







原文链接:https://www.techbeat.net/article-info?id=4205
作者:seven_
近来,视觉语言模型(video-language models)已经成为多模态领域研究的热点话题,其可以完成多种视频到文本相关的任务,例如领域特定的字幕生成(domain-specific captioning),问答(question answering)和未来事件的预测(future event prediction)。但是现有的视频语言模型往往过多的关注编码器的设计,而解码器缺少从视频到文本(video-to-text)的生成能力。此外目前的视频字幕生成模型大都依靠在大规模视觉语言数据集上进行预训练,并且严重依赖于微调,其在小样本场景下识别未知样本的能力有所欠缺。
本文提出了一种基于小样本的视频语言学习器VidIL,其无需在任何视频数据集进行预训练和微调就可以在小样本视频文本任务上表现出优异的性能。具体而言,作者首先使用图像语言模型从视频内容中抽取出帧标题、对象类别、属性和事件短语,并将它们组合形成一种具有时间结构的模版,然后再通过指定一个提示符(prompt)引导语言模型从模版生成目标输出。得益于提示符的灵活性允许模型可以捕获多种形式的文本输入,例如通过自动语音识别(ASR)模型得到的数据,可以极大提高模型效率。本文的实验也证明所提出的VidIL模型在各种视频语言任务上的理解能力,特别是在小样本设置下的视频未来事件预测任务中,达到了目前的SOTA性能。目前本文已被人工智能领域顶级会议NeurIPS 2022接收。

论文链接:
https://arxiv.org/abs/2205.10747
代码仓库:
https://github.com/MikeWangWZHL/VidIL
一、引言
目前小样本视频语言理解仍处于起步阶段,常用的视频语言编码模型仍严重依赖于使用大量标注的视频样本对进行微调,因此无法快速适应没有见过的任务。因此,本文作者建议利用小样本学习来解决这个问题,作者的灵感来源基于这样一个现象,人类具有非常优秀视觉故事讲述能力,能够从一些孤立的图像中拼凑出一个连贯的故事。此外,视频中包含多粒度的丰富语义和时序内容。与静态图像相比,视频内容可以描述对象、属性和事件,然而,帧序列进一步丰富了对象的状态变化,产生的动作和事件。如下图所示,帧标题描述了第一帧的静态视觉特征,例如“一个人手里拿着一个绿色物体”。然而,视频序列却可以正确表述为”一个人在制作看很逼真的叶子和花朵“,还可以根据不同的时间戳对发生的对象和事件集合进行层次化的概述,例如”切割垫子和花朵设计“,因此,为了试模型能够达到视频级别的描述,就需要根据时间顺序提取这些内容。

