来检查是否有Batch可以发送起码要等待那个时间,比如说10ms
逗留时间和重试时间
- 逗留时间:lingerMs逗留时间到了必须发送出去,默认是0,表明不需要等待,来一条消息就发送一条消息,很明显不合适。所以我们在发送数据的时候,一定记得去配置这个参数,假设配置100ms,表示最多等待100ms后必须发送出去
- 第一次发送数据:attempts()==0->backingOff=false,截止时间为逗留时间lingerMs。
- 第二次发送数据:重试时间还没到也是逗留时间
- 重试时间:第一次发送MQ失败后,必须超过重试间隔时间后才能再次重试,防止重试太频繁
前提知识点:判断batch是否该发送了
boolean backingOff = batch.attempts() > 0 && waitedTimeMs < retryBackoffMs;
/**
* 第一次发送数据,之前也么有消息,没有重试这一说
* backingOff为false
* timeToWaitMs=lingerMs 默认是0,表明不需要等待
* 如果默认是0的话,来一条消息就发送一条消息,很明显不合适
* 所以我们在发送数据的时候,一定记得去配置这个参数
* 假设配置100ms,表示最多瞪大100ms后必须发送出去
* */
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
筛选可以发送的batch
前提知识点:准备发送内容
入口:给batch追加MQ后唤醒sender线程–>sender继续执行run–>准备发送的内容,即Sender.sendProducerData–>RecordAccumulator.ready
因为有的分区没找到leader信息,所以要把这些分区的batch去除
- 初步筛选出来一些可以发送数据的Broker,这些broker只是备选,还需要判断Broker到底是否可以发送数据过去呢?
当前不能处于元数据加载的过程,而且下一次要更新元数据的间隔时间为0,现在没有加载元数据,但是马上就应该要加载元数据了,如果对上述条件判断是非的话,要不然是正在加载元数据,或者是还没到加载元数据的时候
我们就认为现在还没到加载元数据的时候,就认为这个条件是false,满足了就可以了
为什么前面一定要有这个条件?假设此时必须要更新元数据了,就不能发送请求,必须要等待这个元数据被刷新了再次去发送请求
(1)有一个Broker连接状态的缓存,先查一下这个缓存,当前这个Broker是否已经建立了连接了,如果是的话,才可以继续判断其他的条件
(2)Selector,你大概可以认为底层封装的就是Java NIO的 Selector,但凡是看过我的NIO课程,跟着做NIO研发分布式文件系统,Selector上要注册很多Channel,每个Channel就代表了跟一个Broker建立的连接
(3)inFlightRequests,有一个参数可以设置这个东西,默认是对同一个Broker同一时间最多容忍5个请求发送过去但是还没有收到响应,所以如果对一个Broker已经发送了5个请求,都没收到响应,此时就不可以继续发送了
必须同时满足3个条件,才可以认为这个Broker可以发送数据过去
kafka网络设计
sender拉取元数据和发MQ都涉及网络
主要类是NetworkClient
前提知识点:网络是否准备好
入口:构建sender线程–>封装NetworkClient–>封装selector,即NIO
使用:sender发送MQ或拉取元数据
代码:https://gitee.com/HanFerm/kafka-source-2.1.0/blob/master/clients/src/main/java/org/apache/kafka/common/network/Selector.java
public class Selector implements Selectable {
/** NIO的selector */
private final java.nio.channels.Selector nioSelector = java.nio.channels.Selector.open();
broker的链接状态可以使用设计模式里的“状态机模式”来表达,其实就是枚举而已,然后让这个状态可以互相流转
状态包括:null,CONNECTING,CONNECTED,DISCONNECTED。针对不同的状态,还可以做不同的事情,如果是null就可以发起连接,如果连接成功,就可以进入已连接的状态,如果中间发生连接的故障,就进入连接失败
KafkaSelector
最最核心的一点,就是在KafkaSelector的底层,其实就是封装了原生的Java NIO的Selector,很关键的组件,就是一个多路复用组件,他会一个线程调用他直接监听多个网络连接的请求和响应
