




 BNV-Fusion是针对神经网络隐式表达在实时三维重建中面临的实时性和可更新性挑战提出的新方法。通过双层融合机制——局部融合和全局融合,BNV-Fusion能高效且精确地融合新的深度图,实现快速且高质量的三维重建。局部融合采用类似Kinect-Fusion的加权平均策略,全局融合则通过迭代优化确保重建的准确性和一致性。实验结果显示,BNV-Fusion在多个数据集上超越了现有方法,且具备较高的运行效率。
BNV-Fusion是针对神经网络隐式表达在实时三维重建中面临的实时性和可更新性挑战提出的新方法。通过双层融合机制——局部融合和全局融合,BNV-Fusion能高效且精确地融合新的深度图,实现快速且高质量的三维重建。局部融合采用类似Kinect-Fusion的加权平均策略,全局融合则通过迭代优化确保重建的准确性和一致性。实验结果显示,BNV-Fusion在多个数据集上超越了现有方法,且具备较高的运行效率。
摘要:
最近的神经网络隐式表达(neural implicit representation)因为其在三维重建和新视角图片生成的显著效果受到广泛关注,可是直接把神经网络隐式表达运用到实时三维重建上主要有两个难点:
-
实时性,neural implicit representation通常需要非常长的训练时间;
-
可更新性,因为重建是一个在线的过程,算法需要根据新的深度图更新对场景的重建。
针对以上问题,我们创新性地提出BNV-Fusion。本作的亮点在于我们所提出的双层融合机制能够高效并且精确地把新的深度图融合进对三维场景的隐式表达中。在运行速度上,BNV-Fusion显著优于之前基于神经网络隐式表达的工作。在重建效果上,本作也能精确地重建之前工作容易忽略掉的细节。

:::
论文名称:
BNV-Fusion: Dense 3D Reconstruction using Bi-level Neural Volume Fusion
论文链接:
https://arxiv.org/pdf/2204.01139.pdf
代码链接:
https://github.com/likojack/bnv_fusion
视频解读-Youtube:
https://www.youtube.com/watch?v=ptx5vtQ9SvM
视频解读-Bilibili:
https://www.bilibili.com/video/BV12Y4y1x7c9/
一、研究动机
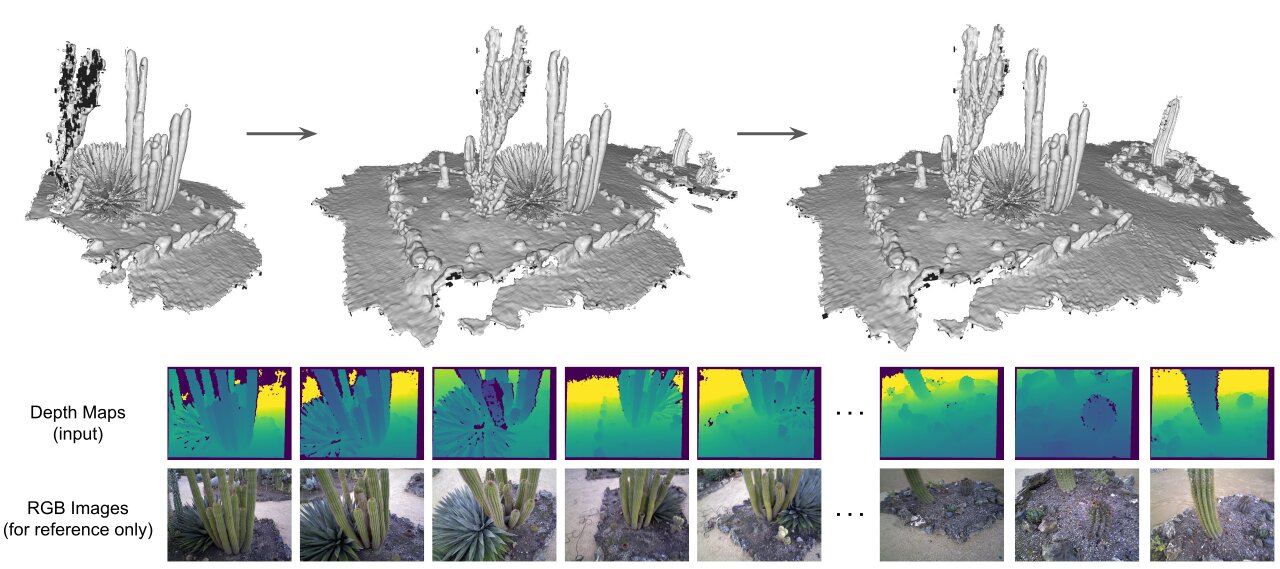
图一 三维重建示意图
:::
实时三维重建要求在移动的深度相机获得的一系列深度图上重建稠密的三维表面(如上图所示)。这项任务具有广泛的用途,例如展示三维模型,AR/VR的相关应用。传统的TSDF-Fusion,例如著名的Kinect-Fusion[1],虽然在普通场景下能绘制三维场景,但是他们的局限性在于体素(Voxel)大小的选择上。过大的体素虽然能有效过滤深度图的噪声,但是会失去重建的细节。过小的体素则会导致相反的问题。
