







第九章 Recurrent Neural Networks 递归神经网络
与传统的前馈神经网络(如全连接网络)不同,RNN 具有 循环结构,能够处理和记住序列中的时间依赖性。
9.1 Sequential Processing
输入和输出对应关系可以有一对一、一对多、多对一、多对多、不定长对不定长等等等等,有着不同的应用场景。
9.2 Recurrent Neural Network
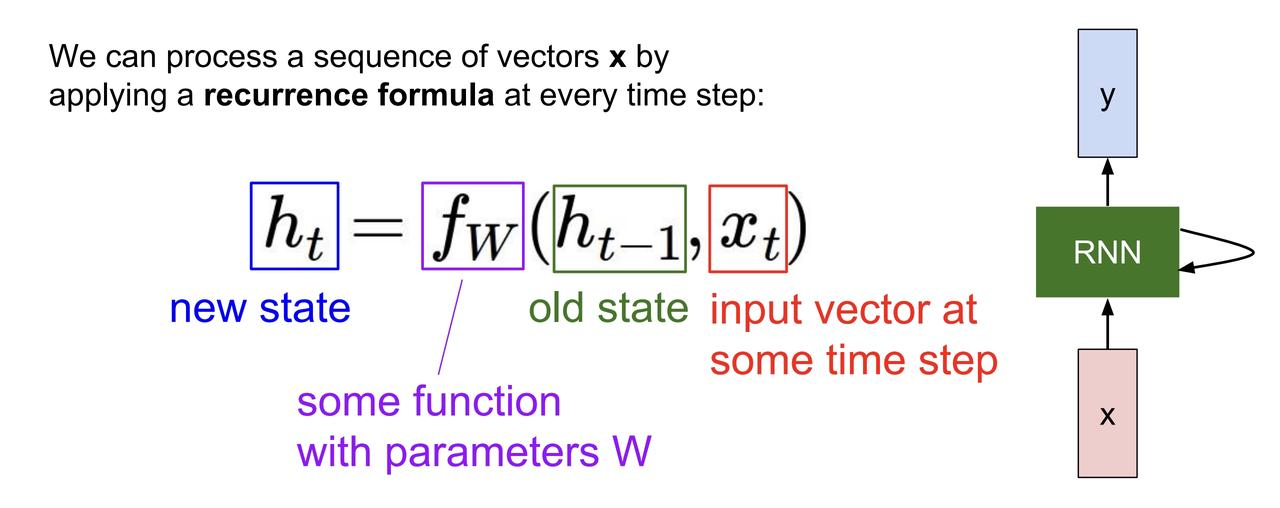
9.2.1 Internal hidden state 内部隐藏态
内部隐藏态会在 RNN 每次读入新的输入时更新,并且 RNN 生成输出。
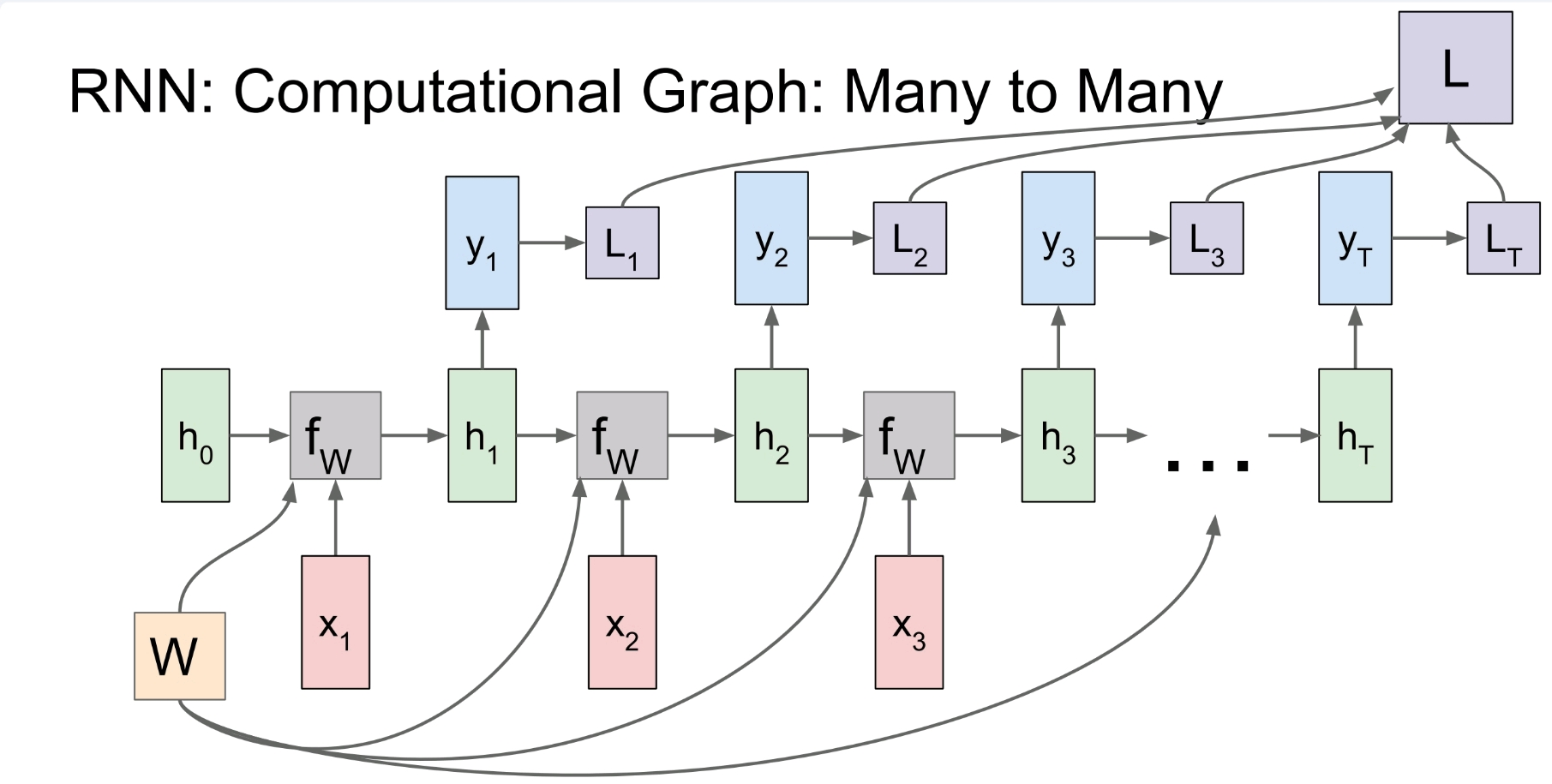