为此,作者建议将视频分解为三个层次:视频输出、帧字幕和视觉tokens(包括对象、事件、属性)。将视频分层表示的一个优势是可以分离视频的视觉维度和时间维度。作者首先利用预训练图像语言模型从稀疏采样的帧中提取低层次视觉特征,随后使用CLIP模型[1]根据相似性得分对其中的视觉tokens进行标记。为了在帧级别捕获视频的整体语义,作者使用预训练图像语言模型BLIP[2]来生成帧字幕,然后使用in-context学习框架[3]将视觉tokens与生成的字幕解释为目标文本内容。
二、本文方法
下图为本文提出的层次化视频表示框架,它将视频分解为三个层次,即视觉tokens层、帧级层和视频层。在视觉tokens级别,提取每个采样帧的显著对象、事件和属性。在帧级别,执行图像字幕生成和文本过滤后处理。在视频层面,通过使用少量时间感知提示符,整合视觉tokens、帧标题和其他文本形式(如ASR)来构建视频表示。然后,将提示信息与特定于任务的指令一起发送到预先训练好的语言模型,以生成各种视频语言任务的目标文本。下面将详细介绍这三个层次的具体操作细节。
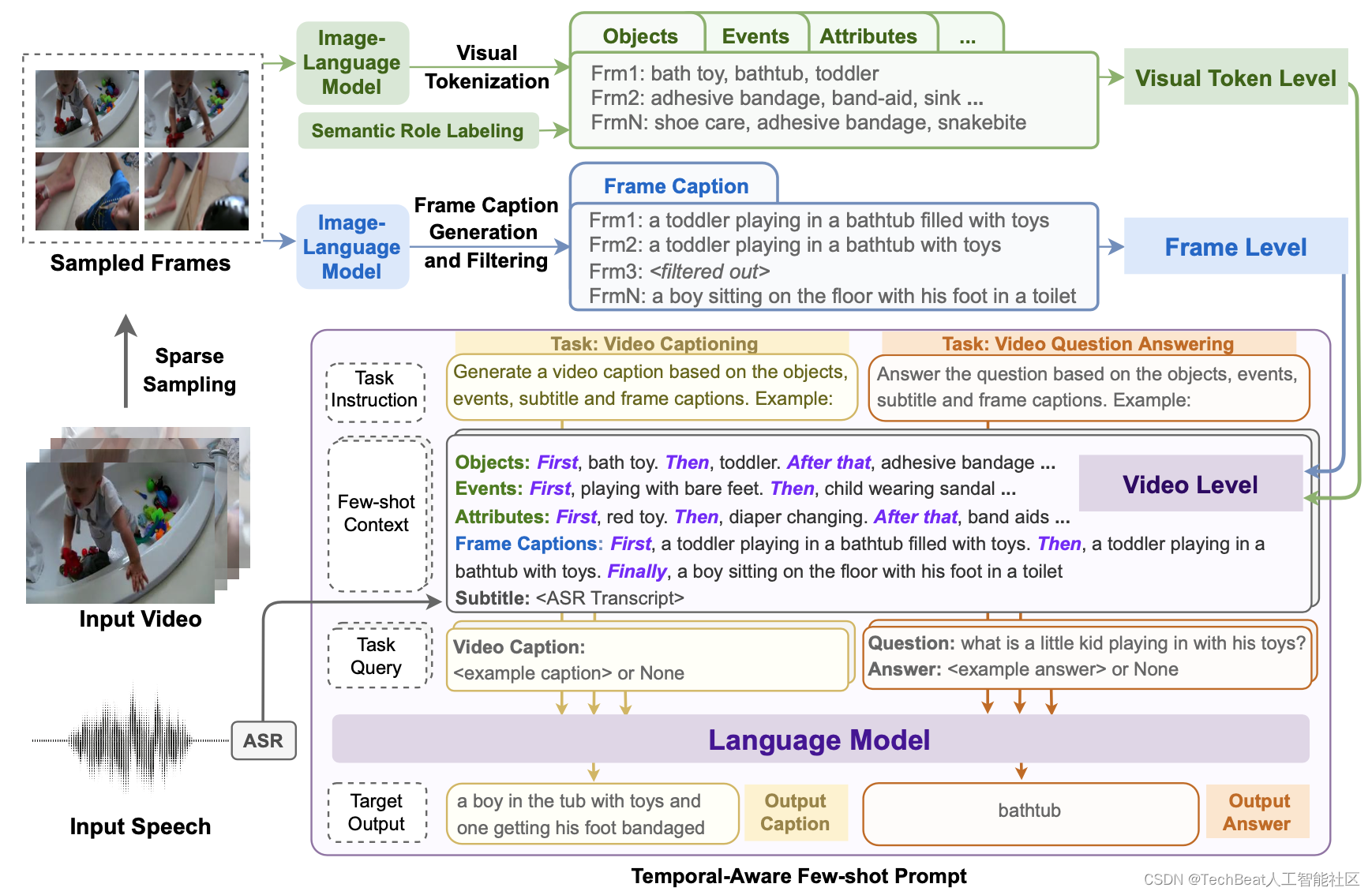
2.1 帧级别:图像字幕生成
在帧级别,作者首先执行稀疏采样以获得视频帧序列,然后将视频序列输入到预训练的图像语言模型BLIP来获得帧级字幕,如上图的蓝色部分所示。BLIP模型是最近提出的一种图像语言框架,其由基于图像的编码器和解码器构成,可以直接用于帧字幕生成任务。由于视频包含丰富的语义和多粒度的时序内容,仅得到帧级的视频字幕是不够的,因此需要进一步对每一帧执行视觉标记化,以获得更加细粒度的视频特征。
2.2 视觉tokens级别:结构感知视觉标记化
在视觉tokens层次中,模型的目标是提取显著视觉token的文本表示,例如对象、事件和属性。作者发现,之前工作使用的预定义分类类别仍然来源于ImageNet,其远远不够涵盖开放域视频中的丰富语义。因此作者没有像之前的工作一样使用基于分类的视觉标记化方法,而是利用对比图像语言模型采用基于检索的可视化标记化方法。即首先给定一个包含所有候选对象、事件和属性文本短语的视觉词汇表,使用对比式编码器CLIP计算帧的图像嵌入和候选视觉token的文本嵌入,然后根据图像和文本嵌入的余弦相似性选择前5个视觉标记,提取过程如上图的绿色部分所示。
2.3 视频级别:时序引导的小样本提示学习
在完成从帧级别和视觉tokens级别获得文本表示后,模型需要将这些信息进行组合以生成视频级别的目标文本。由于本文的目标场景是小样本设置,只需几个示例样本即可使模型快速适应到不同类型的视频到文本的生成任务。为此,作者使用大规模预训练语言模型,例如GPT-3来完成小样本提示学习,如上图紫色部分所示,VidIL框架可以通过共享Prompting模板灵活的泛化到多种视频文本任务上,例如视频字幕生成和视频视觉问答,这种提示策略可以使语言模型能够同时兼顾低层次的视觉信息和时序信息。
具体而言,小样本提示由三部分组成:指令、小样本context和任务query。其中指令是对生成任务的简明描述,例如“Generate a video caption based on the objects, events, attributes and frame captions”。小样本context包含视频内容中的关键事件,其由一系列视觉tokens组成,例如“Objects(对象): First, bath toy. Then,…”(有一个洗浴玩具),“Frame Captions(帧标题): First, a toddler playing in a bathtub filled with toys. Then,…"(一个蹒跚学步的孩子在浴缸里玩玩具),以及ASR输入。任务query是特定于任务的指令格式,例如“Video Caption”(视频字幕生成)。
形式上,作者将指令表示为
t
t
t,将小样本context表示为
c
c
c,任务query表示为
q
q
q,目标文本表示为
y
y
y,其中
y
=
(
y
1
,
y
2
,
…
,
y
L
)
\mathbf{y}=\left(y_{1}, y_{2}, \ldots, y_{L}\right)
y=(y1,y2,…,yL)。 下一个目标
y
l
y_{l}
yl 的生成可以建模为:

为了捕捉帧和视觉tokens之间的时序交互动态,作者进一步在prompt中注入时序标记(temporal markers)。如上图中的小样本context部分,每个视觉token和帧标题都以自然语言短语为前缀,并且指示其时间顺序,例如“First”、“Then”和“Finally”。作者发现添加这些时序标记可以使语言模型不仅以文字为条件,还可以以上下文的时间信息为条件。下图展示了一个示例,将时序prompt与使用InstructGPT生成的静态prompt进行了比较。在此示例中,两个上下文之间的唯一区别是视觉tokens和帧标题的顺序。对于左边的上下文,“太阳移动”出现在“夜空”之前,可以预计到会看到一个关于日落的故事,而对于右边的上下文,预计会看到日出的故事,可以观察到静态prompt为两种上下文生成关于日落的字幕,而时序prompt可以正确捕获时间顺序并为右侧的上下文生成日出的字幕描述。

三、实验效果
作者分别在涵盖开放域(MSR-VTT、VaTeX)和特定域(YouCook2)的三个视频字幕数据集上进行了实验验证,并且与目前最先进的视频字幕生成模型UniVL[4]和图像字幕生成模型BLIP进行了对比实验,为了构成小样本视频字幕生成的任务设置,作者进一步将BLIP中用于文本视频检索评估的方法扩展到视频语言训练上来。
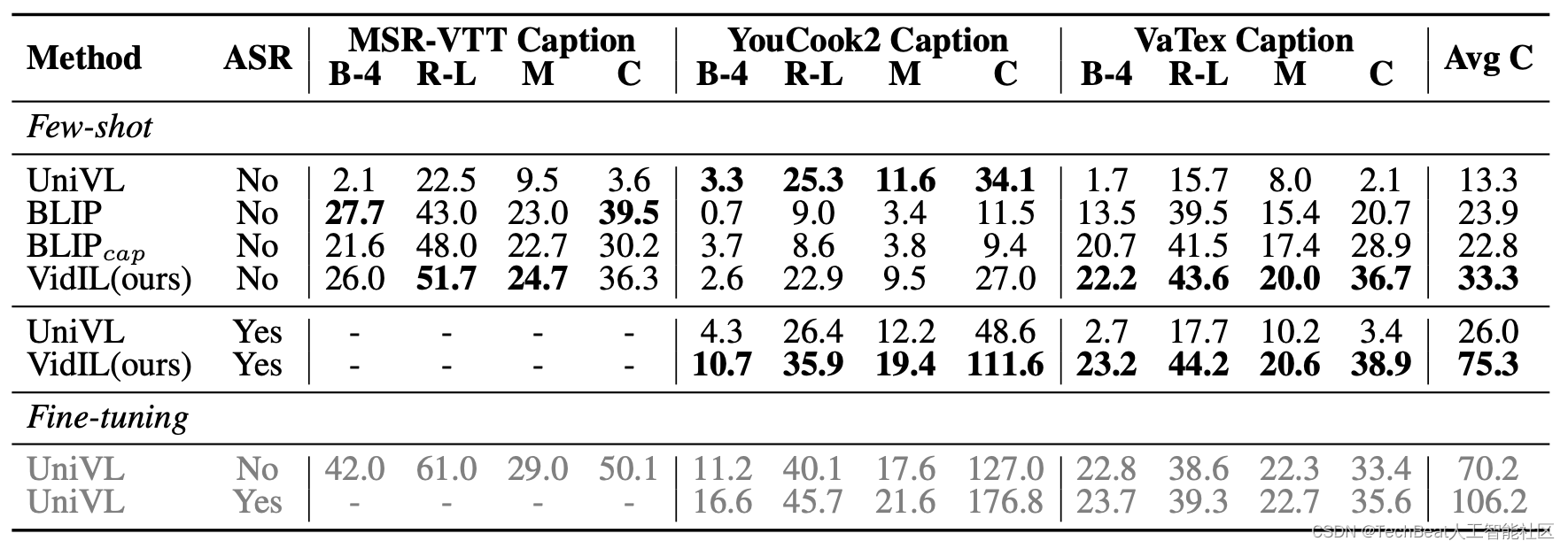
实验结果如上表所示,现有方法对某些数据集有很强的偏差。例如,UniVL在YouCook2上表现良好,但在MSR-VTT和VaTeX上表现不佳,而BLIP则相反。这是因为UniVL是在HowTo100M上进行预训练的,其对教学类视频更加鲁棒,而BLIP是在图像-字幕对上进行预训练,对描述类的字幕生成更加熟悉。相反,本文提出的模型在开放域和教学类视频上的表现都具有竞争力,并且在所有三个基准测试中的平均CIDEr分数都显着优于基线方法。这表明通过利用语言模型,无论视频域或目标字幕分布如何,VidIL都可以保持鲁棒的小样本学习能力。