我们看看kafka自定义的Selector的注释,他主要说明什么初始化链接并不是真正建立了网络,而只有调用poll()方法时才是真正建立的网络连接:https://gitee.com/HanFerm/kafka-source-2.1.0/blob/master/clients/src/main/java/org/apache/kafka/common/network/Selector.java
KafkaSelector相关参数
- maxReceiveSize,最大可以接收的数据量的大小
- connectionsMaxIdle,每个网络连接最多可以空闲的时间的大小,就要回收掉
- Map<broker-string, KafkaChannel> channels,这里保存了每个broker id到Channel的映射关系,对于每个broker都有一个网络连接,每个连接在NIO的语义里,都有一个对应的SocketChannel,我们估计,KafkaChannel封装了SocketChannel
- List completedSends,已经成功发送出去的请求
- List completedReceives,已经接收回来的响应而且被处理完了
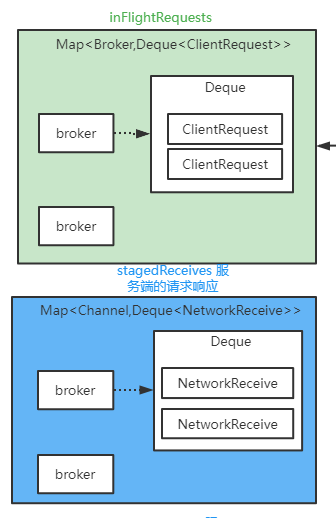
- Map<KafkaChannel, Dequeue> stagedReceives,每个Broker的收到的但是还没有被处理的响应
KafkaChannel
代码:https://gitee.com/HanFerm/kafka-source-2.1.0/blob/master/clients/src/main/java/org/apache/kafka/common/network/KafkaChannel.java
broker id对应一个网络连接,一个网络连接对应一个KafkaChannel,底层对应的是SocketChannel,SocketChannel对应的是最最底层的网络通信层面的一个Socket,套接字通信,Socket通信,TCP
Send,应该是说要交给这个底层的Channel发送出去的请求,可能会不断的变换的,因为发送完一个请求需要发送下一个请求
NetworkReceive:这个Channel最近一次读出来的响应,先暂存在这里,也是会不断的变换的,因为会不断的读取新的响应数据
TransportLayer:封装了底层的Java NIO的SocketChannel
链接是什么
链接的单位是生产者与node的链接,不是分区,也不是batch
此外有个inFlightRequest代表该broker有几个没有收到响应的请求
broker之间是一个channel,多个请求
网络是否准备好
入口:sender要发送MQ–>Sender.sendProducerData()–>NetworkClient.ready()
代码:https://gitee.com/HanFerm/kafka-source-2.1.0/blob/master/clients/src/main/java/org/apache/kafka/clients/NetworkClient.java
NetworkClient.ready()
- 先从缓存中看是否已经有该node的链接了
- 缓存中没有则尝试建立连接该node
@Override
public boolean ready(Node node, long now) {
// 要发送MQ到的node是否具备发送的条件//没有缓存等时就不走这,走下面尝试建立网络
if (isReady(node, now))
return true;
// 第一次进来判断是否可以建立好网络
if (connectionStates.canConnect(node.idString(), now))
initiateConnect(node, now);
// 第一次进来时候虽然init了网络,然后还是return false
return false;
}
网络没有建立好会发送MQ吗?
发送MQ前会检查网络是否建立好,没有建立则先建立网络。
重新回到里的ready逻辑
- 第一次进入ready时,虽然会初始化网络,但是还是return false,代表没有ready,从而remove掉该node,代表不发送MQ
- 最后回到sender.run()的第二个方法 client.poll,这时候不不发送,所以下一次循环run才发送
总结:初始化网络和发送MQ不再一次run中执行
是否可以链接
入口:NetworkClient.ready–>connectionStates.canConnect–>initiateConnect(node, now);
public boolean canConnect(String id, long now) {
// 获取node的状态
NodeConnectionState state = nodeState.get(id);
// 没有链接过该node,则可以与broker建立链接
if (state == null)
return true;
else { // 建立过链接了,该链接是否还可以用呢?