9.2.2 RNN 的计算图展开
首先是多对多 :
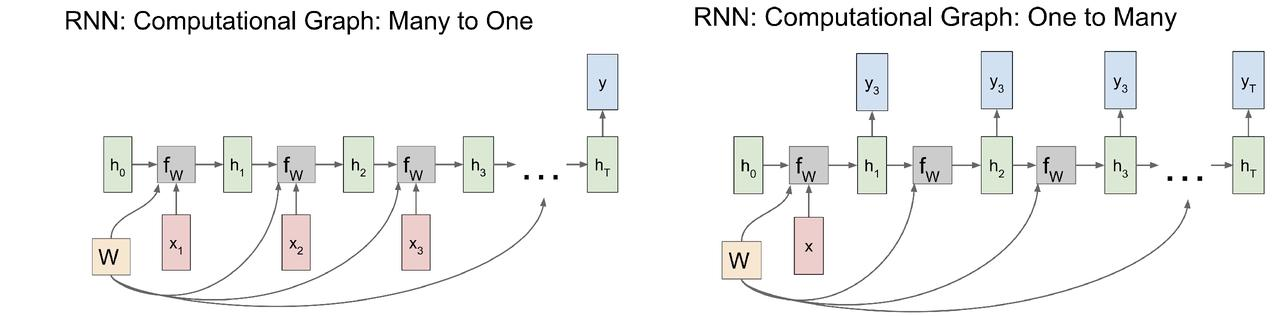
多对一、一对多 类似:
Sequence to Sequence(不定长对不定长)
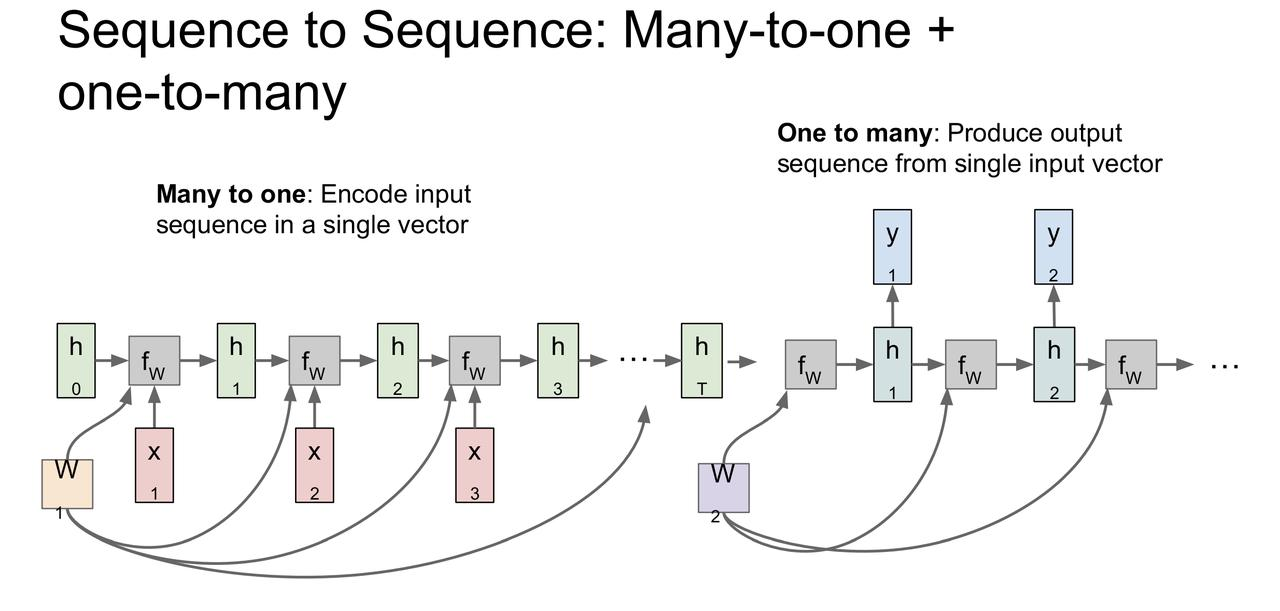
可以当作 多对一 + 一对多。一般语言翻译会涉及到。
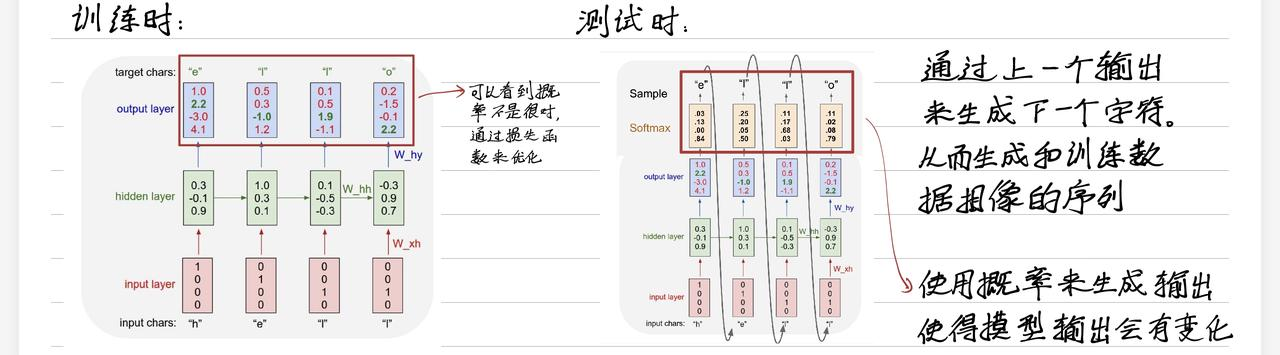
9.3 RNN 的训练和测试
9.4 Backpropagation through time 沿时间的反向传播
因为输出时是随着时间推移输出,所以反向传播要“逆着时间往回”。将损失函数的梯度通过每个时间步反向传播到初始时间步。
但是会引起梯度消失 / 爆炸,以及算力不足。