作者还进一步展示了VidIL对视频字幕生成的示例,如上图所示,灰色框表示所选取视频的片段,蓝色框包含了不同模型生成出来的字幕,绿色框中展示了对于该段视频的GroundTruth标注,粗体绿色文本突出显示了基线方法输出中未能正确捕获的信息,但这些信息可以通过VidIL的视觉tokens和帧标题中推断出来。

此外作者还展示了VidIL的未来事件预测能力,VidIL不仅可以回答有关视频视觉特性的问题,还可以回答“接下来可能发生什么?“,如上图所示,给定一段带有相关字幕的视频作为前提,视频语言事件预测(VLEP)任务是预测未来最有可能发生的事件。原始VLEP[5]论文将该问题表述为一个二进制分类问题,模型会从两个可能的未来事件候选中选择最有可能的一个事件。相反,本文作者将这个问题转换为另一种视频到文本生成问题,由于事件预测任务在很大程度上依赖于视频中的时序动态,通过VidIL的时序prompt,可以引导语言模型捕获历史事件和未来事件之间的时间动态,帮助模型更准确的生成目标文本。
四、总结
本文提出了VidIL模型,一种基于小样本学习理论的视频语言学习器。当使用图像语言模型将帧特征作为统一的文本表示作为输入时,它展示了将大规模预训练语言模型迁移到多种视频文本任务中的普适能力。作者通过将视频内容进行层次化分解,并提出了时序感知的prompt机制,帮助模型整合了多个级别的帧时序特征以及语音转录(ASR)多模态信息。作者通过大量实验证明,在没有对大规模视频预训练的情况下,VidIL在各种小样本任务(例如特定领域的字幕生成、问答和未来事件预测)上均由于在大规模视频数据集中训练的视觉语言模型。VidIL的提出为视觉语言模型领域加入了设计更鲁棒模型,具有小样本能力模型的需求,这对于模型应用到更加广泛的领域具有重要的启示作用。
参考
[1] AlecRadford, JongWookKim, ChrisHallacy, AdityaRamesh, GabrielGoh, SandhiniAgarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, ICML 2021.
[2] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. ArXiv preprint, abs/2201.12086, 2022.
[3] LongOuyang, JeffWu, XuJiang, DiogoAlmeida, CarrollLWainwright, PamelaMishkin, ChongZhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. ArXiv preprint, abs/2203.02155, 2022.
[4] Huaishao Luo, Lei Ji, Botian Shi, Haoyang Huang, Nan Duan, Tianrui Li, Jason Li, Taroon Bharti, and Ming Zhou. Univl: A unified video and language pre-training model for multimodal understanding and generation. ArXiv preprint, abs/2002.06353, 2020.
[5] Jie Lei, Licheng Yu, Tamara Berg, and Mohit Bansal. What is more likely to happen next? video-and-language future event prediction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8769–8784, Online, 2020. Association for Computational Linguistics.
Illustration by TanahAir Studio from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