// 断开了 && 并且断开时长>重连时长==>可以重新连接
return state.state.isDisconnected() &&
now - state.lastConnectAttemptMs >= state.reconnectBackoffMs;
}
}
初始化链接
前提知识点:网络是否准备好
入口:NetworkClient.ready–>connectionStates.canConnect==>NetworkClient.initiateConnect(node, now);–>selector.connect
/**
* Initiate a connection to the given node
* NetworkClient 初始化和某broker的链接
*/
private void initiateConnect(Node node, long now) {
String nodeConnectionId = node.idString();
// 新建NodeConnectionState并设置链接状态为CONNECTING
this.connectionStates.connecting(nodeConnectionId, now, node.host(), clientDnsLookup);
// 设置node ip
InetAddress address = this.connectionStates.currentAddress(nodeConnectionId);
// 里面也有初始化,但是往往并非完全初始化好
selector.connect(nodeConnectionId,
new InetSocketAddress(address, node.port()),
this.socketSendBuffer,
this.socketReceiveBuffer);
代码:https://gitee.com/HanFerm/kafka-source-2.1.0/blob/master/clients/src/main/java/org/apache/kafka/common/network/Selector.java
但是第一次只是创建了channel,还没有建立连接,所以取看client.poll,在里面有selector.poll来建立连接
connect进一步初始化Selector
入口:Selector.connect
- 开启channel: SocketChannel.open();
- 配置连接configureSocketChannel
- 生产者和broker是同主机的话立马连接成功:doConnect(socketChannel, address);
- 注册关注事件,得到SelectionKey:SelectionKey = registerChannel(id, socketChannel, SelectionKey.OP_CONNECT);
- 借助KafkaChannel关联SelectionKey和channel,都是一对一的关系
- 是双向关联:有个有意思的是key.attach(channel);
- 保存链接
- 连接成功则取消关注OP_CONNECT事件
- 借助KafkaChannel关联SelectionKey和channel,都是一对一的关系
不管连接成功与否,都需要缓存起来,以后来真正连接的时候才能找到
配置连接configureSocketChannel
入口:Selector.connect–>Selector.configureSocketChannel()
- keepalive:主要是避免客户端和服务端任何一方如果断开连接之后,别人不知道,一直保持着网络连接的资源;所以设置这个之后,2小时内如果双方没有任何通信,那么发送一个探测包,根据探测包的结果保持连接、重新连接或者断开连接
- 缓冲区:设置channel的发送和接收的缓冲区大小 128k和32k
- TcpNoDelay:是否禁用nagle算法
- 由来:小而多的通信会使得网络拥塞。
- 解决:nagle算法适用于需要发送大量数据的场景,会收集小的数据包成大的数据包,再发送出去
- true:关闭agle算法,发送出去的数据包立马通过网络传输过去
保存channel
入口:NetworkClient.ready–>connectionStates.canConnect==>NetworkClient.initiateConnect(node, now);–>selector.connect–>registerChannel(id, socketChannel, SelectionKey.OP_CONNECT);–>this.channels.put(id, channel);
你直接初始化了一个SocketChannel然后就发起了一个连接请求,接着不管连接请求是成功还是暂时没成功,都需要把这个SocketChannel给缓存起来,接下来你才可以基于这个东西去完成连接,或者是发起读写请求
借助KafkaChannel关联SelectionKey和channel:将SelectionKey、brokerid封装为了KafkaChannel,他是先把SelectionKey封装到TransportLayer里面去(SelectionKey底层是跟SocketChannel是一一对应起来),Authenticator,brokerid,直接封装一个KafkaChannel
缓存起来立即建立好连接的SelectionKey
// map<broker,channel>
this.channels.put(id, channel);
具体完成者连接需要到poll方法里才能实现,我们现在先不看
筛选没初始化完全的channel
前提知识点:准备发送内容
入口:给batch追加MQ后唤醒sender线程–>sender继续执行run–>准备发送的内容,即Sender.sendProducerData–>RecordAccumulator.ready》》》result.readyNodes.iterator();
正式完成链接建立
入口:给batch追加MQ后唤醒sender线程–>sender继续执行run–>准备发送的内容,》》client.poll(pollTimeout, now);–>pollSelectionKeys()–>channel.finishConnect()
链接流程:send里有2个主要的方法,在第一个阶段只是注册了CONNECT事件,然后注册WRITE事件,即请求元数据去了,然后读取响应
KafkaChannel.finishConnect()–>transportLayer.finishConnect();