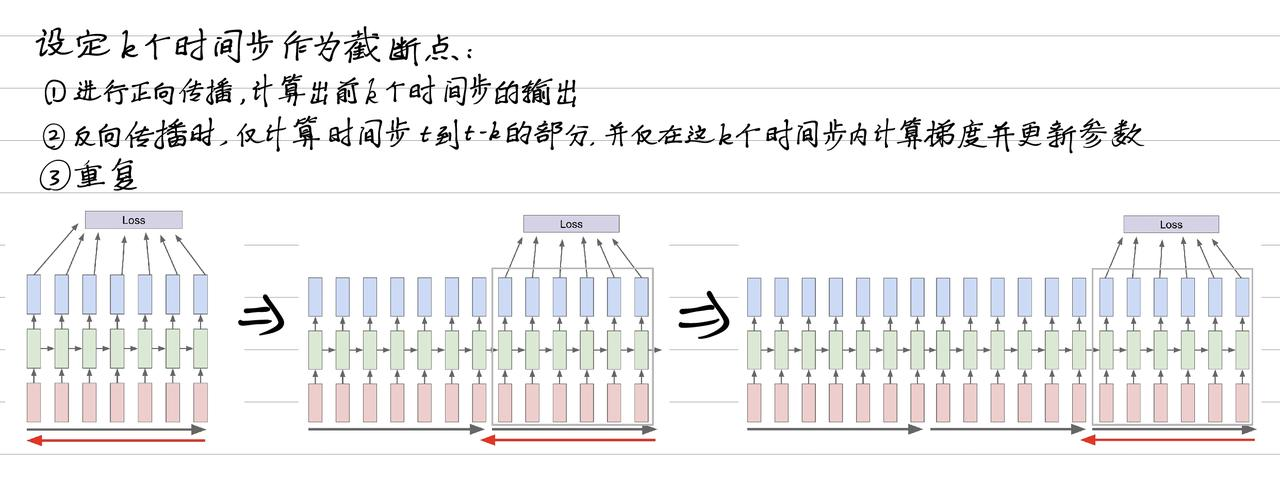
所以就有了 Truncated 的(沿时间截断反向传播算法):
9.5 RNN 的局限性
RNN 主要进行局部模式学习,记忆容量不足,所以只能写出看似连贯的文字,没有全局的语义理解。因为前期的记忆会慢慢被“冲淡”。
改进机制:LSTM 或 GRU
LSTM (长短期记忆网络):通过遗忘门(决定保留多少旧记忆)、输入门(控制新信息注入)和输出门(决定输出的信息量)显示管理信息流。
GRU (门控循环单元):简化版 LSTM,合并部分门控,但仍能有效缓解梯度消失。
9.6 Image Caption 图像标注
输入是图像,输出是语义信息。
将输出的语义信息看作可变长度的字符序列,适配 RNN。
