






NSGA-II:快速非支配排序遗传算法(Fast Elitist Non-Dominated Sorting Genetic Algorithm)
在多目标优化(Multi-Objective Optimization, MOO)中,我们通常希望同时优化多个相互冲突的目标,而不是简单地找到一个最优解。NSGA-II(Non-dominated Sorting Genetic Algorithm II,快速非支配排序遗传算法 II)是一种强大的多目标优化算法,广泛应用于工程、金融、人工智能等领域。
1. NSGA-II 的核心思想
NSGA-II 是 Deb 等人在 2002 年提出的一种改进的遗传算法(GA),其核心思想包括:
- 非支配排序(Non-dominated Sorting):对种群进行排序,优先保留Pareto 最优解。
- 拥挤度计算(Crowding Distance Calculation):在相同支配层次(front)的个体中,选择分布均匀的解。
- 精英保留策略(Elitism):下一代种群不仅包括子代,还包括当前种群中最优的个体。
2. 数学原理
2.1 Pareto 最优解
一个解
x
x
x 被称为 Pareto 最优解,如果不存在另一个解
y
y
y 满足:
∀
i
,
f
i
(
y
)
≤
f
i
(
x
)
且
∃
j
,
f
j
(
y
)
<
f
j
(
x
)
\forall i, f_i(y) \leq f_i(x) \quad \text{且} \quad \exists j, f_j(y) < f_j(x)
∀i,fi(y)≤fi(x)且∃j,fj(y)<fj(x)
其中
f
i
(
x
)
f_i(x)
fi(x) 代表目标函数值。
Pareto 前沿(Pareto Front) 由所有 Pareto 最优解组成的集合形成。
2.2 非支配排序
定义种群中的每个个体 x x x 的支配度(dominance count) n x n_x nx,表示支配它的个体数量。然后进行层级划分:
- 第一层 Pareto 前沿(Front 1): n x = 0 n_x = 0 nx=0 的个体。
- 第二层 Pareto 前沿(Front 2):仅被 Front 1 个体支配的个体。
- 依次递推,直到所有个体被分类。
2.3 拥挤度计算(Crowding Distance)
拥挤度衡量了解在 Pareto 前沿上的分布情况:
C
D
(
i
)
=
∑
m
=
1
M
(
f
m
i
+
1
−
f
m
i
−
1
f
m
max
−
f
m
min
)
CD(i) = \sum_{m=1}^{M} \left( \frac{f_m^{i+1} - f_m^{i-1}}{f_m^{\max} - f_m^{\min}} \right)
CD(i)=m=1∑M(fmmax−fmminfmi+1−fmi−1)
其中,
f
m
i
f_m^i
fmi 代表目标函数
f
m
f_m
fm 的第
i
i
i 个个体,
f
m
max
f_m^{\max}
fmmax 和
f
m
min
f_m^{\min}
fmmin 分别为该目标的最大值和最小值。
3. NSGA-II 的实现步骤
Step 1:初始化种群
随机生成一组个体,每个个体代表一个可能的解。
Step 2:非支配排序(Non-dominated Sorting)
NSGA-II 采用快速非支配排序方法,将种群划分为多个非支配层(Fronts):
- 第一层包含所有非支配解。
- 第二层包含被第一层支配但不被彼此支配的解。
- 依次类推,直到所有个体都被分类。
Step 3:计算拥挤距离(Crowding Distance)
为了保持 Pareto 前沿的均匀分布,NSGA-II 计算个体的拥挤距离(Crowding Distance):
- 拥挤距离衡量了一个解与其他解之间的间隔。
- 距离大的个体优先保留,以确保解的多样性。
Step 4:选择(Selection)
- 采用 锦标赛选择(Tournament Selection),优先选择非支配层级更低或拥挤距离更大的个体。
Step 5:交叉(Crossover)与变异(Mutation)
- 交叉:使用模拟二进制交叉(SBX, Simulated Binary Crossover)生成新个体。
- 变异:采用多项式变异(Polynomial Mutation)增加解的多样性。
Step 6:生成下一代(Next Generation)
- 结合当前种群和子代种群。
- 进行非支配排序并按 Pareto 层级和拥挤度选择个体,形成下一代。
- 迭代至最大代数。
