








论文链接: https://arxiv.org/abs/2303.13479
代码链接: https://github.com/CVMI-Lab/IST-Net
01.背景介绍
Category-level 的物体姿态估计旨在让模型学习到类别独有的特征,从而能够在面对未见过的同类别物体时展现出良好的泛化性。为了解决 inrta-class variation 的问题,SPD 在早期提出了一种 Prior-based 的框架,现已被大多数主流的方法所采用。具体操作是当我们想估计一个 RGBD 图片的位姿时,使用预先训练好的一个 shape prior 作为辅助,学习 deformation 和 matching 的矩阵让 prior 通过先重建 RGBD 图片所对应的 3D 模型再进一步转换到世界坐标系下的视角(NOCS)。有了匹配的相机坐标系和世界坐标系下的视角,求解位姿便是一件十分容易的事情。
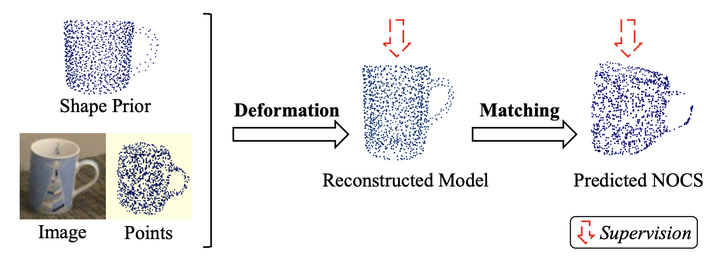
02.Prior-based 方法对于 3D 模型的开销
3D 模型的标注是昂贵和耗时的,因此减少对于 3D 模型的依赖对于算法的实际应用是十分重要的。Prior-based 方法所产生的对于 3D 模型的数据开销主要来源于两个方面。一方面是训练过程中,网络在学习 deformation 的矩阵时(图 1)需要来自 3D 模型的监督。而另一方面是,prior 的产生需要依赖于大量的 3D 模型。
如图 2 所示,首先使用大量的 3D 模型训练一个 auto-encoder, 在训练完成后将相同类别的所有 3D 模型输入到 enco
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