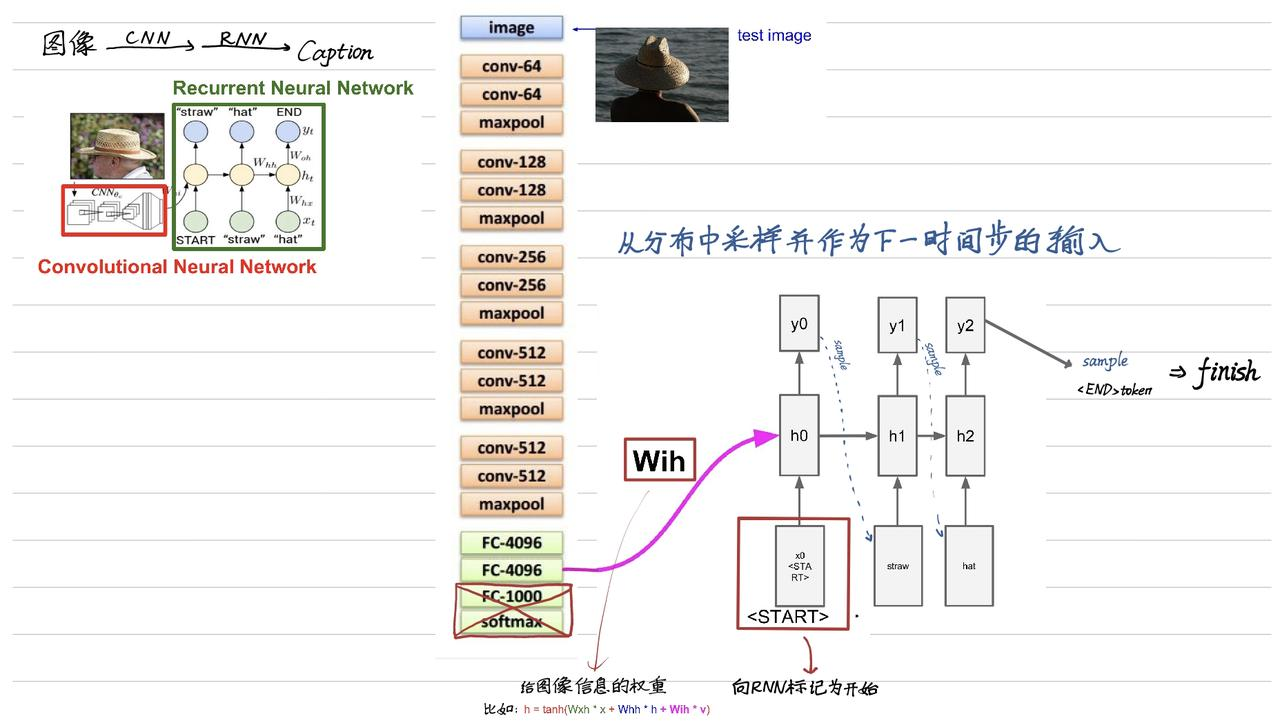
可以采用 监督学习 的方式,也可以 GAN 。
在训练数据范围内的测试数据可以表现的很好,但是在没有出现过的形象面前表现欠佳(以及无法区分扔球和抓球等)。
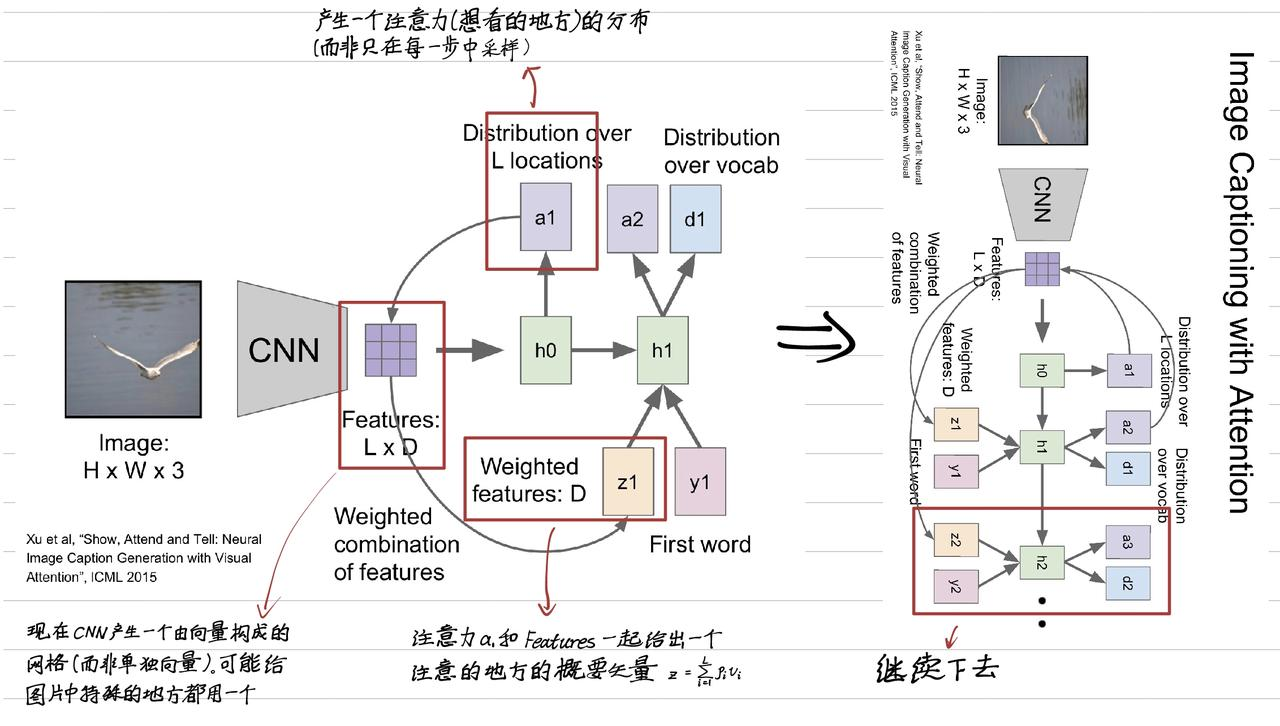
9.7 Image Captioning with Attention
9.7.1 Attention 机制
CNN 输出的是一组二维特征图 patch,记作 L × D L \times D L×D,每个 patch 是一个区域(图像块)向量 v i v_i vi。
当前隐藏状态 h t h_t ht(RNN)被用作 Query,与所有 v i v_i vi 计算注意力分数 a i = a t t e n t i o n ( h t , v i ) a_i = attention(h_t, v_i) ai=attention(ht,vi)。
将所有特征向量 v i v_i vi 按注意力加权求和得到 z t = Σ α i ∗ v i z_t = Σ α_i * v_i zt=Σαi∗vi。
z t z_t zt 作为上下文送入 decoder,辅助生成下一个词。
- Hard attention: 强制模型每一步只选一个位置
- Soft attention: 加权组合图像位置中的所有特征

9.7.2 视觉问答
比如问图中哪个是濒危动物。这里有两种思考方式,前面用的是一对多的机制,这里也可以把语言序列 + 图像想成多对一的输入,但其实一般还是看成一个向量。
问题向量和视觉向量怎么结合?