- if key.isConnectable()
- 注册感兴趣事件 取消OP_CONNECT,关注OP_READ
lruConnections,因为一般来说一个客户端不能放太多的Socket连接资源,否则会导致这个客户端的复杂过重,所以他需要采用lru的方式来不断的淘汰掉最近最少使用的一些连接,很多连接最近没怎么发送消息
比如说有一个连接,最近一次使用是在1个小时之前了,还有一个连接,最近一次使用是在1分钟之前,此时如果要淘汰掉一个连接,你会选择谁?LRU算法,明显是淘汰掉那个1小时之前才使用的连接
selector.select获取事件
- select()》》》nioSelector.selectedKeys();》》》Selector.pollSelectionKeys(toPoll, false, endSelect);–>
- channel.finishConnect()》》》key.isWritable()》》》channel.write();
注册各种事件的时机
这里建议参考我思维导图的红色部分:https://www.processon.com/view/link/614f1c35e0b34d69dd7a493a
1、注册CONNECT事件的时机是:在sender线程里run方法的long pollTimeout = sendProducerData(now);,它在里面初始化网络的时候注册CONNECT事件
2、注册READ事件的时机是:在sender线程里run方法的client.poll里,发现key是key.isConnectable()时,在channel.finishConnect()里进行如下的操作
ey.interestOps(key.interestOps() & ~SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
3、注册WRITE事件发batch:在第二次进入sender线程时,执行sendProducerData(now);里的sendProduceRequests(batches, now);,它遍历node,最终在client.send(clientRequest, now);里完成注册写事件
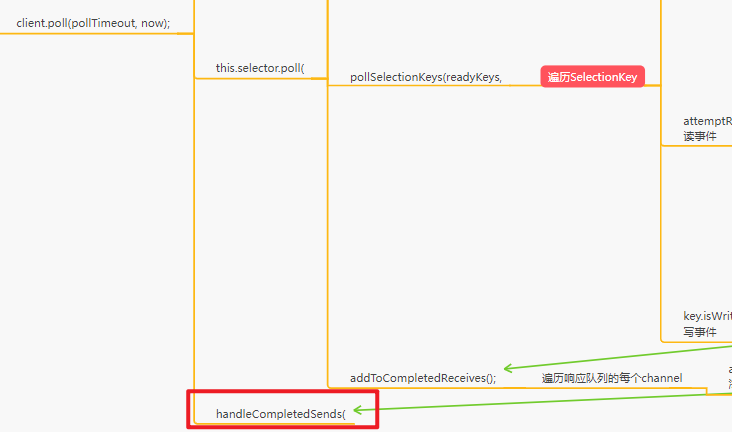
处理事件
Selector.pollSelectionKeys
入口:Sender.run–>NetworkClient.poll–>
- metadataUpdater.maybeUpdate(now);》》
- selector.poll(》》
- Selector.select(timeout);》》
- nioSelector.selectedKeys();
- pollSelectionKeys(readyKeys, )遍历keys
- key.isConnectable()
连接事件 - attemptRead(key, channel);
- key.isWritable()
- key.isConnectable()
- NetworkClient.handleCompletedSends(responses, updatedNow);
下一轮进来后run方法,ready方法就返回true了
建立连接后获取batch-drain
入口:Sender.run–>Sender.sendProducerData()–>筛选》》》accumulator.drain(cluster, result.readyNodes
获取broker上所有的partition,遍历broker上的所有的partitions,对每个partition获取到dequeue里的first batch,放入待发送到broker的列表里,每个broker都有一个batches,最后有一个map,放了这些数据
没有readyNodes时,直接回退到client.poll方法里
二进制写ByteBuffer
- offset
- size
- crc
- magic valye
- attribute
- timestamp
- key.length
- key
- value.length
- value
ByteBufferOutputStream包裹了ByteBuffer,持有一个针对ByteBuffer的输出流,接着会把ByteBufferOutputStream给包裹在一个压缩流里,gzip、lz4、snappy,如果是包裹在压缩流里,写入的时候会先进入压缩流的缓冲区
压缩流会把一条消息放在缓冲区里,用压缩算法给压缩了,再写入底层的ByteBufferOutputStream里去
如果是非压缩的模式,最最普通的情况下,就是DataOutputStream包裹了ByteBufferOutputSteram,然后写入数据,Long、Byte、String,都会在底层转换为字节进入到ByteBuffer里去
内存空间管理的方式,包括他有内存缓冲的核心数据结构,内存缓冲池,ByteBuffer,如何通过IO流将数据写入ByteBuffer的,如何按照二进制协议规范来写一条消息的
发送出去的请求,需要按照kafka的二进制协议来定制数据的格式
他需要包含对应的请求头,api key,api version,acks,request timeout,接着才是请求体,里面就是包含了对应的多个batch的数据,最后的最后,一定是把刚才说的那些东西都给打成一个二进制的字节数组
ClientRequest里面就是封装了按照二进制协议的格式,放入了组装好的数据,发送到broker上去的有很多个Topic,每个Topic有很多Partition,每个Partitioin是对应就一个batch的数据发送过去
发送请求
接下来就是要一个一个的去发送请求了,看看依托于KafkaChannel和NIO selector多路复用的机制,是如何把这个请求给发送出去的,其实就是依托inFlightRequests去暂存了正在发送的Request
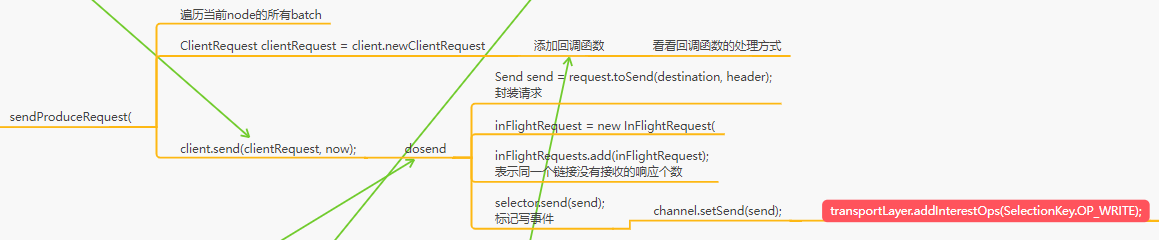
为每个batch构建client
sendProduceRequest
将batch封装为clientRequest,由NetworkClient缓存到InflightRequest,然后包装为RequestSend来发送给channel
发送完后更改状态
如果说已经发送完毕数据了,那么就可以取消对OP_WRITE事件的关注,否则如果一个Request的数据都没发送完毕,此时还需要保持对OP_WRITE事件的关注,而且如果发送完毕了,就会放到completedSends里面去
发送后注册读事件
发送完请求如何关注NIO里的OP_READ事件呢?
