









在Hadoop集群上面使用数据库导入数据工具:sqoop(这个工具的作用就是将服务器或者本地MySQL数据库单表或者多表联合查询出来的数据直接上传到hadoop集群中,或者将hadoop集群中的数据迁移到MySQL数据库当中)
1.配置工作:
下载sqoop文件:这里我使用的是sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar
下载connector文件:这个文件是数据库与hadoop集群传输数据的驱动:mysql-connector-java-5.1.38.tar.gz
2.文件的存放路径
(1)在服务器上面保存sqoop文件和jdbc文件的配置:
(2)在服务器中我存放sqoop文件的目录是:/usr/sqoop
(3)把解压过后的jdbc驱动文件拷贝到sqoop文件目录下的lib目录中
3.重命名配置文件
在sqoop目录下的conf目录中执行命令:
mv sqoop-env-template.sh sqoop-env.sh
在conf目录下,有两个文件sqoop-site.xml和sqoop-site-template.xml内容是完全一样的,不必在意,我们只关心sqoop-site.xml即可。
4.修改配置文件信息:
(1)修改在sqoop目录下的conf目录中的sqoop-env.sh文件信息:vim sqoop-env.sh
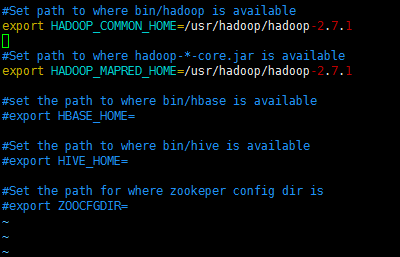
因为目前还没有使用到HBASE,HIVE,ZOOKEPPER,所以可以把这些功能的环境变量的信息注释掉,以后使用到的时候再去配置即可.
(2)修改sqoop目录下的bin目录中的configure-sqoop文件,把文件中有相关HBASE,HIVE,ZOOKEPPER的信息全部注释掉
5.启动sqoop
在sqoop的bin目录下执行命令: ./sqoop
通过此命令来启动sqoop功能
配置sqoop的环境呢变量:

成功后,在根目录下输入sqoop命令来查看sqoop能否正常使用:
成功后:

6.数据迁移测试:
(向数据库中上传数据)在bin目录下输入命令: ./sqoop import --connect jdbc:mysql://(服务器的IP地址):3306/rmsdb --username 你的数据库用户名 --password 数据库密码 --table rae_updatejson(表名称) --cloumns “id,account,icome” --target-dir -m 1 (启用一个map)
这里面每个参数的含义:
-import;向集群中迁入数据
jdbc:mysql://123.57.210.236:3306:数据库所在的服务器IP地址
-rmsdb:数据库名称
-username:数据库的用户名
-password:数据库密码
--table 数据库里面的表名
-m 1;启动的mapper数量
--target-dir:数据导入到hdfs中的路径
--cloumns:要导入的表中的列数据
迁出数据
:
sqoop export --connectjdbc:mysql://(服务器的IP地址):3306/sqoop --table tb2 --username --password123456 --export-dir
hdfs://hadoop0:9000/user/hadoop/tb1/part-m-00000















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