最近受到广泛关注的神经网络隐式表达(Neural implicit representation),例如DeepSDF[2],NeRF[3] 在三维模型重建和新视角生成方面都取得了非常好的效果。他们能够绕过上述传统重建方法遇到的问题。可是,把神经网络隐式表达运用到实时三维重建上仍然面临一些困难:
-
神经网络隐式表达需要训练长达数小时甚至数天来重建一个场景。因此达不到实时的要求。
-
因为深度相机在持续提供新的深度图,神经网络隐式表达还需要能根据新的深度图来更新已重建的地图。现有的大部分方法通常不会去考虑更新地图的这个要求。
尽管近来有一些工作尝试将神经隐式表达应用在实时三维重建上,他们在运行时间和重建精度上离传统的Kinect-Fusion还有较大距离。我们认为主要的限制因素在于如何高效地融合新的深度图到隐式表达。针对这个问题,我们创新地提出双层融合方法(Bi-level Fusion)。
二、方法
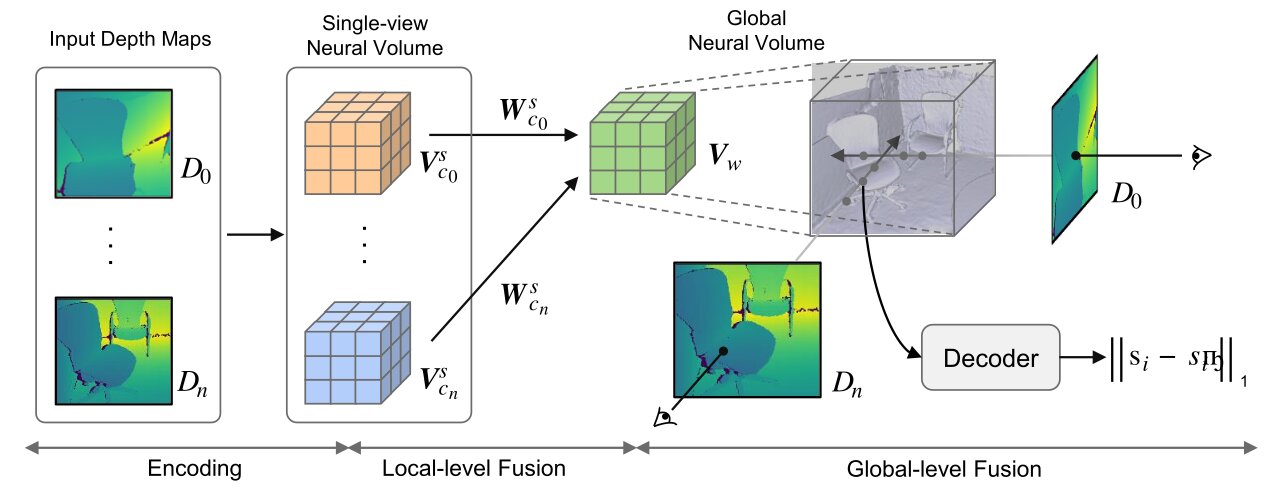
图二 BNV-Fusion结构图
:::
2.1 概述
如上图所示,BNV-FUsion主要有三个步骤。第一步是Encoding:给定一张新的深度图,我们首先将其映射到一个描述这个深度图三维表面的neural implicit volume。第二步是局部融合(local-level fusion):我们在隐式空间中局部地融合新的neural implicit volume到global representation中,最后一步是全局融合(global-level fusion):在局部融合的基础上,我们通过多角度下的深度图观测优化描述整个三维场景的neural implicit volume。
2.2 三维场景的表达方式
我们对三维空间的表达基于稀疏的neural implicit volume。Volume里的每一个voxel v = ( p , l ) \mathbf{v} = (\mathbf{p}, \mathbf{l}) v=(p,l) 包含了这个voxel在空间中的位置 p \mathbf{p} p 和一个 N N N 维的隐式码(latent code) l ∈ R n \mathbf{l}\in\mathcal{R}^n l∈Rn 。隐式码在隐式空间中表达了局部的三维表面。所有的voxel结合起来所形成的feature volume就在隐式空间中表达了整个场景的三维表面。给定三维空间中的任意点 x \mathbf{x} x,我们首先将其坐标转换成基于临近voxels的局部的坐标: x ˉ i = x − p i \bar{\mathbf{x}}_i = \mathbf{x} - \mathbf{p}_i xˉi=x−pi ,它的截断符号距离函数(TSDF)便可用以下公式获得:
s = ∑ i = 0 N = 7 w ( x ˉ i , p i ) D ( l i , x ˉ i ) , s = \sum_{i=0}^{N=7} w(\bar{\mathbf{x}}_i, \mathbf{p}_i)\mathcal{D}(\mathbf{l}_i, \bar{\mathbf{x}}_i), s=i=0∑N=7w(xˉi,pi)D(li,xˉ<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