一般来说直接连接起来,传入 CNN 即可。也有作乘法啥的。
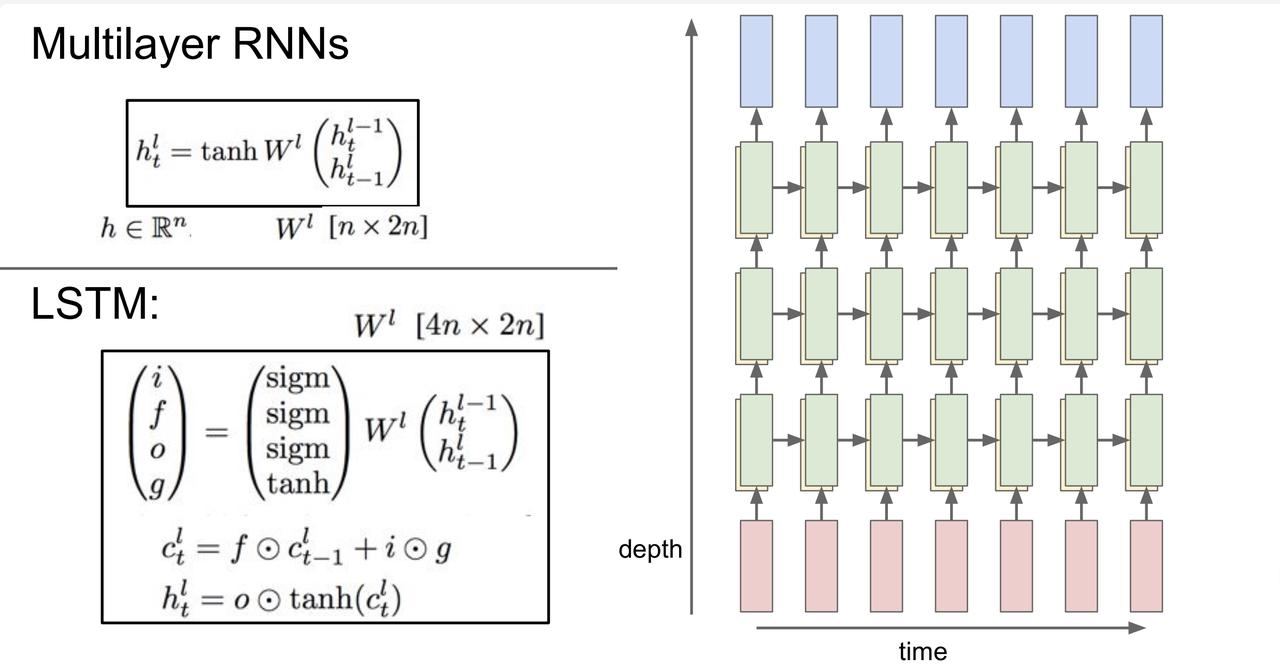
9.8 Multilayer RNNs 多层递归神经网络
多层意味着多个隐藏状态(hidden state)。一般使用二、三、四层的 RNN,不会太深。低层的作为高层的输入。效果一般会更好。
9.9 Gradient flow in RNN
9.9.1 Vanilla RNN gradient flow (Vanilla 可以理解为“原始的”“传统的”)
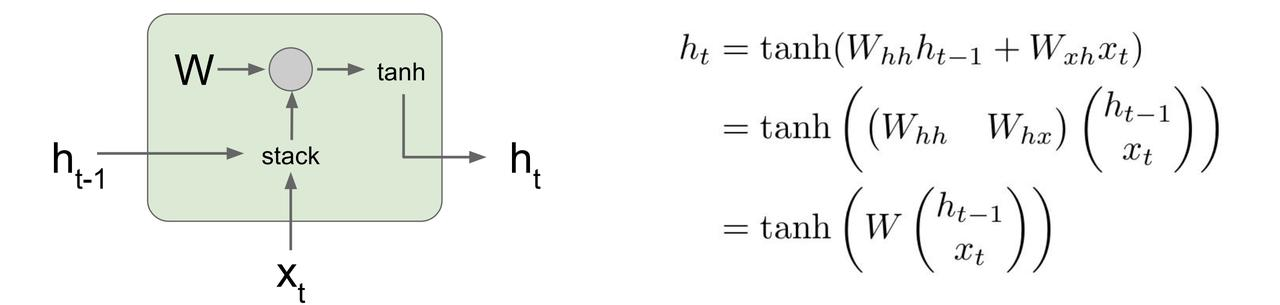
多层连续反向传播,每层都乘以权重矩阵的转置之类的:

不是梯度消失就是梯度爆炸(取决于矩阵的最大奇异值)。有一种解决方式是 梯度截断 ,就是发现 L2 范式太大了的时候,直接“剪断”(具体要见代码)。