key.interestOps(key.interestOps() & ~SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
SeletionKey,里面封装了Selector对一个连接关注那个连接上的哪些事件,OP_CONNECT,OP_WRITE,OP_READ,取消对OP_CONNECT事件的关注,增加对OP_READ事件的一个关注,主要都是通过二进制位运算来实现的
一旦建立好连接之后,天然的就会去监听这个连接的OP_READ事件
要发送请求的时候,会把这个请求暂存到KafkaChannel里去,同时让Selector监视他的OP_WRITE事件,增加一种OP_WRITE事件,同时保留了OP_READ事件,此时Selector会同时监听这个连接的OP_WRITE和OP_READ事件
发送完了请求之后,对事件的监听会怎么样呢?一旦写完请求之后,就会把OP_WRITE事件取消监听,就是此时不关注这个写请求的事件了,此时仅仅保留关注OP_READ事件
ack与inFlightRequests
实际上就是在刚刚的那个poll方法里,对一个broker发送出去的request
expectResponse应该是通过acks计算出来的,如果说acks = 0的话,也就是不需要对一个请求接收响应,此时expectResponse应该就是false,这个时候直接就会把这个Request从inFlightRequests里面移出去
直接就可以返回一个响应了,其实就是做一个回调
如果说一次请求没有把所有的数据都发送出去的话,会怎么样?
一次发送不完
如果Kafka一个请求一次write操作没有把全部的数据都写到broker去,相当于出现了类似于拆包的问题,一个请求一次没法发送完毕,此时如何处理的呢?这个是非常工业级的一个问题的处理方案
如果说一个请求对应的ByteBuffer中的二进制字节数据一次write没有全部发送完毕,如果说一次请求没有发送完毕,此时肯定remaining是大于0,此时就不会取消对OP_WRITE事件的监听
假设此时针对某个Broker是说,此时是可以再次发送一个Request了,必须得先判断一下,这个Broker上一次发送的Request请求是否发送完毕了,那个request中的数据是否发送完了呢?
即使发送完毕了,还得限制为最多只发送5个request是没有收到响应的
如果说上一次 request出现了类似拆包的问题,一次请求没有发送完毕,此时下次就不会继续往这个broker发送请求了,但是此时针对这个broker还是保持着OP_WRITE的监听,下次调用poll,会发现对这个broker可以再次执行WRITABLE事件
大不了再次对SocketChannel调用write方法,把ByteBuffer里剩余的数据继续往Broker去写,上述的过程重复多次,一定会把这个请求发送完毕的
如何对同个broker同时发送多个inFlightRequests
假设如果说一个Request已经发送完毕了,那么接下来是否可以在接收到响应之前,就继续发送下一个Request呢?
缓存响应
你之前发送出去的请求,如果说broker给你返回了响应消息,那么你一定会感知到一个OP_READ事件,在这里会使用while循环,针对一个broker的连接,反复的读,推测一下,因为是这样子的
你的一个broker是可以通过一个连接连续发送出去多个请求的,这个多个请求可能都没有收到响应消息,此时人家broker端可能会连续处理完多个请求然后连续返回多个响应给你,所以在这里,你一旦去读数据
可能会连续读到多个请求的响应
所以说在这里处理OP_READ事件的时候,必须要通过一个while循环,连续不断的读,可能会读到多个响应消息,全部放到一个暂存的集合里,stagedReceives
底层的KafkaChannel.read -> TransportLayer.read -> SocketChannel.read,我是怎么区分开来不同的请求对应的响应的呢?我到底是怎么通过底层的NIO去进行 响应的读取的呢?