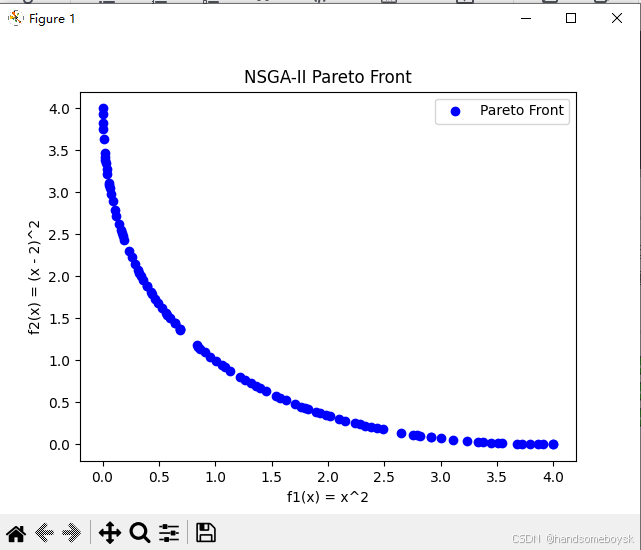
示例问题
假设我们有两个目标函数:
f
1
(
x
)
=
x
2
f_1(x) = x^2
f1(x)=x2
f
2
(
x
)
=
(
x
−
2
)
2
f_2(x) = (x - 2)^2
f2(x)=(x−2)2
目标是同时最小化
f
1
f_1
f1 和
f
2
f_2
f2。
4. Python 代码示例
使用 DEAP(Distributed Evolutionary Algorithms in Python)实现 NSGA-II 解决上述示例问题。
import random
import numpy as np
from deap import base, creator, tools, algorithms
import matplotlib.pyplot as plt
# 定义多目标优化问题(最小化)
creator.create("FitnessMulti", base.Fitness, weights=(-1.0, -1.0)) # 最小化两个目标
creator.create("Individual", list, fitness=creator.FitnessMulti)
# 初始化种群
toolbox = base.Toolbox()
toolbox.register("attr_float", random.uniform, -10, 10)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_float, n=1)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
def evaluate(individual):
x = individual[0]
return x**2, (x - 2)**2 # 目标函数 f1(x), f2(x)
toolbox.register("mate", tools.cxBlend, alpha=0.5)
toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=1, indpb=0.2)
toolbox.register("select", tools.selNSGA2)
toolbox.register("evaluate", evaluate)
def main():
pop_size = 100 # 种群大小
generations = 100 # 迭代次数
pop = toolbox.population(n=pop_size)
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("min", np.min)
stats.register("max", np.max)
pop, logbook = algorithms.eaMuPlusLambda(pop, toolbox, mu=pop_size, lambda_=pop_size,
cxpb=0.7, mutpb=0.2, ngen=generations,
stats=stats, halloffame=None, verbose=True)
return pop
if __name__ == "__main__":
pop = main()
# 获取 Pareto 前沿解
pareto_front = np.array([ind.fitness.values for ind in pop])
# 可视化 Pareto 前沿
plt.scatter(pareto_front[:, 0], pareto_front[:, 1], c='b', label='Pareto Front')
plt.xlabel("f1(x) = x^2")
plt.ylabel("f2(x) = (x - 2)^2")
plt.legend()
plt.title("NSGA-II Pareto Front")
plt.show()
5. 结果与分析
运行上述代码后,我们得到一个 Pareto 前沿图,其中每个点都是 NSGA-II 发现的 Pareto 最优解。通过观察该图,我们可以直观地看到优化的权衡关系。
6. NSGA-II 的优势
✅ 能够高效搜索 Pareto 前沿,适用于高维多目标优化。
✅ 保持解的多样性,通过拥挤距离防止收敛到局部最优。
✅ 无需目标加权,适用于权衡关系不明确的问题。


















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