9.9.2 Long Short Term Memory (LSTM)
设计一种更好的结构控制梯度流动。
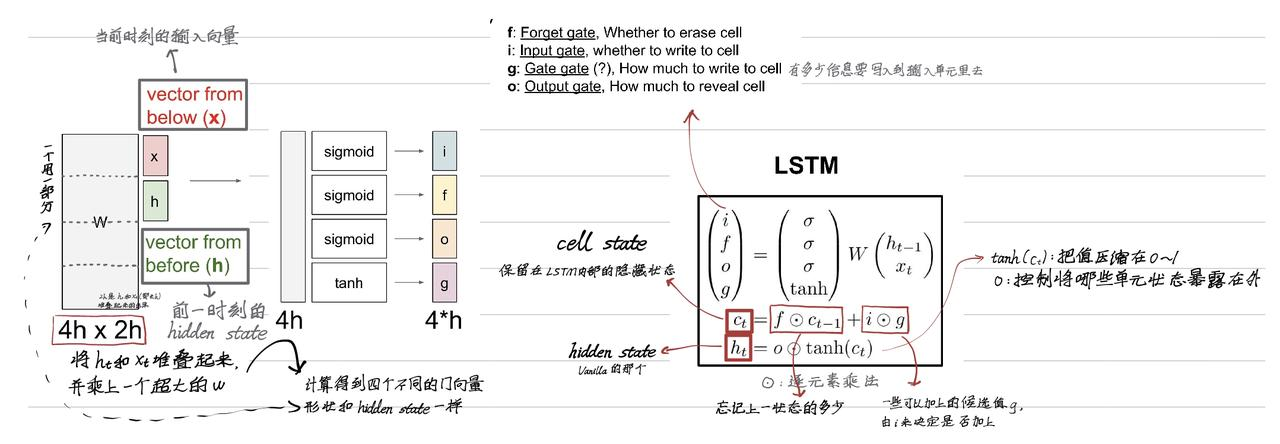
LSTM 的反向传播

- 从 h t h_t ht 开始到 c t c_t ct 后,经过这第一个 tanh() 函数就再也不经过了,一路畅通
- 经过那个逐元素乘法结点时,会将 遗忘门 f 的数值传递。而遗忘门每次都在变,所以不会随意的梯度消失 / 爆炸
- 都用的逐元素乘法,开销比矩阵乘法小
其中权重矩阵的反向传播:什么因为 c t c_t ct保存了每一个时间步上的权重的局部梯度就很好,没听懂。
9.9.3 GRU
利用元素乘法门和加法避免梯度消失 / 爆炸。类似 LSTM。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