粘包拆包
粘包:之前提及过,在producer端发送MQ的时候,一个链接默认是可以最多忍受5个发送出去了但没有收到响应的个数,这就意味着,服务端在发送请求响应的时候,可能一个请求中带有多个响应,这里就设计了粘包的问题
发送请求时不会出现粘包类的问题,因为可以控制一次只能把一个请求给人家发送过去,所以只会出现拆包类的问题。
拆包:producer可能分多次读取服务端响应的记过,这里就涉及了拆包的问题
producer的拆包:一个请求一次没有发送完毕,就需要通过执行多次OP_WRITE事件才能发送出去
解决粘包拆包的问题可以使用添加length字段或使用特殊分隔符来解决。
kafka使用长度编码方式来解决TCP的粘包、拆包问题
源码入口:sender.run–>client.poll(pollTimeout, now);–>this.selector.poll(–>pollSelectionKeys(readyKeys,—>attemptRead(key, channel);
直接看思维导图的下面版块吧
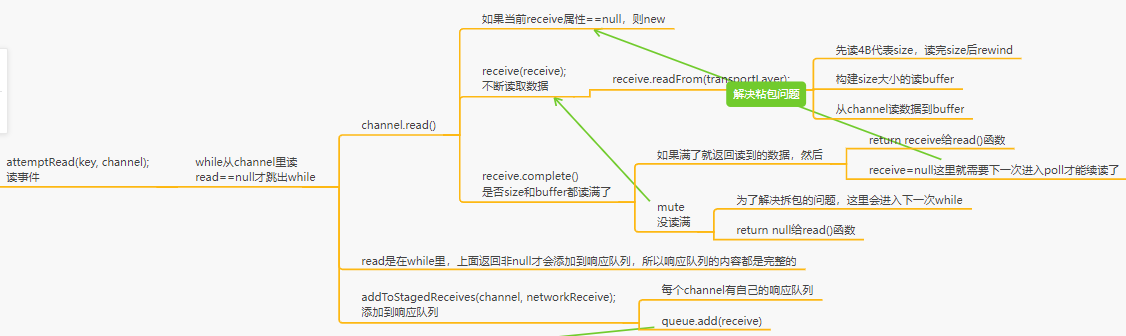
主要内容就是size和buffer都是java-NIO里的buffer,buffer根据size制定大小
size和buffer是NetworkReceive的final属性
细节点:
1)size读取完后:ByteBuffer.rewind,把position设置为0,一个ByteBuffer写满之后,调用rewind,把position重置为0,此时就可以从ByteBuffer里读取数据了
2)拆包是如何解决的:每个channel里有个receive,没读完它是不会赋值为null的,每一次响应都会new一个新的NetworkReceive。所以没读完下次poll进来时候还有读事件,还是这个receive对象,然后继续进入while的read读。
size和buffer都是java-NIO里的buffer,buffer根据size制定大小NetworkReceive对象的
size和buffer是NetworkReceive的final属性,所以它当然知道size和buffer哪个读满了没有
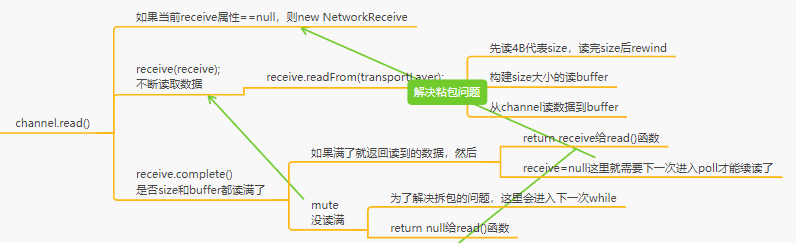
处理响应stagedReceives
发送MQ后我们也收到响应了,也解决粘包的问题封装好了
在粘包拆包那里讲解了响应封装完整后放到每个channel独有的响应队列Map<Channel,Deque<NetworkReceive>> stagedReceives
然后在selector.poll的最后一步又将响应从stagedReceive队列放到了completedReceives这个list
对应的思维导图是这里:
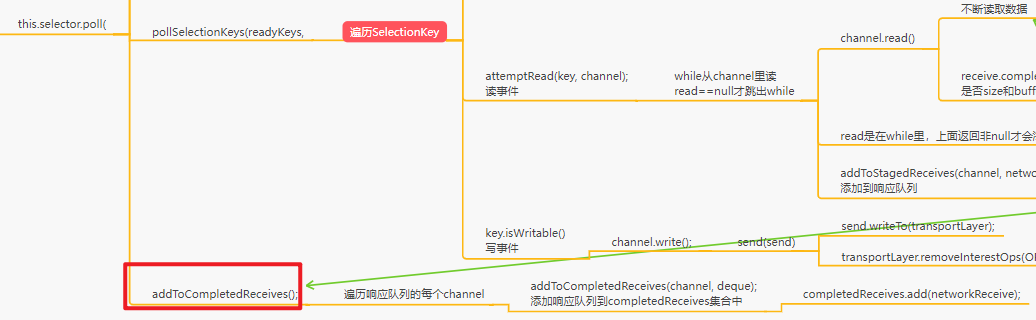
如果一个连接一次OP_READ读取出来多个响应消息的话,在这里仅仅只会把每个连接对应的第一个响应消息会放到completedReceives里面去,放到后面去进行处理,此时有可能某个连接的stagedReceives是不为空的
completedReceives他是如何进行处理的:答案在这
这里几个集合的关系如下:
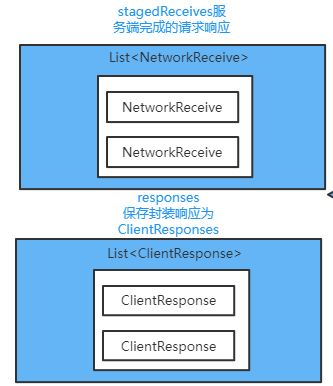
处理完成
确认读取完毕的响应消息放在completedReceives
handleCompletedReceives()方法将响应放到了指定的集合
而completeResponses(responses);遍历ClientResponse并callback.onComplete(this);

但是回调函数什么时候放进去的呢?
是在这个地方,就是在发送时候封装进去的
处理响应时仅仅是处理回调函数,还需要处理异常之类的内容,所以当初设计回调函数的时候是包装了一下的
从inFlightRequests中,移除掉一个request,腾出来一个位置,其中的一个请求是获取到了响应消息了,不管是不是成功,去解析他的响应,读取到的数据一定是一段二进制字节数组的一段数据
这段数据一定是按照人家的二进制协议来定义的,比如说返回什么什么东西,什么什么东西,把这段二进制的字节数组,一点一点从里面,先读取8个字节,代表了什么,再读取20个字节,代表了什么
放到一个Java对象里去,就代表了他的响应消息
correlation_id,是全局唯一的,用来标识一次请求的,也就是说你发送请求的时候,就会带过去这个东东,读取到的响应,首先一定是可以读取到这个correlation_id的,就知道对应的是哪一次请求
你一定是可以在inFlighRequest里面是知道他对应的请求的
对于同一个broker,连续发送多个request出去,但是会在inFlighRequest里面排队
inFlighRequests -> <请求1,请求2,请求3,请求4,请求5>
此时对broker读取响应,响应1,响应2,都在stagedReceives -> 响应1放在completedReceives -> 只会获取到响应1
就是直接从inFlighRequests里面移除掉请求1,按照顺序,先发送请求1,那么就应该先获取到请求1对应的响应1,而不是响应2
其实在这里,仅仅是解析一个响应,还没有对响应进行处理呢!
回调函数
主要就是对获取到的请求进行二进制字节数组的解析,把人家回传过来的数据给解析出来,把响应和请求一一匹配起来,一次请求是对应的每个Partition会有一个Batch放在这个请求里
所以说响应也是一样的,对每个Partition只有一个Batch是有对应的请求的
如果正常情况下,就会回调你的每条消息对应的一个回调函数
相关逻辑在下图
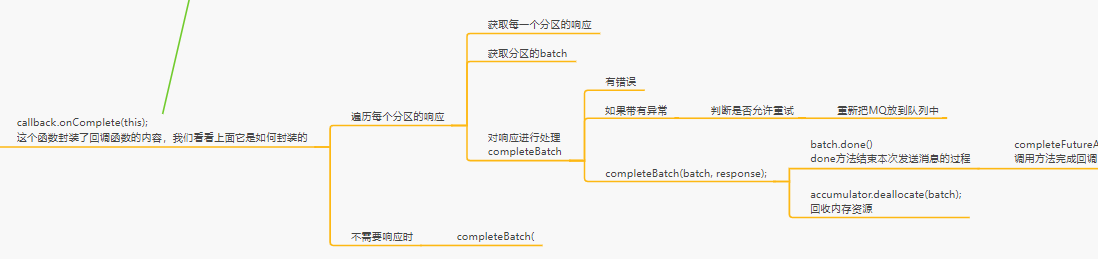
回收内存资源
在执行完回调函数后会回收内存资源,入口如下图

异步处理响应
一旦说某个请求的响应中,发现了其中某个Batch有异常,就会首当其冲 判断一下,这个Batch是否可以进行重试,首先一个Batch的重试次数(默认从0开始),必须得小于设置的重试次数
默认情况下,是不允许你重试的,异常就是异常,他会在回调函数里通知你,这条消息是有异常的,比如说在客户端缓存的元数据里,知道Partition的Leader在Broker01上,结果此时发送消息过去到那个Parititon Leader
但是Broker01上突然发现,这Leader之前做过一次切换,Leader已经转移到Broker02上去了,此时Broker01会给你一个异常,意思就是说LeaderNotExistException,在我这里找不到对应的Leader
是很常见的,完全是可以进行重试的,但是如果要重试,就必须得重新拉取一下这个Topic的对应的元数据,感知一下这个Partition的Leader现在已经转移到哪里去了,比如说已经到Broker02上去了
重试下一次就应该试试去发送请求到那个Broker上去
NetworkException,网络抖动,网络通信突然短暂的失败,也是可以进行重试的
推测这个重试应该就是说把这个RecordBatch给放回到Accumulator里的Queue里去,Batch的内存资源被释放的过程看一下
释放batch到队列
就是应该释放这个Batch底层的内存块的资源,给还回到内存缓冲池里去,让下一个Batch可以重复利用内存块的资源,一个是把内存块的资源给还回去,另外一个就是做并发的通知的处理
如果之前内存已经被耗尽了,此时有线程使用了Condition阻塞在这里等待获取内存资源,一旦有内存资源还回去了,此时就会使用Condition的await方法,唤醒之前阻塞等待的线程,告诉他们说,可以来尝试获取锁,然后申请内存资源了
处理异常重试
重试的Batch会放入到队列的头部,不是尾部,这样的话,下一次循环的时候就可以优先处理这个要重新发送的Batch了,attempts、lastAttemptMs这些参数都会进行设置,辅助判断这个Batch下一次是什么时候要进行重试发送
Batch的内存资源不会释放掉的
可以重试
对于这个处于重试状态的Batch
lastAttemptMs,是他重新入队的时间,retryBackoffMs其实就是重试的间隔,默认是100ms,他的意思是必须间隔一定的时间再进行重试,这个100ms一般来说建议保持默认值就可以了,但是重试的次数可以自己设置一下,一遍来说建议设置为3次
如果3次重试 都不行,那么一定是Kafka的集群出现问题了,此时人家就会回调你,通知你的回调函数说,重试之后还是异常
重新入队之后到现在必须已经过了100ms了,才能算做backingOff是true
lastAttemptMs + retryBackoffMs > now,意思是什么?上次重新入队的时间到现在还没超过100ms呢,如果说当前时间距离上次入队时间还没到100ms,此时backingOff就是true,如果是true的话,就不能重试
假如说:lastAttemptMs + retryBackoffMs <= now,就说明现在的时间距离上次重新入队的时间已经超过了100ms了,此时backingOff就是false,此时就说明这个要重试的Batch就可以再次发送了
多次重试失败
如果一个Batch是重试发送出去的,成功了,没有什么特别的,直接就是回调函数,然后就是释放资源,那么如果在指定次数内,3次,都没成功,哪怕重试几次都失败了,一定会回调通知你的
在使用Kafka的时候,如果是走异步的消息发送,回调函数的编写是很有必要的
还是最终会释放掉这个Batch占用的内存资源的
检测超时
如果说超时,一定会调用回调函数,必须去释放到这个batch的内存资源
总结
KafkaProducer源码中的 精华总结
(1)缓冲机制:数据结构,CopyOnWriteMap + Dequeu,Batch + Request
(2)内存管理:内存块缓冲池,有很多空的内存块,可以循环的利用,大幅度减轻JVM GC的弊端,避免频繁的回收大量的内存块
(3)网络通信:NIO封装自己的网络通信框架,KafkaSelector、KafkaChannel,一个客户端对多个Broker服务器建立长连接,缓存维护,IO多路复用,一个主线程完成跟多个客户端的网络通信,读写请求中的粘包和拆包的处理

















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









